python自动化测试学习笔记合集二
python自动化测试学习笔记-4内置函数,处理json
函数、全局变量
写代码时注意的几点事项:
1、一般写代码的时候尽量少用或不用全局变量,首先全局变量不安全,大家协作的情况下,代码公用容易被篡改,其次全局变量会一直占用系统内容。
2、函数里如果有多个return值,会把几个return值放到一个元组里
def hello(a,b,c,d):
return a,b,c,d
res=hello('1111','2222','3333','4444')
print(res)
3、一个函数尽量只写一个功能
4、用简练的代码写高级的程序
例如:循环一个list的每一个值,通常可以用for循环
num = [1,2,3,4,5,6,7,8,9]
newnum=[]
for i in num:
newnum.append(i)
print(newnum)
python提供一种更简洁的方式来实现,列表推导式:
num = [1, 2, 3, 4, 5, 6, 7, 8, 9] newnum=[str(x) for x in num ] print(newnum)
又例如,交换A,B的值,通常做法是添加第三方变量:
a=1 b=2 #a=2,b=1 c=0 c=a a=b b=c print(a,b)
python提供了一种更简便的方法,直接交换A,B的值
#python中可以直接交换 a=1 b=2 a,b=b,a print(a,b)
5、函数即变量
函数名也是一个变量,不加(),只是函数名。
def say(name):
print(name)
na=say
na('sss')
上述代码看到,我们把na=say ,因为say是一个函数,所以传给na后,na也变为一个函数,直接用na调用,也执行了定义的函数。再如:
def add():
print('tianjia')
def view():
print('chakan')
def delete():
print('shanchu')
menu={
'1':add,
'2':view,
'3':delete
}
case=input('请输入选择:1、2、3').strip()
if case in menu:
menu[case]()
else:
print('输入错误')
上述代码我们定义了三个函数,分别代表添加,查看,删除操作,同时定义一个字典来存放不同选择代表的调用不同函数;
当执行input时,判断输入的key是不是存在于字典中,menu[case](),如果存在,menu[case]的value值对应的函数名,加上()则表示执行函数;
当然这种函数即变量调用的时候适用于传参为空或者传参相同的场合。
内置函数
之前已经用到了一些python的内置函数,今天来学习一些常用的内置函数。
len() 方法返回对象(字符、列表、元组等)长度或项目个数。
len(s) --s对象
str='123456789' list=['1adssss',2,'3','4'] print(len(str))#长度; print(len(list))
执行结果:9、4
input()
python3 里 input() 默认接收到的是 str 类型。
st=input('shuru:')#输入
print(type(st))
执行结果:输入4,查看到input的类型是
如果想要int类型,可以进行强制转化int():
st=int(input('shuru:'))#输入
print(type(st))
查看执行结果:
shuru:3
print() 方法用于打印输出,最常见的一个函数。
print('打印')#输出
执行结果:打印
type()查看对象类型
list=['1adssss',2,'3','4']
print(type('sss'))#查看类型
print(type(2))
print(type(list))
查看执行结果:
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否不为 0、''、False 或者 iterable 为空,如果是返回 True,否则返回 False。简单的说就是判断参数是否都为真;
any() 函数用于判断给定的可迭代参数 iterable 是否全部为空对象,如果都为空、0、false,则返回 False,如果不都为空、0、false,则返回 True。简单说就是参数有任意一个为真,则返回真。如下:
print(all([0,1,2,3,4,5]))#判断其中的值都为真,则返回真 print(any([0,1,2,3,4,5]))#判断其中有一个值为真,则返回值真
查看执行结果:False、True
bin() 返回一个整数 int 或者长整数 long int 的二进制表示。
bin(10)#十进制转2进制
ejz=bin(100)
print(ejz)
print(ejz.replace('0b',''))
查看执行结果:0b1100100、1100100
代码中,如果直接执行bin(),会有0b开头代表二进制数,想要得到一个整数类型,我们把0b替换掉;
chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
chr(i) -- 可以是10进制也可以是16进制的形式的数字。
print(chr(88))#打印数字对应的ascii print(chr(0x61))
执行查看结果:
X
a
ord() 函数是查询一个长度为1的字符串对应的ASCII值
print(ord('#'))#打印字符串的对一个的ASCII
print(ord('e'))#打印字符串的对一个的ASCII
查看执行结果:35、101
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。
a='aaa'
b={}
c=[]
d=set()
print(dir(a))#查看字符串的方法
print(dir(b))#查看字典的方法
print(dir(c))#查看list的方法
print(dir(d))#查看元组的方法
print(dir())#查看当前模块的属性列表
查看执行结果:可以看到打印出了对应对象类型的方法,如果有写对象不清楚其方法,可以用此方法查看
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
['__and__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__iand__', '__init__', '__ior__', '__isub__', '__iter__', '__ixor__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__or__', '__rand__', '__reduce__', '__reduce_ex__', '__repr__', '__ror__', '__rsub__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__xor__', 'add', 'clear', 'copy', 'difference', 'difference_update', 'discard', 'intersection', 'intersection_update', 'isdisjoint', 'issubset', 'issuperset', 'pop', 'remove', 'symmetric_difference', 'symmetric_difference_update', 'union', 'update']
['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'c', 'd']
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
print(eval('[]'))#执行简单的python代码
a=3
b=a
print(eval('b'))
print(eval('1+2'))
查看执行结果:[]、3、3
excel()函数可以执行一个稍微复杂的python或执行一个python文件
code='''def a(): print('aaaa')'''
print(exec(code))
a()#调用
上述代码中exec执行了code,解析出其中的代码段定义了一个函数a(),所以在后面的调用a()的时候没有报错;直接打印了aaaa
又如,我们有一个python文件,可以用读的形式执行代码:
with open('clean_log.py','r',encoding='utf-8') as f:
exec(f.read())
上述代码的意思就是执行了clean_log.py文件中的代码。
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
比如我们同时循环两个列表的元素,可以用zip
ids=[1,2,3,4,5,6,7,-1,-2]
names=['aaa','bbb','ccc','ddd','eee','fff']
for id,name in zip(ids,names):
print(id,name)
