笔记——机器学习入门
文章目录
- 机器学习概述
-
- 什么是机器学习
- 机器学习算法分类
- 机器学习开发流程
- 机器学习框架
- 数据集获取
-
- 获取sklearn自带数据集的方法
- 数据集划分
- 特征工程
-
- 特征工程步骤:
-
- 特征提取
- 特征预处理
-
- 归一化
- 标准化(常用这种方式无量纲化)
- 特征降维
-
- 特征选择
- 主成分分析(Principal component analysis)
-
- PCA降维案例
- 机器学习算法训练
-
- 详解转换器类和预估器类
- 模型选择与调优
机器学习概述
什么是机器学习
- 机器学习与人解决问题过程比较


即机器学习的过程为:分析数据 --> 得出模型 --> 利用模型分析新数据
- 数据集:数据集是有特征值和目标值(也称为标签,可以没有)构成的.如下图,房子面积,位置等都是特征值。
机器学习算法分类
- 有监督学习(有目标值):分类(目标值是类别) 回归(目标值时连续值)
1. 分类算法:k-近邻算法,贝叶斯算法,决策树与随机森林,逻辑回归
2. 回归算法:线性回归,岭回归 - 无监督学习(没有目标值):聚类
3.聚类算法:K-means
机器学习开发流程
- 获取数据
- 数据处理
- 特征工程
- 机器学习算法训练出模型
- 模型评估
- 使用模型
主要是做2,3两个步骤
机器学习框架
scikit learn
tensorflow
pytorch
数据集获取
- scikit learn自带数据集: https://scikit-learn.org/stable/datasets
- UCI数据集:https://archive.ics.uci.edu/ml/index.php
- Kaggle: https://www.kaggle.com/datasets
获取sklearn自带数据集的方法
- 导入模块datasets
- 使用load_*()函数导入数据集,*是要导入数据集的名称
- 使用fetch_*(data_home=None)函数将数据集下载到data_home指定路径下
- 返回的数据类型为Bunch类型,该类型继承字典,有以下键

from sklearn.datasets import load_iris
# 导入莺尾花数据集
iris=load_iris()
print('数据描述\n',iris['DESCR'])
特征数组
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%[email protected])
:Date: July, 1988
The famous Iris database, first used by Sir R.A. Fisher. The dataset is taken
from Fisher's paper. Note that it's the same as in R, but not as in the UCI
Machine Learning Repository, which has two wrong data points.
This is perhaps the best known database to be found in the
pattern recognition literature. Fisher's paper is a classic in the field and
is referenced frequently to this day. (See Duda & Hart, for example.) The
data set contains 3 classes of 50 instances each, where each class refers to a
type of iris plant. One class is linearly separable from the other 2; the
latter are NOT linearly separable from each other.
.. topic:: References
- Fisher, R.A. "The use of multiple measurements in taxonomic problems"
Annual Eugenics, 7, Part II, 179-188 (1936); also in "Contributions to
Mathematical Statistics" (John Wiley, NY, 1950).
- Duda, R.O., & Hart, P.E. (1973) Pattern Classification and Scene Analysis.
(Q327.D83) John Wiley & Sons. ISBN 0-471-22361-1. See page 218.
- Dasarathy, B.V. (1980) "Nosing Around the Neighborhood: A New System
Structure and Classification Rule for Recognition in Partially Exposed
Environments". IEEE Transactions on Pattern Analysis and Machine
Intelligence, Vol. PAMI-2, No. 1, 67-71.
- Gates, G.W. (1972) "The Reduced Nearest Neighbor Rule". IEEE Transactions
on Information Theory, May 1972, 431-433.
- See also: 1988 MLC Proceedings, 54-64. Cheeseman et al"s AUTOCLASS II
conceptual clustering system finds 3 classes in the data.
- Many, many more ...
数据集划分
1.数据集一部分用于训练模型,一部分用于测试模型评估。所以需要对数据集划分。
2.测试集一般在20%到30%之间。
3.sklearn包提供model_selection模块的train_test_split()函数用于训练和测试数据分割。

