Track to Detect and Segment: An Online Multi-Object Tracker
论文与代码地址:链接
TraDeS
- 介绍和相关工作
- TraDeS Tracker
-
- 基于代价度量的关联模块
- 运动指导的特征整理模块
- Tracklet的生成
- 实验
- 总结
介绍和相关工作
TraDeS 延续JDT的思想,但是和一般的JDT不同的是,他利用追踪获得的信息来反馈检测,从而更好的进行追踪,不同范式对比如下图:
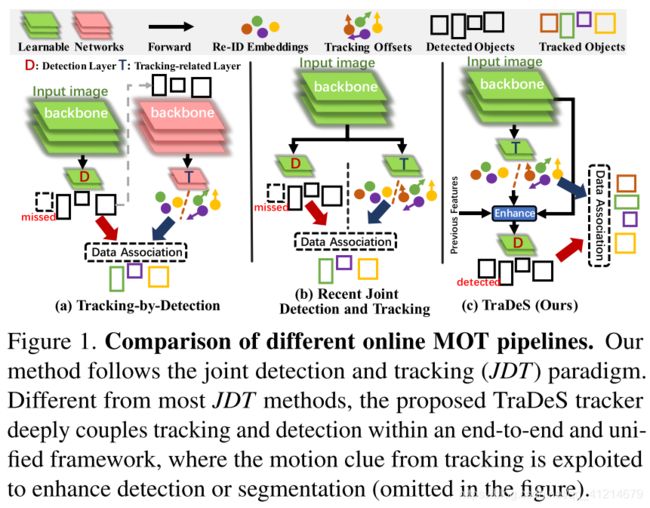
对比DBT范式的两个backbone,JDT范式有天然的优势,一个网络同时实现检测和关联任务,能更加快速的进行推理。
但是JDT虽然网络共享,良好的检测对于追踪的稳定和一致是有益的,但是相较于追踪后的结果,检测仍然是独立的,也就是追踪后得到的结果对下次检测几乎无任何关系。并且其中使用的re-ID损失往往不利于检测效果的提升,re-ID的损失关注的是类内的变量,需要尽可能的将类内拉开,而检测的目的是最大化类间的区别,最小化类内的变量。
面对以上问题,作者认为使用追踪的线索应该来帮助检测,并且在模型中考虑了类间变量,在学习有效embedding的同时,适应检测损失。基于以上两点提出了TraDeS模型,类似于CenterNet,模型中的特征图中的每个点代表一个目标中心或者背景区域,通过将追踪整合进检测的同时,专门设计了一个re-ID学习机制来解决问题。
相应的作者提出了两个模块:
1.基于代价度量的关联模块(a cost volume based association (CVA) module);
2.运动指导的特征整理模块(a motion-guided feature warper (MFW) module)。
CVA模块通过backbone提取点级re-ID embedding特征来构建一个存储两帧间的所有embedding对之间的匹配相似度的代价向量(cost volume)。利用代价度量,推理出追踪的偏移(所有点的时空位移,如潜在目标的中心点在两帧中位移)。这些追踪偏移加上提取的embedding一起构建数据关联。
MFW利用追踪偏移作为运动线索,用来传播和增强目标特征。最终传播的特征和当前的特征一起聚集来实现检测和分割。
如下图所示,追踪偏移是参考外貌embedding相似度进行预测的,因此模型可以在大规模运动或者低帧情况下匹配目标(图3),也可以在不同数据集中实现精准追踪。


有之前的工作尝试过使用追踪的结果来为原始检测得分赋权,虽然利用了追踪信息,但是还是存在缺点:
- 追踪只在检测后处理(检测结果已经出了,只影响其得分)起作用,检测和追踪任然单独优化,这样追踪器的效果任然依赖于检测器。
- 手动重新赋权的机制需要对具体检测器和追踪器进行人工微调。
和之前工作相比,TraDeS 的检测器利用追踪器的结果进行额外学习,且不需要复杂的赋权机制,检测性能更加鲁棒。
代价度量(Cost Volume.)之前也已经被成功运用到了两帧之间关联像素的深度评估或者光流评估,这里引用到MOT进行学习re-ID embedding和推导追踪偏移。
TraDeS Tracker
TraDeS基于基于点的检测器进行构建的,CenterNet输入图片 I I I尺寸为 R H × W × 3 R^{H×W×3} RH×W×3,通过backbone网络 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)获得特征基础特征 f = ϕ ( I ) f = \phi(I) f=ϕ(I)., f ∈ R H F × W F × 64 , H F = H / 4 , W F = W / 4 f\in R^{H_F×W_F×64},H_F = H/4,W_F = W/4 f∈RHF×WF×64,HF=H/4,WF=W/4。一系列头卷积分支利用 f f f构建类级别中心热度图(center heatmap) P ∈ R H F × W F × N c l s P\in R^{H_F×W_F×N_{cls}} P∈RHF×WF×Ncls和具体任务预测图(2D目标获得3D目标)。 N c l s N_{cls} Ncls表示类别数,
