A Comparative Analysis of Deep Learning Approaches for Network Intrusion Detection Systems (N-IDSs)
论文阅读记录
数据类型
在预定义时间窗口中,按照传输控制协议/互联网协议(TCP/IP)数据包将网络流量数据建模成时间序列数据。
数据:KDDCup-99/ NSL-KDD/ UNSW-NB15 NIDS数据集
使用方法
监督深度学习方法:循环神经网络(RNN)、身份循环神经网络(IRNN)、长短时记忆网络(LSTM)、带时钟频率的循环神经网络(CWRNN)和门控制循环单元(GRU)主要关注的是评估RNN比新引入的方法如LSTM和IRNN的性能,以缓解记忆长期依赖关系时的消失和爆炸梯度问题。通过改变0.01-05之间的学习率,对这种选定的深度模型的有效配置进行了1,000个epochs的实验。
introduction
过去几年,行业和组织经常研究的一个关键领域是入侵检测 (ID)。它是网络安全的重要途径。机器学习的许多概念和方法被转移到 ID,目的是提高区分系统异常行为和正常网络行为的性能。(安德森,1980) 是通过 1931 年发表的一篇论文“计算机安全威胁监视和监视”对 ID 工作的最初贡献者。从根本上说,IDS 根据网络类型及其行为分为两种类型,例如 (1) 基于网络的 IDS (N-IDS):根据网络流量中数据包之前的数据来识别恶意活动 (2) 主机基础 IDS:根据软件日志、系统日志、传感器等日志文件的内容,文件系统、特定主机或系统的磁盘资源。一个组织使用网络和基于主机的系统的交叉来有效地攻击实时环境中的恶意活动。
(Anderson, 1980) is an initial contributor towards the work in ID through a paper “Computer Security threat monitoring and surveillance” published in 1931. Fundamentally, the IDSs are categorized into two types based on the network type and its behaviors such as (1) network basis IDS (N-IDS): depend as far as the data prior to packets in network traffic to identify the malicious activities (2) host basis IDS: rely on the contents as far as the log files such as software logs, system logs, sensors, file systems, disk resources of particular host or a system. An organization uses the intercross as far as network and host-based system to effectively attack the malicious activities in real time environment. This has become an indispensable part of ICT systems and networks. However, the performances of detecting the unforeseen attacks are not acceptable with the existing traditional approaches in N-IDS.
常见网络流量数据分类方法
异常检测:基于启发式方法检测未知入侵。异常检测对于未知入侵不是一种可靠的犯法,主要由于其误报率高。
状态全协议分析:根据协议信息精确定位检测域,分析攻击特征,有针对性地使用详细具体检测手段。针对不同的异常和攻击,灵活制定检测方式。
1.检测TCP syn Flooding攻击
攻击描述:在短时间内,攻击者发送大量SYN报文建立TCP连接,在服务器端发送应答包后,客户端不发出确认,服务器端会维持每个连接直到超时,这样会使服务端的TCP资源迅速枯竭,导致正常连接不能进入。
解决方式:当客户端发出的建立TCP连接的SYN包时,便跟踪记录此连接的状态,直到成功完成或超时。同时,统计在规定时间内,接受到这种SYN包的个数超过了某个规定的临界值,则发生TCP Syn Flooding攻击o
2.检测FTP会话
一个FTP会话可以分为以下四个步骤:
(1)建立控制连接。FTP客户端建立一个TCP连接到服务器的FTP端21;
(2)客户身份验证。FTP用户发送用户名和口令,或用匿名登陆到服务器;
(3)执行客户命令。客户向服务器发出命令,如果要求数据传输,则客户使用一个临时端口和服务器端口20建立一个数据连接进行数据的传输;
(4)断开连接。FTP会话完成后,断开TCP连接。
客户端通过身份验证后才合法执行命令,以LIST命令为例,LIST命令列表显示文件或目录,将引发一个数据连接的建立和使用,客户端使用PORT命令发送客户IP地址和端口号给服务器用于建立临时数据连接。
误用检测:特征检测,依赖于预定义的特征和过滤器来有效的确定熟悉的入侵。对于匿名入侵,性能不佳,由于签名检测依赖于人工任务不断更新签名语料库,以保持新攻击的签名。
(市场上存在的大多数商业工具都使用了误用检测和异常检测的混合体;市场流行的商业工具基于阈值计算方法或统计措施,利用流量大小、到达间隔时间、数据包长度等参数作为特征来学些特定时间窗口内网络的流量模式。不足:限制检测复杂攻击的性能,因为基于数据包头和数据包长度统计计算的度量)
方法改进
使用自学习系统,从良性特征中检测和分类恶意行为。
自学习系统:有监督或无监督的机器学习方法。用大量的恶意和良性连接记录来学习网络流量行为,目的是区分良性和攻击性行为。自学习系统具有检测未知入侵的能力,有助于以时间受限的方式针对所有类型的突发事件采取必要的对策。
