一种基于过分割的上坡聚类方法用于从MLS数据中提取城市街道区域的个体树木
Abstract
针对现有方法对树干依赖严重,在复杂环境下提取效果不佳的问题,本文提出了一种基于过分割的上坡聚类方法从移动激光扫描数据中提取城市行道树。树干被汽车和绿化带挡住,树冠相接或互锁大。首先,通过过分割生成超体素,从而减少原始数据量并有效保留不同对象的边界。然后,通过提取典型的对象结构来获得潜在的树冠和树干。最后,通过上坡聚类从潜在树冠中提取独立树冠,并从潜在树干中搜索对应的树干,实现单树提取。本文的主要贡献是提出了一种不依赖树干提取的基于上坡聚类的行道树个体提取方法,提高了复杂城市环境中提取结果的完整性。实验结果表明,该方法有效地从测试数据中单独提取行道树,完整性为100%,正确率为96.4%,F-score为0.98。此外,该方法对于绿化带区域被严重遮挡的绿化树木的提取也取得了良好的效果。相应的完整性、正确性和 F 分数分别为 94.6%、83.3% 和 0.89。
索引词——聚类、个体树、移动激光扫描 (MLS)、分割、超体素、城市环境。
I. INTRODUCTION
行道树作为城市的重要组成部分,在降低噪音[1]、改善空气质量[2]、增加城市植被覆盖率[3]等诸多方面发挥着至关重要的作用。在其他一些方面,准确提取行道树个体并进一步捕获它们的位置、树高、树冠面积和胸径等属性非常重要[4]。例如,在确定行道树的数量和大小的基础上进行适当的规划可以最大限度地减少道路拓宽过程中的损失 [5]。此外,分析交通标志和红绿灯与个别树木的能见度可以保证行车安全。此外,在电力线路巡检方面,计算树冠与电力线路的距离,可以及时发现安全隐患,保障电力线路的安全运行。此外,准确提取每棵行道树也是城市高精度结构化制图的重要内容之一。因此,准确提取城市街道区域的树木个体具有重要意义。
移动激光扫描(MLS)技术可以快速获取城市街道物体的表面信息,这些信息由高密度的点云数据表示[6]。与地面激光扫描、机载激光扫描(ALS)和数字卫星成像技术相比,MLS技术更加灵活和高效[7]。在过去,大多数先进的城市地区静态目标调查主要与从图像中获得的数据有关。随着2008年以来MLS技术的快速发展,与MLS相关的出版物数量迅速增长[8]。已经进行了许多基于来自MLS的点云数据的城市街道区域研究,例如对象检测和提取(例如,杆状对象[9]-[12],建筑物立面[13]、[14],道路及其边界[15]-[19]),场景语义分割和对象分类[20]-[23],以及高精度导航地图生成[24]-[26]。所有上述研究显示了从MLS数据中分割和提取单个行道树的巨大潜力。
一些学者对城市行道树的提取做了大量的研究,并提出了一些提取单株树木的方法。这些方法在简单场景下,尤其是没有遮挡树干的场景下,具有较好的提取效果。然而,对于树干被汽车和绿化带遮挡,树冠接触或互锁较大的复杂场景,现有方法存在漏检问题,提取结果正确率较低。为此,本文提出了一种基于过分割的"上坡聚类"单株树木提取方法,旨在实现城市街道区域单株树木的自动提取,提高提取的准确性。
文章的其余部分组织如下。第二节介绍了从MLS数据中提取城市街道区域单株树木的相关工作。第三节介绍了行道树的提取方法。在第四节中,使用真实数据集对所提出的方法进行了实验和评估。第五部分详细讨论了实验结果。最后,第六节给出了结论和未来的工作。
II. RELATED WORKS
从 MLS 数据中提取单棵树的主要过程包括两个步骤。首先,容易识别的非树对象(例如,地面和建筑物立面)通过预处理被移除 [27]。然后,局部结构的几何特征,如高度[28]、点密度[29]、树冠半径[30]、3-D结构张量特征[9]、形状复杂度[31],用于从剩余的对象中提取具有树干和树冠的单棵树。根据 Vo 等人[32]和 Li 等人[33]的研究,现有的基于 MLS 数据的城市街道区域树木个体提取方法分为两类:基于区域生长的[28],[31],[ 33]–[35] 和基于聚类的方法 [30]、[36]–[40]。