测试集大小默认0.25即占比25%.
随机数种子可用于控制变量比较不同的算法.
from sklearn.model_selection import train_test_split
train_data,test_data,train_target,test_target=train_test_split(iris['data'],
iris['target'],
test_size=0.2)
print('训练特征值\n',train_data[:5,:])
print('测试目标值\n',test_target)
训练特征值
[[5.8 2.7 5.1 1.9]
[6.9 3.1 4.9 1.5]
[7.7 3.8 6.7 2.2]
[6.4 3.2 4.5 1.5]
[5.1 3.3 1.7 0.5]]
测试目标值
[2 2 0 2 2 2 0 0 0 1 1 1 0 0 2 2 0 0 2 0 2 2 1 2 1 2 2 2 1 2]
特征工程
- 为什么需要做特征工程?
因为数据和特征决定了机器学习的上限,模型和算法只是去逼近这个上限。 - 特征工程用sklearn做,pandas主要是去做数据清洗和处理的。
特征工程步骤:
特征提取
特征提取(就是特征值化):用sklearn的feature_extraction模块来做
1.字典特征提取 (实际就是将类别处理为one-hot编码)
one hot编码是将类别变量转换为机器学习算法易于利用的一种形式的过程,使得不同类别间无优先级差异

sparse matrix干了什么?就是只把非零值按位置表示出来,从而达到节省内存提高加载效率的作用。可以通过参数sparse=Flase设置不返回稀疏矩阵也可以得到sparse matrix后用toarray方法将稀疏矩阵转换为一般的矩阵。
应用场景:(1)数据集中有类别变量,那么久将数据集转字典或字典迭代器类型再用DictVectorizer做转换 (2)数据集本身就是字典
from sklearn import feature_extraction
data=[{'city':'mianyang','num':100},{'city':'shanghai','num':200},{'city':'dalian','num':300}]
# 实例化转换器类
transfer=feature_extraction.DictVectorizer(sparse=False)
# 调用fit_transform方法对字典迭代器进行特征值化
new_data=transfer.fit_transform(data)
print('特征值:\n',new_data)
# 注get_feature_names()方法将在未来版本被移除,请使用get_feature_names_out()方法
print('特征值名称:\n',transfer.get_feature_names_out())
特征值:
[[ 0. 1. 0. 100.]
[ 0. 0. 1. 200.]
[ 1. 0. 0. 300.]]
特征值名称:
['city=dalian' 'city=mianyang' 'city=shanghai' 'num']
2.文本特征提取:用子模块text来做
(1).用CountVectorizer类:统计特征出现次数来特征值化文本

注:由于中文之间不像英语一样单词之间有空格分割,所有中文文本特征化前要先做单词分割,可以考虑用jieba库实现:https://zhuanlan.zhihu.com/p/109110105
注:哪些词可以停用可以参考停用词表
from sklearn.feature_extraction import text
data=['i love china too','he loves china too ha ha ']
# 实例化转换器类
transfer=text.CountVectorizer() # 这个实例化方法没提供sparse参数
# 调用fit_transform方法进行转换
new_data=transfer.fit_transform(data)
print('特征值:\n',new_data.toarray())
print('特征名称:\n',transfer.get_feature_names_out())
特征值:
[[1 0 0 1 0 1]
[1 2 1 0 1 1]]
特征名称:
['china' 'ha' 'he' 'love' 'loves' 'too']
import jieba
def words_cut(text):
# jieba.cut(text)返回一个生成器,用list转生成器对象为list后才能转为字符串
# 注意列表单词间以空格分割
return ' '.join(list(jieba.cut(text)))
data=['我爱中国,中国是一个美丽的国家',
'我来自四川,四川有大熊猫,他们很可爱']
# 中文单词分割
new_data=[words_cut(text) for text in data]
print(new_data)
['我 爱 中国 , 中国 是 一个 美丽 的 国家', '我 来自 四川 , 四川 有 大熊猫 , 他们 很 可爱']
# 实例化转换器对象
transfer=text.CountVectorizer()
# 调用fit_transform方法转换
final_data=transfer.fit_transform(new_data)
print('特征值:\n',final_data.toarray())
print('特征名称:\n',transfer.get_feature_names_out())
特征值:
[[1 2 0 0 0 1 0 0 1]
[0 0 1 1 2 0 1 1 0]]
特征名称:
['一个' '中国' '他们' '可爱' '四川' '国家' '大熊猫' '来自' '美丽']
(2).用TfidfVectorizer做:用单词重要性程度特征值化
- TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文件频率)是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的一份文件的重要程度,其原理可概括为:一个词语在一篇文章中出现次数越多,同时在所有文档中出现次数越少,越能够代表该文章。分类机器学习前常用这种特征提取处理文本。
tfidf计算公式: t f i d f = t f ∗ i d f tfidf=tf*idf tfidf=tf∗idf t f = 这个单词在本字符串出现频率 tf=这个单词在本字符串出现频率 tf=这个单词在本字符串出现频率 i d f = l g 语料库文档量 包含该单词的文档数目 idf=lg\frac{语料库文档量}{包含该单词的文档数目} idf=lg包含该单词的文档数目语料库文档量