Machine learning (ML) methods are current prominent methods used largely for IDS. These ML based solutions to real-time IDS is not an effective approach mainly due to the model’s outputs in a high false positive rate and ineffective in identifying the novel intrusions (Lee, Fan, Miller, Stolfo, & Zadok, 2002). The main reason is that the machine learning models learns the attack patterns of simple features of TCP/IP packets locally. However, the recent development of machine learning models resulted in a robust and advanced learning technique, named as ‘deep learning’. Deep learning models have achieved significant results in various fields includes natural language processing (NLP), image processing (IP) and speech recognition (SR) (LeCun, Bengio, & Hinton, 2015) comes under the purview of artificial intelligence (AI) tasks. Deep learning approaches have two essential characteristics (1) Ability to learn the complex hierarchical feature representation of TCP/IP packets globally (2) Ability to memorize the past information in large sequences of TCP/IP packets. The performance of deep learning methods is transferred to ID (Staudemeyer, & Omlin, 2014; (Staudemeyer, 2015; Kim, & Kim, 2017). Moreover, recently (Hodo, Bellekens, Hamilton, Tachtatzis, & Atkinson, 2017) outlined the taxonomies and the precursory works of trivial deep learning algorithms to ID. Following, this paper compares the effectiveness of IRNN and other approaches introduced to solving the long-range temporal dependencies for N-IDS. Both LSTM and IRNN network is complex and remained as a black-box. This makes reverse engineering the system with exact same specifications by a malicious adversary quite impossible unless he/she is in possession of the exact same training sample used to build the system.
机器学习在网络入侵检测中,只能在本地学习TCP/IP数据包的简单特征的攻击模式,误报率高,无法有效识别新的入侵。
深度学习方法有两个基本特征 (1) 能够全局学习 TCP/IP 数据包的复杂分层特征表示 (2) 能够记住大序列 TCP/IP 数据包中的过去信息。深度学习方法的性能转移到 ID(Staudemeyer 和 Omlin,2014 年; 斯塔德迈尔,2015 年;金和金,2017)。此外,最近(Hodo、Bellekens、Hamilton、Tachtatzis 和 Atkinson,2017) 概述了 ID 的琐碎深度学习算法的分类法和先驱工作。
文章主题
比较了 IRNN 和其他引入解决 N-IDS 的长期时间依赖性的方法的有效性。LSTM 和 IRNN 网络都很复杂,仍然是一个黑盒。这使得恶意对手完全不可能以完全相同的规格对系统进行逆向工程,除非他/她拥有用于构建系统的完全相同的训练样本。(这也可以作为一个使用深度学习做网络入侵检测的优势)
深度学习方法
RNN
主要用于序列数据建模,学习可变长度输入序列中隐藏的序列关系。ReLU激活函数在RNN中的应用并不成功,因为RNN会产生大量的输出。随着研究的发展发现,RNN在学习大规模序列数据的长距离时间依赖性时,会出现输出消失和梯度爆炸的问题。为了克服这个问题,对RNN的研究在3个重要方向上取得了进展:
一个方向是改进算法中的优化方法;无Hessian优化方法。
第二个方向是在网络结构的递归隐藏层中引入复杂的组件;(Hochreiter, & Schmidhuber, 1997)引入了长短时记忆(LSTM),LSTM网络的一个变种,减少了参数设置;门控递归单元(GRU),以及带时钟频率的循环神经网络(CWRN)。
第三,适当的权重初始化;与LSTM相比,使用ReLU的RNN涉及身份矩阵到循环权重矩阵的适当初始化,能够在性能上表现得更接近,命名为身份-递归神经网络(IRNN)。IRNN的基本思想是,在输入不足的情况下,RNN会无限期地保持相同的状态,其中RNN是由ReLU组成并以身份矩阵初始化。
RNN is mainly used for sequential data modeling in which the hidden sequential relationships in variable length input sequences is learnt by them.
