爬虫
初识爬虫:
利用requests模块来编写第一个简易爬虫:
import requests
#要爬取的网页的链接
url = 'https://www.sogou.com'
#response来接受得到的网页的内容
response = requests.get(url = url)
#将内容转换成文本
page_text = response.text
#永久储存
with open('D:\test.html', 'w', encoding = 'utf-8') as f:
f.write(page_text)
print(fileName, "爬取完毕")
上述是第一个简单的爬虫,现在我们在爬取另外一个网页。下一个网页是爬取我女神林允儿的网页。
但有两个问题:
-
出现了乱码
-
提示要输入验证码
这里其实就涉及到了反爬虫措施UA
import requests
#爬取搜索了关键字的网页
url = 'https://www.sogou.com/web?query=林允儿'
#response来接受得到的网页的内容
response = requests.get(url = url)
#这里就解决了乱码问题,发现乱码,第一反应影响到编码错了
response.encoding = 'utf-8'
#将内容转换成文本
page_text = response.text
#永久储存
with open('D:\test.html', 'w', encoding = 'utf-8') as f:
f.write(page_text)
print(fileName, "爬取完毕")
解决了乱码问题,接下来就是反爬。
-网站后台会检验请求对应的User-Agent
什么是User-Agent?
是请求载体的身份标识
什么是请求载体?
浏览器:浏览器的身份标识是统一固定的,可以在抓包工具中看
爬虫程序:身份表示各不相同
解决UA反爬方法:
伪装一下User-Agent即可!
下面是获取UA的方法:
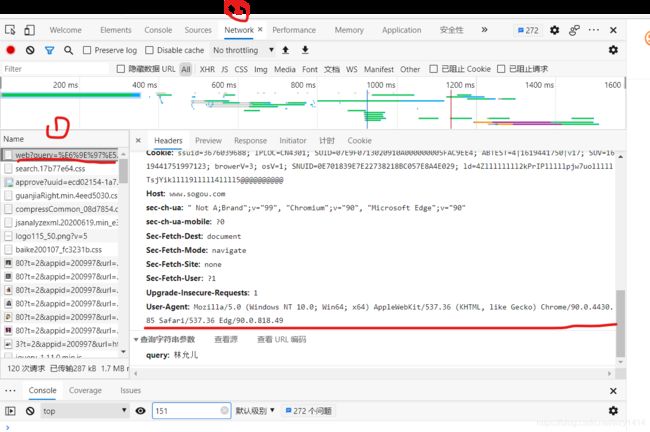
import requests
#爬取搜索了关键字的网页
url = 'https://www.sogou.com/web'
#输入要爬取的关键字
keyWord = input('输入要爬取的关键字:')
#可以在字符串参数中看到参数为query,后面的就是关键字
paramas = {
'query' = keyWord
}
#用字典来伪装头部UA,把copy来的UA赋值到字典中
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.46'
}
#response来接受得到的网页的内容
response = requests.get(url = url, params = params, headers = headers)
#这里就解决了乱码问题,发现乱码,第一反应应想到编码方式错了
response.encoding = 'utf-8'
#将内容转换成文本字符串
page_text = response.text
#永久储存
'''
其实还可以写一个fileName来动态化储存数据
fileName = 'D:\' + keyWord + '.html'
with open(fileName, 'w', encoding = 'utf-8') as f:
f.write(page_text)
'''
with open('D:\test.html', 'w', encoding = 'utf-8') as f:
f.write(page_text)
print(fileName, "爬取完毕")
怎么来获取动态加载的数据?
因为动态加载数据,所有网页中的信息会由其他包来进行请求,所有我们在URL所在的数据包中是看不到我们要查找的信息的。
如何确定是否是动态加载数据呢?
在捕获的URL数据包中查找是否由页面上的内容。
下面我们用豆瓣动作电影排行榜来进行学习
URL = 豆瓣电影分类排行榜 - 动作片 (douban.com)
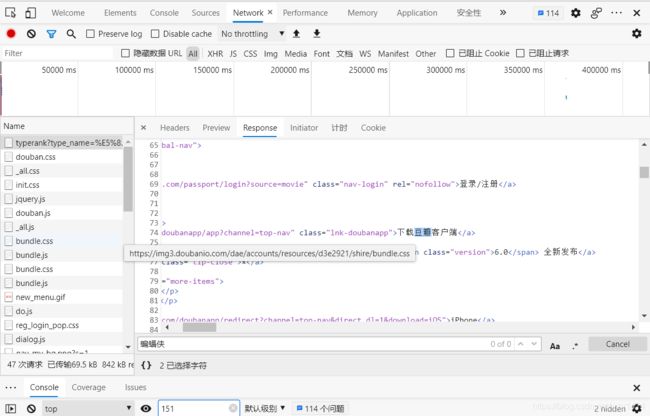
我们查找后发现没有蝙蝠侠的信息,说明这是动态加载的数据或加密的数据。
如何获取动态加载的数据呢?
