开源 | ViT模型结构分析及自动压缩加速!
作者 | 吕梦思 编辑 | 极市平台
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心技术交流群
后台回复【transformer综述】获取2022最新ViT综述论文!
导读
本文以ViT这一典型的Transformer模型为例,为大家介绍使用低成本、高收益的AI模型自动压缩工具(ACT, Auto Compression Toolkit)。
Transformer模型及其变体,因其更优的注意力机制能力和长时依赖等特性,已成为自然语言处理 (NLP)、语音识别 (ASR)、计算机视觉 (CV)等领域的主流序列建模结构。根据Paper With Code网站Object Detection on COCO test-dev专栏数据,检测任务中Transformer类模型精度早已超越卷积类模型,然而,Transformer模型的体积和速度相比卷积网络却存在很大的劣势,限制了其在产业上的应用。
本文以ViT这一典型的Transformer模型为例,为大家介绍使用低成本、高收益的AI模型自动压缩工具(ACT, Auto Compression Toolkit)。ACT无需修改训练源代码,调用两行压缩API,通过几十分钟量化训练,保证模型精度的同时,极大的减小模型体积,降低显存占用,提升模型推理速度,助力AI模型的快速落地。使用ACT工具压缩ViT模型,通过几十分钟量化训练,模型体积即可减小3.93倍。在GPU上,INT8推理速度相比FP32推理速度提升7.1倍。
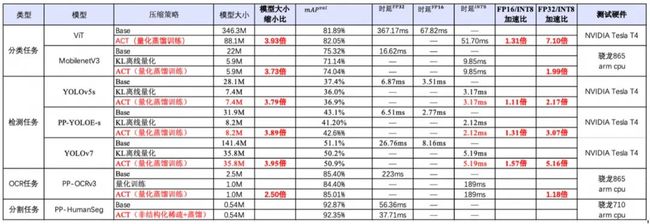
注:ViT模型和分割任务模型测速batch_size=40,其他模型测速batch_size=1
本文将从以下五个方面进行讲解:
ViT模型分析
ViT压缩策略介绍
ViT自动化压缩
ViT推理优化
未来工作展望
开源项目地址:https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/
一、ViT模型分析
本节首先对ViT模型结构进行简单介绍,然后对各个模块的计算量进行分析,以确定压缩的重点。
1.1 ViT模型结构分析
ViT 使用标准的 Transformer 结构替代传统的卷积操作,将图像拆分为多个 patch 后再输入到 Transformer 中。对于一张3x224x224大小的输出图片,首先会被分成14x14个patch,每个patch的大小为3x16x16,每个patch都使用一个768x3x16x16的卷积核进行特征提取,生成1x1x768的特征图,整个图片经过卷积之后得到的特征大小为1x14x14x768,再对特征进行维度展开,得到1x196x768的特征。借鉴NLP场景,在每个图片的特征前引入一个CLS字段的特征,来帮助模型进行分类。最终得到完整的特征是1x197x768维度,197对应的是NLP场景中的每个句子的token数量,768对应的是NLP场景中每个token的维度。接下来这些特征就可以直接输入到后续堆叠的Transformer Encoder结构中。如下图所示:
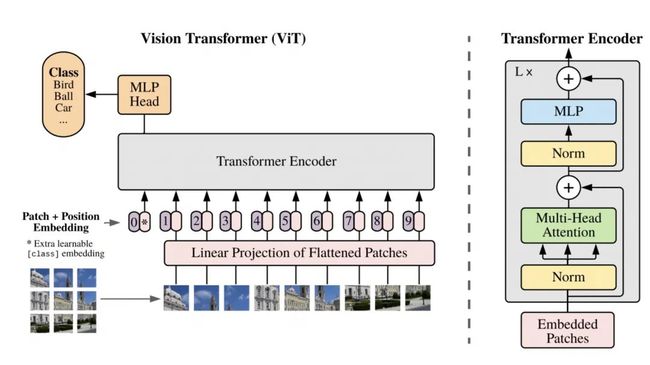
注:图片来自ViT论文[5]
Transformer Encoder结构是由一个MultiHead Self-Attention(简称MSA)和一个MLP组成。MSA中包含六个矩阵乘计算,其中四个全连接层对MSA不同部分的特征进行特征映射或特征融合,两个Batch GEMM和一个softmax算子表示特征的自注意力机制。MLP是由一个GeLU非线性层和两个全连接线性层组成。整个Transformer Encoder结构如下图所示:
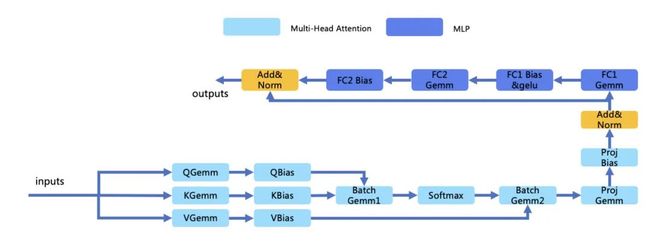
1.2 ViT模型计算量分析