查看执行结果:
1 aaa
2 bbb
3 ccc
4 ddd
5 eee
6 fff
在比如我们直接打包两个列表:
ids=[1,2,3,4,5,6,7,-1,-2] names=['aaa','bbb','ccc','ddd','eee','fff'] print(list(zip(ids,names)))
查看执行结果:
[(1, 'aaa'), (2, 'bbb'), (3, 'ccc'), (4, 'ddd'), (5, 'eee'), (6, 'fff')]
sorted() 函数对所有可迭代的对象进行排序操作。 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
ids=[1,2,3,4,5,6,7,-1,-2] print(sorted(ids,reverse=True))#默认是升序排列,可以用reverse进行降序
查看执行结果:
[7, 6, 5, 4, 3, 2, 1, -1, -2]
对一个字符串进行排序:
print(sorted('2125343230'))
print(sorted('asdgowequwxasd'))
查看执行结果:返回的是两个默认升序的列表
['0', '1', '2', '2', '2', '3', '3', '3', '4', '5']
['a', 'a', 'd', 'd', 'e', 'g', 'o', 'q', 's', 's', 'u', 'w', 'w', 'x']
map() 会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
def func(a):
if a%2==0:
return True
else:
return False
num2=[1,2,3,4,5,6,7,8,9,10]
nums=[x for x in range(11)]
res=map(func,nums)
res1=map(func,num2)
print(list(res))
print(list(res1))#map 的结果是一串字符串,需要强制类型转换成list查看
实际就是用list中的每一个值调用func函数,返回的是一个字符串,需要强制转化一下成list,在这里map等同于下面的代码:
all=[]
for num in nums:
res=func(num)
all.append(res)
print(all)
执行代码可以看到,返回值是一样的:
[True, False, True, False, True, False, True, False, True, False, True]
[False, True, False, True, False, True, False, True, False, True]
[True, False, True, False, True, False, True, False, True, False, True]
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
与map类似,只不过filter是用来过滤的。
def func(a):
if a%2==0:
return True
else:
return False
nums=[0,1,2,3,4,5,6,7,8,9,10]
res=filter(func,nums)#如果返回的是值0,0会当作False 过滤掉
print(list(res))
查看执行结果:
[0, 2, 4, 6, 8, 10]
json函数
使用json函数需要导入json模块
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,易于人阅读和编写。
json.dumps 用于将 Python 对象编码成 JSON 字符串。
例如,我们向文件中写入一个字典表时,写入的是一个字符串形式的,不方便查看,这时就可用用json进行格式转化。
import json
d={'吉普车':{
'color':'fffff',
'count':20,
'price':100000
},
'小轿车': {
'color': '00000',
'count': 50,
'price': 60000
}
}
f=open('aaa','a+',encoding='utf-8')
f.seek(0)
f.write(str(d))
执行上述代码,写入文件的是一个字符串。
import json
d={'吉普车':{
'color':'fffff',
'count':20,
'price':100000
},
'小轿车': {
'color': '00000',
'count': 50,
'price': 60000
}
}
f=open('aaa','a+',encoding='utf-8')
f.seek(0)
res=json.dumps(d,indent=4,ensure_ascii=False)#json 把字典转化为json,indent表示缩进,显示中文
f.write(res)
执行上述代码,查看文件:
{
"吉普车": {
"count": 20,
"color": "fffff",
"price": 100000
},
"小轿车": {
"count": 50,
"color": "00000",
"price": 60000
}
}
还有一个dump方法,与dumps的方法区别是:
#dump 操作的是文件 ,dumps操作的是字符串 #dump 第一个参数是字典数据,第二个参数是文件,自动写入文件
如上边的代码用dump改造一下:
import json
d={'吉普车':{
'color':'fffff',
'count':20,
'price':100000
},
'小轿车': {
'color': '00000',
'count': 50,
'price': 60000
}
}
f=open('aaa','a+',encoding='utf-8')
f.seek(0)
json.dump(d,f,ensure_ascii=False,indent=4)#d表示字典数据,f是文件
f.close()
查看执行结果,同样文件中写入了json串,省略了一步write操作。
json.loads 用于解码 JSON 数据。该函数返回 Python 字段的数据类型。我们用上述写入文件的json进行试验:
import json
f=open('aaa','r',encoding='utf-8')
res=f.read()
dict_res=json.loads(res)#把json转化python的数据类型字典
print(dict_res)
执行查看结果:返回的是python的字典类型
{'吉普车': {'count': 20, 'color': 'fffff', 'price': 100000}, '小轿车': {'count': 50, 'color': '00000', 'price': 60000}}
同样的还有一个load方法,与dump方法一样,参数中传入文件,直接进行转换,省略了一步读的动作:
import json
f=open('aaa','r',encoding='utf-8')
print(json.load(f))
查看执行结果,返回了字典类型:
{'小轿车': {'count': 50, 'price': 60000, 'color': '00000'}, '吉普车': {'count': 20, 'price': 100000, 'color': 'fffff'}}
python自动化测试学习笔记-4常用模块
常用模块
1、os
2、sys
3、random
4、string
5、time
6、hashlib
一、os模块
os模块主要用来操作文件、目录,与操作系统无关。要使用os模块首先要导入OS模块,用命令import os 即可。
目录和文件操作
1、os.getcwd()--用来获取当前工作目录
3、os.chdir(),改变当前脚本工作目录,相当于shell下的CD
print(os.getcwd())#取当前工作目录 *************
os.chdir("E:\\besttest\\python\\")#更改当前目录
print(os.getcwd())
查看执行结果:
E:\besttest\python\besttest_code\练习\day5笔记
E:\besttest\python
4、os.curdir()属性值为当前文件所在目录,当前目录相对路径
5、os.pardir()当前目录的父目录字符串名:(‘..’)父目录相对路径
print(os.curdir)#当前目录,相对路径’ print(os.pardir)#父目录,相对路径
6、os.mkdir()创建文件夹,生成单级目录
print(os.mkdir("test"))#创建文件夹
print(os.mkdir("c:\\test"))#创建文件夹指定目录创建文件夹
7、os.remdir()删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
print(os.rmdir("test"))#删除文件夹
8、os.remove()删除指定文件,不能删除文件夹