我们随便点击①哪里的一个,都可以。然后按CTRL + F,然后就在全局搜索Search那输入信息,按下回车就找到了。
找到之后我们在去JSON解析器上解析。
解析器链接:JSON在线解析及格式化验证 - JSON.cn
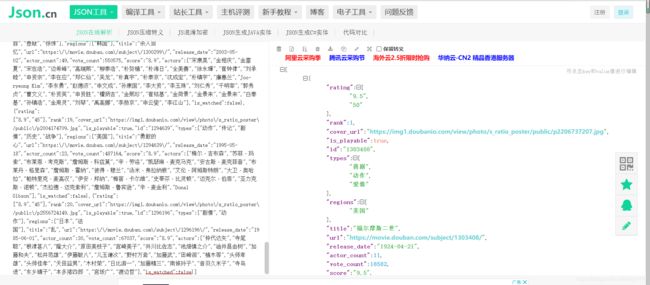
解析后就可以看到里面的信息。
接下来我们可以开始爬取了。
import requests
#在我们刚才找到的数据包中查看URL,把问号后面的都删掉,因为都是参数
url = 'https://movie.douban.com/j/chart/top_list'
#伪装UA
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
#获取参数
params = {
'type' : '5',
'interval_id' : '100:90',
'action' : '' ,
'start' : '0', #通过修改这些数据,我们发现 start 代表从第几部开始
'limit' : '20', # limit 代表获取多少部电影
}
#查看请求方式,发现是get,其实这个应该在参数之前弄,如果是post,则前面params改成data
response = requests.get(url = url, params = params, headers = headers )
#.json()将获取的字符串形式的json数据序列化成字典或列表
page_text = response.json()
#循环遍历获取的信息,电影名称 + 评分,这些信息可以在刚刚解析的数据中查看,看它在哪一部分
for movie in page_text:
name = movie['title']
score = movie['score']
print(name, score)
好b( ̄▽ ̄)d ,解决了动态加载数据的问题(后面还有动态加载+加密)(大家一定要自己尝试写,没思路的时候看看我的注释,爬虫就是多试,经验多的人试的少,经验少的人试的多,所以多尝试这样才能以后犯更少的错误),我们再来看看怎么分页爬取数据。
分页爬取
我们这次爬取KFC餐店查询,URL = 肯德基餐厅信息查询 (kfc.com.cn)
这次会涉及到另一个知识点ajax,即用户获取信息时,不需要重载整个网页,只需要更新部分。
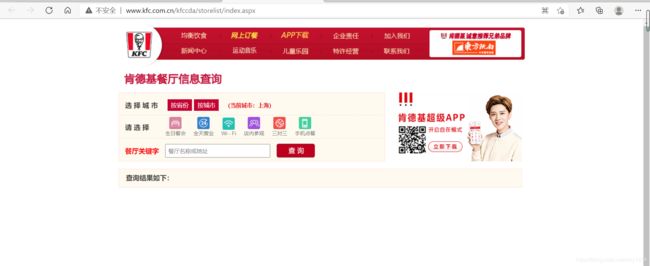
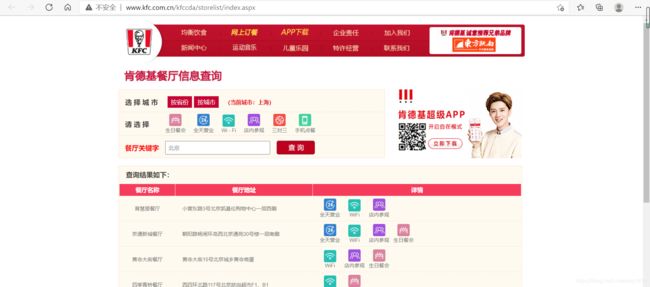
我们发现查询北京地区的信息后,url并没有改变,说明就是查询北京时发起的是一个ajax请求。
分析:
- 请求的URL
- 请求方式
- 请求携带参数
- 响应数据
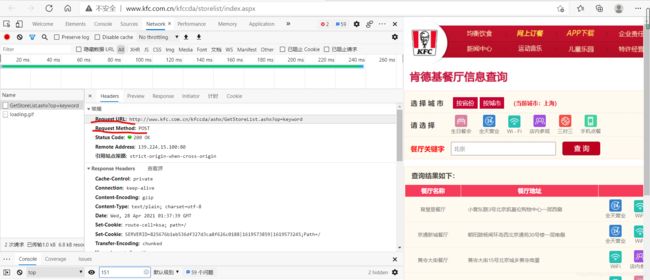
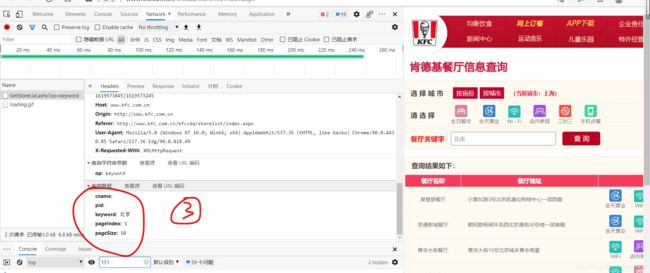
响应数据就在response那,可自行查看,然后去json在线解析器上解析
import requests
#在我们刚才找到的数据包中查看URL,这里不用删除?后面的内容,因为我们发现参数里没有op,所以这个就要带上
#这也是要注意的一个地方,自己也可以试一试,实践出真知,也记得更牢固
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
#伪装UA
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
#我们发现分页就是pageIndex那改变了,所以那里改成动态参数就行了
for page in range(1,10):
#获取参数,我们发现请求方式是post,所以这里得改
data = {
'cname' : '',
'pid' : '',
'keyword' : '北京',
'pageIndex' : str(page), #这里得注意呀,page是个整数常量
'pageSize' : '10'
}
#!!!(这个是要注意的)查看请求方式,发现是post,post的参数表单是 data
response = requests.post(url = url, data = data, headers = headers )
#.json()将获取的字符串形式的json数据序列化成字典或列表
page_text = response.json()
#循环遍历获取的信息,店名 + 地址
for dic in page_text['Table1']:
storeName = dic['storeName']
addre = dic['addressDetail']