再来分析下Transformer Encoder每一个模块对应的计算量,方便后续对各个模块进行压缩。从上图可以看出在整个Transformer Encoder中,在整个模型中,大部分计算量在于矩阵乘计算,所以接下来着重分析每个模块的矩阵乘计算量。
MSA计算公式如下:

其中, 表示 QKV 三个矩阵乘的参数, 代表每个 patch 映射到的特征维度, 对应上图中 Batch GEMM1, 表示图片有多少个 patch, Av 对应上图中的 Batch GEMM2, MSA(z) 计算公式对应的是上图中的 Proj GEMM, 表示 head 数量。
MLP计算公式如下:

MLP在计算过程中对特征维度进行了扩展,利用 和 两个参数特征扩展,所以MLP中每个矩阵乘的计算量是MSA中每个矩阵乘的计算量的4倍。
每个矩阵乘在整个Transformer Encoder矩阵乘计算量占比如下图所示:
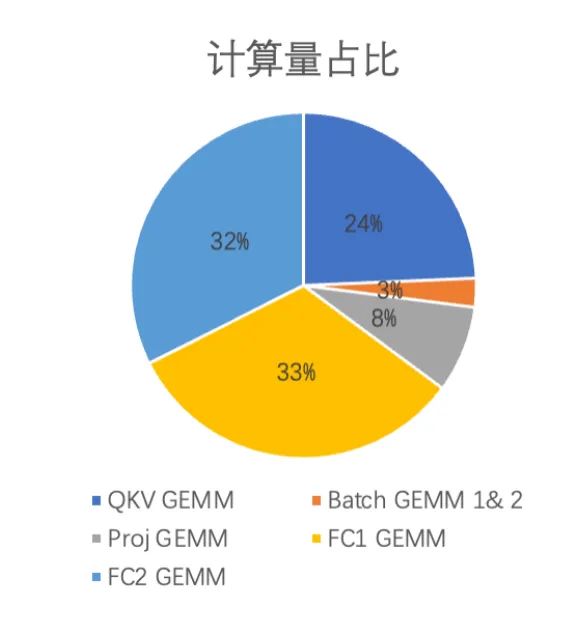
如图所示,QKV GEMM、FC1 GEMM以及FC2 GEMM的矩阵乘计算量占比总和达到89%,所以后续重点介绍如何压缩这些矩阵乘。
二、ViT压缩策略解析
型压缩中最常用的技术包括量化、剪枝、知识蒸馏和神经网络搜索。压缩ViT模型主要用到量化、剪枝和知识蒸馏,自动压缩技术主要使用这三种方法来对ViT模型进行整体压缩,在保证压缩模型精度的前提下,减小模型体积并带来实际的推理加速。本章节简单的介绍这三个方法的原理,主要介绍如何把这些方法应用在ViT模型上。
2.1 量化
量化本质上就是用低比特数值存储计算代替高精度数值存储和计算,来达到节省显存和加速计算的目的。在本案例中,量化主要针对最开始的卷积、MSA中QKV三个矩阵乘、Proj矩阵乘和MLP中的两个矩阵乘。
量化包括离线量化和量化训练两种方式。
离线量化只需要一些校准数据,收集模型中间的激活值,用一些离线量化策略来处理收集到的激活值,得到量化映射参数。然而,对一些模型进行离线量化会造成一定的精度损失,因此,有一些研究专门针对ViT这种特殊结构的模型进行离线量化算法改进,例如利用attention map重要性机制来构造量化损失[1],或者利用log量化[2]等方式来对ViT模型进行量化,可以提升量化后模型的精度或者把模型量化到更低比特。
量化训练需要构建量化模型,使用训练数据微调模型,得到训练后的量化模型,这种方式相比离线量化通常会有更优的精度。有一些研究针对ViT结构来做量化训练,例如根据MSA的特性把量化参数和量化比特数都作为可学习的参数参与整体量化模型训练[6],把ViT模型量化到更合适的比特数。
2.2 剪枝
剪枝是指直接减掉模型的参数维度,直接减少了计算量,达到降低显存和加速的目的。剪枝包括非结构化剪枝、半结构化剪枝和结构化剪枝。其中,非结构化剪枝和半结构化剪枝需要推理库的特殊支持,例如针对1x1卷积的非结构化剪枝,PaddleSlim联合Paddle Lite对其进行了特殊优化,在精度无损的情况下带来实际的加速。英伟达针对安培架构ASP稀疏也实现了特殊的推理。因此,对于非结构化剪枝和半结构化剪枝如果没有推理优化,很难有实际的加速。
为了保证压缩后的模型在任一硬件和任一推理库上都有实际的推理加速,建议选择结构化剪枝,减掉参数量就是实际减少的计算量,无需推理库特殊的支持。
和量化类似,我们选择对ViT中计算量大的矩阵乘进行剪枝,可选的剪枝策略也比较多,这里主要介绍结构化剪枝,例如对ViT模型构造剪枝空间[3],对剪枝空间中可调整的部分进行重要性排序,迭代式的进行结构化剪枝,得到最终的剪枝模型。
2.3 蒸馏
蒸馏主要是把精度较高、复杂度较高的模型的信息传递给精度较低、复杂度较低的模型,从而提升小模型的精度。相比大模型,蒸馏后的模型在保证模型精度的前提下降低了模型的复杂度。
最早针对ViT进行蒸馏的DeIT[4]在学生模型中,通过在刚开始引入一个可学习的蒸馏标识符来学习教师模型的输出,用蒸馏标识符和ViT模型本身引入的分类标识符同时来优化学生模型,达到蒸馏的目的。
三、对ViT模型进行自动压缩
上一章介绍了ViT模型进行压缩时主要用到的策略,本章节介绍如何使用ACT工具通过配置文件配置压缩策略,实现ViT模型的自动压缩。