在基于区域生长的方法中,应首先选择一般位于树干上的区域生长种子点。然后,整棵树的提取可以通过种子点的增长,按照一定的方法进行,如竞争区域增长算法[31]、广度优先搜索算法[34]、对偶增长法[33]等。 .正确选择种子点对提高提取的完整性和正确性很重要。 Yue 等[28] 根据高程差和各格点的密度在树干上选择种子点。 Wu et al [31] 根据投影到水平面的体素面积和形状选择它们,相对高度为地面以上 1.2-1.4 m。 Li等[33]按照树干位于相应树冠水平中心附近且直径小于树冠的相对圆柱形的规则在树干上搜索种子点。 Wu等[34]指出,如果一个超体素的重心平面坐标和超体素中的其他点都靠近检测位置,则该超体素更可能属于检测位置,也就是种子点在树干上。类似地,Zhong等[35]根据八叉树节点水平直方图中的局部最大值及其构建八叉树后的形状特征来选择种子点。这些方法的提取结果在很大程度上取决于种子点的选择[41]。对于树干未被遮挡的树木,这些方法可以完全选择每棵树的树干位置,通过向上和向下生长,从树干位置独立提取对应的树。然而,由于无法选择树干上的种子点,当树干被汽车和绿化带挡住时,就会出现问题。
在基于聚类的方法中,Huang等[37]对去除地面后的点进行欧几里得距离聚类,并用支持向量机分类器提取个体树。此外,Guan 等人 [36] 将欧几里得距离聚类和基于体素的归一化切割 [42] 分割相结合,用于提取单棵树。为了提高个体树提取的结果,Weinmann 等人[38]通过均值漂移聚类和形状分析提取了独立的树。 Y adav等[30]和Xu等[39]按照以下规则对每个树冠进行分割和提取,即对于除树顶点之外的任何点云,该点属于最近的树顶点所在的树。 Xu等[40]提出了一种自下而上的层次聚类方法,对树木的非光合成分进行聚类,按照离聚类非光合成分最近的原则对叶区进行聚类。现有的基于聚类的方法可以在一些简单的场景中很好地提取单个树木,这些场景中相邻的行道树间距较大,接触较少,或与城市基础设施环环相扣。然而,在行道树树冠大小不同、树冠相互接触或互锁较大、树冠与城市其他基础设施存在重叠等场景下,这些方法识别精度较低,树冠分割效果较差。
为了克服现有方法的不足,本文提出了一种基于过分割的“uphill clustering”方法,用于从MLS数据中自动提取城市街道区域的单株树木。本文的主要贡献包括以下条件。
1)我们提出了一种新的上坡聚类方法,用于从 MLS 数据中提取个体行道树。
2)我们实现了聚类阈值参数的自适应设置,提高了个体树提取的自动化程度。
3)我们在进行过分割时考虑了点密度,以改进Lin等人[43]提出的超体素分割方法,改进后的方法在处理具有不均匀密度的MLS点云数据时显示出优势。
III. METHODOLOGY
城市场景的MLS点云数据中含有较多的非树对象,如地面、建筑立面、立杆、汽车等,导致个别行道树的提取困难。为了准确提取每棵行道树,所提出的基于上坡聚类的方法主要包括以下过程。首先,我们过度分割原始点云数据以生成超体素。这种操作可以减少点云的数量,提高计算效率,也可以很好地区分不同物体的边界[43]。二是典型的物体结构,如地面、建筑立面、低平面结构、水平线性结构和垂直线性结构(潜在的树干)都是在基于超体素的区域生长提取平面和线性结构之后识别的。然后,对剩余的体积对象结构(潜在树冠)进行重新分割和聚类以生成“山坡”,并进行上坡聚类以单独分割潜在树冠。最后,选择树冠并从中找到相应的树干潜在的树干。整体工作流程示意图如图 1 所示。