print(storeName, addre)
接下来我们可以爬一下药监总局,大家可以自己尝试一下,爬取首页的每个公司的详细信息,这是一个很好的例子,希望大家动手试试。
URL = 化妆品生产许可信息管理系统服务平台 (nmpa.gov.cn)
这是首页的公司大略信息:
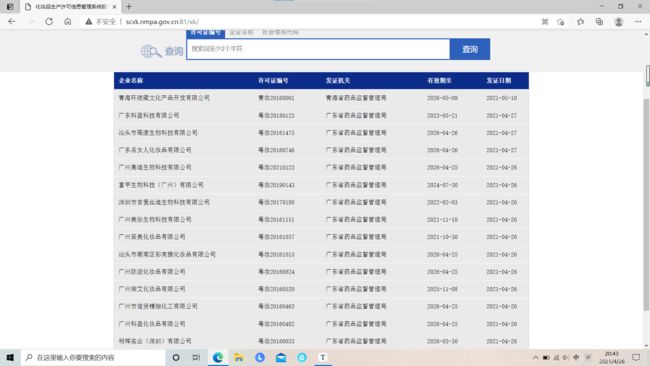
我们要爬取的是点击公司进去之后的信息:
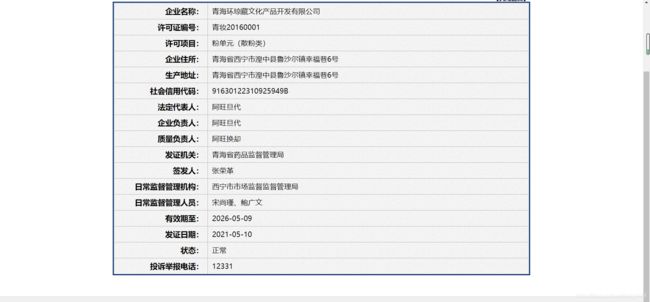
尝试一下,爬取首页的每个公司的详细信息,这是一个很好的例子,希望大家动手试试。
这些用我们刚才学到的方法足够爬取。
代码如下:
import requests
url = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsList'
#UA伪装
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
# post请求
data = {
'on' : 'true',
'page' : '1',
'pageSize' : '15',
'productName' : '',
'conditionType' : '1',
'applyname' : '',
'applysn' : ''
}
#获取网页信息
response = requests.post(url = url, data = data, headers = headers)
#序列化成字典或列表
page_text = response.json()
for company in page_text['list']:
Id = company['ID']
url_1 = 'http://scxk.nmpa.gov.cn:81/xk/itownet/portalAction.do?method=getXkzsById'
data = {
'id' : Id
}
response = requests.post(url = url_1, data = data, headers = headers)
message = response.json()
#for message in company_text_1:
epsName = message['epsName']
productSn = message['productSn']
certStr = message['certStr']
epsAddress = message['epsAddress']
epsProductAddress = message['epsProductAddress']
businessLicenseNumber = message['businessLicenseNumber']
legalPerson = message['legalPerson']
businessPerson = message['businessPerson']
qualityPerson = message['qualityPerson']
qfManagerName = message['qfManagerName']
xkName = message['xkName']
rcManagerDepartName = message['rcManagerDepartName']
rcManagerUser = message['rcManagerUser']
xkDate = message['xkDate']
xkDateStr = message['xkDateStr']
print('企业名称:', epsName)
print('许可证编号:', productSn)
print('企业住所:', certStr)
print('生产地址:', epsAddress)
print('社会信用代码:', businessLicenseNumber)
print('法定代表人:', legalPerson)
print('企业负责人:', businessPerson)
print('质量负责人:', qualityPerson)
print('发证机关:', qfManagerName)
print('签发人:', xkName)
print('日常监督管理机构:', rcManagerDepartName)
print('日常监督管理人员:', rcManagerUser)
print('有效日期:', xkDate)
print('发证日期:', xkDateStr)
print('状态:正常')
print('投诉举报电话:12331')
爬虫之正则表达式 + bs4基础
