用Python手把手教你理解Resnet的运行过程(全代码注释版,基于paddle)
简单粗暴直接上代码:
每一句都基本上有注释,具体的原理下面再解释~
代码流程:
def resnet(input): #resnet 101
def conv_bn_layer(input, num_filters, filter_size, stride=1, groups=1, act=None, name=None): #卷积conv
conv = fluid.layers.conv2d(input=input, #飞浆内部集成的函数,用以卷积运算
num_filters=num_filters, #卷积核数量
filter_size=filter_size, #卷积核尺寸
stride=stride #步长,即卷积核在矩阵上移动的步数
padding=(filter_size - 1) // 2, #扩充图片,在边缘增加大小为0的像素点,防止边缘信息丢失和图片尺寸变小
groups=groups, #组
act=None, #准确率
param_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
name=name + '.conv2d.output.1')
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
return fluid.layers.batch_norm(input=conv,
act=act,
name=bn_name + '.output.1',
param_attr=ParamAttr(name=bn_name + '_scale'),
bias_attr=ParamAttr(bn_name + '_offset'),
moving_mean_name=bn_name + '_mean',
moving_variance_name=bn_name + '_variance', )
def shortcut(input, ch_out, stride, name): #一种跨越方式,实现残差的工具
ch_in = input.shape[1]
if ch_in != ch_out or stride != 1:
return conv_bn_layer(input, ch_out, 1, stride, name=name)
else:
return input
def bottleneck_block(input, num_filters, stride, name): #瓶颈,可以实现输入的channel_num小于输出的。辅助残差的实现
conv0 = conv_bn_layer(input=input, #在101中,每一组有三个卷积核,大小不同,深度不同。
num_filters=num_filters, #详细尺寸看表,101中第一组第一个为64
filter_size=1, #大小为1*1
act='relu', #激活函数为relu
name=name + "_branch2a")
conv1 = conv_bn_layer(input=conv0,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu',
name=name + "_branch2b")
conv2 = conv_bn_layer(input=conv1,
num_filters=num_filters * 4, #第三个是第一个的四倍
filter_size=1,
act=None,
name=name + "_branch2c")
short = shortcut(input, num_filters * 4, stride, name=name + "_branch1")
return fluid.layers.elementwise_add(x=short, y=conv2, act='relu', name=name + ".add.output.5")
depth = [3, 4, 23, 3] #在101中有四大组,3,4,23,3分别是每组卷积的数量。每组三个.101的构成是=1+(3+4+23+3)*3+1=101个conv
num_filters = [64, 128, 256, 512] #不同组的初始num_filters大小
conv = conv_bn_layer(input=input, num_filters=64, filter_size=7, stride=2, act='relu', name="conv1") #第一个卷积层,input是原图,被64张7*7大小的矩阵卷积,每次矩阵移动的步长为2
conv = fluid.layers.pool2d(input=conv, pool_size=3, pool_stride=2, pool_padding=1, pool_type='max') #第一次池化,conv是第一次卷积后的输出,池化的卷积核是3*3,步长2,在图像边缘进行1像素点的补充,池化采用最大值池化
for block in range(len(depth)): #99层conv的进行方式,每组循环多少次
for i in range(depth[block]): #每次的初始num_filters是多少
if block == 2:
if i == 0:
conv_name="res"+str(block+2)+"a"
else:
conv_name="res"+str(block+2)+"b"+str(i)
else:
conv_name="res"+str(block+2)+chr(97+i)
conv = bottleneck_block(input=conv,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1, #何时运用残差
name=conv_name)
pool = fluid.layers.pool2d(input=conv, pool_size=7, pool_type='avg', global_pooling=True) #最后一层,采用全局平均池化层,滑窗和整张特征图大小一样,即用7*7进行卷积,因此最终是输出num_filters个1*1的数,达到了全连接的目的
return pool
有些基础的同学可能就看懂了,但是为了让大家更清楚每一步是怎么来的,下面上图片:
网络构成:
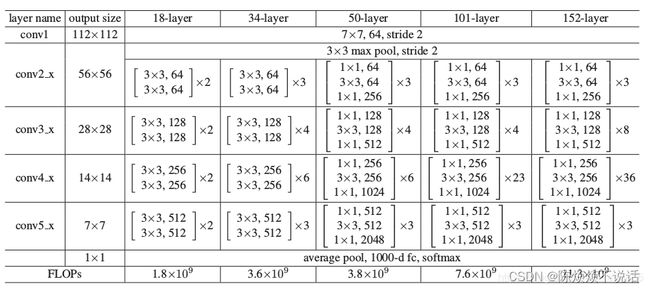
上图是Resnet的网络结构。让我们的目光放在101-layer上。会发现主要分为五个卷积,一个全连接。在第一次卷积后出现了一次池化,最后的全连接也是采用池化的方式实现的。因此在Resnet中,主要就是卷积和池化。
残差:
提到Resnet最经典最有效的就是残差的引入,相关资料有很多。这里就用最大白话的方式说一下:残差就是将之前图片中被卷积卷掉的部分加入到后续的卷积运算中,增大特征数量。
在之后学习的特征金字塔,就是减少噪音,即不必要的特征量。减少特征数量。
全局平均池化:
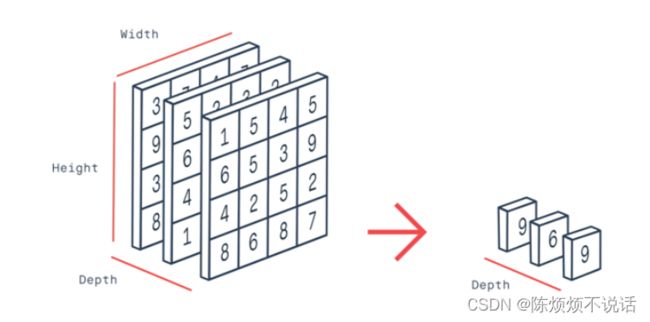
用和上一层conv出来的图像同样大小的size进行卷积。使图像由h*w变成1*1的形式。实现全连接的作用。这种方法可以减少输入参数量。
结语:
以上是我认为在Resnet学习中较为重要的几部分,因为笔者水平有限,很多地方用词不太准确,表述不清晰,如有疑问可以直接私信我。