RNN mechanism has significantly performed well in the field of NLP and SR (LeCun, Bengio, & Hinton, 2015). In initial time the applicability of ReLU activation function in RNN was not successful due to the fact that RNN results in large outputs. As the research evolved, authors showed that RNN outputs vanishing and exploding gradient problem in learning long range temporal dependencies of large scale sequence data modeling. To overcome this issue, research on RNN progressed on the 3 significant directions. One was towards on improving optimization methods in algorithms; Hessian-free optimization methods belong to this category (Martens, 2010). Second one was towards introducing complex components in recurrent hidden layer of network structure; (Hochreiter, & Schmidhuber, 1997) introduced long short-term memory (LSTM), a variant of LSTM network reduced parameters set; gated recurrent unit (GRU) (Cho, Van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk, & Bengio, 2014), and clock-work RNN (CWRNN) (Koutnik, Greff, Gomez, & Schmidhuber, 2014). Third one was towards the appropriate weight initializations; recently, (Le, Jaitly, & Hinton, 2015) authors have showed RNN with ReLU involving an appropriate initialization of identity matrix to a recurrent weight matrix is able to perform closer in the performance in compared to LSTM. This was substantiated with evaluating the 4 experiments on two toy problems, language modeling and SR. They named the newly formed architecture of RNN as identity-recurrent neural network (IRNN). The basic idea behind IRNN is that, while in the case of deficiency in inputs, the RNN stays in same state indefinitely in which the RNN is composed of ReLU and initialized with identity matrix.
RNN除了过去状态信息影响当前状态外,它类似一个前馈网络(FFN)
LSTM包含一个记忆块和自适应乘法门控制单元,以增强时间步长值的存储能力
As further the research on RNN in handling vanishing and exploding gradient issue, (Hochreiter, & Schmidhuber, 1997) introduced long short-term memory (LSTM) that followed entirely a new kind of architecture to enhance the storing capacity of values for long time-steps.
带时钟频率的RNN(CWRNN)是标准RNN架构的变体。其中隐藏层被细分为平行的m个模块。每个模块以不同的时钟速率运行,模块中的权重矩阵根据时间步长整除相应模块的频率的条件在时间步数t中得到更新,否则就保留之前的状态。此外,CWRNN网络的隐藏层有许多时间步长,有利于学习序列数据中时间模式的短期和长期依赖。这些模块从隐藏层到上下文层以时钟频率递增的方式连接。
身份循环神经网络(IRNN)RNN的变体,在捕捉长距离的时间依赖性方面表现良好。这些微小的变化与初始化技巧有关;使用身份矩阵或其缩放版本来初始化适当的RNNs权重矩阵,并使用ReLU作为非线性激活函数。此外,该方法在4个重要任务中的表现更接近于LSTM;两个玩具问题、语言建模和语音识别。在其中一个玩具问题中,IRNN的表现优于LSTM网络。
(Le, Jaitly, & Hinton, 2015) proposed a new RNN, named as identity-recurrent neural network (IRNN) with minor changes to RNN that has significantly performed well in capturing long-range temporal dependencies.
CNN
通过矩形区域上应用过滤器来逐层提取复杂的特征。复杂特征分层表示,其中存在于较高级别的特征由一组较低级别的特征组成。分层特征表示允许CNN学习各种抽象级别的数据。CNN组成——单个或一组卷积和池化操作以及非线性激活函数。
数据特征
KDDCup-99和NSL-KDD数据集描述
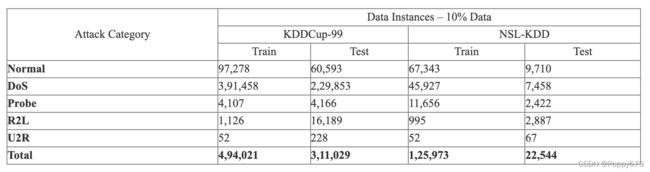
