【AI Studio】飞桨图像分类零基础训练营 - 04&5&6 - 图像分类竞赛全流程实战
前言:因为两课讲的一个比赛内容(课程里也没分页),所以我把笔记也合在一起。而且也是因为老师讲得很飘,所以我感觉我想记的东西估计不多吧。因为大部分都是新概念,所以我自己也没什么全新的理解,基本都是复制粘贴老师的笔记。
第四第五课主要围绕“柠檬分类竞赛”讲的,这篇笔记主要总结(拷贝)老师的讲课内容。关于完整的代码流程另外立一篇博客。
目录
- 【AI Studio】飞桨图像分类零基础训练营
- 04 - 图像分类竞赛全流程实战
-
- 一、EDA(Exploratory Data Analysis)与数据预处理
-
- 1.EDA(Exploratory Data Analysis)
- 2.数据预处理
-
- ①概念:图像标准化 与 归一化
- ②数据集划分
- 二、Baseline选择
-
- 1.SubClass
- 2.网络结构可视化
- 3.VisualDL模块 - 训练过程可视化
- 4.总结
- 三、竞赛完整流程总结
- 四、常用调参技巧
-
- 1.数据处理部分
-
- ①label shuffling (标签洗牌)
- ②图像扩增
- 2.模型训练部分
-
- ①标签平滑(LSR)
- ②One-Hot编码(独热编码)
- ③优化算法选择
- ④学习率调整策略
- ⑤预训练模型
- ⑥软标签&硬标签
- 五、完整代码&流程分析
- 05 - 飞桨图像分类套件 PaddleClas
-
- 一、PaddleClas 是什么?
- 二、PaddleClas使用流程
-
- 1.前置条件
- 2.准备数据集
- 3.模型训练与评估
- 三、图像增广
- 06 - 模型部署
———————————————
【AI Studio】飞桨图像分类零基础训练营
04 - 图像分类竞赛全流程实战
课程项目:图像分类课程(1)
https://aistudio.baidu.com/aistudio/projectdetail/1625783
一、EDA(Exploratory Data Analysis)与数据预处理
1.EDA(Exploratory Data Analysis)
- 探索性数据分析(Exploratory Data Analysis,简称EDA),是指对已有的数据(原始数据)进行分析探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。一般来说,我们最初接触到数据的时候往往是毫无头绪的,不知道如何下手,这时候探索性数据分析就非常有效。
- 对于图像分类任务,我们通常首先应该统计出每个类别的数量,查看训练集的数据分布情况。通过数据分布情况分析赛题,形成解题思路。(洞察数据的本质很重要。)
- 数据分析的一些建议
- 写出一系列你自己做的假设,然后接着做更深入的数据分析;
- 记录自己的数据分析过程,防止出现遗忘;
- 把自己的中间的结果给自己的同行看看,让他们能够给你一些更有拓展性的反馈、或者意见(即open to everybody);
- 可视化分析结果;
- 介绍一个API
pandas.read_csv, 作为常用的读取数据的常用API,使用频率非常高。 - 如果数据集中的标签是用
.csv文件记录的,那就需要用这个API读取解析。
# 数据EDA
df = pd.read_csv('data/data71799/lemon_lesson/train_images.csv')
# print(df)
d=df['class_num'].hist().get_figure()
# 可返回一个直方图,然后打印。
print(d)
# d.savefig('2.jpg')
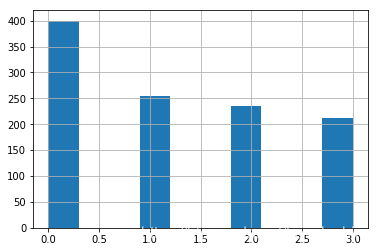
- 知识点 图像分类竞赛常见难点
- 类别不均衡
One-Shot和Few-Shot分类- 细粒度分类
- 柠檬分类竞赛难点
- 限制模型大小
- 数据量小(训练集1102张图片)
2.数据预处理
Compose实现将用于数据集预处理的接口以列表的方式进行组合。
# 定义数据预处理
data_transforms = T.Compose([
T.Resize(size=(32, 32)),
T.Transpose(), # HWC -> CHW
T.Normalize(
mean=[0, 0, 0], # 归一化
std=[255, 255, 255],
to_rgb=True)
])
①概念:图像标准化 与 归一化
最常见的对图像预处理方法有两种,一种叫做图像标准化处理,另外一种方法叫做归一化处理。
- 数据的标准化是指将数据按照比例缩放,使之落入一个特定的区间。将数据通过去均值,实现中心化。处理后的数据呈正态分布,即均值为零。
- 数据归一化是数据标准化的一种典型做法,即将数据统一映射到[0,1]区间上。
作用
- 有利于初始化的进行
- 避免给梯度数值的更新带来数值问题
- 有利于学习率数值的调整
- 加快寻找最优解速度