# 实例化转换器对象
transfer=text.TfidfVectorizer()
# 调用fit_transform方法转换
final_data=transfer.fit_transform(new_data)
print('特征值:\n',final_data.toarray())
print('特征名称:\n',transfer.get_feature_names_out())
# 第一个字符串的的‘一个’这个单词的tfidf计算
# tf=1/10=0.1 idf=lg 2/1 tfidf=0.1*
特征值:
[[0.37796447 0.75592895 0. 0. 0. 0.37796447
0. 0. 0.37796447]
[0. 0. 0.35355339 0.35355339 0.70710678 0.
0.35355339 0.35355339 0. ]]
特征名称:
['一个' '中国' '他们' '可爱' '四川' '国家' '大熊猫' '来自' '美丽']
特征预处理
- 特征预处理是通过一些转换函数将特征值转换为更加适合机器学习算法的特征数据的过程
- 特征预处理的目的:做无量纲化处理(归一化/标准化)使得不同规模数据转为同规模消除数据单位的影响。避免学习过程中由于单位差异导致数值差异过大而忽略某些特征
- 特征预处理用preprocessing模块做
归一化
- 最大最小值归一化 X ′ = X − m i n ( X ) m a x ( X ) − m i n ( X ) × ( m a x ( X ) − m i n ( X ) ) + m i n ( X ) X'=\frac{X-min(X)}{max(X)-min(X)}\times (max(X)-min(X))+min(X) X′=max(X)−min(X)X−min(X)×(max(X)−min(X))+min(X)
preprocessing模块提供了完成这一操作的函数

归一化实现无量纲的缺点:依赖最大最小值,如果存在异常值恰好是最大/最小值那么对归一化结果影响很大。鲁棒性差所以只适用于精确的小数据场景
import sklearn.preprocessing
# scaler是放缩器的意思
# 实例化转换器类
transfer=sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)) # 归一化到0,1区间
prepro_data=transfer.fit_transform(final_data.toarray())
print('归一化后的特征值:\n',prepro_data)
归一化后的特征值:
[[1. 1. 0. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 1. 1. 0. 1. 1. 0.]]
标准化(常用这种方式无量纲化)
- z-score标准化 X ′ = X − m e a n s t d X'=\frac{X-mean}{std} X′=stdX−mean
部分异常值对mean和std的影响不大,因而采用z-score标准化的方式实现无量纲化可以减弱异常值的影响
preprocessing模块提供了完成这一操作的函数

import sklearn.preprocessing
# scaler是放缩器的意思
# 实例化转换器类
transfer=sklearn.preprocessing.StandardScaler() # 归一化到0,1区间
prepro_data=transfer.fit_transform(final_data.toarray())
print('标准化后的特征值:\n',prepro_data)
标准化后的特征值:
[[ 1. 1. -1. -1. -1. 1. -1. -1. 1.]
[-1. -1. 1. 1. 1. -1. 1. 1. -1.]]
特征降维
- 降维对象:特征降维是降低的特征的个数而不是数组的维度。得到一组不相关的主变量的过程。
- 降维方法:(1)特征选择(2)主成分分析
特征选择
1.filter过滤式
(1)方差选择法:方差小的特征过滤掉
- sklearn提供feature_selection模块做过滤式特征选择