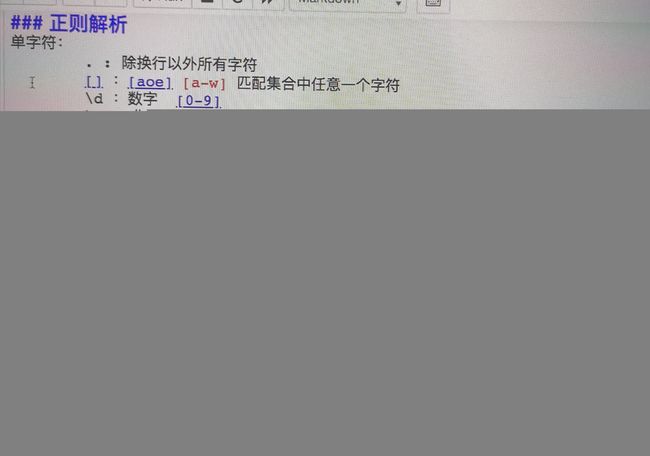
正则表达式应该都听说过,就是匹配文本内容的,大家可以看看用法python正则表达式_wzy1414的博客-CSDN博客
我们直接试一下吧,爬取校花网的图片,试了一下,不是动态加载的数据。
我们要爬取图片呢,肯定得知道图片的URL,我们检查元素,查询后发现,所有的图片链接都在li标签里面,所以我们只需要利用正则表达式获取li中img的src就行了
<li style="position: absolute; left: 0px; top: 0px;">
<a href="/tuku/1216.html" title="袁冰妍长发披肩笑容温柔 对手机整理刘海随时保持精致">
<img src="/d/file/p/2021/03-04/9e951567b427eade48156bd289effa42.jpg" alt="袁冰妍长发披肩笑容温柔 对手机整理刘海随时保持精致">
<p>袁冰妍长发披肩笑容温柔 对手机整理刘海随时保持精致p>
a>
li>
先来写一下正则表达式
ex = '<img src="(.*?)".*?>#获取的是()里面的内容
现在来编写代码
import requests
import re
import os
#利用os来进行文件的创建
dirName = 'ImgLibs'
if not os.path.exists(dirName):
os.mkdir(dirName)
url = 'http://www.521609.com/tuku/shz/'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
response = requests.get(url = url, headers = headers)
page_text = response.text
ex = ') '#获取的是()里面的内容
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
#我们发现我们获取的只是/d/file....这些,还不是完整的url
#我们可以复制图片链接,发现前面还有个前缀
#http://www.521609.com/d/file/p/2021/03-04/e79eb980349244d21f005a4bfb592e3d.jpg
src = 'http://www.521609.com' + src
#下面那个url = src如果写成了url = url还是会获得图片,但是打开时会说似乎不支持此格式,别问我怎么知道的,一定要注意细节。
response = requests.get(url = src, headers = headers)
#储存照片,得先转换成二进制数据
img_data = response.content #content返回的是二进制的数据
#这个是给每一个图片创建名字
img_name = dirName + '/' + src.split('/')[-1]
#要以‘wb’方式写入数据,‘wb’是写入二进制数据
with open(img_name, 'wb') as f:
f.write(img_data)
'#获取的是()里面的内容
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
#我们发现我们获取的只是/d/file....这些,还不是完整的url
#我们可以复制图片链接,发现前面还有个前缀
#http://www.521609.com/d/file/p/2021/03-04/e79eb980349244d21f005a4bfb592e3d.jpg
src = 'http://www.521609.com' + src
#下面那个url = src如果写成了url = url还是会获得图片,但是打开时会说似乎不支持此格式,别问我怎么知道的,一定要注意细节。
response = requests.get(url = src, headers = headers)
#储存照片,得先转换成二进制数据
img_data = response.content #content返回的是二进制的数据
#这个是给每一个图片创建名字
img_name = dirName + '/' + src.split('/')[-1]
#要以‘wb’方式写入数据,‘wb’是写入二进制数据
with open(img_name, 'wb') as f:
f.write(img_data)
数据解析的作用:
用来实现聚焦爬虫
网页中显示的数据都储存再哪
储存在 html 标签或标签的属性中
数据解析的通用原理是什么?