3.1 准备待压缩模型
准备待压缩的部署模型。可以通过从PaddleClas套件模型库、自动压缩repo中获得待压缩的ViT模型,也可以自己训练好ViT模型。
3.2 准备数据读取模块
在对ViT模型进行自动化压缩的过程中,我们可以直接复用飞桨图像分类套件PaddleClas中相应的数据读取模块。
from ppcls.data import build_dataloader
data_config = config.get_config(global_config['reader_config'], show=False)
train_loader = build_dataloader(data_config["DataLoader"], "Train", device)3.3 定义策略配置文件
3.3.1 策略自动组合
自动化压缩工具提供的压缩策略有很多,可以在配置文件中指定。自动压缩工具会对这些配置进行自动组合,得到最终的组合压缩策略。以下内容会介绍如何在配置文件中指定压缩策略。
策略组合一:量化蒸馏训练配置
本节使用ACT中的量化训练和蒸馏训练对ViT进行量化,量化位置主要为卷积层、MSA中的全连接层和MLP中的全连接层,减少模型显存的同时加速矩阵乘的计算速度。
在进行量化训练或者剪枝训练的时候需要有损失优化信息来反向传播优化模型参数,而ACT主要压缩的推理模型是不包含原始的损失优化信息,所以ACT中选择使用蒸馏来监督压缩后模型进行优化训练,用压缩前模型的隐藏层特征来监督压缩后模型的隐藏层特征,从而实现模型的训练。
ACT量化配置如下:
Distillation: #蒸馏
node: softmax_12.tmp_0
QuantAware: #量化
use_pact: true
onnx_format: true
quantize_op_types: [conv2d, matmul_v2]参数含义如下:
Distillation 表示使用蒸馏
node 参数表示使用的蒸馏结点,这里选择的ViT网络结构最后输出的softmax输出结点作为蒸馏节点
QuantAware 表示使用量化训练的压缩策略,量化op选择 conv2d和matmul_v2即可表示量化整个ViT模型中的卷积和全连接层
use_pact 为是否使用PACT量化
onnx_format 量化后的模型如果想转为ONNX格式,需要设置onnx_format为true。
策略组合二:策略剪枝蒸馏训练
ACT提供了Transformer通道数剪枝,主要是对MSA中的head数量、全连接层和MLP中的全连接层进行参数裁剪。剪枝逻辑为在剪枝前对模型进行head重要性排序和参数重要性排序,然后根据传入的剪枝比例对相应位置进行裁剪,得到剪枝后的模型。同样的,剪枝训练也需要结合蒸馏使用。ViT模型主体结构是Transformer,所以也可以使用ACT提供的Transformer通道数剪枝方案进行剪枝(目前还在适配中,可能您读到这篇推文或者看到直播的时候已经可以使用啦)。可以先看下应该如何设置对应的ACT剪枝配置:
Distillation:
node: softmax_12.tmp_0参数含义如下:
Distillation表示使用蒸馏
node参数表示使用的蒸馏结点
TransformerPrune表示使用Transformer剪枝策略进行剪枝
pruned_ratio为剪枝比例,本方案设为25%,您的可以根据需要自行设置。
剪枝和量化压缩是两种交互使用的压缩策略,最优的方式是串行使用这两种压缩策略,当然也可以单独使用。
3.3.2 策略自动选择
针对ViT模型,如果没有指定具体的压缩策略(即3.3.1没有确定压缩策略 ),在剪枝已经支持的情况下会先对模型进行结构化剪枝,再对剪枝后的模型进行量化,从而得到最终优化后的模型。在剪枝没有支持的情况下会自动选择量化的策略进行模型压缩。
完整的ViT自动压缩量化压缩配置文件请查看:https://github.com/PaddlePaddle/PaddleSlim/blob/develop/example/auto_compression/image_classification/configs/VIT/qat_dis.yaml
