《机器学习实战》学习笔记:绘制树形图&使用决策树预测隐形眼镜类型
上一节实现了决策树,但只是使用包含树结构信息的嵌套字典来实现,其表示形式较难理解,显然,绘制直观的二叉树图是十分必要的。Python没有提供自带的绘制树工具,需要自己编写函数,结合Matplotlib库创建自己的树形图。这一部分的代码多而复杂,涉及二维坐标运算;书里的代码虽然可用,但函数和各种变量非常多,感觉非常凌乱,同时大量使用递归,因此只能反复研究,反反复复用了一天多时间,才差不多搞懂,因此需要备注一下。
一.绘制属性图
这里使用Matplotlib的注解工具annotations实现决策树绘制的各种细节,包括生成节点处的文本框、添加文本注释、提供对文字着色等等。在画一整颗树之前,最好先掌握单个树节点的绘制。一个简单实例如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 04 01:15:01 2015
@author: Herbert
"""
import matplotlib.pyplot as plt
nonLeafNodes = dict(boxstyle = "sawtooth", fc = "0.8")
leafNodes = dict(boxstyle = "round4", fc = "0.8")
line = dict(arrowstyle = "<-")
def plotNode(nodeName, targetPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeName, xy = parentPt, xycoords = \
'axes fraction', xytext = targetPt, \
textcoords = 'axes fraction', va = \
"center", ha = "center", bbox = nodeType, \
arrowprops = line)
def createPlot():
fig = plt.figure(1, facecolor = 'white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon = False)
plotNode('nonLeafNode', (0.2, 0.1), (0.4, 0.8), nonLeafNodes)
plotNode('LeafNode', (0.8, 0.1), (0.6, 0.8), leafNodes)
plt.show()
createPlot()输出结果:
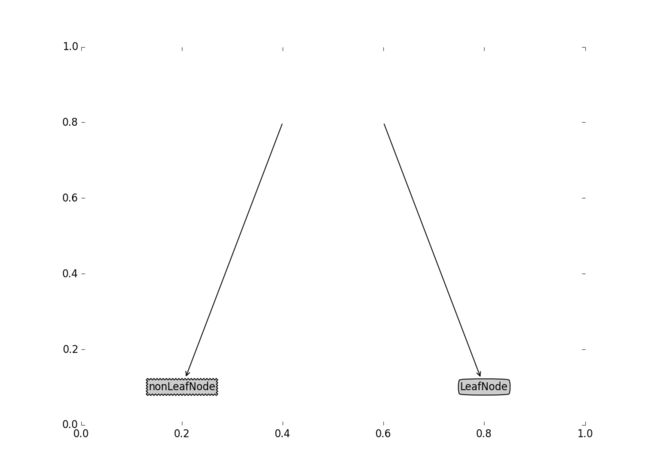
该实例中,plotNode()函数用于绘制箭头和节点,该函数每调用一次,将绘制一个箭头和一个节点。后面对于该函数有比较详细的解释。createPlot()函数创建了输出图像的对话框并对齐进行一些简单的设置,同时调用了两次plotNode(),生成一对节点和指向节点的箭头。
绘制整颗树
这部分的函数和变量较多,为方便日后扩展功能,需要给出必要的标注:
# -*- coding: utf-8 -*-
"""
Created on Fri Sep 04 01:15:01 2015
@author: Herbert
"""
import matplotlib.pyplot as plt
# 部分代码是对绘制图形的一些定义,主要定义了文本框和剪头的格式
nonLeafNodes = dict(boxstyle = "sawtooth", fc = "0.8")
leafNodes = dict(boxstyle = "round4", fc = "0.8")
line = dict(arrowstyle = "<-")
# 使用递归计算树的叶子节点数目
def getLeafNum(tree):
num = 0
firstKey = tree.keys()[0]
secondDict = tree[firstKey]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
num += getLeafNum(secondDict[key])
else:
num += 1
return num
# 同叶子节点计算函数,使用递归计算决策树的深度
def getTreeDepth(tree):
maxDepth = 0
firstKey = tree.keys()[0]
secondDict = tree[firstKey]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
depth = getTreeDepth(secondDict[key]) + 1
else:
depth = 1
if depth > maxDepth:
maxDepth = depth
return maxDepth