1.指定标签的定位
2.取出标签中储存的数据或标签属性中储存的数据
bs4基础
bs4解析原理:
- 实例化一个BeautifulSoup对象,然后把带解析的网页数据源码加载到该对象中
- 调用BeautifulSoup对象中的方法或属性进行标签的定位和数据的提取
BeautifulSoup(fp,'lxml'):用来将本地储存的html文档中的数据进行解析
BeautifulSoup(page_text,'lxml'):用来将从网页上获取的数据源码解析解析
form bs4 import Beautiful
#这里可以用自己电脑上的html文档
fp = open(fileName, 'r')
soup = BeautifulSoup(fp, 'lxml')
soup.tagName #打印第一个tagName标签(注意是第一个,后面的打印不了)
soup.find('tagName', attrName = 'value') #例如soup.find('div', class_ = 'menu'),因为class是关键字所以要加个_,soup.find('div', id = 'name')
soup.findAll和find类似,只不过findAll返回的是列表,即所有满足条件的标签,find只返回一个
soup.select('选择器'):
类选择器 . + 类 如:.menu
id选择器 # + id 如 #menu
层级选择器
> 表示一级
空格 表示多级
现在来用bs4实战一下:爬取三国演义:《三国演义》全集在线阅读_史书典籍_诗词名句网 (shicimingju.com)
思路是先爬取首页的所有文章的链接,然后再爬取每个链接中的信息

import requests
from bs4 import BeautifulSoup
#首页链接
main_url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
response = requests.get(url = main_url, headers = headers)
#一开始没有改编码结果错了,所以以后若是遇到乱码问题先试试改一下编码
response.encoding = 'utf-8'
page_text = response.text
#实例化一个BeautifulSoup对象
soup = BeautifulSoup(page_text, 'lxml')
#我们发现文本的链接都在类为.book-mulu > ul > li > a 的herf里面
url_list = soup.select('.book-mulu > ul > li > a')
#储存在一个文件里
fp = open('D:\sanguoyanyi.txt', 'w', encoding = 'utf-8')
for a in url_list:
#文章的标题
title = a.string
#取出 a 标签里的 herf 属性,还得加上前缀才是完整的 url
url = 'https://www.shicimingju.com' + a['href']
response = requests.get(url = url, headers = headers)
response.encoding = 'utf-8'
page_text_detail = response.text
#重新实例化一个对象
soup = BeautifulSoup(page_text_detail, 'lxml')
div_tag = soup.find('div', class_ = 'chapter_content')
content = div_tag.text
fp.write(title + ':' + content + '\n')
print(title, '爬取完毕')
fp.close()
xpath解析
环境安装:pip install lxml
解析原理:html是以树状的形式进行展示
- 实例化一个etree的对象,且将带解析的页面源码数据加载到该对象中
- 调用etree对象的xpath方法结合着不同表达式实现标签的定位与数据提取
实例化一个etree对象
- -etree.parse(‘fileName’):将本地html文档加载到该对象中
- -etree.HTML(page_text):网站获取的页面数据加载到该对象中
from lxml import etree
-标签定位
tree = etree.parse('fileName')
tree.xpath('/html/head/meta') #定位到meta
tree.xpath('/html//meta') #定位到meta
tree.xpath('//meta') #定位到meta
-最左侧的 /:如果xpath表达式最左侧是以/开头,则表示xpath表达式一定要从更标签开始,即html标签 (一般不用)
-非最左侧 /:表示一个层级
-非最左侧 //:表示多个层级
-最左侧 //:xpath表达式可以从任意位置进行标签定位
-属性定位:tagName[@attrName = 'vaule']
#如定位class为song的div下面的所有的p
tree.xpath('//div[@class = "song"]/p')
-索引定位:tag/[index]:索引是从1开始
#如定位class为song的div下面的第一个p
tree.xpath('//div[@class = "song"]/p[1]')
#模糊匹配:
-//div[contains(@class,"ng")] class中含有ng的div
-//div[starts-with(@class,"ta")] class属性中以ta开头的div
-取文本
