Sparse-Interest Network for Sequential Recommendation WSDM2021
摘要
顺序推荐中的最新方法着重于从用户的行为序列中学习下一个推荐的整体嵌入向量。但是,通过经验分析,我们发现用户的行为序列通常包含多个概念上不同的项目,而统一的嵌入向量主要受一个人最近的频繁动作的影响。因此,如果概念上相似的项目在最近的交互中不占主导地位,则可能无法推断出下一个首选项目。为此,另一种解决方案是用编码该用户意图的不同方面的多个嵌入矢量来表示每个用户。尽管如此,最近有关多兴趣嵌入的工作通常考虑了通过聚类发现的少量概念,这可能无法与真实系统中的大量项目类别相提并论。有效地建模大量不同的概念原型是一项艰巨的任务,因为项目在概念上通常不能很好地按精细的粒度进行聚类。此外,一个人通常只与一组稀疏的概念进行交互。有鉴于此,我们提出了一种新颖的稀疏兴趣网络(SINE),以进行顺序推荐。我们的稀疏兴趣模块可以从大型概念库中为每个用户自适应地推断出一组稀疏概念,并相应地输出多个嵌入。给定多个兴趣嵌入,我们将开发一个兴趣汇总模块,以主动预测用户的当前意图,然后使用该模块显式地对多个兴趣进行建模,以进行下一项预测。在几个公共基准数据集和一个大型工业数据集上的经验结果表明,SINE可以比最先进的方法取得实质性的进步。

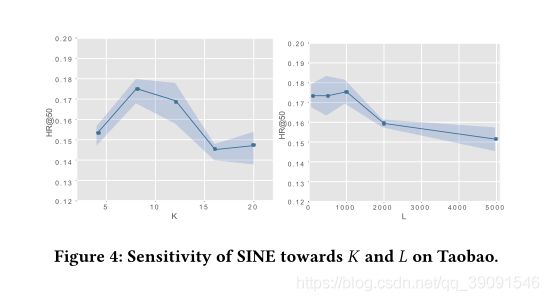
我就没懂这个图的含义
问题
但是,要从行业水平数据中的用户行为序列中有效地提取多个嵌入矢量,仍然存在一些挑战。首先,项目在概念上通常不能很好地聚集在实际系统中。尽管可以将项目的类别信息用作概念,但是在许多情况下,实际上这种类型的辅助信息由于注释噪声而可能不可用或不可靠。第二个挑战是从大型概念库中为用户自适应地推断出一组稀疏的感兴趣概念。推理过程包括选择操作,这是一个离散的优化问题,难于端到端训练。第三,给定多个兴趣嵌入向量,我们需要确定哪个兴趣可能会被激活以用于下一个项目的预测。在训练期间,下一个预测项目可以用作激活首选意图的标签,但是推断阶段没有这样的标签。该模型必须自适应地预测用户的下一个意图。
在本文中,我们提出了一种新的稀疏兴趣网络(SINE)用于顺序推荐来解决这些问题。SINE可以学习大量的兴趣组,并以端到端的方式捕获用户的多种意图。图4显示了SINE的整体结构。我们的稀疏兴趣提取模块自适应地从大量兴趣组中推断出用户交互的兴趣,并输出多个兴趣嵌入。聚合模块能够动态预测用户的下一个意图,有助于显式地捕获前N个项目推荐的多个兴趣。我们在几个公共基准和一个工业数据集上进行了实验。实验结果表明,我们的框架比最先进的模型性能更好,并产生了合理的项目聚类。
模型
先捕获用户意图,然后利用K临近算法来生成候选项目
用于捕获用户的多个意图的最先进的序列编码器可以概括为两类。第一类方法求助于强大的顺序编码器来隐含地提取用户的多重意图,例如基于多头自我注意的模型(又名变形金刚[43])。另一种类型的方法依赖于潜在的原型来显式地捕捉用户的多重意图。通常,由于意图检测和嵌入在实践中的混合性质,前一种方法可能会限制其捕获多个意图的能力。例如,实证结果表明,在推荐方面,Transformer学习的多个矢量表示似乎并不比单头实现[21]具有明显的优势。相反,后者通过聚类识别的概念可以有效地提取用户的不同兴趣,如文献[27,29]中经验证明的那样。然而,这些方法的可伸缩性很差,因为它们要求每个用户都有一个嵌入在每个概念下的意图,这在工业应用中很容易扩展到数千个。例如,在中国天猫的电商平台上,数百万甚至数十亿的商品属于1万多个专家标注的树叶类别[24个]。随着实际系统中存在大量的兴趣概念,需要一个可扩展的多兴趣提取模块。