print(os.remove("test.txt"))#只能删除文件,不能删除文件夹
print(os.remove("C:\\test\\dasd.vsdx"))#指定文件路径的文件
9、os.listdir():列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
print(os.listdir('.'))#列出目录下的所有文件“.”代表当前目录
print(os.listdir("c:\\"))#可以列出指定目录的所有文件
10、os.rename(): 格式:os.rename(“oldname”,”newname”) 重命名文件/目录
os.rename("test","test1")#重命名文件
os.rename("c:\\test\\sd","c:\\test\\rename")#重命名文件夹
11、os.stat() 获取文件、文件夹(目录)的信息
print(os.stat("test1"))#获取文件夹信息
print(os.stat("全局变量.py"))#获取文件信息
执行:os.stat_result(st_mode=16895, st_ino=10414574138339362, st_dev=100732189, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1516072926, st_mtime=1516072926, st_ctime=1516072926)
os.stat_result(st_mode=33206, st_ino=3659174697285543, st_dev=100732189, st_nlink=1, st_uid=0, st_gid=0, st_size=778, st_atime=1516012249, st_mtime=1516012249, st_ctime=1515997654)
12、_file_ file是这个文件夹的绝对路径
print(__file__)#file就是这个文件的绝对路径
系统属性和操作相关
1、os.name()字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
print(os.name)#当前系统名称
2、os.seq()输出操作系统特定的路径分隔符,win下为”\”,Linux下为”/”
print(os.sep)#当前系统路径的分隔符
3、os.linesep: 输出当前平台使用的行终止符,win下为”\t\n”,Linux下为”\n”
print(os.linesep)#当前系统的换行符win'\n' linux '\r\n'
4、os.pathsep: 输出用于分割文件路径的字符串
print(os.pathsep)#当前系统的环境变量中每个路径的分隔符,win 是; linux shi :
5、os.environ: 系统环境变量
print(os.environ)#当前系统的环境变量
6、os.system(): 格式:os.system(“command”) ,运行命令,直接显示
os.system('calc')#用来执行操作系统的命令直接打开计算器
os.system('cmd')#用来执行操作系统的命令
7、os.popen(),执行操作系统命令,并返回结果
res=os.popen('ipconfig')#执行操作系统
print(res.read())#能够执行操作系统命令,并返回结果,用read查看
执行结果:
Windows IP 配置
无线局域网适配器 无线网络连接 2:
媒体状态 . . . . . . . . . . . . : 媒体已断开
连接特定的 DNS 后缀 . . . . . . . :
无线局域网适配器 无线网络连接:
媒体状态 . . . . . . . . . . . . : 媒体已断开
连接特定的 DNS 后缀 . . . . . . . : AirDream
以太网适配器 本地连接:
连接特定的 DNS 后缀 . . . . . . . : AirDream
本地链接 IPv6 地址. . . . . . . . : fe80::582c:b8ae:16b9:dd70%13
IPv4 地址 . . . . . . . . . . . . : 192.168.56.55
子网掩码 . . . . . . . . . . . . : 255.255.255.0
默认网关. . . . . . . . . . . . . : 192.168.56.1
。。。。
文件路径相关
1、os.path.abspath(): 格式:os.path.abspath(path) ,返回path规范化的绝对路径
print(os.path.abspath(__file__))#获取绝对路径
print(os.path.abspath("."))
print(os.path.abspath(".."))
查看结果:
E:\besttest\python\besttest_code\练习\day5笔记\常用模块.py
E:\besttest\python\besttest_code\练习\day5笔记
E:\besttest\python\besttest_code\练习
2、os.path.split(): 格式:os.path.split(path) 、将path分割成目录和文件名二元组返回
print(os.path.split("c:\\usr\\hehe\\hehe.txt"))#分割路径和文件名
查看执行结果:
('c:\\usr\\hehe', 'hehe.txt')
3、os.path.dirname(): 格式:os.path.dirname(path) ,返回path的目录。其实就是os.path.split(path)的第一个元素
print(os.path.dirname("\\usr\\local"))#获取父目录#***********
查看执行结果:\usr
4、os.path.basename(): 格式:os.path.basename(path) ,返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
print(os.path.basename("E:\\besttest\\python"))#获取最后一个
查看执行结果:python
5、os.path.exists(): 格式:os.path.exists(path) ,如果path存在,返回True;如果path不存在,返回False
print(os.path.exists("E:\\besttest\\python"))#目录文件是否存在
print(os.path.exists("c:\\besttest\\python"))#目录文件是否存在
查看执行结果:True False
6、os.path.isabs(): 格式:os.path.isabs(path) ,如果path是绝对路径,返回True
print(os.path.exists("..\\day4笔记"))#路径是否存在
print(os.path.isabs("..\\day4笔记"))#绝对路径是否存在
运行结果:
True
False
7、os.path.isfile(): 格式:os.path.isfile(path) ,如果path是一个存在的文件,返回True。否则返回False
print(os.path.isfile("E:\\besttest\\python\\userinfo.txt"))#判断是否是一个文件
print(os.path.isfile("E:\\besttest\\python"))
查看执行结果:
True
False
8、os.path.isdir(): 格式:os.path.isdir(path) ,如果path是一个存在的目录,则返回True。否则返回False
print(os.path.isdir("E:\\besttest\\python"))
9、os.path.getatime(): 格式:os.path.getatime(path) ,返回path所指向的文件或者目录的最后存取时间
print(os.path.getatime("E:\\besttest\\python"))
执行结果:1514864986.2809415
10、os.path.getmtime(): 格式:os.path.getmtime(path) ,返回path所指向的文件或者目录的最后修改时间
print(os.path.getmtime("e:\\"))
1516072216.474383
11、os.path.join():
格式:os.path.join(*parentpath,filename)
将目录和文件名组合成路径(可以将目录拆分成多个,例如D:\a\abc目录,可以拆分成D:\a和abc)
print(os.path.join("e:\\","root","hehe","a.sql"))#拼接成一个路径*
查看执行结果:e:\root\hehe\a.sql
二、sys模块
sys模块包括了一组非常实用的服务,内含很多函数方法和变量,用来处理Python运行时配置以及资源,从而可以与前当程序之外的系统环境交互.