# ?什么是数值问题?这这个等式居然不相等!?
421*0.00243 == 0.421*2.43
# False
- 标准化代码:输出范围在(-1,1)内,符合正态分布。
import numpy as np
from PIL import Image
from paddle.vision.transforms import Normalize
normalize_std = Normalize(mean=[127.5, 127.5, 127.5],
std=[127.5, 127.5, 127.5],
data_format='HWC')
fake_img = Image.fromarray((np.random.rand(300, 320, 3) * 255.).astype(np.uint8))
fake_img = normalize_std(fake_img)
# print(fake_img.shape)
print(fake_img)
- 归一化代码:输出范围在(0,1)内。
import numpy as np
from PIL import Image
from paddle.vision.transforms import Normalize
normalize = Normalize(mean=[0, 0, 0],
std=[255, 255, 255],
data_format='HWC')
fake_img = Image.fromarray((np.random.rand(300, 320, 3) * 255.).astype(np.uint8))
fake_img = normalize(fake_img)
# print(fake_img.shape)
print(fake_img)
②数据集划分
- 读取标签,依旧是八二分,训练集八,验证集二。(代码略)
- 这次把路径读取也写入到类中了,然后继承父类,“一步到位”。
# 构建Dataset
class MyDataset(paddle.io.Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, train_list, val_list, mode='train'):
"""
步骤二:实现构造函数,定义数据读取方式
"""
super(MyDataset, self).__init__()
self.data = []
# 借助pandas读取csv文件
self.train_images = train_list
self.test_images = val_list
if mode == 'train':
# 读train_images.csv中的数据
for row in self.train_images.itertuples():
self.data.append(['data/data71799/lemon_lesson/train_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
else:
# 读test_images.csv中的数据
for row in self.test_images.itertuples():
self.data.append(['data/data71799/lemon_lesson/train_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.data[index][0])
label = self.data[index][1]
return data_transforms(image), np.array(label, dtype='int64')
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
二、Baseline选择
- 看完老师的讲解,对这个标题不是很理解。只能大概猜测
Baseline(基准)就是:基本流程。
理想情况中,模型越大拟合能力越强,图像尺寸越大,保留的信息也越多。在实际情况中模型越复杂训练时间越长,图像输入尺寸越大训练时间也越长。 比赛开始优先使用最简单的模型(如
ResNet),快速跑完整个训练和预测流程;分类模型的选择需要根据任务复杂度来进行选择,并不是精度越高的模型越适合比赛。 在实际的比赛中我们可以逐步增加图像的尺寸,比如先在64 * 64的尺寸下让模型收敛,进而将模型在128 * 128的尺寸下训练,进而到224 * 224的尺寸情况下,这种方法可以加速模型的收敛速度。
Baseline应遵循以下几点原则:
- 复杂度低,代码结构简单。
Loss收敛正确,评价指标(metric)出现相应提升(如accuracy/AUC之类的)- 迭代快速,没有很复杂(
Fancy)的模型结构/Loss function/图像预处理方法之类的- 编写正确并简单的测试脚本,能够提交
submission后获得正确的分数
1.SubClass
- 上节课笔记中提到了2种组网方式,下面详细介绍一下专业术语的说法。
模型组网方式
- 对于组网方式,飞桨框架统一支持
Sequential或SubClass的方式进行模型的组建。我们根据实际的使用场景,来选择最合适的组网方式。
- 如针对顺序的线性网络结构我们可以直接使用
Sequential,相比于SubClass,Sequential可以快速的完成组网。- 如果是一些比较复杂的网络结构,我们可以使用
SubClass定义的方式来进行模型代码编写,在__init__构造函数中进行Layer的声明,在forward中使用声明的Layer变量进行前向计算。通过这种方式,我们可以组建更灵活的网络结构。
- 第三节课笔记中的第2个线性模型例子
SoftMAx分类器就是使用Sequential方法,打包几层网络直接当模型。 - 注意!!