注: threshold /ˈθreʃhəʊld/ n.阈值
(2)相关系数法:相关系数大的特征过滤其一 或 按一定权重加权得到新特征删除原来两个特征 或 主成分分析
- pearson相关系数

|r|越接近1两个变量相关性越强,r越接近0相关性越弱。

- pearson相关系数可以用scipy.stats模块做

2.embedded嵌入式
决策树
正则化
深度学习:卷积等
import sklearn.feature_selection
from sklearn.datasets import load_diabetes
# 实例化转换器类用方差选择法降维
transfer=sklearn.feature_selection.VarianceThreshold()
# 调用fit_transform方法
new_data=transfer.fit_transform(data)
print(new_data)
[[ 0.03807591 0.05068012 0.06169621 ... -0.00259226 0.01990842
-0.01764613]
[-0.00188202 -0.04464164 -0.05147406 ... -0.03949338 -0.06832974
-0.09220405]
[ 0.08529891 0.05068012 0.04445121 ... -0.00259226 0.00286377
-0.02593034]
...
[ 0.04170844 0.05068012 -0.01590626 ... -0.01107952 -0.04687948
0.01549073]
[-0.04547248 -0.04464164 0.03906215 ... 0.02655962 0.04452837
-0.02593034]
[-0.04547248 -0.04464164 -0.0730303 ... -0.03949338 -0.00421986
0.00306441]]
主成分分析(Principal component analysis)
-
详解PCA:https://zhuanlan.zhihu.com/p/37777074
-
简述PCA降维:PCA是高维数据转低维数据的过程(还是减少特征的过程),这个过程中可能会舍弃原有特征创建新特征。它的作用是将数据维数进行压缩,在损失少量信息的情况下尽可能降低原来数据的复杂度。如图所示将5个样本两个特征的数据集用散点图绘制,可以将点投射到(合适的一条直线上)蓝色直线上,删除原来的两个特征创建一个新的特征达到降维效果。
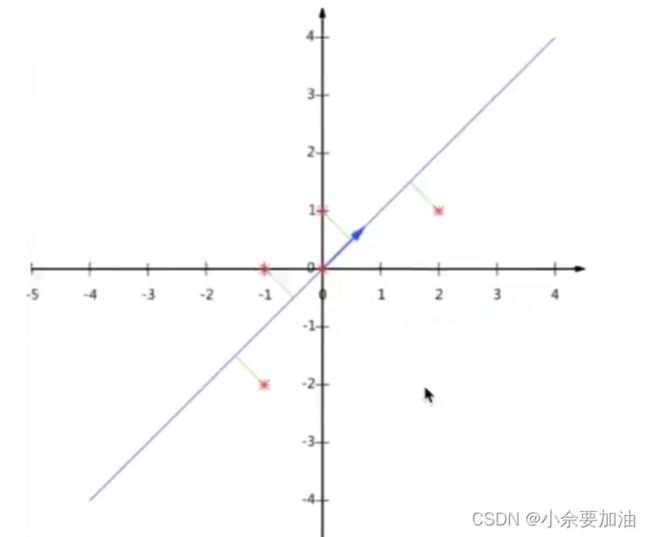
-
sklearn提供deposition模块的PCA类可用于PCA降维

import sklearn.decomposition
import numpy as np
data=np.array([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
# 实例化转换器类
transfer=sklearn.decomposition.PCA(n_components=0.95)
# 调用fit_transform进行转换
new_data=transfer.fit_transform(data)
print('PCA decompositon后的特征值:\n',new_data)
# 原来有4个特征PCA降维后只有两个特征,样本量不变
PCA decompositon后的特征值:
[[-3.13587302e-16 3.82970843e+00]
[-5.74456265e+00 -1.91485422e+00]
[ 5.74456265e+00 -1.91485422e+00]]
PCA降维案例
题目:将user_id和aisle放到同一张表(如第二张图所示结构)并使用PCA降维
参考:
- 表合并:https://pandas.pydata.org/docs/reference/api/pandas.merge.html?highlight=merge#pandas.merge
- 表交叉:https://pandas.pydata.org/docs/reference/api/pandas.crosstab.html?highlight=crosstab#pandas.crosstab