CenterNet通过中心点(峰点 P P P)和在该点处相应的具体任务预测进行目标检测。

在CenterNet基础上增加额外的头来预测追踪偏移映射 O B ∈ R H F × W F × 2 O^B\in R^{H_F×W_F×2} OB∈RHF×WF×2用于数据关联, O B O^B OB用于计算所有点的在帧 t t t对应于过去帧 t − τ t-τ t−τ的时空位移。
TraDeS 模型如下:

基于代价度量的关联模块
代价度量:
从两张原图 I t I^t It和 I t − τ I^{t-τ} It−τ获得两个基础特征图 f t f^t ft和 f t − τ f^{t-τ} ft−τ。通过embedding网络 σ ( ⋅ ) σ(·) σ(⋅)提取相应的re-ID embedding: e t = σ ( f t ) ∈ R H F × W F × 128 \boldsymbol{e}^{t}=\sigma\left(\boldsymbol{f}^{t}\right) \in \mathbb{R}^{H_{F} \times W_{F} \times 128} et=σ(ft)∈RHF×WF×128。用这两个提取的embedding来构建存储当前帧点到过去帧相应点的密集相似度的代价度量。
具体计算首先通过对embedding进行倍率为2的下采样,获得 e ′ ∈ R H C × W C × 128 e^{\prime} \in \mathbb{R}^{H_{C} \times W_{C} \times 128} e′∈RHC×WC×128,其中 H C = H F / 2 , W C = W F / 2 H_C = H_F/2,W_C = W_F/2 HC=HF/2,WC=WF/2。对于从两张图获得的 e ′ t e^{\prime t} e′t和 e ′ t − τ e^{\prime{t−τ}} e′t−τ,通过矩阵乘法或者4维的代价度量 C ∈ R H C × W C × H C × W C C\in \mathbb{R}^{H_{C} \times W_{C}\times H_{C} \times W_{C}} C∈RHC×WC×HC×WC: C i , j , k , l = e i , j t e k , l ′ t − τ ⊤ (1) C_{i, j, k, l}=\boldsymbol{e}_{i, j}^{t} \boldsymbol{e}_{k, l}^{\prime t-\tau \top} \tag{1} Ci,j,k,l=ei,jtek,l′t−τ⊤(1)
C i , j , k , l C_{i, j, k, l} Ci,j,k,l表示 t t t帧中点 ( i , j ) (i,j) (i,j)和 t − τ t − τ t−τ帧中点 ( k , l ) (k, l) (k,l)的embedding相似度,其中 f f f和 e ′ e^{\prime} e′中每个点表示一个实体。
追踪偏移:
基于代价度量 C C C,计算追踪偏移矩阵 O ∈ R H C × W C × 2 O\in \mathbb{R}^{H_{C} \times W_{C}\times 2} O∈RHC×WC×2,用以表示两帧之间相应点之间的时空位移。
简要介绍 O i , j ∈ R 2 O_{i,j}\in \mathbb{R}^{2} Oi,j∈R2的估计过程:
如上图2模型中所示,对于一个目标 x x x,中心点在 t t t帧中为 ( i , j ) (i,j) (i,j),可以从代价度量矩阵中获得他的相应点的2维代价度量图: C i , j ∈ R H C × W C \boldsymbol{C}_{i, j} \in \mathbb{R}^{H_{C} \times W_{C}} Ci,j∈RHC×WC。 C i , j \boldsymbol{C}_{i, j} Ci,j保存 x x x和其他 t − τ t − τ t−τ中所有点的匹配相似度。
然后使用 C i , j \boldsymbol{C}_{i, j} Ci,j进行 O i , j ∈ R 2 O_{i,j}\in \mathbb{R}^{2} Oi,j∈R2的估计:第一步: C i , j \boldsymbol{C}_{i, j} Ci,j分别通过 H C × 1 H_C × 1 HC×1和 1 × W C 1\times W_C 1×WC两个核进行最大池化,然后分别通过softmax进行标准化,获得 C i , j W ∈ [ 0 , 1 ] 1 × W C \boldsymbol{C}_{i, j}^{W} \in[0,1]^{1 \times W_{C}} Ci,jW∈[0,1]1×WC和 C i , j H ∈ [ 0 , 1 ] H C × 1 \boldsymbol{C}_{i, j}^{H} \in[0,1]^{ H_{C}\times 1} Ci,jH∈[0,1]HC×1。其中 C i , j W \boldsymbol{C}_{i, j}^{W} Ci,jW和 C i , j H \boldsymbol{C}_{i, j}^{H} Ci,jH组成目标 x x x出现在t − τ帧上指定的水平和垂直位置的概率。比如 C i , j , l W \boldsymbol{C}_{i, j,l}^{W} Ci,j,lW表示目标 x x x出现在t − τ帧上位置 ( ∗ , l ) (∗, l) (∗,l)的概率。第二步 :已经获得了 C i , j W \boldsymbol{C}_{i, j}^{W} Ci,jW和 C i , j H \boldsymbol{C}_{i, j}^{H} Ci,jH,即以及获得了到t − τ具体位置的概率。重新定义两个水平和垂直方向的偏移属性,分别表示 x x x出现在这些位置的真实偏移值, M i , j ∈ R 1 × W C \boldsymbol{M}_{i, j} \in \mathbb{R}^{1 \times W_{C}} Mi,j∈R1×WC和 V i , j ∈ R H C × 1 \boldsymbol{V}_{i, j} \in \mathbb{R}^{H_{C}\times 1} Vi,j∈RHC×1表示水平和垂直偏移属性:
{ M i , j , l = ( l − j ) × s 1 ≤ l ≤ W C V i , j , k = ( k − i ) × s 1 ≤ k ≤ H C (2) \left\{\begin{array}{ll} M_{i, j, l}=(l-j) \times s & 1 \leq l \leq W_{C} \\ V_{i, j, k}=(k-i) \times s & 1 \leq k \leq H_{C} \end{array}\right. \tag{2} {Mi,j,l=(l−j)×sVi,j,k=(k−i)×s1≤l≤WC1≤k≤HC(2)