Sequential方法有一个特点,模型封装时和SubClass方法不太一样。
# 构建模型。
linear=paddle.nn.Sequential(
paddle.nn.Flatten(),#将[1,28,28]形状的图片数据改变形状为[1,784]
paddle.nn.Linear(784,10)
)
# 模型封装
model = paddle.Model(linear()) !!会报错!!
model = paddle.Model(linear) # 不会报错
- 第三节课笔记中的第3个线性模型例子
多层感知机模型就是使用SubClass方法。
# 构建模型。
def forward(self, x):
x=self.flatten(x)
x=self.hidden(x) #经过隐藏层
x=F.relu(x) #经过激活层
x=self.output(x)
return x
# 模型封装
model = paddle.Model(linear()) # 不会报错
- 对于复杂的网络,往往是2种相互组合嵌套,无限套娃。比如上节课笔记中的
AlexNet卷积网络模型。一般建议这么使用,不过也希望减少Sequential方法的使用,不方便看。 - 最后就使用API:封装模型
paddle.Model();然后选优化器、损失函数、评估方法model.prepare();最后开始训练模型,丢数据集、设定批次轮次等参数model.fit()。
2.网络结构可视化
- 通过
summary打印网络的基础结构和参数信息。相当重要!!!!! - 对于
summary中的参数,我个人理解是:(一张图像,一通道(灰度一,彩色三),图像长,图像宽);即一次传入模型的数据形状,然后模型就会把这个形状在模型中变化的情况
# 用Model封装模型
model = paddle.Model(LeNet_5()) # 先给模型,然后再调用 summary
model.summary((1, 1, 28, 28)) # 元组的含义(个人理解):(一张图像,一通道(灰度一,彩色三),图像长,图像宽)
# 下面是返回,我使用的是第二课的作业,也就是第二课笔记的第五个模型例子 LeNet_5()
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-5 [[1, 1, 28, 28]] [1, 6, 24, 24] 156
MaxPool2D-5 [[1, 6, 24, 24]] [1, 6, 12, 12] 0
Conv2D-6 [[1, 6, 12, 12]] [1, 16, 8, 8] 2,416
MaxPool2D-6 [[1, 16, 8, 8]] [1, 16, 4, 4] 0
Linear-9 [[1, 256]] [1, 120] 30,840
Linear-10 [[1, 120]] [1, 84] 10,164
Linear-11 [[1, 84]] [1, 10] 850
===========================================================================
Total params: 44,426
Trainable params: 44,426
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.04
Params size (MB): 0.17
Estimated Total Size (MB): 0.22
---------------------------------------------------------------------------
{'total_params': 44426, 'trainable_params': 44426}
- 如果没有这个指令,就要自己手动计算卷积模型的输出 特征图 尺寸了。(上一课简单介绍了一下,其实完整的公式是这样的)

3.VisualDL模块 - 训练过程可视化
- 我也不怎么会用这个模块,一次都没成功打开loss图像。好像也有人遇到和我一样的情况,怀疑是官方bug。每次网站都加载失败。打开模型流程图倒是很正常。
- 下面的代码是从课程项目里截取了。具体的
VisualDL模块使用教程在飞桨文档中有详细记载。注意继承paddle.callbacks.Callback的东西
VisualDL 使用指南
https://www.paddlepaddle.org.cn/documentation/docs/zh/guides/03_VisualDL/visualdl_usage.html
# 调用飞桨框架的VisualDL模块,保存信息到目录中。
# callback = paddle.callbacks.VisualDL(log_dir='visualdl_log_dir')
from visualdl import LogReader, LogWriter
# 把一些参数用字典打包
args={
'logdir':'./vdl',
'file_name':'vdlrecords.model.log',
'iters':0,
}
