每日学术速递2.1
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.Cv
1.SeaFormer: Squeeze-enhanced Axial Transformer for Mobile Semantic Segmentation

标题:SeaFormer:用于移动语义分割的挤压增强型轴向变换器
作者: Qiang Wan, Zilong Huang, Jiachen Lu, Gang Yu, Li Zhang
文章链接:https://arxiv.org/abs/2301.13156v1
项目代码:https://github.com/fudan-zvg/seaformer

摘要:
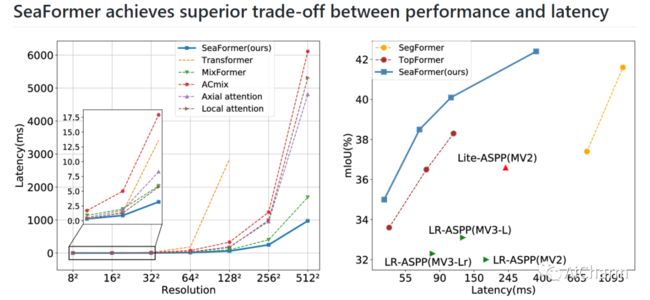
自从引入视觉变换器后,许多计算机视觉任务(如语义分割)的格局,最近被CNN压倒性地主宰,发生了显著的变化。然而,计算成本和内存要求使得这些方法不适合在移动设备上使用,特别是对于高分辨率的每像素语义分割任务。在本文中,我们介绍了一种用于移动语义分割的新方法--挤压增强的轴向变换器(SeaFormer)。具体来说,我们设计了一个通用的注意力块,其特点是制定挤压轴向和细节增强。它可以进一步用于创建一个具有卓越成本效益的骨干架构系列。与轻型分割头相结合,我们在ADE20K和Cityscapes数据集上基于ARM的移动设备上实现了分割精度和延迟之间的最佳权衡。最关键的是,我们以更好的性能和更低的延迟击败了对移动设备友好的对手和基于变压器的同行,而没有任何花哨的东西。除了语义分割之外,我们还将提出的SeaFormer架构应用于图像分类问题,展示了其作为多功能移动友好骨干的潜力。
Since the introduction of Vision Transformers, the landscape of many computer vision tasks (e.g., semantic segmentation), which has been overwhelmingly dominated by CNNs, recently has significantly revolutionized. However, the computational cost and memory requirement render these methods unsuitable on the mobile device, especially for the high-resolution per-pixel semantic segmentation task. In this paper, we introduce a new method squeeze-enhanced Axial TransFormer (SeaFormer) for mobile semantic segmentation. Specifically, we design a generic attention block characterized by the formulation of squeeze Axial and detail enhancement. It can be further used to create a family of backbone architectures with superior cost-effectiveness. Coupled with a light segmentation head, we achieve the best trade-off between segmentation accuracy and latency on the ARM-based mobile devices on the ADE20K and Cityscapes datasets. Critically, we beat both the mobile-friendly rivals and Transformer-based counterparts with better performance and lower latency without bells and whistles. Beyond semantic segmentation, we further apply the proposed SeaFormer architecture to image classification problem, demonstrating the potentials of serving as a versatile mobile-friendly backbone.
2.Counterfactual Explanation and Instance-Generation using Cycle-Consistent Generative Adversarial Networks