s s s表示特征图 e ′ e' e′较于原图的缩放倍数,实验中改为8。 M i , j , l M_{i,j,l} Mi,j,l表示 x x x出现在t − τ中位置 ( ∗ , l ) (∗, l) (∗,l)的水平偏移。最终的追踪偏移通过可能性矩阵和偏移矩阵的点积推导: O i , j = [ C i , j H ⊤ V i , j , C i , j W M i , j ⊤ ] ⊤ (3) \boldsymbol{O}_{i, j}=\left[\boldsymbol{C}_{i, j}^{H \top} \boldsymbol{V}_{i, j}, \boldsymbol{C}_{i, j}^{W} \boldsymbol{M}_{i, j}^{\top}\right]^{\top}\tag{3} Oi,j=[Ci,jH⊤Vi,j,Ci,jWMi,j⊤]⊤(3)
轨迹偏移矩阵 O \boldsymbol{O} O大小为 H C × W C H_C ×W_C HC×WC,每个元素包含两个量, O ∈ R H C × W C × 2 \boldsymbol{O}\in \mathbb{R}^{H_{C} \times W_{C} \times 2} O∈RHC×WC×2。将其通过倍率为2的下采样,获得 O C ∈ R H F × W F × 2 \boldsymbol{O}^{C} \in \mathbb{R}^{H_{F} \times W_{F} \times 2} OC∈RHF×WF×2,用于MFW的运动线索以及后续的数据关联。
训练:
σ ( ⋅ ) σ(·) σ(⋅)是CVA中唯一可学习的部分,训练的目标是学习到有效的embedding e e e。为了实现对 e e e的监督,但是不直接使用re-ID损失对 e e e监督,而是去监督代价度量。首先当在 t t t帧的位置 ( i , j ) (i,j) (i,j)的目标在 t − τ t-τ t−τ帧的 ( k , l ) (k,l) (k,l)出现则定义 Y i j k l = 1 Y_{ijkl}=1 Yijkl=1,否则定义 Y i j k l = 0 Y_{ijkl}=0 Yijkl=0。然后使用focal loss的形式计算CVA逻辑回归训练损失:
L C V A = − 1 ∑ i j k l Y i j k l ∑ i j k l { α 1 log ( C i , j , l W ) + α 2 log ( C i , j , k H ) if Y i j k l = 1 0 otherwise (4) L_{C V A}=\frac{-1}{\sum_{i j k l} Y_{i j k l}} \sum_{i j k l}\left\{\begin{array}{cl} \alpha_{1} \log \left(C_{i, j, l}^{W}\right)+\alpha_{2} \log \left(C_{i, j, k}^{H}\right) & \text { if } Y_{i j k l}=1 \\ & \\ 0 & \text { otherwise } \end{array}\right. \tag{4} LCVA=∑ijklYijkl−1ijkl∑⎩⎪⎨⎪⎧α1log(Ci,j,lW)+α2log(Ci,j,kH)0 if Yijkl=1 otherwise (4)
其中 α 1 = ( 1 − C i , j , l W ) β \alpha_1 = (1-C^W_{i,j,l})^\beta α1=(1−Ci,j,lW)β, α 2 = ( 1 − C i , j , k H ) β \alpha_2 = (1-C^H_{i,j,k})^\beta α2=(1−Ci,j,kH)β, β \beta β是focal loss的超参。 C i , j , l W \boldsymbol{C}_{i, j,l}^{W} Ci,j,lW和 C i , j , k H \boldsymbol{C}_{i, j,k}^{H} Ci,j,kH已经由softmax计算得出,不仅会存在 ( i , j ) (i,j) (i,j)和 ( k , l ) (k,l) (k,l)的相似度,也包含了 ( i , j ) (i,j) (i,j)和其他所有点的相似度信息。通过如此优化,不仅强制一个对象不仅在前一个框架中接近自己,而且排斥其他对象和背景区域。