图 1. 所提出方法的总体工作流程。
A. Supervoxels Generation
Supervoxel 可以定义为超像素 [44] 或紧凑点簇 [43] 的 3-D 模拟。使用超体素可以大大减少原始三维点的数量,提高处理效率。此外,良好的超体素生成方法可以保留对象边界并为原始 3-D 点提供自然和紧凑的表示,这允许在具有一致特征的局部区域而不是原始分散点上执行操作。超体素在 3-D 点云处理中受到了很多关注,例如对象检测 [39]、[45] 和语义分割或分类 [46]、[47]。定义为参考文献[43]中的紧凑点簇,本文生成超体素以减少数据量并提高个体树提取的效率。
在超体素生成方法中,Papon 等人 [44] 提出了体素云连接分割(VCCS)算法,其中初始超体素由在 3-D 空间中均匀选择的种子点形成,然后生成最终超体素与局部k均值聚类方法。相应的结果取决于种子点的选择和体素分辨率的设置。对于密度不均匀的点云数据,物体边界不能得到理想的保留,存在多个物体可能与同一体素重叠的不足[43]。因此,Lin 等人 [43] 将超体素分割视为一个子集选择问题。首先,指定超体素的数量 N,或超体素所需的分辨率 R,(N 可以通过 R 评估)。然后,N 个超体素通过最小化每个点与其对应的代表点之间的相异距离之和(用距离度量,D来衡量)来选择。这种方法更适合于对象的提取或检测,因为它更好地保留了对象边界。但是,由于距离度量D只考虑点间法向量差和欧式距离,不同点密度区域生成的超体素分辨率差异较大,这对于MLS点云数据尤为明显。如图 2(a) 所示,激光扫描仪附近的道路中间点云更密集,因此生成的超体素的分辨率更小。远离扫描仪的道路两侧,点云密度越小,生成的超体素对应的分辨率越大。因此,直接使用该方法从MLS点云数据中提取行道树会造成如下两个问题。
1)道路两侧树木附近的超体素的平均分辨率与输入的期望分辨率R不一致,这使得参数R的选择变得困难。R表示生成的超体素的平均分辨率,其中点密度接近原始点云中的平均点密度。道路两侧树木附近的超体素平均分辨率大于所需分辨率。
2)生成的supervoxels很大一部分分布在道路上,无法有效减少点数。道路上的超体素平均分辨率小,超体素数量多,这可以归因于 MLS 数据路面上的高点密度。然而,路面通常是简单的平面结构,因此不需要使用过多的超体素来表示。因此,有必要减少道路上的超体素数量。
为了解决上述两个问题,[43]中的距离度量在本文考虑的点密度不一致的情况下得到改进。使用改进的方法,可以尽可能避免密度不一致对生成的超体素的平均分辨率的影响,并且可以有效地减少道路上的超体素的数量。优化的距离度量表示为
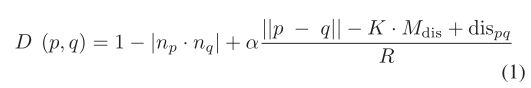
其中 np 和 nq 是点 p 和 q 的法向量,分别归一化为单位长度。法向量的计算与 [48] 中的 VCCS 实现相同。 K是需要指定的参数,用来控制点密度的影响。 Mdis表示原始点云中所有点的平均点密度,用平均点间距表示。 dispq为p点和q点的平均密度,用p点和q点的平均点间距表示。实际上,点 p 的点间距由点 p 到其 k 最近邻域中的点的平均距离表示。 α是平衡法向量差异和空间距离影响的权重参数。在实践中,α取0.4,与[43]和[48]中的相同。
通过距离度量在优化前后以相同的所需分辨率生成的超体素分别如图 2(a) 和 (b) 所示。从图2的比较中可以看出,考虑点密度生成的超体素的分辨率更加均匀,便于选择所需的分辨率R。此外,道路上的超体素数量也大大减少, 通过使用 supervoxels 来表示原始点有效地减少了数据量。
B. Planar and Linear Object Structures Extraction