标题:使用循环一致的生成式对抗网络进行反事实解释和实例生成
作者:Tehseen Zia, Zeeshan Nisar, Shakeeb Murtaza
文章链接:https://arxiv.org/abs/2301.08939v1
项目代码:https://github.com/zeeshannisar/cx_gan
摘要:
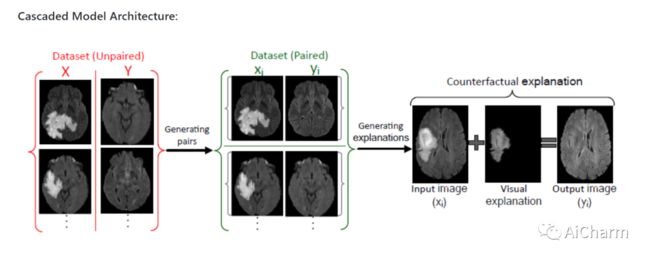
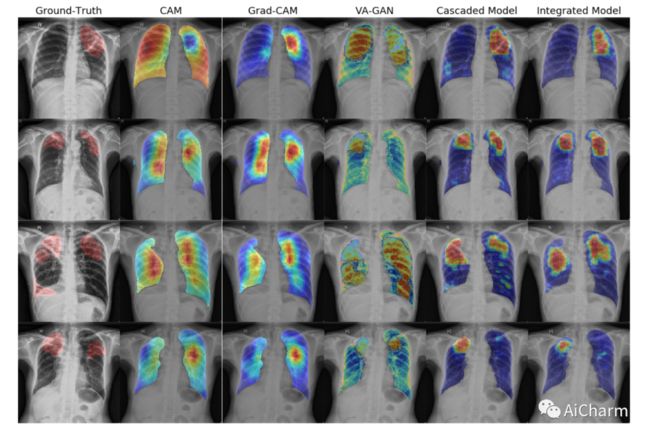
基于图像的诊断现在是现代自动化辅助诊断的一个重要方面。为了使模型能够产生像素级的诊断,基本上需要像素级的地面真实标签。然而,由于在许多应用领域(如医学图像)中,获得标签往往并不容易,基于分类的方法已经成为执行诊断的事实标准。尽管它们可以识别出类的优势区域,但对于捕捉所有证据是重要要求的诊断来说,它们可能并不有用。另外,反事实解释(CX)的目的是利用 "如果X没有发生,Y就不会发生 "这样的随意推理过程来提供解释。然而,现有的CX方法使用分类器来解释那些可以改变其预测的特征。因此,它们只能解释类的特征,而不是整个感兴趣的对象。因此,这促使我们提出一种不依赖图像分类的新型CX策略。这项工作受到了基于生成对抗网络(GANs)的图像到图像领域翻译的最新发展的启发,并利用将异常图像翻译成对应的正常图像(即反事实实例CI)来寻找两者之间的差异图。由于通常不可能获得异常和正常的图像对,我们利用周期一致性原则(又称CycleGAN),以无监督的方式进行翻译。我们用差异图来表述CX,当从异常图像中添加时,将使其与CI无法区分。我们在三个数据集上评估了我们的方法,包括一个合成数据集、结核病数据集和BraTS数据集。所有这些实验都证实了提议的方法在生成准确的CX和CI方面的优越性。
The image-based diagnosis is now a vital aspect of modern automation assisted diagnosis. To enable models to produce pixel-level diagnosis, pixel-level ground-truth labels are essentially required. However, since it is often not straight forward to obtain the labels in many application domains such as in medical image, classification-based approaches have become the de facto standard to perform the diagnosis. Though they can identify class-salient regions, they may not be useful for diagnosis where capturing all of the evidences is important requirement. Alternatively, a counterfactual explanation (CX) aims at providing explanations using a casual reasoning process of form "If X has not happend, Y would not heppend". Existing CX approaches, however, use classifier to explain features that can change its predictions. Thus, they can only explain class-salient features, rather than entire object of interest. This hence motivates us to propose a novel CX strategy that is not reliant on image classification. This work is inspired from the recent developments in generative adversarial networks (GANs) based image-to-image domain translation, and leverages to translate an abnormal image to counterpart normal image (i.e. counterfactual instance CI) to find discrepancy maps between the two. Since it is generally not possible to obtain abnormal and normal image pairs, we leverage Cycle-Consistency principle (a.k.a CycleGAN) to perform the translation in unsupervised way. We formulate CX in terms of a discrepancy map that, when added from the abnormal image, will make it indistinguishable from the CI. We evaluate our method on three datasets including a synthetic, tuberculosis and BraTS dataset. All these experiments confirm the supremacy of propose method in generating accurate CX and CI.

