【xml】Jsoup使用
首先创建一项目,需要导入jsoup-1.11.2.jar架包
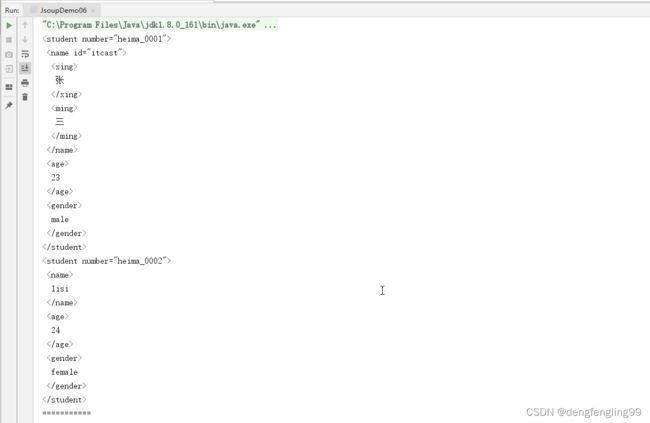
首先创建一个student.xml:
张
三
23
male
lisi
24
female
JsopuDemo01类:
package xml.Jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.io.IOException;
import java.net.URISyntaxException;
public class JsoupDemo01 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path=JsoupDemo01.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//3.获取元素对象 Element
Elements elements = document.getElementsByTag("name");
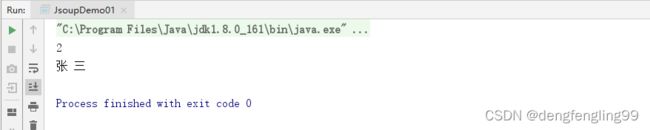
System.out.println(elements.size());
//3.1获取第一个name的Element对象
Element element = elements.get(0);
//3.2获取数据
String name = element.text();
System.out.println(name);
}
}
结果:
JsoupDemo 02类:
package xml.Jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.net.URL;
public class JsoupDemo02 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path= JsoupDemo02.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//System.out.println(document);
//第二种parse(String html):解析xml或html字符串
String str="\n" +
"\n" +
" \n" +
" zhangsan \n" +
" 23 \n" +
" male \n" +
" \n" +
"\n" +
" \n" +
" lisi \n" +
" 24 \n" +
" female \n" +
" \n" +
" ";
Document document1=Jsoup.parse(str);
//System.out.println(document1);
//第三个 parse(URL url,int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
URL url=new URL("https://www.bilibili.com/video/BV1uJ411k7wy?p=670");
Document document2=Jsoup.parse(url,10000);
System.out.println(document2);
}
}
第一个System.out.println的结果:
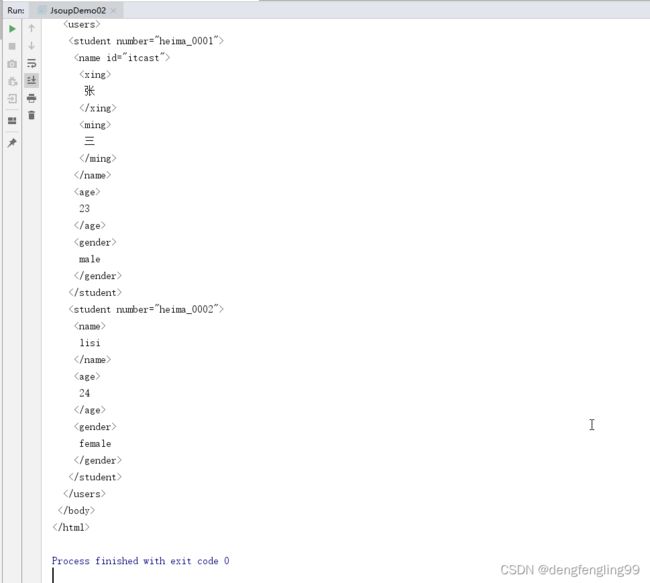
第二个:
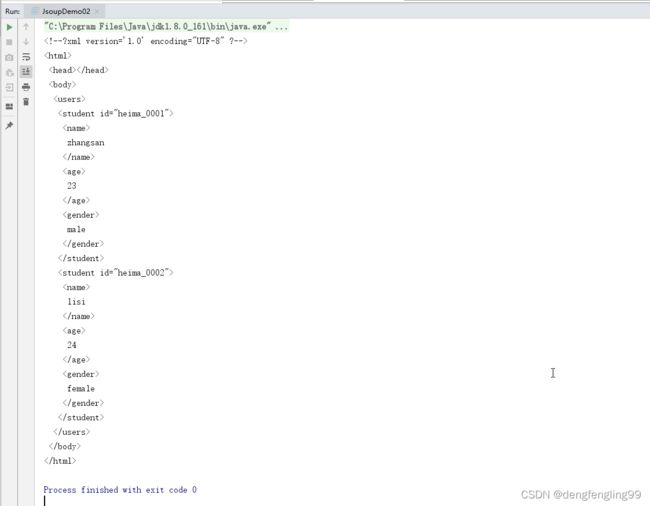
第三个:输出的是哔哩哔哩的网址:
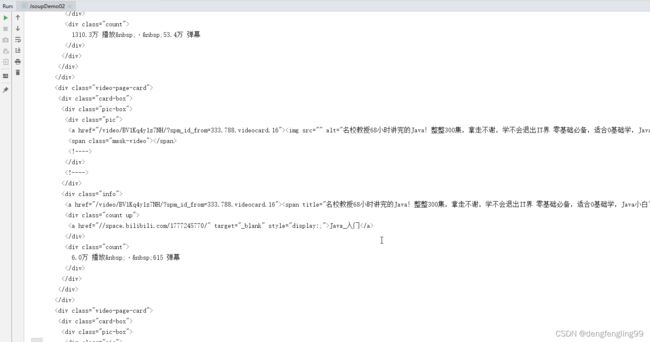
JsoupDemo03 类:
package xml.Jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/*
Document extends Element对象的功能
Document文档对象获取元素对象Elements对象
功能:
*/
public class JsoupDemo03 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path= JsoupDemo03.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//根据标签名称获取元素对象集合,获取student对象
