prometheus存储
目录
一:prometheus架构
二:存储
1.本地存储
磁盘大小计算
为什么默认两个小时存储一次数据,写成一个chuck块文件?
最新写入的2 小时数据保存在内存中
数据大内存问题
如何防止断电程序崩溃数据丢失
数据存储方式
删除数据方式
本地存储的缺点
2.远程存储
配置
influxdb简介
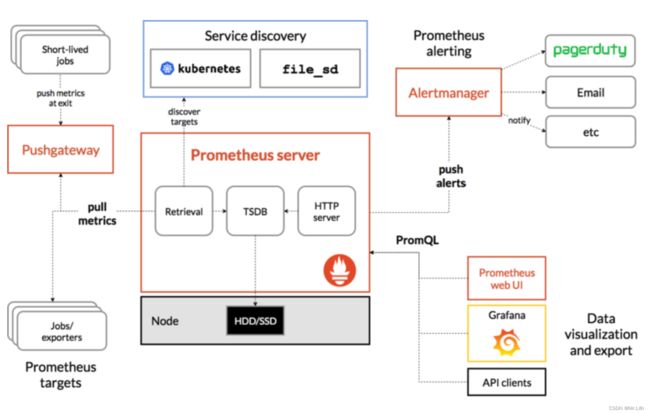
一:prometheus架构
网上找的图
二:存储
1.本地存储
Prometheus 按2小时一个block进行存储,每个block由一个目录组成,该目录里包含:一个或者多个chunk文件(保存时间序列数据)默认每个chunk大小为512M、一个metadata文件、一个index文件(通过metric name和labels查找时间序列数据在chunk 块文件的位置。
磁盘大小计算
磁盘大小计算方式:磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小
保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
因此有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。
考虑到Prometheus会对时间序列进行压缩,因此减少时间序列的数量效果更明显。
为什么默认两个小时存储一次数据,写成一个chuck块文件
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。
/prometheus $ ls -alh
total 24K
drwxrwsrwx 17 root 2000 4.0K Feb 22 05:00 .
drwxr-xr-x 1 root root 28 Feb 2 06:03 ..
drwxr-sr-x 3 1000 2000 68 Feb 21 05:00 01EZ1FAVT6VZ7GQ2RKNZRFK47Z
drwxr-sr-x 3 1000 2000 68 Feb 21 07:00 01EZ1P6K16BXJQJDFF008VKVZ1
drwxr-sr-x 3 1000 2000 68 Feb 21 09:00 01EZ1X2A9B41NMEPD0T8FH9YH2
drwxr-sr-x 3 1000 2000 68 Feb 21 11:00 01EZ23Y1HQQPJZJTGF4NPH944Y
drwxr-sr-x 3 1000 2000 68 Feb 21 13:00 01EZ2ASRS728MQ2TWXC2K6R3G6
drwxr-sr-x 3 1000 2000 68 Feb 21 15:00 01EZ2HNG2GSF4GD2JZ25FBJHS3
drwxr-sr-x 3 1000 2000 68 Feb 21 17:00 01EZ2RH7A3M9V3RPDHDN4T21FM
drwxr-sr-x 3 1000 2000 68 Feb 21 19:00 01EZ2ZCYJFNG3HYWF326NJKXE3
drwxr-sr-x 3 1000 2000 68 Feb 21 21:00 01EZ368NS93N04A6RHDBGFBKJQ
drwxr-sr-x 3 1000 2000 68 Feb 21 23:00 01EZ3D4D13YT2HG8QPR4WB1QK0
drwxr-sr-x 3 1000 2000 68 Feb 22 01:00 01EZ3M04943Q1WW6SGAGN9ZVWX
drwxr-sr-x 3 1000 2000 68 Feb 22 03:00 01EZ3TVVHKWDFKNN697DPFE7J6
drwxr-sr-x 3 1000 2000 68 Feb 22 05:00 01EZ41QJS6YM7SHX18RQHSTV8H
drwxr-sr-x 2 1000 2000 34 Feb 22 05:00 chunks_head
-rw-r--r-- 1 1000 2000 19.5K Feb 22 06:58 queries.active
drwxr-sr-x 3 1000 2000 97 Feb 22 05:00 wal
/prometheus $
/prometheus $ du -sh 01EZ1FAVT6VZ7GQ2RKNZRFK47Z
25.5M 01EZ1FAVT6VZ7GQ2RKNZRFK47Z
/prometheus $
/prometheus $ du -sh 01EZ1P6K16BXJQJDFF008VKVZ1
25.4M 01EZ1P6K16BXJQJDFF008VKVZ1
/prometheus $最新写入的2 小时数据保存在内存中
最新写入的数据保存在内存block中,达到2小时后写入磁盘,计算2小时写入数据大小,决定出内存的大小。
数据大内存问题
随着规模变大,Prometheus 需要的 CPU 和内存都会升高,内存一般先达到瓶颈,这个时候要么加内存,要么集群分片减少单机指标。这里我们先讨论单机版 Prometheus 的内存问题。