3.Edge-guided Multi-domain RGB-to-TIR image Translation for Training Vision Tasks with Challenging Labels

标题:边缘引导的多域RGB-TIR图像翻译用于具有挑战性标签的训练视觉任务
作者: Dong-Guw Lee, Myung-Hwan Jeon, Younggun Cho, Ayoung Kim
文章链接:https://arxiv.org/abs/2301.12689v1
项目代码:https://github.com/rpmsnu/sRGB-TIR
摘要:
有注释的热红外(TIR)图像数据集数量不足,这不仅阻碍了基于TIR图像的深度学习网络具有与RGB相当的性能,而且还限制了基于TIR图像任务的监督学习,因为标签具有挑战性。作为一种补救措施,我们提出了一个改进的多域RGB到TIR图像翻译模型,重点是保留边缘,以采用具有挑战性标签的RGB图像。我们提出的方法不仅保留了原始图像的关键细节,而且还利用了最佳的TIR风格代码,在翻译后的图像中描绘出准确的TIR特征,当应用于合成和真实世界的RGB图像时。使用我们的翻译模型,我们已经实现了基于TIR图像的光流估计和物体检测的监督学习,通过平均减少56.5%的端点误差和23.9%的最佳物体检测mAP,改善了深TIR光流估计。
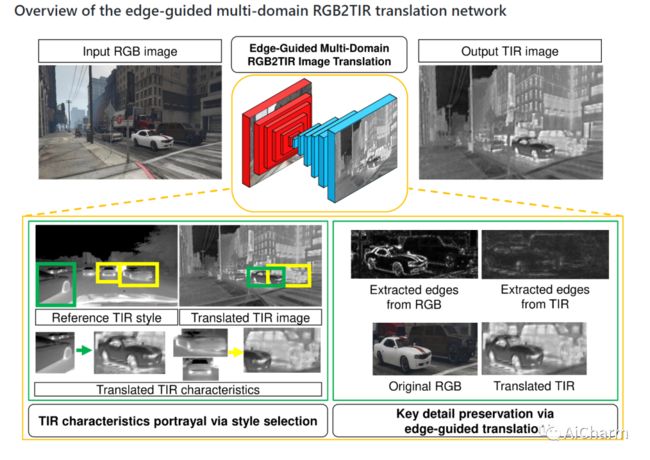
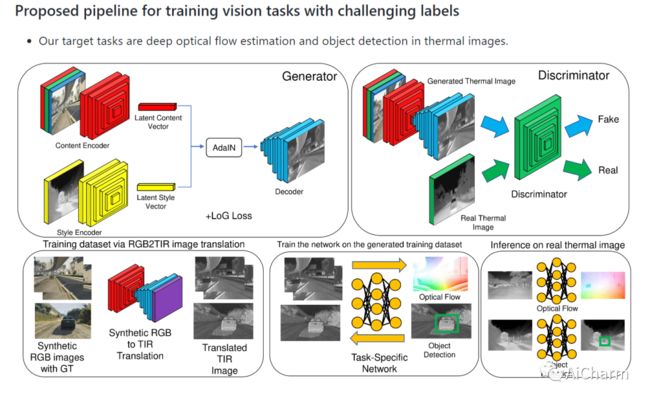
The insufficient number of annotated thermal infrared (TIR) image datasets not only hinders TIR image-based deep learning networks to have comparable performances to that of RGB but it also limits the supervised learning of TIR image-based tasks with challenging labels. As a remedy, we propose a modified multidomain RGB to TIR image translation model focused on edge preservation to employ annotated RGB images with challenging labels. Our proposed method not only preserves key details in the original image but also leverages the optimal TIR style code to portray accurate TIR characteristics in the translated image, when applied on both synthetic and real world RGB images. Using our translation model, we have enabled the supervised learning of deep TIR image-based optical flow estimation and object detection that ameliorated in deep TIR optical flow estimation by reduction in end point error by 56.5% on average and the best object detection mAP of 23.9% respectively. Our code and supplementary materials are available at https://github.com/rpmsnu/sRGB-TIR.