# 在前面例子已实现的函数,用于注释形式绘制节点和箭头
def plotNode(nodeName, targetPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeName, xy = parentPt, xycoords = \
'axes fraction', xytext = targetPt, \
textcoords = 'axes fraction', va = \
"center", ha = "center", bbox = nodeType, \
arrowprops = line)
# 用于绘制剪头线上的标注,涉及坐标计算,其实就是两个点坐标的中心处添加标注
def insertText(targetPt, parentPt, info):
xCoord = (parentPt[0] - targetPt[0]) / 2.0 + targetPt[0]
yCoord = (parentPt[1] - targetPt[1]) / 2.0 + targetPt[1]
createPlot.ax1.text(xCoord, yCoord, info)
# 实现整个树的绘制逻辑和坐标运算,使用的递归,重要的函数
# 其中两个全局变量plotTree.xOff和plotTree.yOff
# 用于追踪已绘制的节点位置,并放置下个节点的恰当位置
def plotTree(tree, parentPt, info):
# 分别调用两个函数算出树的叶子节点数目和树的深度
leafNum = getLeafNum(tree)
treeDepth = getTreeDepth(tree)
firstKey = tree.keys()[0] # the text label for this node
firstPt = (plotTree.xOff + (1.0 + float(leafNum)) / 2.0/plotTree.totalW,\
plotTree.yOff)
insertText(firstPt, parentPt, info)
plotNode(firstKey, firstPt, parentPt, nonLeafNodes)
secondDict = tree[firstKey]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], firstPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), \
firstPt, leafNodes)
insertText((plotTree.xOff, plotTree.yOff), firstPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
# 以下函数执行真正的绘图操作,plotTree()函数只是树的一些逻辑和坐标运算
def createPlot(inTree):
fig = plt.figure(1, facecolor = 'white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon = False) #, **axprops)
# 全局变量plotTree.totalW和plotTree.totalD
# 用于存储树的宽度和树的深度
plotTree.totalW = float(getLeafNum(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), ' ')
plt.show()
# 一个小的测试集
def retrieveTree(i):
listOfTrees = [{'no surfacing':{0: 'no', 1:{'flippers':{0:'no', 1:'yes'}}}},\
{'no surfacing':{0: 'no', 1:{'flippers':{0:{'head':{0:'no', \
1:'yes'}}, 1:'no'}}}}]
return listOfTrees[i]
createPlot(retrieveTree(1)) # 调用测试集中一棵树进行绘制
retrieveTree()函数中包含两颗独立的树,分别输入参数即可返回树的参数tree,最后执行createPlot(tree)即得到画图的结果,如下所示:
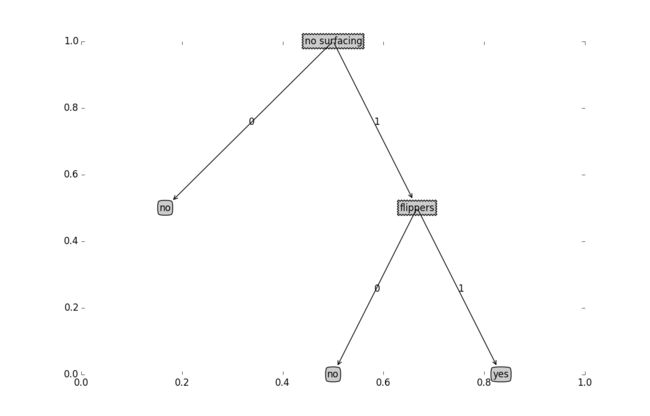
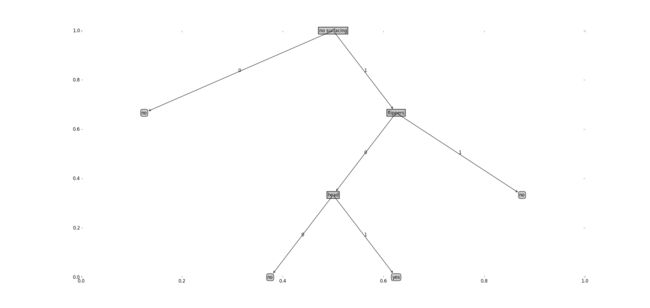
书中关于递归计算树的叶子节点和深度这部分十分简单,在编写绘制属性图的函数时,难度在于这本书中一些绘图坐标的取值以及在计算节点坐标所作的处理,书中对于这部分的解释比较散乱。博客:http://www.cnblogs.com/fantasy01/p/4595902.html 给出了十分详尽的解释,包括坐标的求解和公式的分析,以下只摘取一部分作为了解:
这里说一下具体绘制的时候是利用自定义,如下图:
这里绘图,作者选取了一个很聪明的方式,并不会因为树的节点的增减和深度的增减而导致绘制出来的图形出现问题,当然不能太密集。这里利用整 棵树的叶子节点数作为份数将整个x轴的长度进行平均切分,利用树的深度作为份数将y轴长度作平均切分,并利用plotTree.xOff作为最近绘制的一 个叶子节点的x坐标,当再一次绘制叶子节点坐标的时候才会plotTree.xOff才会发生改变;用plotTree.yOff作为当前绘制的深 度,plotTree.yOff是在每递归一层就会减一份(上边所说的按份平均切分),其他时候是利用这两个坐标点去计算非叶子节点,这两个参数其实就可 以确定一个点坐标,这个坐标确定的时候就是绘制节点的时候
plotTree函数的整体步骤分为以下三步:
绘制自身
若当前子节点不是叶子节点,递归
若当子节点为叶子节点,绘制该节点
以下是plotTree和createPlot函数的详细解析,因此把两个函数的代码单独拿出来了:
# 实现整个树的绘制逻辑和坐标运算,使用的递归,重要的函数
# 其中两个全局变量plotTree.xOff和plotTree.yOff
# 用于追踪已绘制的节点位置,并放置下个节点的恰当位置
def plotTree(tree, parentPt, info):
# 分别调用两个函数算出树的叶子节点数目和树的深度
leafNum = getLeafNum(tree)
treeDepth = getTreeDepth(tree)
firstKey = tree.keys()[0] # the text label for this node
firstPt = (plotTree.xOff + (1.0 + float(leafNum)) / 2.0/plotTree.totalW,\
plotTree.yOff)
insertText(firstPt, parentPt, info)
plotNode(firstKey, firstPt, parentPt, nonLeafNodes)
secondDict = tree[firstKey]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], firstPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), \
firstPt, leafNodes)
insertText((plotTree.xOff, plotTree.yOff), firstPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
# 以下函数执行真正的绘图操作,plotTree()函数只是树的一些逻辑和坐标运算
def createPlot(inTree):
fig = plt.figure(1, facecolor = 'white')
fig.clf()
createPlot.ax1 = plt.subplot(111, frameon = False) #, **axprops)
# 全局变量plotTree.totalW和plotTree.totalD
# 用于存储树的宽度和树的深度
plotTree.totalW = float(getLeafNum(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW
plotTree.yOff = 1.0
plotTree(inTree, (0.5, 1.0), ' ')
plt.show()
首先代码对整个画图区间根据叶子节点数和深度进行平均切分,并且x和y轴的总长度均为1,如同下图:
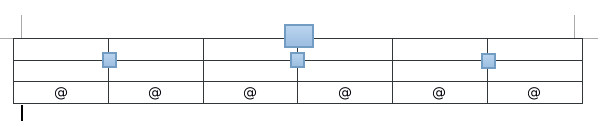
解释如下:
1.图中的方形为非叶子节点的位置,@是叶子节点的位置,因此上图的一个表格的长度应该为: 1/plotTree.totalW,但是叶子节点的位置应该为@所在位置,则在开始的时候 plotTree.xOff 的赋值为: -0.5/plotTree.totalW,即意为开始x 轴位置为第一个表格左边的半个表格距离位置,这样作的好处是在以后确定@位置时候可以直接加整数倍的 1/plotTree.totalW。
2.plotTree函数中的一句代码如下:
firstPt = (plotTree.xOff + (1.0 + float(leafNum)) / 2.0/ plotTree.totalW, plotTree.yOff)其中,变量plotTree.xOff即为最近绘制的一个叶子节点的x轴坐标,在确定当前节点位置时每次只需确定当前节点有几个叶子节点,因此其叶子节点所占的总距离就确定了即为: float(numLeafs)/plotTree.totalW,因此当前节点的位置即为其所有叶子节点所占距离的中间即一半为: float(numLeafs)/2.0/plotTree.totalW,但是由于开始plotTree.xOff赋值并非从0开始,而是左移了半个表格,因此还需加上半个表格距离即为: 1/2/plotTree.totalW,则加起来便为: (1.0 + float(numLeafs))/2.0/plotTree.totalW,因此偏移量确定,则x轴的位置变为: plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW
3.关于plotTree()函数的参数
plotTree(inTree, (0.5, 1.0), ' ')对plotTree()函数的第二个参数赋值为(0.5, 1.0),因为开始的根节点并不用划线,因此父节点和当前节点的位置需要重合,利用2中的确定当前节点的位置为(0.5, 1.0)。
总结:利用这样的逐渐增加x 轴的坐标,以及逐渐降低y轴的坐标能能够很好的将树的叶子节点数和深度考虑进去,因此图的逻辑比例就很好的确定了,即使图像尺寸改变,我们仍然可以看到按比例绘制的树形图。
二.使用决策树预测隐形眼镜类型
这里实现一个例子,即利用决策树预测一个患者需要佩戴的隐形眼镜类型。以下是整个预测的大体步骤:
收集数据:使用书中提供的小型数据集
准备数据:对文本中的数据进行预处理,如解析数据行
分析数据:快速检查数据,并使用
createPlot()函数绘制最终的树形图训练决策树:使用
createTree()函数训练测试决策树:编写简单的测试函数验证决策树的输出结果&绘图结果
使用决策树:这部分可选择将训练好的决策树进行存储,以便随时使用
此处新建脚本文件
saveTree.py,将训练好的决策树保存在磁盘中,这里需要使用Python模块的pickle序列化对象。storeTree()函数负责把tree存放在当前目录下的filename(.txt)文件中,而getTree(filename)则是在当前目录下的filename(.txt)文件中读取决策树的相关数据。
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 05 01:56:04 2015
@author: Herbert
"""
import pickle
def storeTree(tree, filename):
fw = open(filename, 'w')
pickle.dump(tree, fw)
fw.close()
def getTree(filename):
fr = open(filename)
return pickle.load(fr)以下代码实现了决策树预测隐形眼镜模型的实例,使用的数据集是隐形眼镜数据集,它包含很多患者的眼部状况的观察条件以及医生推荐的隐形眼镜类型,其中隐形眼镜类型包括:硬材质(hard)、软材质(soft)和不适合佩戴隐形眼镜(no lenses) , 数据来源于UCI数据库。代码最后调用了之前准备好的createPlot()函数绘制树形图。
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 05 14:21:43 2015
@author: Herbert
"""
import tree
import plotTree
import saveTree
fr = open('lenses.txt')
lensesData = [data.strip().split('\t') for data in fr.readlines()]
lensesLabel = ['age', 'prescript', 'astigmatic', 'tearRate']
lensesTree = tree.buildTree(lensesData, lensesLabel)
#print lensesData
print lensesTree
print plotTree.createPlot(lensesTree)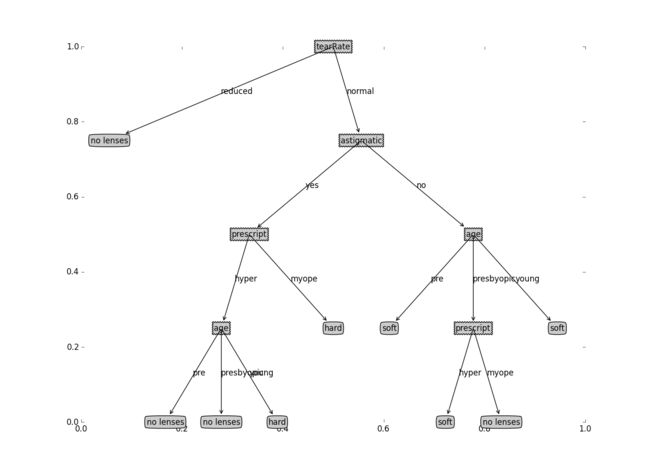
可以看到,前期实现了决策树的构建和绘制,使用不同的数据集都可以得到很直观的结果,从图中可以看到,沿着决策树的不同分支,可以得到不同患者需要佩戴的隐形眼镜的类型。
三.关于本章使用的决策树的总结
回到决策树的算法层面,以上代码的实现基于ID3决策树构造算法,它是一个非常经典的算法,但其实缺点也不少。实际上决策树的使用中常常会遇到一个问题,即“过度匹配”。有时候,过多的分支选择或匹配选项会给决策带来负面的效果。为了减少过度匹配的问题,通常算法设计者会在一些实际情况中选择“剪枝”。简单说来,如果叶子节点只能增加少许信息,则可以删除该节点。
另外,还有几种目前很流行的决策树构造算法:C4.5、C5.0和CART,后期需继续深入研究。
参考资料:http://blog.sina.com.cn/s/blog_7399ad1f01014wec.html