要应用sys模块,同样需要先导入模块:import sys
dir(sys)可以查看sys所有可用的方法:
1、dir(sys)
import sys print(dir(sys))
查看执行结果:
['__displayhook__', '__doc__', '__excepthook__', '__interactivehook__', '__loader__', '__name__', '__package__', '__spec__', '__stderr__', '__stdin__', '__stdout__', '_clear_type_cache', '_current_frames', '_debugmallocstats', '_getframe', '_home', '_mercurial', '_xoptions', 'api_version', 'argv', 'base_exec_prefix', 'base_prefix', 'builtin_module_names', 'byteorder', 'call_tracing', 'callstats', 'copyright', 'displayhook', 'dllhandle', 'dont_write_bytecode', 'exc_info', 'excepthook', 'exec_prefix', 'executable', 'exit', 'flags', 'float_info', 'float_repr_style', 'get_coroutine_wrapper', 'getallocatedblocks', 'getcheckinterval', 'getdefaultencoding', 'getfilesystemencoding', 'getprofile', 'getrecursionlimit', 'getrefcount', 'getsizeof', 'getswitchinterval', 'gettrace', 'getwindowsversion', 'hash_info', 'hexversion', 'implementation', 'int_info', 'intern', 'is_finalizing', 'maxsize', 'maxunicode', 'meta_path', 'modules', 'path', 'path_hooks', 'path_importer_cache', 'platform', 'prefix', 'set_coroutine_wrapper', 'setcheckinterval', 'setprofile', 'setrecursionlimit', 'setswitchinterval', 'settrace', 'stderr', 'stdin', 'stdout', 'thread_info', 'version', 'version_info', 'warnoptions', 'winver']
2、sys.path python环境变量的值
print(sys.path)#环境变量
查看执行结果:
['E:\\besttest\\python\\besttest_code\\练习\\day5笔记', 'E:\\besttest\\python\\besttest_code', 'C:\\Miniconda3\\python35.zip', 'C:\\Miniconda3\\DLLs', 'C:\\Miniconda3\\lib', 'C:\\Miniconda3', 'C:\\Miniconda3\\lib\\site-packages', 'C:\\Miniconda3\\lib\\site-packages\\setuptools-23.0.0-py3.5.egg']
3、sys.platform 返回操作系统平台名称
print(sys.platform)
执行结果:win32
4、sys.version 查看python解释程序的版本信息
print(sys.version)#查看python 版本
查看执行结果:
3.5.2 |Continuum Analytics, Inc.| (default, Jul 5 2016, 11:41:13) [MSC v.1900 64 bit (AMD64)]
5、sys.exit 退出程序,正常退出时exit(0)
print('ssssss')
sys.exit()
print('继续')
查看执行结果:ssssss 可以看到,结果只打印了第一行,没有打印第三行。
6、sys.argv 命令行参数,第一个元素是程序本身路径
print(sys.argv)#获取运行python文件的时候参数
运行查看结果:
['E:/besttest/python/besttest_code/练习/day5笔记/常用模块.py']
可以看到,上述运行结果是一个list ,什么都不传的场合,list中默认的元素是当前程序的路径。
下面写一个小程序:
在命令行中,执行python文件,给出文件路径,就能清楚路径下的日志内容。
import os
import sys
def clean_log(path):#定义一个清理日志的函数,此处只是虚拟的,需要传入一个路径
print('日志已经清理')
args=sys.argv#获取命令行参数
if len(args)>1:#判断命令行参数list长度是否大于1
if os.path.isdir(args[1]):#大于1的场合,说明传了一个参数进来,然后判断参数是否为有效的路径
clean_log(args[1])#如果是一个有效的路径,则调用clean_log函数
else:
print('地址不正确')
else:#如果长度小于等于1,则说明命令行没有传入其他参数,给出提示
print('需要输入一个路径')
需要几个参数就在命令行输入几个参数就可以,argv传参不能直接运行python文件,需要在命令行运行,输入参数。
三、random模块
要使用random模块,同样需要导入:import random
1、random.random
random.random()用于生成一个0到1的随机浮点数: 0 <= n < 1.0
print(random.random())
查看执行结果:0.013748057102894395
2、random.randint
random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b
print(random.randint(1,199))
查看执行结果:18
3、random.uniform 查看执行结果: 154.15652457751816 6、random.choice 查看执行结果: 1 7、random.sample 查看执行结果: [21, 61, 81, 11] 8、random.shuffle 查看执行结果: [31, 41, 61, 51] 四、string模块 使用string模块也需要导入,import string ,主要用来处理一些字符串。 首先查看string都有哪些方法: ['Formatter', 'Template', '_ChainMap', '_TemplateMetaclass', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_re', '_string', 'ascii_letters', 'ascii_lowercase', 'ascii_uppercase', 'capwords', 'digits', 'hexdigits', 'octdigits', 'printable', 'punctuation', 'whitespace'] 查看执行结果: 0123456789 Sss 五、time模块 time模块提供各种操作时间的函数,使用time模块,首先需要导入:import time 在Python中,通常有这几种方式表示时间:时间戳、格式化的时间字符串、元组(struct_time 共九种元素) 1、时间戳:只从计算机Unix元年1970年1月1号 00:00:00开始到现在按秒计算的偏移量。 2、格式化的时间字符串:世界标准时间,中国为UTC+8 3、时间元祖:中间过程,可以把时间戳和格式化时间进行相互转换,struct_time元组共有9个元素,返回struct_time的函数主要有gmtime(),localtime(),strptime()。 time.time 查看当前时间的时间戳 查看执行结果:返回值类型,可以看出是float类型,如果需要int类型,可以进行类型强制转化,int() 1516103056.6053376 查看执行结果: 1516103746 time.localtime() 将一个时间戳转换为当前时区的struct_time,即时间数组格式的时间,不填参数,默认是当前时间。 查看执行结果: time.struct_time(tm_year=2018, tm_mon=1, tm_mday=16, tm_hour=19, tm_min=52, tm_sec=28, tm_wday=1, tm_yday=16, tm_isdst=0) tm_mon :月(1-12) tm_mday :日(1-31) tm_hour :时(0-23) tm_min :分(0-59) tm_sec :秒(0-59) tm_wday :星期几(0-6,0表示周日) tm_yday :一年中的第几天(1-366) tm_isdst :是否是夏令时(默认为-1) 也可以指定参数,我们用上面获取的时间戳 time.struct_time(tm_year=2018, tm_mon=1, tm_mday=16, tm_hour=19, tm_min=55, tm_sec=46, tm_wday=1, tm_yday=16, tm_isdst=0) time.gmtime() time.gmtime() 函数将一个时间戳转换为UTC时区(0时区)的struct_time,可选的参数sec表示从1970-1-1 00:00:00以来的秒数。 