# 配置visualdl
write = LogWriter(logdir=args['logdir'], file_name=args['file_name'])
#iters 初始化为0
iters = args['iters']
#自定义Callback
class Callbk(paddle.callbacks.Callback):
def __init__(self, write, iters=0):
self.write = write
self.iters = iters
def on_train_batch_end(self, step, logs):
self.iters += 1
#记录loss
self.write.add_scalar(tag="loss",step=self.iters,value=logs['loss'][0])
#记录 accuracy
self.write.add_scalar(tag="acc",step=self.iters,value=logs['acc'])
4.总结
- baseline选择技巧
- 模型:复杂度小的模型可以快速迭代。
- optimizer:推荐Adam,或者SGD
- Loss Function: 多分类Cross entropy;
- metric:以比赛的评估指标为准。
- 数据增强:数据增强其实可为空,或者只有一个HorizontalFlip即可。
- 图像分辨率:初始最好就用小图,如224*224之类的。
- 如何提升搭建baseline的能力
- 鲁棒的baseline,等价于好的起点,意味着成功了一半。
- 阅读top solution的开源代码,取其精华,去其糟粕。
- 积累经验,多点实践,模仿他人,最后有着属于自己风格的一套。
三、竞赛完整流程总结
- 第一部分(数据处理)
- 数据预处理
- 自定义数据集
- 定义数据加载器
- 第二部分(模型训练)
- 模型组网
- 模型封装(Model对象是一个具备训练、测试、推理的神经网络。)
- 模型配置(配置模型所需的部件,比如优化器、损失函数和评价指标。)
- 模型训练&验证
- 第三部分(提交结果)
- 模型预测
- 生成提交结果(pandas)
四、常用调参技巧
- 为什么需要调参技巧
- 调参是比赛环节里非常重要的一步,即使在日常工作里也不可避免。
- 合适的
learning rate对比不合适的learning rate,得到的结果差异非常大。- 模型的调优,很大一部分的收益其实多是从调参中获得的。
- 在一些数据没有很明显的特点的比赛任务里,最后的名次往往取决于你的调参能力。
- 接下来,我将结合刚刚总结的三个部分介绍每个步骤中常用的一些调参技巧。
1.数据处理部分
①label shuffling (标签洗牌)
首先对原始的图像列表,按照标签顺序进行排序; 然后计算每个类别的样本数量,并得到样本最多的那个类别的样本数。 根据这个最多的样本数,对每类都产生一个随机排列的列表; 然后用每个类别的列表中的数对各自类别的样本数求余,得到一个索引值,从该类的图像中提取图像,生成该类的图像随机列表; 然后把所有类别的随机列表连在一起,做个Random Shuffling,得到最后的图像列表,用这个列表进行训练。
-
下图是课程项目里给出的一种补充图像数据的方法。因为训练集中各个标签的数目不均衡,可能导致模型会过拟合某类标签,所以需要吧各个标签的数目都变成一样。课程教程中只是把已有的数据复制粘贴到数目一样。(这样多了相同的数据集,会不会不好的,应该加图像处理可能比较好。)

-
具体代码在下一篇的竞赛程序流程中再说明。
②图像扩增
为了获得更多数据,我们只需要对现有数据集进行微小改动。例如翻转剪裁等操作。对图像进行微小改动,模型就会认为这些是不同的图像。常用的有两种数据增广方法: 第一个方法称为离线扩充。对于相对较小的数据集,此方法是首选。 第二个方法称为在线增强,或即时增强。对于较大的数据集,此方法是首选。
- 个人对
图像扩增和图像增强的理解,其中图像增强是对每个数据都做概率性随机改变,而图像扩增则应该是原有的图片不变的基础上复制一份,然后再做图像增强。 - 而这些都包含在图像的
预处理中:(不过预处理其中对图像的标准化和归一化操作一直不是很懂。)
在图像分类任务中常见的数据增强有翻转、旋转、随机裁剪、颜色噪音、平移等,具体的数据增强方法要根据具体任务来选择,要根据具体数据的特定来选择。对于不同的比赛来说数据扩增方法一定要反复尝试,会很大程度上影响模型精度。飞桨2.0中的预处理方法:

2.模型训练部分
①标签平滑(LSR)
在分类问题中,一般最后一层是全连接层,然后对应one-hot编码,这种编码方式和通过降低交叉熵损失来调整参数的方式结合起来,会有一些问题。这种方式鼓励模型对不同类别的输出分数差异非常大,或者说模型过分相信他的判断,但是由于人工标注信息可能会出现一些错误。模型对标签的过分相信会导致过拟合。
标签平滑可以有效解决该问题,它的具体思想是降低我们对于标签的信任,例如我们可以将损失的目标值从1稍微降到0.9,或者将从0稍微升到0.1。总的来说,标签平滑是一种通过在标签y中加入噪声,实现对模型约束,降低模型过拟合程度的一种正则化方法
-
在之前学习过的概念中,就是正则化过程。