# 用pandas来读文件,以及合并操作
import pandas as pd
orders=pd.read_csv(r"D:\资料\machine_learning\数据集\instacart-market-basket-analysis\orders.csv\orders.csv")
orders.head(n=3)
| order_id | user_id | eval_set | order_number | order_dow | order_hour_of_day | days_since_prior_order | |
|---|---|---|---|---|---|---|---|
| 0 | 2539329 | 1 | prior | 1 | 2 | 8 | NaN |
| 1 | 2398795 | 1 | prior | 2 | 3 | 7 | 15.0 |
| 2 | 473747 | 1 | prior | 3 | 3 | 12 | 21.0 |
products=pd.read_csv(r"D:\资料\machine_learning\数据集\instacart-market-basket-analysis\products.csv\products.csv")
products.head(n=3)
| product_id | product_name | aisle_id | department_id | |
|---|---|---|---|---|
| 0 | 1 | Chocolate Sandwich Cookies | 61 | 19 |
| 1 | 2 | All-Seasons Salt | 104 | 13 |
| 2 | 3 | Robust Golden Unsweetened Oolong Tea | 94 | 7 |
order_products=pd.read_csv(r"D:\资料\machine_learning\数据集\instacart-market-basket-analysis\order_products__prior.csv\order_products__prior.csv")
order_products.head(n=3)
| order_id | product_id | add_to_cart_order | reordered | |
|---|---|---|---|---|
| 0 | 2 | 33120 | 1 | 1 |
| 1 | 2 | 28985 | 2 | 1 |
| 2 | 2 | 9327 | 3 | 0 |
aisles=pd.read_csv(r"D:\资料\machine_learning\数据集\instacart-market-basket-analysis\aisles.csv\aisles.csv")
aisles.head(n=3)
| aisle_id | aisle | |
|---|---|---|
| 0 | 1 | prepared soups salads |
| 1 | 2 | specialty cheeses |
| 2 | 3 | energy granola bars |
tabel1=pd.merge(aisles,products,on=['aisle_id'])
tabel1.head(20)
| aisle_id | aisle | product_id | product_name | department_id | |
|---|---|---|---|---|---|
| 0 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 |
| 1 | 1 | prepared soups salads | 554 | Turkey Chili | 20 |
| 2 | 1 | prepared soups salads | 886 | Whole Grain Salad with Roasted Pecans & Mango ... | 20 |
| 3 | 1 | prepared soups salads | 1600 | Mediterranean Orzo Salad | 20 |
| 4 | 1 | prepared soups salads | 2539 | Original Potato Salad | 20 |
| 5 | 1 | prepared soups salads | 2941 | Broccoli Salad | 20 |
| 6 | 1 | prepared soups salads | 3991 | Moms Macaroni Salad | 20 |
| 7 | 1 | prepared soups salads | 4112 | Chopped Salad Bowl Italian Salad with Salami &... | 20 |
| 8 | 1 | prepared soups salads | 4369 | American Potato Salad | 20 |
| 9 | 1 | prepared soups salads | 4977 | Mushroom Barley Soup | 20 |
| 10 | 1 | prepared soups salads | 5351 | Smoked Whitefish Salad | 20 |
| 11 | 1 | prepared soups salads | 5653 | Chicken Curry Salad | 20 |
| 12 | 1 | prepared soups salads | 6778 | Soup, Golden Quinoa and Kale | 20 |
| 13 | 1 | prepared soups salads | 8121 | Split Pea Soup | 20 |
| 14 | 1 | prepared soups salads | 8382 | Organic Tomato Bisque | 20 |
| 15 | 1 | prepared soups salads | 8946 | Organic Spinach Pow Salad | 20 |
| 16 | 1 | prepared soups salads | 9431 | San Francisco Potato Salad | 20 |
| 17 | 1 | prepared soups salads | 10059 | Quinoa Salad Pistachio Citrus | 20 |
| 18 | 1 | prepared soups salads | 10288 | Broccoli with Almond Soup | 20 |
| 19 | 1 | prepared soups salads | 10617 | Butternut Squash Cumin Soup | 20 |
tabel2=pd.merge(tabel1,order_products,on='product_id')
tabel2.head(n=20)
| aisle_id | aisle | product_id | product_name | department_id | order_id | add_to_cart_order | reordered | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 94246 | 5 | 0 |
| 1 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 192465 | 2 | 1 |
| 2 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 195206 | 18 | 1 |
| 3 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 227717 | 1 | 1 |
| 4 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 260072 | 13 | 0 |
| 5 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 289399 | 4 | 1 |
| 6 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 340960 | 7 | 1 |
| 7 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 344099 | 10 | 0 |
| 8 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 379434 | 7 | 0 |
| 9 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 472683 | 4 | 0 |
| 10 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 473054 | 5 | 1 |
| 11 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 520382 | 11 | 0 |
| 12 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 600934 | 3 | 1 |
| 13 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 632958 | 5 | 1 |
| 14 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 650024 | 14 | 1 |
| 15 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 657646 | 4 | 1 |
| 16 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 686260 | 1 | 0 |
| 17 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 789744 | 3 | 0 |
| 18 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 836624 | 2 | 0 |