查看执行结果: time.struct_time(tm_year=2018, tm_mon=1, tm_mday=16, tm_hour=11, tm_min=58, tm_sec=28, tm_wday=1, tm_yday=16, tm_isdst=0) time.mktime() 将一个struct_time转化为时间戳 查看执行结果: 1516104153.0 time.sleep() 线程睡眠指定时间,单位为妙 会在启动程序5秒后,执行后边的代码。 time.strftime( format [, t] ) 返回字符串表示的当地时间。 查看执行结果: 20180116 20:16:29 查看执行结果:不传参数的时候,默认当前格式化时间,可以单独获取某一个格式化的参数 2018-01-16 20:17:30 time.strptime(string[,format]) 查看执行结果: time.struct_time(tm_year=2018, tm_mon=1, tm_mday=1, tm_hour=20, tm_min=20, tm_sec=0, tm_wday=0, tm_yday=1, tm_isdst=-1) ########################################### 我们可以根据上边的知识,写两个时间戳与格式化时间相互转化的函数,方便以后调用。 查看执行结果: 2018-01-14 10:18:19 六、hashlib模块 hashlib 是一个提供了一些流行的hash算法的 Python 标准库.其中所包括的算法有 md5, sha1, sha224, sha256, sha384, sha512. 要使用hashlib要先导入该模块:import hashlib 1.创建一个哈希对象,使用哈希算法命名的构造函数或通用构造函数hashlib.new(name[, data]) 2.使用哈希对象调用update()方法填充这个对象 3.调用digest() 或 hexdigest()方法来获取摘要(加密结果) 哈希对象常用的方法 h = hashlib.md5() 或 h = hashlib.new("md5") # md5可以替换为其他的哈希类型 h.update(arg) 将字节对象arg填充到哈希对象中,arg通常为要加密的字符串 h.digest() 返回加密结果,它是一个字节对象,长度为 h.digest_size,包含的字节范围 0 ~ 255 h.hexdigest() 返回加密结果,它是一个字符串对象,长度为 h.digest_size * 2,只包含16进制数字 查看执行结果: b7bc2a2f5bb6d521e64c8974c143e9a0 通常要把字符串转化成字节,可以用encode方法例如: 查看执行结果: e807f1fcf82d132f9bb018ca6738a19f ############################ 现在我们来写一个小程序,用来对字符串加密 查看执行结果:5429caaedc494ebfd6f3d988ab6a1d66 其他的一些加密算法应用于MD5类似 上一次学习了os模块,sys模块,json模块,random模块,string模块,time模块,hashlib模块,今天继续学习以下的常用模块: 1、datetime模块 2、pymysql模块(3.0以上版本) 3、Redis模块 4、flask模块 datetime模块 datetime中包含三个类date ,time,datetime datetime.date:表示日期的类。常用的属性有year, month, day; datetime.time:表示时间的类。常用的属性有hour, minute, second, microsecond; datetime.datetime:表示日期时间。 1、date对象由 例如: 差看执行结果: 2018-01-24 formattimestamp()传入一个时间戳,返回一个date对象,例如: 差看执行结果 2018-01-24 strftime格式化,例如: 查看执行结果: 20180124 查看执行结果: 2018-01-27 2、time方法主要用于时间的操作,例如 差看执行结果: 23:59:59.999999 3、datetime 类其实是可以看做是 查看执行结果: 2018-01-24 16:49:43.875425 datetime也可以直接来加减天数,例如: 查看执行结果: 2018-01-20 16:54:39 pymysql 模块 首先确认有没有安装pymysql模块 先导入pymysql模块。如果没有报错,则说明已经安装了pymysql; import pymysql #导入 如果没有安装可以使用pip命令进行安装: 对数据库进行操作,我们需要进行以下操作步骤: 1、链接上mysql,使用到:IP 端口号 账号 密码 数据库名称 2、建立游标 3、执行sql 4、获取结果 实例: 查看执行结果: ((5, '123', '202cb962ac59075b964b07152d234b70'), (8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (2, 'liwang', 'd123dasd8192738127398sd123'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123')) 1、创建游标时,默认查询数据为元组类型,可以指定类型为字典类型,如下: 执行查看结果: [{'id': 5, 'username': '123', 'passwd': '202cb962ac59075b964b07152d234b70'}, {'id': 8, 'username': '1234', 'passwd': '81dc9bdb52d04dc20036dbd8313ed055'}, {'id': 7, 'username': '222', 'passwd': 'bcbe3365e6ac95ea2c0343a2395834dd'}, {'id': 6, 'username': '234', 'passwd': '289dff07669d7a23de0ef88d2f7129e7'}, {'id': 2, 'username': 'liwang', 'passwd': 'd123dasd8192738127398sd123'}, {'id': 3, 'username': 'lwwang', 'passwd': 'd1ww23dasd8192738127398sd123'}] 2、fetch的数据类型 fetch数据类型有两种, fetchone 只获取一条结果,他的结果放到一个一维数组中 fetchall 获取所有结果,他把结果放到一个二维元组 查看执行结果: (5, '123', '202cb962ac59075b964b07152d234b70') 我们先执行fetchall,再执行fetchone看一下: 查看执行结果: ((5, '123', '202cb962ac59075b964b07152d234b70'), (8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (2, 'liwang', 'd123dasd8192738127398sd123'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123')) 我们看到上边的执行结果: 第二个fetchone的执行结果是空,这就与游标的位置有关了; 这就需要控制游标操作来读取数据; 3、控制游标 在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置, 如: cursor.scroll(1,mode='relative') # 相对当前位置移动 cursor.scroll(2,mode='absolute') # 相对绝对位置移动 实例: 查看执行结果: ((5, '123', '202cb962ac59075b964b07152d234b70'), (8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (2, 'liwang', 'd123dasd8192738127398sd123'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123')) 可以看到设置的1,位下标为1的位置,如果想要从头开始读取,可以设置为0; 查看执行结果: ((5, '123', '202cb962ac59075b964b07152d234b70'), (8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (2, 'liwang', 'd123dasd8192738127398sd123'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123')) 可以看到relative模式的相对路径,设置为-1的时候,是向前移动了一个位置,如果relative模式设置为正,则是当前位置向后移动几个位置; 查看执行结果: (5, '123', '202cb962ac59075b964b07152d234b70') 可以看到fetch数据的时候是依次读取的,不是从头读取。读一次取一行,运行两次则是取第二条。 