生成超体素后,所有的点都可以对应到它们所属的超体素。同一个超体素中的几乎所有点都属于同一个对象或同一个对象的一部分。这为物体的检测提供了良好的基础。由于我们侧重于个体树的提取,我们首先根据超体素的区域生长提取典型的平面和线性对象结构,然后去除典型的非树平面和线性对象结构。
使用主成分分析方法,每个超体素的几何结构计算如下 [49]、[50]。
设 pi (i = 1, 2, …, k) 是一个超体素中的点。它们的协方差矩阵M可以写为

其中 k 是超体素中的点数,¯p 是超体素的质心,¯p = 1 k ?k i = 1 pi。
特征值λ1,λ2,λ3;(λ1 ≥ λ2 ≥ λ3)o,它们代表了超体素的三维几何张量特征。
与Yang等[50]采用概率方法判断超体素属于线性、平面还是体积结构不同,我们通过指定参数M的三个特征值来确定超体素的几何结构VL阈值 KL 和 KP 。这可以有效地避免后续区域生长过程中的椒盐噪声。判断超体素几何结构的方法如下:
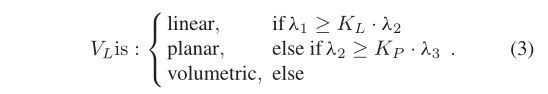
对于具有平面和线性结构的超体素,分别计算它们的法线方向 VN 和主方向 VP 。 VN和VP是M的最小和最大特征值对应的特征向量。
表 1 几种典型的城市对象结构及其相应的判断方法

利用超体素的几何特征,所有的点都可以用N个具有几何特征(线性、平面或体积结构类别,平面结构的法线方向或线性结构的主方向)的超体素代表点来表示。用区域生长法依次检测平面和线状物体结构。过程如下。
1)平面物体结构检测。阈值参数KL = 10和KP = 5用于计算平面物体结构检测中的超体素几何结构。然后,从平面超体素中随机选择第一个种子超体素,将空间相邻的超体素作为候选生长超体素。生长标准是超体素和种子超体素之间的法向量夹角小于阈值 TN(实践中 TN = 20°)。满足生长标准的超体素被聚类到种子超体素中,它们的邻域被放入候选生长超体素中。对于候选超体素,按照生长准则进行生长过程,直至检测出第一个种子超体素的平面物体结构。在第一个种子超体素所在的平面物体结构生长完成后,选择下一个种子超体素开始下一个平面结构体的生长,直到完成所有平面物体结构的检测。
2)线性物体结构的检测。使用阈值参数 KL = 5,KP = 10 重新计算生长的平面对象结构的几何结构,并将重新计算的平面对象结构与其他未生长的线性超体素一起用于线性对象结构检测。线性物体结构的检测方法与平面物体结构的检测方法类似,只是将生长准则替换为超体素与种子超体素的主方向夹角小于阈值的准则,TP(TP = 20°在实践中)。
区域生长后生成的平面和线性物体结构和未生长的超体素都是物体的一部分。为方便起见,我们称它们为对象结构。其中,几种典型的物体结构包括地面、建筑物立面、平面形状的低植被、水平线状结构如路边、建筑物的线状结构,以及垂直线状结构如交通标志杆、路灯杆、树等。树干可以很容易地提取。这些典型对象结构的垂直线性结构是潜在的树干。除上述典型物体结构外的其他结构均属于潜在树冠。受 Yang 等人 [50] 的启发,我们根据其最小边界框大小及其几何特征提取典型对象结构。然后,除去潜在的树干和树冠结构之外的其他典型对象结构。各典型对象结构的判断方法如表一所示。
除了大的平面结构,建筑立面还包含许多其他的小结构,如门窗框、空调等。因此,按照表1中的判断方法提取建筑立面结构后,位于提取的建筑立面最小包围盒内的其他结构也视为建筑立面结构,如图3所示。这样,对于低平面结构,位于低平面结构的最小边界框内的其他结构也被视为低平面结构。

图 4. 山坡生成过程。 (a) 体积几何点(按高程着色)。 (b) 超体素。 © 山坡结构的侧视图。 (d) 山坡结构的俯视图。 (e) 山坡结构代表点的侧视图。 (f) 山坡结构代表点的俯视图。