NSL-KDD是KDDCup-99的一个过滤版本。应用的过滤器是:(1),重复的连接记录被删除,因此它保护分类器不偏向于频繁的连接记录。(2)在索引号136,489和136,497中存在的测试连接记录被完全删除。(3) NSL-KDD的连接记录是随机选择的,保持难度与KDDCup-99成反比。(4)训练和测试数据集中现有的连接向量数量是对每类难度的合理补充。(5) NSL-KDD的记录在训练和测试数据中都是平衡的。NSL-KDD的性能对于误用或异常检测是可以接受的。即使如此,NSL-KDD在代表真实世界的网络流量特征方面仍有不足。其他问题有:(1)NSL-KDD攻击数据包的生存时间值为126或253,而不是127或254。训练和测试数据之间的攻击向量的概率分布是不唯一的。因此,机器学习分类器对更频繁的连接记录有偏见或倾斜。NSL-KDD并不能完全代表正常和攻击的现时连接向量。
NSL-KDD is a filtered version of KDDCup-99 (Tavallaee, Bagheri, Lu, & Ghorbani, 2009). The applied filters are (1), duplicate connection records were removed and as a result it protects the classifier from being biased towards the frequent connection records. (2) Test Connection records existing in index number 136,489 and 136,497 were removed entirely. (3) The connection records for NSL-KDD were chosen randomly with maintaining the degree of difficulty inversely proportional to KDDCup-99. (4) The existing number of connection vectors in train and test data set is reasonable complement to each class difficulty levels. (5) The records of NSL-KDD are balanced in both the train and test data. NSL-KDD performance is acceptable for misuse or anomaly detection. Even, NSL-KDD lack behind in representing the characteristics of real world network traffic. The other issues are (1) Instead of time to live value as 126 or 253 the NSL-KDD attack packets have 127 or 254 (McHugh, J. 2000). The probability distribution of attack vectors between train and test data are not unique (Mahoney, M. V., & Chan, P. K. 2003, September). As a result, the machine learning classifiers are biased or skewed towards the more frequent connection records. The NSL-KDD is not a complete representative of present-time connection vectors of normal and attacks.
UNSW-NB15数据集描述
To overcome the reported issues of KDDCup-99 and NSL-KDD, the Australian Centre for Cyber Security group introduced UNSW-NB15 (Moustafa, & Slay, 2016).

该数据集主要包括近期网络流量的数据模式。该数据集包括与入侵、应用、协议或低层网络实体有关的正常和恶意连接特征,包括电子商务、军事、学术、社交媒体和银行等各种情况。该数据集以两种形式公开(1)完整的数据集(2)完整数据集的小子集。数据集的一个小子集有175,341条连接记录用于训练,82,332条连接记录用于测试。
实验
网络结构
RNN、IRNN、CWRNN、LSTM和GRU是参数化函数,攻击检测率取决于最佳网络参数。网络由三层结构组成:输入层、隐藏层和输出层。
输入层:41个神经元(41个属性)
隐藏层:包含4-64个记忆块,每一个记忆块包含一个记忆单元。输入层的神经元与隐藏层的记忆块之间是全连接。
输出层:5个神经元(将攻击分类为相应的类别)//2个神经元(将网络访问分为正常访问和攻击行为)
网络性能通过混淆矩阵表示。混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第一行第二列的2表示有2个实际归属为第一类的实例被错误预测为第二类。
参数设计
学习率控制在0.01-0.05;
隐藏层数1-4层
epoch次数为300次,batch大小为32
ADAM优化器和分类交叉熵作为损失函数
实验设计
针对RNN的各种变体,按照隐藏层1-4层的方式来训练和验证性能。
实验过程中设计减少数据特征的方法,验证在不同数量特征情况下,模型的有效性。(主要是8个特征和11个特征)
结论
通过IRNN和RNN变体结构的各种实验,详细研究了网络结构及其参数背后的原理。用完整的数据集和最小的特征集对实验进行了评估,以了解每个特征的重要性。IRNN和RNN变体在 "DoS "和 "Probe "攻击中表现出有效的性能,因为它们形成了独特的网络事件的时间序列。与KDDCup-99挑战赛的胜利作品相比,IRNN对低频攻击的分类性能良好。这可能会通过促进训练或在现有的架构上再堆叠几层,或在现有的数据上增加新的特征来改善。**在大多数情况下,低频攻击类别产生一个单一的连接记录。当这些低频攻击的信息隐藏在其他连接记录中时,这些低频攻击的提取显得很困难。**总的来说,RNN及其变体在检测率方面的表现比KDDCup-99挑战赛的胜利作品和其他先前公布的结果都要好。
验证了RNN及其变体在网络入侵中的性能。做了多分类和二分类实验,在UNSW-NB15上实验结果是IRNN4最优0.718的精度。在KDDCup-99上实验结果是IRNN4最优0.938的精度。在NSL-KDD上实验结果是LSTM4最优0.896的精度