4、写操作的时候,如insert、update、delete 语句需要commit提交操作 查看执行结果: ((5, '123', '202cb962ac59075b964b07152d234b70'), (8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (11, 'lifei', 'asdasd123q12aasdsd'), (9, 'lijing', 'asdasd123q12aasdsd'), (2, 'liwang', 'd123dasd8192738127398sd123'), (12, 'lizhong', 'asdasd123q12aasdsd'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123')) 可以看到,插入了我们执行sql的数据; Redis缓存数据库 要使用Redis同样需要先安装,导入,与pymysql操作类似: pip install redis 导入Redis import redis 我们都知道,数据库分为关系型数据库和非关系型数据库; 非关系型数据库就是nosql类型,没有库表关系,比传统的关系型数据库快,常用的nosql型数据库有: memecache :数据存在内存里 key-value 形式 redis: 数据存在内存里,用来提高性能 MongoDB:数据存在磁盘上 对redis进行操作,可以在客户端直接操作,也可以通过python链接redis进行操作。 1、客户端操作 客户端操作可以下载redis-desktop-manager软件。 安装成功后,建立链接(要链接redis 首先保证redis服务器是运行状态。): 如果出现链接失败,的情况,如下: 需要做下面的事: 在redis.conf配置文件中,进行如下配置, 注释掉 bind 127.0.0.1 设置密码: requirepass xxxxxxx 设置密码 为了安全一定要设,而且这里如果不绑定ip也不设密码的话,redis是默认保护模式,只能本虚拟机访问,不允许其他ip访问 保存配置文件,重启redis服务,查看虚拟机ip; 重新进行链接:链接成功 redis默认有16个DB,可以通过界面来添加相应数据: 2、python操作 通过脚本操作redis: 1、导入redis模块 2、链接redis 3、操作redis 对于关闭redis的问题,不需要手动关闭redis, 参考原因:当我们用Redis和StrictRedis创建连接时,其实内部实现并没有主动给我创建一个连接,我们获得的连接是连接池提供的连接,这个连接由连接池管理,所以我们无需关注连接是否需要主动释放的问题。另外连接池有自己的关闭连接的接口,一旦调用该接口,所有连接都将被关闭。 通过客户端我们也可以看到,redis是一个key-value存储系统,支持的value类型:string,list,set,zset(有序集合),hash(哈希类型) 我们先来创建一个redis链接: 实例: string类型 对redis进行操作,我们可以使用set()添加数据,get()获取数据,delete()删除数据; 如下: import redis 查看执行结果: 获取数据的结果: b'123456' 删除数据结果: 我们看到上面获取数据的时候返回的是一个b‘123456’,属于bytes类型,在我们的日常操作中bytes类型很不方便,说以我们可以转化成字符串类型方便操作。 decode方法是将bytes类型转化成字符串类型 例如: 查看执行结果: 123456 添加数据后,我们在后台管理界面可以看到一个TTL的值是-1,这个字段是来控制失效时间的,默认的set的数据是永久有效的,如果要设置失效时间可以用setex来设置,如下: 查看执行结果: abcdefghijk 查看客户端:显示TTL时间剩余9秒,超过20秒之后重新加载db3,已经找不到pei_session这条数据了: 20以后: 上面用到的set(),get(),delete(),setex()都是针对string类型的,K -V模式(redis里边的string类型); 我们常用到的redis数据类型还有hash类型 hash类型 对于hash类型的操作要使用hset(),hget(),hgetall(),例如: hset(name,key,value):存储字典 查看执行结果:123456 查看客户端展示形式 当哈希表中有多条数据的时候获取出来,展示的是一个字典表: import redis 查看执行结果 {b'li': b'123456', b'zhao': b'123456', b'wang': b'123456', b'he': b'123456'} 如果要把每一个key 和 value 都转换成字符串可以循环取值: 查看执行结果: {'he': '123456', 'li': '123456', 'wang': '123456', 'zhao': '123456'} 如果要添加文件夹的话可以用:来控制,例如: 查看执行结果: 对hash类型的也可以建多个文件夹: 查看执行结果: keys()获取所有的key值: 查看执行结果: [b'info:user:name', b'user', b'file:log', b'file:img:001', b'test', b'file:data:ok'] 可以用*通配符进行模糊查询: 查看执行结果: [b'info:user:name', b'user'] type()获取key的类型: 查看执行结果: b'hash' 下面来做一个小程序,实现redis的数据迁移: 分析:1、需要链接两个redis 2、取出第一个redis的key,判断key的类型 3、取出redis的值,然后set进第二个redis 4、如果是hash类型的,需要再循环一次取出值 实例: 查看执行结果: db3中的数据已经迁移到了db4中; 4、flask模块 在使用flask模块之前我们先来了解一下mock技术, mock测试就是在测试过程中,对于某些不容易构造或者不容易获取的对象,用一个虚拟的对象来创建以便测试的测试方法。 什么情况下会使用mock技术: 1、被测代码中需要依赖第三方接口返回值进行逻辑处理,可能因为网络或者其他环境因素,调用第三方经常会中断或者失败,无法对被测单元进行测试,这个时候就可以使用mock技术来将被测单元和依赖模块独立开来,使得测试可以进行下去。 2、被测单元依赖的模块尚未开发完成,而被测单元需要依赖模块的返回值进行后续处理 3、 被测单元依赖的对象较难模拟或者构造比较复杂 下面我们就用flask模块来实现。 要使用flask模块首先要安装,导入: pip install flask import flask#导入 Flask是一个使用 Python 编写的轻量级 Web 应用框架。可以给web前台提供后台服务。 1、获取一个类似句柄的东西app,所有的操作都要通过app来执行,通俗的说就是把当前的文件当做一个后台服务 2、设置一个简单的URL :访问路径,这个URL是提供给web前台的接口,有了接口,我们也得提供接口内容。 3、在URL下设计一个函数 def func() 4、启动整个程序 app.run(port=9999) 实例: import pymysql 运行: 输入地址,拼接路径就可以获取到数据: http://127.0.0.1:8888/get_user 这样就完成了一个接口的开发。 标准的程序框架设置,是下面这种形式: 说明: 好了 这次就学习到这了哦! 还想学习的话,记得收藏及关注哦. 感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走: ① 2000多本软件测试电子书(主流和经典的书籍应该都有了) ② 软件测试/自动化测试标准库资料(最全中文版) ③ 项目源码(四五十个有趣且经典的练手项目及源码) ④ Python编程语言、API接口自动化测试、web自动化测试、App自动化测试(适合小白学习) ⑤ Python学习路线图(告别不入流的学习) 在我的QQ技术交流群里(技术交流和资源共享,广告进来腿给你打断) 可以自助拿走,群号768747503备注(csdn999768747503备注(csdn999))群里的免费资料都是笔者十多年测试生涯的精华。还有同行大神一起交流技术哦。 版权声明:本文为CSDN博主「自动化测试君」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
random.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: b <= n <= a。如果 a print(random.uniform(250,20))
print(random.uniform(10,20))
12.795665102733665
random.choice从序列中获取一个随机元素。函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。print(random.choice('1234567890'))
print(random.choice(['a','b','c','d','e','f','g']))
print(random.choice((11,21,31,41,51,61,71,81,91)))
d
11
random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列;print(random.sample((11,21,31,41,51,61,71,81,91),4))
random.shuffle(x[, random]),用于将一个列表中的元素打乱,改变原有列表。s=random.sample((11,21,31,41,51,61,71,81,91),4)
print(s)
random.shuffle(s)#洗牌,打乱顺序,只能传list,会改变原列表
print(s)
[41, 51, 31, 61]print(dir(string))
print(string.digits)#0-9的字符串