下面会有实验证明这种损失的有效性,如图3和图6所示,该模块定义的轨迹偏移可以在低帧或者一些列运动场景下有很强的鲁棒。
运动指导的特征整理模块
MFW模块的目的是利用预测的轨迹偏移 O C O^C OC作为运动线索来调整和传播 f t − τ f_{t−τ} ft−τ到当前帧,以便弥补和增强 f t f_t ft。通过一个可变性卷积实现有效的时序传播,通过聚集传播来的特征从而增强 f t f_t ft。
时序传播:
可变性卷积(DCN)通过一个时空偏移图和一个过去的特征图作为输入,输出一个传播特征。时空偏移图 O D ∈ R H F × W F × 2 K 2 \boldsymbol{O}^{D} \in \mathbb{R}^{H_{F} \times W_{F} \times 2 K^{2}} OD∈RHF×WF×2K2使用从CVA模块获得的 O C O^C OC通过3 × 3卷积 γ ( ⋅ ) γ(·) γ(⋅)获得, K = 3 K=3 K=3为DCN的核宽和高。也可以将 f t − f t − τ f^t-f^{t−τ} ft−ft−τ获得的参差特征送入 γ ( ⋅ ) γ(·) γ(⋅)作为额外的运动线索。
由于主要是基于中心点的检测和分割,所以不直接调整 f t − τ f^{t−τ} ft−τ,而是通过热度图来给他一个中心的注意力获得最终的前一帧特征 f ˉ t − τ ∈ R H F × W F × 64 \bar{f}^{t-\tau} \in \mathbb{R}^{H_{F} \times W_{F} \times 64} fˉt−τ∈RHF×WF×64: f ‾ q t − τ = f q t − τ ∘ P a g n t − τ , q = 1 , 2 , … , 64 (5) \overline{\boldsymbol{f}}_{q}^{t-\tau}=\boldsymbol{f}_{q}^{t-\tau} \circ \boldsymbol{P}_{a g n}^{t-\tau}, \quad q=1,2, \ldots, 64\tag{5} fqt−τ=fqt−τ∘Pagnt−τ,q=1,2,…,64(5)
q q q是通道索引, ◦ ◦ ◦是哈德曼乘积。 P a g n t − τ ∈ R H F × W F × 1 \boldsymbol{P}_{a g n}^{t-\tau} \in \mathbb{R}^{H_{F} \times W_{F} \times 1} Pagnt−τ∈RHF×WF×1是从 P t − τ P^{t-\tau} Pt−τ(开头由CenterNet计算得到的)获得的不可知类的中心热度图。
获得了 O D O^D OD和 f ˉ t − τ \bar{f}^{t-\tau} fˉt−τ,通过DCN获得最终的传播模特征: f ^ t − τ = D C N ( O D , f ‾ t − τ ) ∈ R H F × W F × 64 \hat{\boldsymbol{f}}^{t-\tau}=D C N\left(\boldsymbol{O}^{D}, \overline{\boldsymbol{f}}^{t-\tau}\right) \in \mathbb{R}^{H_{F} \times W_{F} \times 64} f^t−τ=DCN(OD,ft−τ)∈RHF×WF×64
特征增强:
通过 f ^ t − τ \hat{\boldsymbol{f}}^{t-\tau} f^t−τ来增强 f t f^t ft对遮挡模糊等负面效果的抵抗获得特征 f ~ q t \tilde{\boldsymbol{f}}_{q}^{t} f~qt:
f ~ q t = w t ∘ f q t + ∑ τ = 1 T w t − τ ∘ f ^ q t − τ , q = 1 , 2 , … , 64 (6) \tilde{\boldsymbol{f}}_{q}^{t}=\boldsymbol{w}^{t} \circ \boldsymbol{f}_{q}^{t}+\sum_{\tau=1}^{T} \boldsymbol{w}^{t-\tau} \circ \hat{\boldsymbol{f}}_{q}^{t-\tau}, \quad q=1,2, \ldots, 64\tag{6} f~qt=wt∘fqt+τ=1∑Twt−τ∘f^qt−τ,q=1,2,…,64(6)
w t ∈ R H F × W F × 1 \boldsymbol{w}^{t} \in \mathbb{R}^{H_{F} \times W_{F} \times 1} wt∈RHF×WF×1是 t t t帧的自适应权重, ∑ τ = 0 T w i , j t − τ = 1 \sum_{\tau=0}^{T} \boldsymbol{w}_{i, j}^{t-\tau}=1 ∑τ=0Twi,jt−τ=1。 T T T为用于聚合的过去特征的数目。 w w w由两个卷积加一个softmax函数获得,实验中赋权比平均效果要好。
加强后的特征 f ~ q t \tilde{\boldsymbol{f}}_{q}^{t} f~qt送入头网络生成当前帧检测框或者masks。实验证明有效减少FN和修复消失目标的tracklet。
Tracklet的生成
总体结构如图2,基于 f ~ q t \tilde{\boldsymbol{f}}_{q}^{t} f~qt通过三个不同的头网络分别获得不同任务检测结果,对于检测使用CenterNet,对于分割,使用基于点的CondInst。
给定位置 ( i , j ) (i,j) (i,j)的检测,执行两轮数据关联:
DA-Round (i) :首先在 t − 1 t-1 t−1帧上坐标 ( i , j ) + O i , j C (i,j)+O^C_{i,j} (i,j)+Oi,jC且半径 r r r(所有检测框宽高的均值)内,先将他和最近的未匹配的检测关联, O i , j C O^C_{i,j} Oi,jC指标是 I t I^t It和 I t − 1 I^{t-1} It−1之间的轨迹偏移。
DA-Round (ii):如果该位置检测在第一轮未匹配上,则计算他的embedding和其余未匹配或历史中断的tracklets的embedding余弦相似度,将检测分配给相似度得分最高且需大于阈值(0.3)的轨迹。如果还未匹配,则作为新轨迹。
TraDeS Loss: L = L C V A + L d e t + L m a s k L=L_{C V A}+L_{d e t}+L_{m a s k} L=LCVA+Ldet+Lmask其中 L d e t L_{d e t} Ldet为CenterNet的2D,3D检测损失, L m a s k L_{m a s k} Lmask实例分割损失。
实验
消融实验:
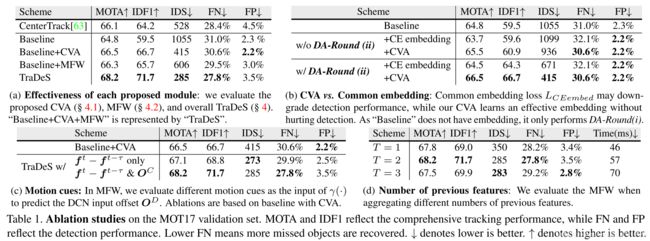
MOT Challenge 2D追踪数据集实验:
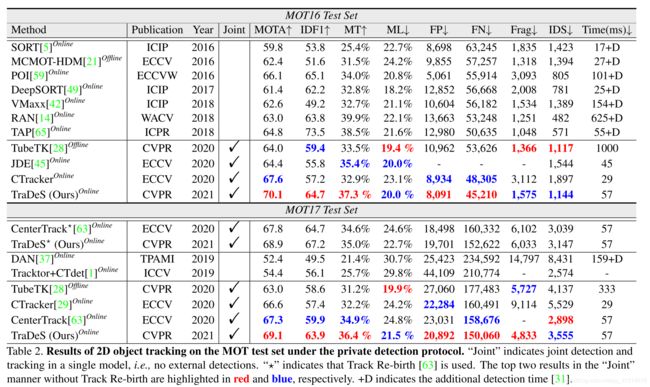
nuScenes数据集3D目标追踪实验:

MOTS实例分割实验:

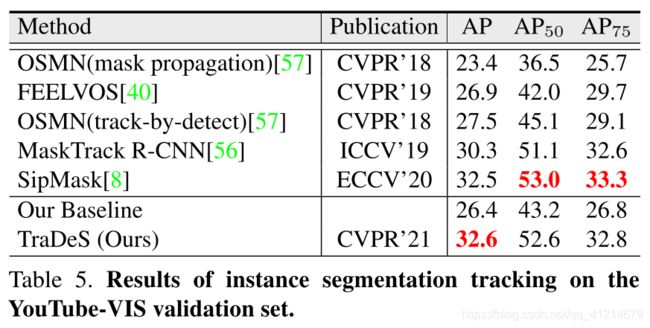
YouTube-VIS验证集实例分割:
总结
一个新颖的JDT模型,集中使用追踪信息来回馈检测,使用位置轨迹偏移信息更好指导检测。主要的两个模块CVA 和MFW,CVA负责学习re-ID的embedding以及为运动建模一个4维的代价度量;MFW从CVA接受运动信息,从而传播过去的目标特征图,增强当前帧特征图进行检测或者分割。