Elements elements=document.getElementsByTag("student");
System.out.println(elements);
System.out.println("=================");
//根据属性名称获取元素对象集合,获取属性名为id的元素的对象
Elements elements1=document.getElementsByAttribute("id");
System.out.println(elements1);
System.out.println("=================");
//根据对应的属性名和属性值获取元素对象集合,获取number属性值heima_0001元素对象
Elements element2 = document.getElementsByAttributeValue("number", "heima_0001");
System.out.println(element2);
System.out.println("=================");
Element itcast = document.getElementById("itcast");
System.out.println(itcast);
}
}
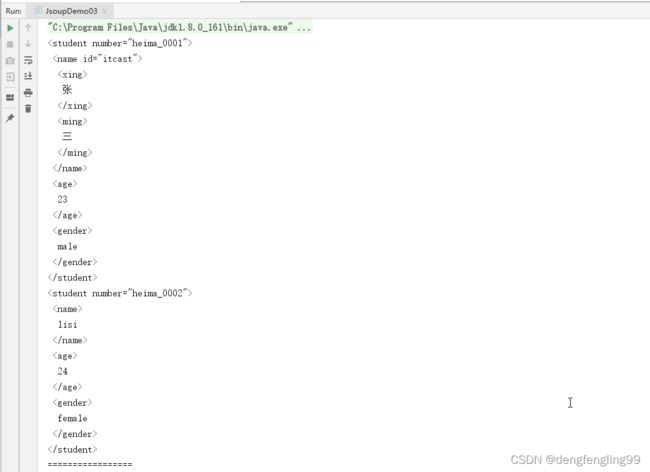


JsoupDemo04类:
package xml.Jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
public class JsoupDemo04 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path= JsoupDemo04.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//通过document对象获取所有的name标签
Elements name = document.getElementsByTag("name");
System.out.println(name);
System.out.println("===================");
//通过Element对象获取子标签对象
Element element_student=document.getElementsByTag("student").get(0);
Elements ele_name = element_student.getElementsByTag("name");
System.out.println(ele_name.size());
//获取student对象属性值
String number = element_student.attr("number");
System.out.println(number);
//获取文本内容
String text1 = ele_name.text();//text()获取字子标签的纯文本内容
System.out.println(text1);
String html = ele_name.html();//html()获取标签体的所有内容(包含子标签的和文本内容)
System.out.println(html);
}
}
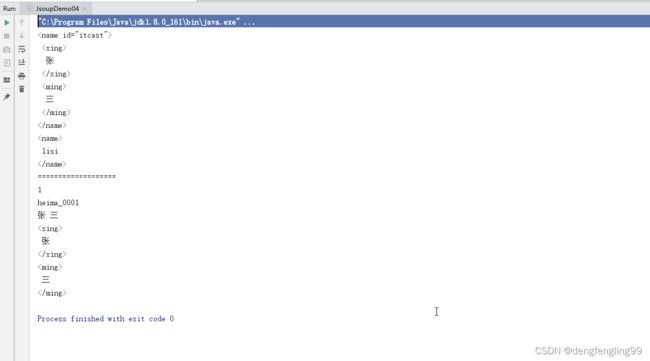
JsoupDemo05类:
package xml.Jsoup;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
/*
选择器select查询
*/
public class JsoupDemo05 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path= JsoupDemo05.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//查询name标签
Elements elements = document.select("name");