原因:
- Prometheus 的内存消耗主要是因为每隔2小时做一个 Block 数据落盘,落盘之前所有数据都在内存里面,因此和采集量有关。
- 加载历史数据时,是从磁盘到内存的,查询范围越大,内存越大。这里面有一定的优化空间。
- 一些不合理的查询条件也会加大内存,如 Group 或大范围 Rate。
200 台 45万样本数据 2小时 60G数据,内存6G
如何防止断电程序崩溃数据丢失
为了防止程序崩溃导致数据丢失,采用WAL(write-ahead-log)预写日志机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
未落盘时数据存储内容。有wal文件
./data/01BKGV7JBM69T2G1BGBGM6KB12
./data/01BKGV7JBM69T2G1BGBGM6KB12/meta.json
./data/01BKGV7JBM69T2G1BGBGM6KB12/wal/000002
./data/01BKGV7JBM69T2G1BGBGM6KB12/wal/000001数据存储方式
落盘后的数据内容,wal文件删除,生成index, tombstones(删除数据的记录),数据文件00001
./data/01BKGV7JC0RY8A6MACW02A2PJD
./data/01BKGV7JC0RY8A6MACW02A2PJD/meta.json
./data/01BKGV7JC0RY8A6MACW02A2PJD/index
./data/01BKGV7JC0RY8A6MACW02A2PJD/chunks
./data/01BKGV7JC0RY8A6MACW02A2PJD/chunks/000001
./data/01BKGV7JC0RY8A6MACW02A2PJD/tombstones这些2小时的block会在后台压缩成更大的block,数据压缩合并成更高level的block文件后删除低level的block文件。这个和leveldb、rocksdb等LSM树的思路一致。
数据过期清理时间,默认保存15天
存储数据的目录,默认为data/,如果要挂外部存储,可以指定该目录
删除数据方式
删除数据时,删除条目会记录在独立的tombstone 删除记录文件中,而不是立即从chunk文件删除。
本地存储的缺点
首先是数据持久化的问题,默认保存15天,原生的TSDB对于大数据量的保存及查询支持不太友好 ,所以并不适用于保存长期的大量数据;另外,该数据库的可靠性也较弱,在使用过程中容易出现数据损坏等故障,且无法支持集群的架构。
2.远程存储
为了解决本地存储缺点,Prometheus提供了remote_write和remote_read的特性,支持将数据存储到远端和从远端读取数据的功能。当配置remote_write特性后,Prometheus会将采集到的指标数据通过HTTP的形式发送给适配器(Adaptor),由适配器进行数据的存入。而remote_read特性则会向适配器发起查询请求,适配器根据请求条件从第三方存储服务中获取响应的数据。
配置
配置非常简单,只需要将对应的地址配置下就行
remote_write:
- url: "http://localhost:9201/write"
remote_read:
- url: "http://localhost:9201/read"社区支持
现在社区已经实现了以下的远程存储方案
- AppOptics: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Graphite: write
- InfluxDB: read and write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- SignalFx: write
influxdb简介
InfluxDB是业界流行的一款时间序列数据库,其使用go语言开发。InfluxDB以性能突出为特点,具备高效的数据处理和存储能力,目前在监控和IOT 等领域被广泛应用。
产品具有以下特点:
- 自定义的TSM引擎,数据高速读写和压缩等功能。
- 简单、高性能的HTP查询和写入API。
- 针对时序数据,量身打造类似SQL的查询语言,轻松查询聚合数据。
- 允许对tag建索引,实现快速有效的查询。
- 通过保留策略,可有效去除过期数据。
与传统关系数据库的名词对比:
| influxDB | 传统关系数据库 |
| database | database |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
安装信息:Downloads
参考信息:Prometheus监控运维实战十六: 远程存储_运维老兵Alex的技术博客_51CTO博客
高可用 Prometheus:问题集锦 | Vermouth | 博客 | docker | k8s | python | go | 开发