-
在之前吴恩达的课程中介绍的是,在模型训练时会随机把部分网络神经元中的输出改为0,这样模型的参数变化量就大大地减少了,起到模型缩小的功能。不过吴恩达老师提出不一样的看法~~(具体忘记了)~~ 。不过一样的是,认为正则化可以减少模型的过拟合。
-
不过在老师的教学项目中,在图像数据预处理的过程中,还提到了直接把标签变模糊。具体操作就是把分类标签
[0 1 0 0]变为[0.1 0.9 0.1 0.1]这种形式。感觉也能起到防止过拟合的目的。而且飞桨文档中提到,这种操作也叫正则化。和我之前的理解不太一样。
飞桨API文档:label_smooth
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/functional/common/label_smooth_cn.html#label-smooth
import paddle
import numpy as np
x_data = np.array([[[0, 1, 0],
[ 1, 0, 1]]]).astype("float32")
print(x_data.shape)
x = paddle.to_tensor(x_data, stop_gradient=False)
output = paddle.nn.functional.label_smooth(x)
print(output)
#[[[0.03333334 0.93333334 0.03333334]
# [0.93333334 0.03333334 0.93333334]]]
②One-Hot编码(独热编码)
One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
- 离散特征的编码分为两种情况:
- 离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
- 离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3},标签编码
没看懂……
③优化算法选择
优化器Adam下,初始学习率init_lr=3e-4,3e-4号称是Adam最好的初始学习率,SGD比较更考验调参功力。(来自一位国外dalao的经验发言)
④学习率调整策略
为什么要进行学习率调整?
当我们使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点。

- 其实还是蛮好理解的。一开始训练离“谷底”远,所以步子大一点。而当准确率到达90%以上后,就要小步子走,不然容易出现在“谷底”左右反复横跳。
- 但是又有另一个,因为如果步子小,很有可能会卡在平缓的“坑洼”地段。这就很麻烦了。因为loss图像的无法预测性,学习率调整一直都是个重要考虑的问题。
飞桨2.0学习率调整相关API
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/Overview_cn.html#about-lr
- 这里只介绍一个飞桨API中的
余弦退火(Cosine annealing)函数
当我们使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点,而
余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。

⑤预训练模型
- 如果每次训练模型时,参数都是从头开始调,效率就太低了。我们可以投机取巧,把别人已经训练好的模型和参数拿来用。
(在做课程作业时,直接用预效率模型轻易达到80%以上了)
⑥软标签&硬标签
- 在做这一课的“柠檬分类”作业时,训练模型一直报错,我一直没找出到底有什么问题。最后崩溃的打开别人写好的代码,一行行对照,看到底是哪里错了。把所有多余内容删了,只剩几行一一对应时,终于发现,原来是交叉熵损失函数中的软硬标签参数没配置为软标签。我……
加斜强迫重点 - 虽然找到了问题,但是我还是不知道为什么一定要开软标签。
在群里问也没人回应。我个人猜测是因为我的标签变不确定了,所以就一定要开软标签?
飞桨文档:CrossEntropyLoss
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/layer/loss/CrossEntropyLoss_cn.html#canshu
# 配置模型
model.prepare(
optim,
paddle.nn.CrossEntropyLoss(soft_label=True), # 这个参数就是切换软硬标签的。
Accuracy()
)
五、完整代码&流程分析
- 另外开篇详细记载干货。这篇略。(其实就是上面内容的代码化)
05 - 飞桨图像分类套件 PaddleClas
第五节课主要讲解了飞桨下的
PaddleClas库,第四节课已经详细介绍比赛流程中需要做的。这一节课讲扩展知识,在某些点上的捷径。
项目地址:图像分类课程(2)
https://aistudio.baidu.com/aistudio/projectdetail/1647139
一、PaddleClas 是什么?
PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。PaddleClas提供了基于图像分类的模型训练、评估、预测、部署全流程的服务,方便大家更加高效地学习图像分类。
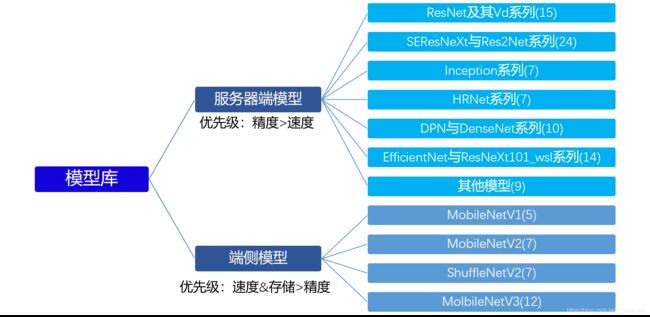
下面将从PaddleClas模型库概览、特色应用、快速上手、实践应用几个方面介绍PaddleClas实践方法:
- PaddleClas模型库概览:概要介绍PaddleClas有哪些分类网络结构和预训练模型。
- PaddleClas柠檬竞赛实战:重点介绍数据增广方法。
-
- 个人理解:老师的重点是:
-
- 作为程序员,“不要重复造车轮”。模型库里有很多预训练模型,使用它们能大大减少训练时间。
-
- 选择模型时要考虑模型的体量大小 ,结合实际运用。很多模型运行起来需要强大的算力支持,普通设备运行效率极低。
-
- 这次柠檬竞赛中就要求模型要在移动端部署,那么我们可以通过图表选择合适的网络模型。(入门就选最左上吧,省事。)
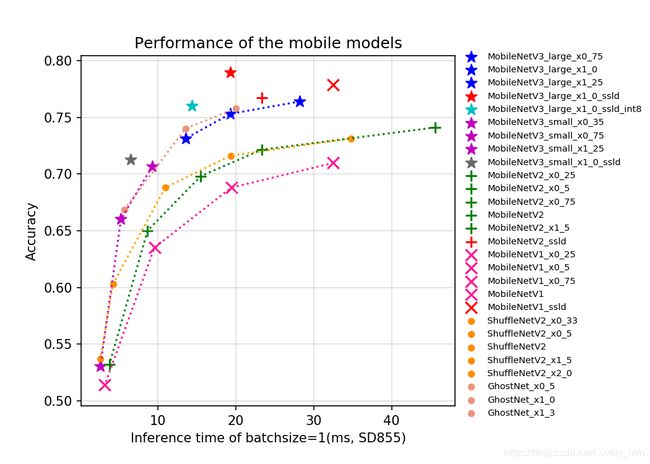
- 这次柠檬竞赛中就要求模型要在移动端部署,那么我们可以通过图表选择合适的网络模型。(入门就选最左上吧,省事。)
二、PaddleClas使用流程
1.前置条件
- 安装Python3.5或更高版本版本。
- 安装PaddlePaddle 1.7或更高版本,具体安装方法请参见快速安装。由于图像分类模型计算开销大,推荐在
GPU版本的PaddlePaddle下使用PaddleClas。 - 下载PaddleClas的代码库。
- 安装Python依赖库。Python依赖库在requirements.txt中给出。(本地)
- 设置PYTHONPATH环境变量(本地)
2.准备数据集
PaddleClas数据准备文档提供了ImageNet1k数据集以及flowers102数据集的准备过程。当然,如果大家希望使用自己的数据集,则需要至少准备以下两份文件。
- 训练集图像,以图像文件形式保存。
- 训练集标签文件,以文本形式保存,每一行的文件都包含文件名以及图像标签,以空格隔开。下面给出一个示例。
- 有点特别的是,PaddleClas在使用时需要用到一个参数配置文件,感觉有点像超文本语言那样,之前在学ROS时接触过。
TRAIN: # 训练配置
batch_size: 32 # 训练的batch size
num_workers: 4 # 每个trainer(1块GPU上可以视为1个trainer)的进程数量
file_list: "./dataset/flowers102/train_list.txt" # 训练集标签文件,每一行由"image_name label"组成
data_dir: "./dataset/flowers102/" # 训练集的图像数据路径
shuffle_seed: 0 # 数据打散的种子
transforms: # 训练图像的数据预处理
- DecodeImage: # 解码
to_rgb: True
to_np: False
channel_first: False
- RandCropImage: # 随机裁剪
size: 224
- RandFlipImage: # 随机水平翻转
flip_code: 1
- NormalizeImage: # 归一化
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: ''