-/text():直系文本内容
tree.xpath('//div[@class = "song"]/p[1]/text()')
-//text():所有的文本内容
tree.xpath('//div[@class = "song"]/p[1]//text()')
-取属性
-/@attrName
tree.xpath('//a[@id = "feng"]/@href') 取出id为feng的a标签里的href属性
现在我们来爬取一个网站:4K美女壁纸_高清4K美女图片_彼岸图网 (netbian.com)(小姐姐图片无所谓,主要是网站好趴doge)
这个网站不是动态加载数据,所以可以直接再elements中查看元素来进行属性的定位
import requests
from lxml import etree
import os
#创建储存的文件夹
dirName = 'GirlsLib'
if not os.path.exists(dirName):
os.mkdir(dirName)
#我们发现页面的url大体相同,所以就用format来进行补充
url = 'https://pic.netbian.com/4kmeinv/index_%d.html'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36 Edg/90.0.818.49'
}
for page in range(1,6):
#首页没有数字
if page == 1:
new_url = 'https://pic.netbian.com/4kmeinv/index.html'
else:
new_url = format(url) % page
response = requests.get(url = new_url, headers = headers)
#试了下utf-8,发现不行,那么就换一个,编码就这几个,不行就换
response.encoding = 'gbk'
page_text = response.text
#创建一个etree对象
tree = etree.HTML(page_text)
#获取图片对应的li标签
li_list = tree.xpath('//div[@class = "slist"]/ul/li')
#下面是进行局部数据的提取,提取局部数据时,就不能用 // ,得用 ./ (这个要注意)
for li in li_list:
#注意xpath表达式返回的总是列表,所以即使只有一个元素也得带上下表[0]
title = li.xpath('./a/img/@alt')[0] + '.jpg' #图片名称
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
#图片要用二进制来写入
img_data = requests.get(url = img_src, headers = headers).content
imgPath = dirName + '/' + title
with open(imgPath,'wb') as f:
f.write(img_data)
print(title, '保存成功!!!')
如何让xpath具有通性?
使用管道赋 | ,在xpath()中使用就行,例如 xpath(’//div/ul’ | ‘//table/td’)
下面继续来爬取网站练练手
丝袜美女图片 -丝袜美女图片大全 (chinaz.com)
这个涉及到一个反爬机制——图片懒加载,大家可以先自己试一下。

可以看到第一张图片是src,而后面的图片是src2,但是img标签中只会对src链接发出请求,所以src2是一个伪属性,只有当图片被显示在浏览器的可观察范围内,伪属性才会变成真正的属性。所以当你向下滑看到图片时,它的src2就变成了src。
所以我们爬取时就不能写@src,而是写@src2
import requests
from lxml import etree
#创建储存的文件夹
dirName = 'GirlsLib'
url = 'https://sc.chinaz.com/tupian/siwameinvtupian_%d.html'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
for page in range(1,7):
if page == 1:
new_url = 'https://sc.chinaz.com/tupian/siwameinvtupian.html'
else:
new_url = format(url) % page
response = requests.get(url = new_url, headers = headers)
response.encoding = 'utf-8'
page_text = response.text
#实例化一个etree对象
tree = etree.HTML(page_text)
img_list = tree.xpath('//div[@id = "container"]//a/img')
for img in img_list:
title = img.xpath('./@alt')[0] + '.jpg'
#注意这个伪属性
img_url = 'https:' + img.xpath('./@src2')[0]
img_data = requests.get(url = img_url, headers = headers).content
imgPath = dirName + '/' + title
with open(imgPath, 'wb') as f:
f.write(img_data)
print(title, '保存完毕!!!')