System.out.println(elements);
//查询id值为itcast的元素
Elements elements1 = document.select("#itcast");
System.out.println(elements1);
System.out.println("=============");
//获取student标签并且number属性值为heima_001的age字标签
Elements elements2 = document.select("student[number='heima_0001']");
System.out.println(elements2);
System.out.println("==================");
//子标签带一个 >
Elements elements3 = document.select("student[number='heima_0001'] > age");
System.out.println(elements3);
}
}
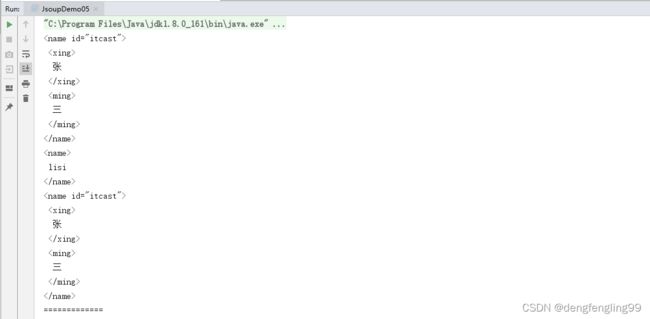
结果:

JsoupDemo06类:
package xml.Jsoup;
import cn.wanghaomiao.xpath.model.JXDocument;
import cn.wanghaomiao.xpath.model.JXNode;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.File;
import java.util.List;
/*
XPath查询
*/
public class JsoupDemo06 {
public static void main(String[] args) throws Exception{
//2.获取document对象,根据xml文档获取
//2.1获取studentxml的path路径
String path= JsoupDemo06.class.getClassLoader().getResource("student.xml").toURI().getPath();
//2.2解析xml文档,加载文档进内存,获取DOM树-->对应document对象
Document document=Jsoup.parse(new File(path),"UTF-8");
//根据document对象,创建JXDocument对象
JXDocument jxDocument=new JXDocument(document);
//结合XPath语法查询 查询所有的student标签
List jxNodes = jxDocument.selN("//student");
//遍历
for (JXNode jxNode:jxNodes){
System.out.println(jxNode);
}
System.out.println("===========");
//查询所有student标签下的name标签
List jxNodes2 = jxDocument.selN("//student/name");
//遍历
for (JXNode jxNode:jxNodes2){
System.out.println(jxNode);
}
System.out.println("=============");
//查询student标签下带id属性的name标签
List jxNode3 = jxDocument.selN("//student/name[@id]");
//遍历
for (JXNode jxNode:jxNode3){
System.out.println(jxNode);
}
System.out.println("==============");
//查询student标签下带有id属性的name标签,并且id属性值为itcast
List jxNodes4 = jxDocument.selN("//student/name[@id='itcast']");
//遍历
for (JXNode jxNode:jxNodes4){
System.out.println(jxNode);
}
}
}