| 19 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 909037 | 2 | 0 |
tabel3=pd.merge(tabel2,orders,on='order_id')
tabel3.head(n=20)
| aisle_id | aisle | product_id | product_name | department_id | order_id | add_to_cart_order | reordered | user_id | eval_set | order_number | order_dow | order_hour_of_day | days_since_prior_order | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | prepared soups salads | 209 | Italian Pasta Salad | 20 | 94246 | 5 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 1 | 1 | prepared soups salads | 22853 | Pesto Pasta Salad | 20 | 94246 | 4 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 2 | 4 | instant foods | 12087 | Chicken Flavor Ramen Noodle Soup | 9 | 94246 | 15 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 3 | 4 | instant foods | 47570 | Original Flavor Macaroni & Cheese Dinner | 9 | 94246 | 14 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 4 | 13 | prepared meals | 10089 | Dolmas | 20 | 94246 | 25 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 5 | 13 | prepared meals | 19687 | Butternut Squash With Cranberries | 20 | 94246 | 6 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 6 | 24 | fresh fruits | 13176 | Bag of Organic Bananas | 4 | 94246 | 24 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 7 | 24 | fresh fruits | 14159 | Seedless Watermelon | 4 | 94246 | 1 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 8 | 24 | fresh fruits | 36082 | Organic Mango | 4 | 94246 | 11 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 9 | 51 | preserved dips spreads | 19415 | Roasted Tomato Salsa Serrano-Tomatillo | 13 | 94246 | 26 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 10 | 61 | cookies cakes | 46373 | Donuts, Powdered | 19 | 94246 | 21 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 11 | 63 | grains rice dried goods | 26313 | Pad Thai Noodles | 9 | 94246 | 2 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 12 | 66 | asian foods | 41481 | Kung Pao Noodles | 6 | 94246 | 3 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 13 | 77 | soft drinks | 19125 | Extra Ginger Brew Jamaican Style Ginger Beer | 7 | 94246 | 27 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 14 | 81 | canned jarred vegetables | 14962 | Hearts of Palm | 15 | 94246 | 12 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 15 | 83 | fresh vegetables | 9839 | Organic Broccoli | 4 | 94246 | 18 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 16 | 83 | fresh vegetables | 29139 | Red Creamer Potato | 4 | 94246 | 20 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 17 | 83 | fresh vegetables | 30027 | Organic Chard Green | 4 | 94246 | 17 | 0 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 18 | 83 | fresh vegetables | 41690 | California Cauliflower | 4 | 94246 | 19 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
| 19 | 83 | fresh vegetables | 46979 | Asparagus | 4 | 94246 | 23 | 1 | 114082 | prior | 26 | 0 | 20 | 1.0 |
# 做user_id和aisle的交叉表
table=pd.crosstab(tabel3['user_id'],tabel3['aisle'])
table
| aisle | air fresheners candles | asian foods | baby accessories | baby bath body care | baby food formula | bakery desserts | baking ingredients | baking supplies decor | beauty | beers coolers | ... | spreads | tea | tofu meat alternatives | tortillas flat bread | trail mix snack mix | trash bags liners | vitamins supplements | water seltzer sparkling water | white wines | yogurt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | |||||||||||||||||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 0 | 3 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | ... | 3 | 1 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 42 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 4 | 1 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 5 | 0 | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 206205 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 |
| 206206 | 0 | 4 | 0 | 0 | 0 | 0 | 4 | 1 | 0 | 0 | ... | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 206207 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... | 3 | 4 | 0 | 2 | 1 | 0 | 0 | 11 | 0 | 15 |
| 206208 | 0 | 3 | 0 | 0 | 3 | 0 | 4 | 0 | 0 | 0 | ... | 5 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 33 |
| 206209 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 |
206209 rows × 134 columns
transfer=sklearn.decomposition.PCA(n_components=0.95)
new_table=transfer.fit_transform(table)
new_table.shape
# 降维成功从134个特征到44个特征
(206209, 44)
机器学习算法训练
详解转换器类和预估器类
-
回顾之前的特征工程,我们对数据做处理前都要实例化一个转换器类,再调用fit_tranform方法进行转换。实际上fit_transform方法是fit方法和transform方法的一个封装。fit方法计算特定转换所需的的数据。最后由transform方法完成最后的转换。
-
如同特征工程要实例化一个转换器,在机器学习算法中我们要实例化一个估计器类。