前面学过的反扒机制:
-
robots协议(防君子不防小人的协议)
-
UA伪装
-
动态加载数据捕获
-
图片懒加载
接下来我们继续学习其他的反爬机制
cookie
cookie是储存在用户本地终端的数据
web中cookie的典型应用:
- 免密登录
cookie和爬虫之间的关联:
有时候对一张页面进行请求时,如果请求过程中不携带cookie的话,那么我们是无法请求到正确的页面数据。因此cookie是爬虫中一个典型且常见的反爬机制。
cookie处理方式:
方式一:手动处理
- 将抓包工具中的cookie粘贴在headers中
- 弊端:cookie过期了就没用了
方式二:自动处理
-
基于Session对象实现自动处理
-
如何获取一个Session对象:requests. Session()返回一个session对象
-
session对象的作用:
该对象可以和requests一样发送get和post请求。如果请求过程中产生了cookie,那么cookie将会存储在session对象中,这就意味着下次请求时将会携带着cookie
-
在爬虫中使用session的时候,session对象至少被调用两次:
一次是为了将cookie存储在session对象中,另一次是为了携带着cookie发送请求
import requests
from lxml import etree
#创建一个Session对象
session = requests.Session()
#第一次调用session对象,获取最新的cookie
main_url = 'https://xueqiu.com/'
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
session.get(url = main_url, headers = headers)
#后续请求时就会带上cookie
url = 'https://xueqiu.com/statuses/hot/listV2.json?since_id=-1&max_id=199609&size=15'
page_text = session.get(url = url, headers = headers).json()
print(page_text)
IP代理
IP代理就在自己的IP因为高频的爬取网页而被封了之后,使用其他的代理服务器进行访问网页,从而再次爬取网页。
我试了一个网站,爬崩了它也没封我的IP,所以这个以后再演示
验证码识别登录
这里推荐超级鹰(因为它可以识别12306的验证码),其实也可以用百度云AI来识别,但还有点难度,以后再说。
我们来爬取古诗文网站登录古诗文网 (gushiwen.cn),因为账号密码都是固定的,所以我们只需要注意验证码就行。
使用超级鹰:
- 创建一个账号
- 没有积分的话充值1块,尝试阶段1块够了
- 然后下载开发文档,选择python版,里面给你包装好了一个类,但还要自己改一下
- 还要创建一个软件ID
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#这里是自己把上面一部分修改了一下
def transformImgCode(ImgPath, ImgType):
#这里填自己的
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID')
im = open(ImgPath, 'rb').read()
#识别出的验证码在字典里,所以我们只需要提取出pic_str就行
return chaojiying.PostPic(im, ImgType)['pic_str']
我们在登录页面打开检查,查看networks,然后进行登录,这时我们会捕获到一个login包
import requests
from hashlib import md5
from lxml import etree
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#这里是自己把上面一部分修改了一下
def transformImgCode(ImgPath, ImgType):
#这里填自己的
chaojiying = Chaojiying_Client('1414521825', '123456789', '916220')
im = open(ImgPath, 'rb').read()
#识别出的验证码在字典里,所以我们只需要提取出pic_str就行
return chaojiying.PostPic(im, ImgType)['pic_str']
#首先获取验证码的图片并识别出验证码
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
main_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
page_text = requests.get(url = main_url, headers = headers).text
tree = etree.HTML(page_text)
img_url = 'https://so.gushiwen.cn' + tree.xpath('//img[@id = "imgCode"]/@src')[0]
img_data = requests.get(url = img_url, headers = headers).content
with open('./code.jpg', 'wb') as f:
f.write(img_data)
#选择要识别的类型,可以在这看:http://www.chaojiying.com/price.html
code_text = transformImgCode('./code.jpg', 1902)
print(code_text)
#进行模拟登录
#我们捕获的那个login包