3.3 两行核心自动压缩代码
启动ACT时,需要传入模型文件的路径(model_dir)、模型文件名(model_filename)、参数文件名称(params_filename)、压缩后模型存储路径(save_dir)、压缩配置文件(config)、dataloader和评估精度的eval_callback参数。
ac=AutoCompression(model_dir=global_config['model_dir'],
model_filename=global_config['model_filename'],
params_filename=global_config['params_filename'],
save_dir=args.save_dir,
config=all_config,
train_dataloader=train_dataloader,
eval_callback=eval_function if rank_id==0 else None,
eval_dataloader=eval_dataloader)
ac.compress()四、 ViT推理优化
服务器推理引擎Paddle Inference团队对ViT模型的推理进行了一些特殊优化,来进一步提升压缩后模型的推理速度。主要包括以下四种:
算子融合:对于一些常用算子进行算子融合,减少整个模型算子的个数,加快模型的推理。算子融合规则如下图所示:
灵活使用TensorRT推理库:在输入图像较小的情况下,attention部分的计算可以利用TensorRT高性能推理库,采用预置策略,在保证性能的同时兼容易用性。
基于硬件特性调优:在输入图像较大的情况下,attention部分的计算需要进行一些其他优化,由于大部分硬件是对8的倍数的矩阵乘有着更优的计算性能,所以在模型计算过程中会把attention部分的计算逻辑padding到8的倍数来进一步提升矩阵乘的性能,引入的padding算子也和transpose算子进行了算子融合,在保证性能的前提下增加attention部分的灵活性。
实现高效计算算子:另外也根据显卡特性比如向量化,开发更加高效的计算kernel来加速整个ViT模型的推理。
参考文献
[1] Post-Training Quantization for Vision Transformer
[2] FQ-ViT: Post-Training Quantization for Fully Quantized Vision Transformer
[3] NViT: Vision Transformer Compression and Parameter Redistribution
[4] Training data-efficient image transformers & distillation through attention
[5] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[6] Q-ViT: Fully Differentiable Quantization for Vision Transformer
往期回顾
DETR系列大盘点 | 端到端Transformer目标检测算法汇总!

【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称
自动驾驶之心【知识星球】
想要了解更多自动驾驶感知(分类、检测、分割、关键点、车道线、3D目标检测、多传感器融合、目标跟踪、光流估计、轨迹预测)、自动驾驶定位建图(SLAM、高精地图)、自动驾驶规划控制、领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球(三天内无条件退款),日常分享论文+代码,这里汇聚行业和学术界大佬,前沿技术方向尽在掌握中,期待交流!