print(string.ascii_letters)#大写加小写
print(string.ascii_lowercase)#所有的小写字符
print(string.ascii_uppercase)#所有大写字符
print(string.punctuation)#所有的特殊字符
print(string.capwords('sss'))#首字母大写
print(string.hexdigits)
print(string.printable)#所有字符
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
abcdefghijklmnopqrstuvwxyz
ABCDEFGHIJKLMNOPQRSTUVWXYZ
!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
0123456789abcdefABCDEF
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~ print(time.time())
print(int(time.time()))#当前的时间戳
print(time.localtime())
tm_year :年print(time.localtime(1516103746))
print(time.gmtime())#默认取标准时区的时间元祖
print(time.gmtime(1516103746))#如果传入了一个时间戳,那么就把这个时间戳转化成时间元祖
time.struct_time(tm_year=2018, tm_mon=1, tm_mday=16, tm_hour=11, tm_min=55, tm_sec=46, tm_wday=1, tm_yday=16, tm_isdst=0)print(time.mktime(time.localtime()))#需要传入一个时间元组
#print(time.mktime())#不传会报错
time.sleep(5)
print('www')
把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回)转化为格式化的时间字符串,格式由参数format决定。如果未指定,将传入time.localtime()。如果元组中任何一个元素越界,就会抛出ValueError的异常。函数返回的是一个可读表示的本地时间的字符串。print(time.strftime("%Y%m%d %H:%M:%S",time.localtime()))
print(time.strftime('%Y-%m-%d %H:%M:%S',time.gmtime(1516103746)))
2018-01-16 11:55:46cur_time=time.strftime('%Y-%m-%d %H:%M:%S')#当前时间的格式化时间
cur_time1=time.strftime('%Y%m%d')
print(cur_time)
print(cur_time1)
20180116
将格式字符串转化成struct_time.
该函数是time.strftime()函数的逆操作。time strptime() 函数根据指定的格式把一个时间字符串解析为时间元组。所以函数返回的是struct_time对象。stime="2018-1-1 20:20:00"#定义一个格式化时间
str_time=time.strptime(stime,"%Y-%m-%d %H:%M:%S")#将格式化时间转化成时间元组
print(str_time)
sc_time=time.mktime(str_time)#将时间元组转化成时间戳
print(sc_time)
1514809200.0def timestampToStr(timestamp):
strc_time=time.gmtime(timestamp)
strf=time.strftime("%Y-%m-%d %H:%M:%S",strc_time)
return strf
def strfTotimestamp(stime,format='%Y-%m-%d %H:%M:%S'):
strc_time=time.strptime(stime,format)
timestamp=time.mktime(strc_time)
return timestamp
res=timestampToStr(1515925099)
print(res)
tim=strfTotimestamp("2018-2-22 12:11:22")
print(tim)
1519272682.0h=hashlib.md5(b"33333")#定义一个哈希函数,只能传入字节对象,不能传入字符串
print(h.hexdigest())#返回的是一个字节对象,用hexidigest 返回一个字符串
st="1234567890"
h=hashlib.md5(st.encode())
print(h.hexdigest())
import hashlib
def md5_pwd(st:str):#规定传参的类型必须是str类型
bytes_st=st.encode()
h=hashlib.md5(bytes_st)
pwd=h.hexdigest()
return pwd
st="peiyingfei"
res=md5_pwd(st)
print(res)
#md5加密是不可逆的,不能被解密
#一些解密的网站,其实是撞库,与库里边的保存的md5值相等了
#sha256加密
import hashlib
st='asdasdasd'
bytes_st=st.encode()
sha_256=hashlib.sha256(bytes_st)
print(sha_256.hexdigest())
import base64
r=base64.b64encode('23123123'.encode())#加密encode
res=r.decode()
print(res)#把bytes类型转化成字符串
jiemi_res=base64.b64decode(res)
print(jiemi_res.decode())
python自动化测试学习笔记-5常用模块
year年份、month月份及day日期三部分构成:a=datetime.date.today()#返回当前日期
print(a)
b=datetime.date(2018,3,23)#传入一个日期
print(b)
print(b.year)
print(b.month)
print(b.day)
2018-03-23
2018
3
23c=time.time()#当前时间的时间戳
d=datetime.date.fromtimestamp(c)#formtimestamp传入一个时间戳,返回一个date对象
print(d)
e=datetime.date.today()
f=datetime.date.today().strftime('%Y%m%d')
print(e)
print(f)
timedelta加减相应的天数
print(datetime.date.today()+datetime.timedelta(3))
print(datetime.time.max)#时间的最大值
print(datetime.time.min)#时间的最小值
print(datetime.time(12,00,59).strftime('%H:%M:%S'))#对传入的时间格式化
00:00:00
12:00:59date类和time类的合体,其大部分的方法和属性都继承于这二个类,print(datetime.datetime.today())
print(datetime.datetime.now())
print(datetime.datetime.today().strftime('%Y-%m-%d %H:%M:%S'))
print(datetime.datetime(2018,1,12,12,59,59))
2018-01-24 16:49:43.875425
2018-01-24 16:49:43
2018-01-12 12:59:59a=datetime.datetime.today()+datetime.timedelta(-4)
print(a.strftime('%Y-%m-%d %H:%M:%S'))
pip install pymysqlimport pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchall()
print(res)
cur.close()#先关闭游标
conn.close()#在关闭链接
可以看到取出的数据为一个二维元组类型。import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor(cursor=pymysql.cursors.DictCursor)
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchall()
print(res)
print(res[2]['id'])
cur.close()#先关闭游标
conn.close()#在关闭链接
可以看到结果为一个list,list中是一个个字典表。如果要查看某一个字段的值,可以直接使用列表及字典的获取数据的方式来获取import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchone()#只获取一条结果,他的结果放到一个一维数组
res1=cur.fetchall()#获取所有结果,是一个二维元祖,它把每一个值放到一个元祖里,每一条数据的每一个字段存到第二个元祖
print(res)
print(res1)
cur.close()#先关闭游标
conn.close()#在关闭链接