D. Uphill Clustering
对于生成的山坡结构的代表点,采用上坡聚类准则,按照高度从低到高的顺序,确定每个代表点及其对应的柱状簇所属的聚类类别,从而实现对每个代表点的个体提取。树冠。图 5 显示了代表点及其对应的原始点的山坡聚类过程。具体的聚类过程如下。
1)对于山坡构造中柱状簇的代表点,按照高程排序并依次编号。数字代表柱状簇所属的簇类别。在上坡聚类之前,簇类别数等于柱状簇数。
2)按照高度从低到高的顺序,即数量从大到小,依次对山坡结构中的每个代表点Pi进行聚类。接下来,我们找到离Pi最近的代表点Pj在 XY 平面上,其数量小于 Pi(即在空间上大于 Pi)。判断Pi和Pj是否满足聚类条件,即空间上相邻且XY平面上的距离是否小于阈值Tc。如果满足聚类条件,则代表点Pi和Pj属于同一个聚类类别。然后将代表点Pi和与Pi编号相同的代表点(即属于Pi的簇类别的柱状簇)的个数都改为Pj的个数。
- 最高代表点聚类完成后,山坡结构柱状簇的所有代表点都有对应的簇类别编号。编号相同的柱状簇属于同一聚类类别,可以区分编号不同的柱状簇,实现上坡聚类。
对于山坡结构的聚类结果,计算每个簇的空间最小边界框,将最小边界框大小大于阈值Sbb的簇作为树冠,如图中的个体树冠图 1 每棵树的树冠提取后,用每个树冠最高点的平面坐标表示树冠在XY平面上的位置。在XY平面上距离树冠最近的垂直线状结构为从潜在的树干结构中选择小于 Dct 作为相应的树干。如果树冠在 XY 平面小于 Dct 的距离内没有潜在的树干结构,则树冠没有相应的树干。至此,完成了城区MLS点云数据中行道树的个体提取,如图1个体树部分所示。
为提高uphill聚类法提取不同大小树冠的自适应能力,在柱状簇代表点聚类过程中,聚类阈值Tc的选取采用了根据树冠大小自适应的方法。假设冠宽与冠长成正比,聚类阈值Tc可以根据柱状簇的当前长度Hi自适应选择。
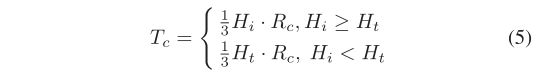
式中Rc为树冠宽与树冠长之比,其值可根据树种选择; Ht 是柱状团簇的长度阈值。在上坡聚类过程中,使用Ht可以避免长度小于Ht的柱状簇聚类失败。
固定阈值的方法存在难以准确提取不同大小树冠的缺点,自适应聚类阈值法可以避免这一缺点。如图A、B、C、D为四个代表点。对于D的聚类,搜索到的最近邻代表点为B,D中的柱状簇能够聚成B的条件是dBD小于阈值TcD。对于C的聚类,搜索到的最近邻代表点为A,对应的聚类条件为dAC小于阈值TcC。

图6. 根据柱状簇长度自适应选择聚类阈值的示意图。
由于dAC大于dBD,当固定阈值Tc较小时,两个柱状簇A和C会被分为两个簇类别,导致树冠过分割;当固定阈值Tc较大时,B和D会被聚到同一个簇类别中,导致欠分割。本文采用的自适应阈值选择方法可以根据当前柱状簇的长度自动确定阈值Tc的大小,使得代表点D处的聚类阈值TcD小于代表点C处的聚类阈值TcC。这样可以有效避免固定阈值难以聚类空间连通和大小不一的树冠的缺点。
VI. CONCLUSION
针对城市MLS点云数据中个体树木的提取,我们提出了一种基于过分割的uphill聚类方法,其主要步骤包括超体素生成、潜在树冠和树干的确定以及个体树木提取。结果表明,它可以成功地提取不同复杂场景中的个体树木。对于树干被阻塞或丢失的树,它仍然可以单独提取,这意味着所提出的方法不依赖于树干的数据质量。
结合实验数据,所提方法提取行道树的正确率和完备率分别为96.4%和100%。没有遗漏提取,整体提取结果优于大多数现有方法。此外,所提出的方法对绿化带区域被严重遮挡的绿化树木也有很好的提取效果。正确性和完整性分别为 83.3% 和 94.6%。需要进一步研究的内容是,对于树冠中混合人工不规则物体的行道树的提取,所提出的个体树提取方法还需要进一步改进。