-
利用估计器进行机器学习的流程
(1)实例化一个估计器estimator
(2)调用fit方法——训练计算出模型
(3)模型评估
(i)直接比较预测值和真实值来评价模型
y_predict=estimator.predict(test_data)
y_predict==test_target
(ii)计算模型准确率评估模型
accuracy=estimator.score(test_data,test_target)

模型选择与调优
-
超参数:在实例化estimator时传递的参数被称为超参数(hyper-parameters)
-
n折交叉验证:是将训练集再划分为n部分,依次去取中一份作为Validation Set,其余分作为Train Set。取n次模型验证得分的均值作为模型得分。可以配合网格搜索来做模型选择。
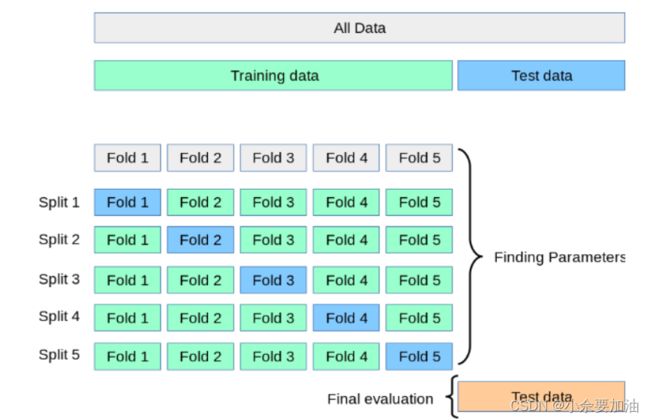
-
网格搜索:是我们给出超参数的组合,它通过遍历的方式根据交叉验证得分得到使得模型最佳的超参数组合

-
sklerarn的模型选择可以用model_selection做

-
注意:最终模型准确率和交叉验证的最佳准确率并不相同,是因为交叉验证的最佳准确率是用验证集得到的,而最终模型评价的准确率是用测试集得到的
-
实例化的GridSearchCV类实现了fit(计算)和score(模型评估)等的方法。于是可直接用于模型训练和评估