- ToCHWImage: # 通道转换
- 题外话:老师还推荐了
PaddleXAPI工具,能图形化部署模型,且有一键切分数据集功能。是一个软件,但是功能有点少,具体用法查飞桨手册。
3.模型训练与评估
知识点:迁移学习
什么是迁移学习?为什么要用迁移学习
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
- 在自己的数据集上训练分类模型时,更推荐加载预训练进行微调。
- 模型微调:30分钟玩转PaddleClas中包含大量模型微调的示例,可以参考该章节进行模型微调。
- 模型评估;
以上内容都略过了,项目里都有详细代码,我这里就不复制粘贴了。
三、图像增广
ImageNet1k数据集包含128W张图片,即使不加其他策略训练,一般也能获得很高的精度,而在大部分实际场景中,都无法获得这么多的数据,这也会导致训练结果很差,通过一些数据增广的方式去扩充训练样本,可以增加训练样本的丰富度,提升模型的泛化性能。PaddleClas开源了8种数据增广方案。包括图像变换类、图像裁剪类以及图像混叠类。经过实验验证,ResNet50模型在ImageNet数据集上, 与标准变换相比,采用数据增广,识别准确率最高可以提升1%。

- 之前讲过图像增强,这次强调的是图像增广。一顿骚操作下来,虽然准确率提高了1%,但是已经很好了。
下面这个流程图是图片预处理并被送进网络训练的一个过程,需要经过解码、随机裁剪、水平翻转、归一化、通道转换以及组batch,最终训练的过程。

- 图像变换类:图像变换类是在随机裁剪与翻转之间进行的操作,也可以认为是在原图上做的操作。主要方式包括
AutoAugment和RandAugment,基于一定的策略,包括锐化、亮度变化、直方图均衡化等,对图像进行处理。这样网络在训练时就已经见过这些情况了,之后在实际预测时,即使遇到了光照变换、旋转这些很棘手的情况,网络也可以从容应对了。 - 图像裁剪类:图像裁剪类主要是在生成的在通道转换之后,在图像上设置掩码,随机遮挡,从而使得网络去学习一些非显著性的特征。否则网络一直学习很重要的显著性区域,之后在预测有遮挡的图片时,泛化能力会很差。主要方式包括:
CutOut、RandErasing、HideAndSeek、GridMask。这里需要注意的是,在通道转换前后去做图像裁剪,其实是没有区别的。因为通道转换这个操作不会修改图像的像素值。 - 图像混叠类:组完batch之后,图像与图像、标签与标签之间进行混合,形成新的batch数据,然后送进网络进行训练。这也就是图像混叠类数据增广方式,主要的有Mixup与Cutmix两种方式。
-
重点!!!注意,使用对图像处理的方法虽多,但要慎重选择,结合实际。在对数据处理后,很有可能就对不少原本的标签,那反而误导了模型训练。
-
打比方就是,有可能不同标签的之间的区别就只有一点点,图像增广就这么去掉了这点区别,但是训练时的标签还是原来的。夸张点的例子就是像下图,对柠檬处理,这种柠檬还能要吗……

-
剩下的几点是模型推理和预测,代码详列之类的。这里略过。
06 - 模型部署
第六节课,最后一节讲了模型的部署。很主要,最后训练好模型,就是要投入到运用中,这样才有实感。
但是好高深……没听懂所以我直接不纠结,略过了……之后学完学透后,再回来补怎么模型部署。
课程项目:日本广岛Quest2020:柠檬外观分类竞赛部署实践
https://aistudio.baidu.com/aistudio/projectdetail/1647097