((8, '1234', '81dc9bdb52d04dc20036dbd8313ed055'), (7, '222', 'bcbe3365e6ac95ea2c0343a2395834dd'), (6, '234', '289dff07669d7a23de0ef88d2f7129e7'), (2, 'liwang', 'd123dasd8192738127398sd123'), (3, 'lwwang', 'd1ww23dasd8192738127398sd123'))import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
tes=cur.fetchone()#指定游标类型,每一条取出的是一个字典,列名就是key值
res=cur.fetchall()#指定游标类型后,fetchall 取出的是一个list ,每个元素的值又是一个字典
print(res)
print(res1)
cur.close()#先关闭游标
conn.close()#在关闭链接
Noneimport pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchall()
cur.scroll(1,mode='absolute')
res1=cur.fetchone()
print(res)
print(res1)
cur.close()#先关闭游标
conn.close()#在关闭链接
(8, '1234', '81dc9bdb52d04dc20036dbd8313ed055')import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchall()
cur.scroll(-1,mode='relative')
res1=cur.fetchone()
print(res)
print(res1)
cur.close()#先关闭游标
conn.close()#在关闭链接
(3, 'lwwang', 'd1ww23dasd8192738127398sd123')import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
res=cur.fetchone()
res1=cur.fetchone()
print(res)
print(res1)
cur.close()#先关闭游标
conn.close()#在关闭链接
(8, '1234', '81dc9bdb52d04dc20036dbd8313ed055')import pymysql
#打开仓库大门#port 一定要写int类型
conn=pymysql.connect(host='192.168.59.60',user='root',passwd='123456',port=3306,db='txz',charset='utf8')
#建立游标,游标你的仓库管理员
cur=conn.cursor()
#执行sql
cur.execute('select * from users')
# #获取数据
sql="insert into users (username,passwd) VALUES ('lizhong','asdasd123q12aasdsd');"
cur.execute(sql)
conn.commit()
cur.execute("select * from users ;")
res=cur.fetchall()
print(res)
cur.close()#先关闭游标
conn.close()#在关闭链接
import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,passwd='123456',db=3)
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
#添加数据
r.set('test','123456')
#获取数据
res=r.get('test')
print(res)
#删除数据
r.delete('test')import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
#添加数据
r.set('test','123456')
#获取数据
res=r.get('test')
print(res.decode())
import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
#添加数据
r.setex('pei_session','abcdefghijk','20')
#获取数据
res=r.get('pei_session')
print(res.decode())
import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
#添加数据
r.hset('user','wang','123456')
#获取数据
res=r.hget('user','wang')
print(res.decode())
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
#获取数据
res=r.hgetall('user')
print(res)import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
redis_data=r.hgetall('user')
all_dat={}
for k,v in redis_data.items():#取出k ,v
k=k.decode()
v=v.decode()
all_dat[k]=v
print(all_dat)
import redis
#链接redis
r=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
r.set('file:log','123456')
r.set('file:img:001','001')
r.hset('info:user:name','wang','123456')
print(r.keys())#获取所有的key,是一个list
print(r.keys('*user*'))
print(r.type('user'))
print(r.type('file:data:ok'))
b'string'import redis
r1=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=3)
r2=redis.Redis(host='192.168.59.60',port=6379,password='123456',db=4)
ex_listkey=r1.keys()
#print(ex_listkey)
for key in ex_listkey:
if r1.type(key)==b'string':
r1_v=r1.get(key)
r2.set(key,r1_v)
elif r1.type(key)==b'hash':
r1_hash=r1.hgetall(key)
for k,v in r1_hash.items():
r2.hset(key,k,v)
else:
print('类型不考虑')
import redis
def op_mysql(host,user,passwd,db,sql,port=3306,charset='utf8'):
conn=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db=db,charset=charset)
cur=conn.cursor(cursor=pymysql.cursors.DictCursor)
cur.execute(sql)
sql_start=sql[:6].upper()
if sql_start=='SELECT':#取sql的前6位,判断它是什么类型的语句。
res=cur.fetchall()
else:
conn.commit()
res='ok'
cur.close()
conn.close()
return resimport flask
from tools import op_mysql#之前定的一个方法
import json
app=flask.Flask(__name__)
@app.route('/get_user',methods=['get','post'])
def get_alluser():
sql='select * from users'
res=op_mysql(host='192.168.1.105',user='root',passwd='123456',port=3306,db='test',sql=sql,charset='utf8')
response=json.dumps(res,ensure_ascii=False)
return response
app.run(port=8888,debug=True)


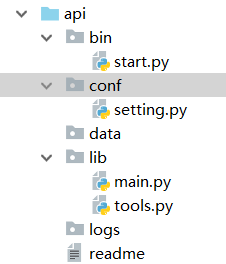
为了使逻辑更清晰
一般readme文件会说明程序的使用规则,如下:
#这个程序是xxx接口
#依赖 flask pysmysql python3
#pip install flask
#pip install pymysql
#python bin/start.py
conf 文件夹下主要存放配置文件
lib 目录用来写主逻辑
bin 目录存放启动文件start.py
接下来就可以进入到程序开发阶段了~

————————————————

原文链接:https://blog.csdn.net/Yanan990830/article/details/120660072