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
#我们发现是post请求,且带有参数
data = {
'__VIEWSTATE' : 'zHpMW8T3VcEjT9Dnv3ZrOpiqWMCUwnN7VBUNR1LRddGgAWsZGXg2vZ094PlG1MrjPLL9vrV8kiOj/5uELk3caOdVE4cZcTwCsb6vv8S/Wnle2DwyHeqsCS8yT6o=',
'__VIEWSTATEGENERATOR' : 'C93BE1AE',
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
'email' : '17375815229',
'pwd' : '123456789',
'code' : code_text,
'denglu' : '登录'
}
page_text_login = requests.post(url = login_url, headers = headers, data = data).text
with open('./gushiwen.html', 'w', encoding = 'utf-8') as f:
f.write(page_text_login)
但这串代码还是无法成功登录并提取信息
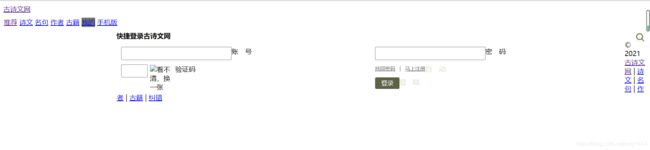
我们可以看到验证码并没有识别错误,那么我们可以试一试是不是cookie或者那两个意义不明的参数的问题
先试一试cookie把,前面讲过使用session对象即可
import requests
from hashlib import md5
from lxml import etree
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
#这里是自己把上面一部分修改了一下
def transformImgCode(ImgPath, ImgType):
#这里填自己的
chaojiying = Chaojiying_Client('用户名', '密码', '软件ID')
im = open(ImgPath, 'rb').read()
#识别出的验证码在字典里,所以我们只需要提取出pic_str就行
return chaojiying.PostPic(im, ImgType)['pic_str']
#首先获取验证码的图片并识别出验证码
#创建session对象
session = requests.Session()
headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
main_url = 'https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx'
#因为不知道cookie是在哪获得的,所以我们都试一下
page_text = session.get(url = main_url, headers = headers).text
tree = etree.HTML(page_text)
img_url = 'https://so.gushiwen.cn' + tree.xpath('//img[@id = "imgCode"]/@src')[0]
#也有可能是在访问验证码图片的时候获取cookie,所以这里也用session
img_data = session.get(url = img_url, headers = headers).content
with open('./code.jpg', 'wb') as f:
f.write(img_data)
#选择要识别的类型,可以在这看:http://www.chaojiying.com/price.html
code_text = transformImgCode('./code.jpg', 1902)
print(code_text)
#进行模拟登录
#我们捕获的那个login包
login_url = 'https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx'
#我们发现是post请求,且带有参数
data = {
'__VIEWSTATE' : 'zHpMW8T3VcEjT9Dnv3ZrOpiqWMCUwnN7VBUNR1LRddGgAWsZGXg2vZ094PlG1MrjPLL9vrV8kiOj/5uELk3caOdVE4cZcTwCsb6vv8S/Wnle2DwyHeqsCS8yT6o=',
'__VIEWSTATEGENERATOR' : 'C93BE1AE',
'from' : 'http://so.gushiwen.cn/user/collect.aspx',
#这里填自己的
'email' : '用户名',
'pwd' : '密码',
'code' : code_text,
'denglu' : '登录'
}
page_text_login = session.post(url = login_url, headers = headers, data = data).text
with open('./gushiwen.html', 'w', encoding = 'utf-8') as f:
f.write(page_text_login)
加了cookie后成功了,说明是没加cookie的问题
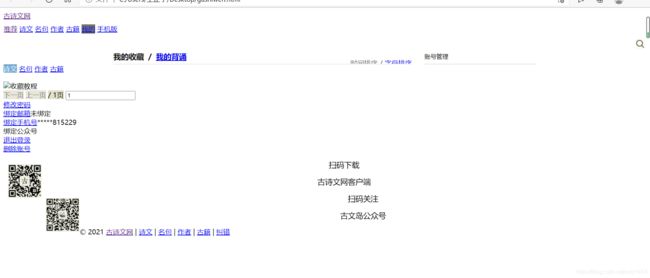
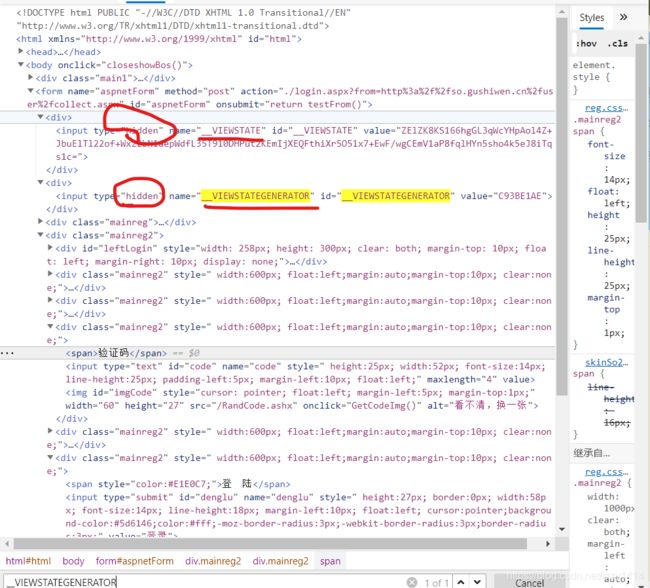
那么后面那两个参数是干嘛的呢?
我也不知道,但我猜测可能是以后网站升级后用来进行反爬的一种措施,但也有解决办法。
- 一般情况下,这些动态的参数数据可以在前台查看到,即elements中
- 还可以在动态加载数据中使用全局搜索来进行查找