第一个模块
正弦的架构(彩色效果更佳)。稀疏兴趣模块以用户的行为序列为输入,从庞大的兴趣组池中自适应地激活用户的兴趣,并输出多兴趣嵌入。然后,兴趣聚合模块通过主动预测用户的下一意图,帮助用户选择最喜欢的兴趣进行下一项推荐。SINE提供了以端到端的方式对项目进行聚类并推断用户稀疏兴趣集的能力。

a是用户行为的注意力权重向量。
2式首先是合并C和Z,然后top-k打分,最后得到用户的潜在矩阵
公式2是一个TOP-K选择技巧,它使得离散选择操作是可微的,前人的工作[8]发现它在逼近TOP-K选择问题时非常有效。
在推断出当前的概念原型Cu之后,我们可以根据用户与原型的距离来估计他/她的行为序列中的每一项与其相关的用户意图。
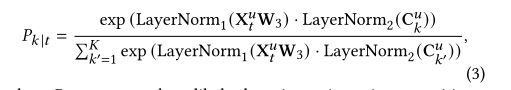
度量位置t的主要意图与潜在概念相关的可能性。
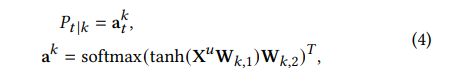
t和k换了位置的具体影响,以及p代表的含义
p是一个概率矩阵
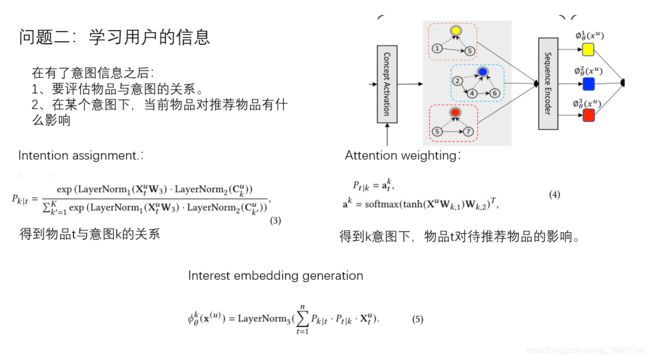

生成多个兴趣嵌入向量
到目前为止,我们已经介绍了稀疏兴趣网络的整个过程。给定用户的行为序列,我们首先从概念池中激活他/她喜欢的概念原型。然后执行意图分配以估计与输入序列中的每个项目相关的用户意图。然后,应用自关注层计算所有项目的关注度权重,用于下一项目预测。最后,根据公式5,通过加权和生成用户的多个兴趣嵌入。
第二个模块
在稀疏兴趣提取模块之后,我们得到每个用户的多个兴趣嵌入。一个自然的后续问题是如何利用各种兴趣进行实际推理。一种直观的解决方案是使用下一个预测项作为目标标签,以选择不同的兴趣嵌入进行训练[24]。尽管它很简单,但它的主要缺点是在推理过程中没有目标标签,这导致训练和测试之间的差距,并可能导致性能退化。
针对这一问题,我们提出了一种基于主动预测的自适应兴趣聚合模型。这里的动机是,更容易预测用户基于时间偏好的下一步意图,而不是找到理想的标签。具体地说,基于在公式3中计算的意图分配分数ptk,我们可以得到行为序列中所有项目的意图分布矩阵,表示为pu,

xu拔 是用户意图序列
不同兴趣的聚合权重计算如下

e是是不同兴趣的注意力载体。
The final user representation

整体思路
1.通过输入的序列中找到pool中最相关的K个concept得到Cu
2.Cu所选中的K跟每一个item发生的关系来生成pkt,ptk(捕捉item与attention的关系),然后用公式5得到特定用户意图的embedding
3 得到K个意图嵌入后,利用pool得到下一个意图后,与之前的K个意图做一个attention,最后加权求和得到Vu