基于简单MLP模型的加州房价预测
基于简单MLP模型的加州房价预测
摘要
机器学习是当前热度非常高的领域,可以对房价数据进行预测,具有很高的研究价值。为了更好地学习机器学习,将理论付诸于实践,本文从加州房价预测实验入手,提出了基于简单MLP的房价预测模型方法研究。
本文的主要研究内容为基于简单MLP模型的方法,提出了加州房价预测的模型。本文首先介绍了研究背景和意义,实验选取了来源于Kaggle上的一次竞赛California House Prices。在实验中,首先观察了训练数据以及测试数据,分析了自变量Sold Price与因变量的相关性,选取了用来训练的特征。接着,对数据进行预处理,对数值类型的特征进行特征归一化和缺失值的补充,使用了独热编码处理了离散值,最终得到了用于训练的特征。构建了一个简单MLP模型,共三个线性层,并对前两层使用了Relu()。训练函数借助了Adam优化器,其优点是它对初始学习率敏感度不强。使用了网格搜索结合K折交叉验证对超参数进行了调整。训练结束后将获得的模型应用于测试集,并将预测保存在CSV文件中提交到Kaggle查看结果。最终我在Kaggle上获得的score为。
将我的预测结果与简单线性模型的预测结果进行对比,结果显示在这次竞赛的数据上,所提出的模型预测精度更好,具有稳健性,适合用于加州房价预测。
关键词
房价预测;机器学习;
1. 数据指标说明及处理
1.1 数据来源
为了验证模型的普适性,本文选择的数据是Kaggle竞赛California House Prices的数据。该竞赛的任务是根据房子的信息,如卧室数量、居住面积、位置、附近的学校和卖家的摘要,预测房子的销售价格。数据包括2020年在加州售出的房屋,测试数据集中的房屋在训练数据集中的房屋之后售出。此外,私人排行榜上的房子也是在公共排行榜上的房子之后出售的。
1.2 数据指标说明
> 读入数据集之后首先对数据进行观察,代码和结果如下。
print(train_data.shape)
print(test_data.shape)
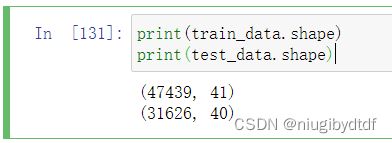
图1-1
可以观察到训练集共有47439个数据,40个特征,多出的一列是标签Sold Price。测试集有31626个数据,40个特征。
将训练集和测试集合并之后对数据进行总览,结果如下。
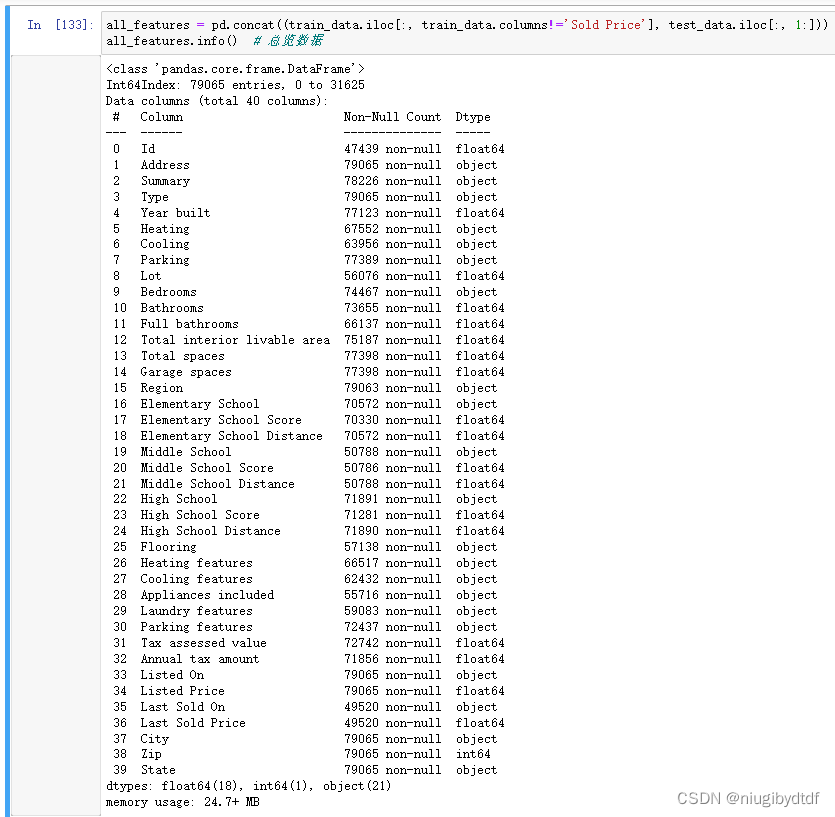
图1-2
1.2.1 影响因素特征
通过分析自变量Sold Price与因变量的相关性,得到的结果如下图。
#查看自变量与因变量的相关性
fig = plt.figure(figsize=(14,8))
abs(train_data.corr()['Sold Price']).sort_values(ascending=False).plot.bar()
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
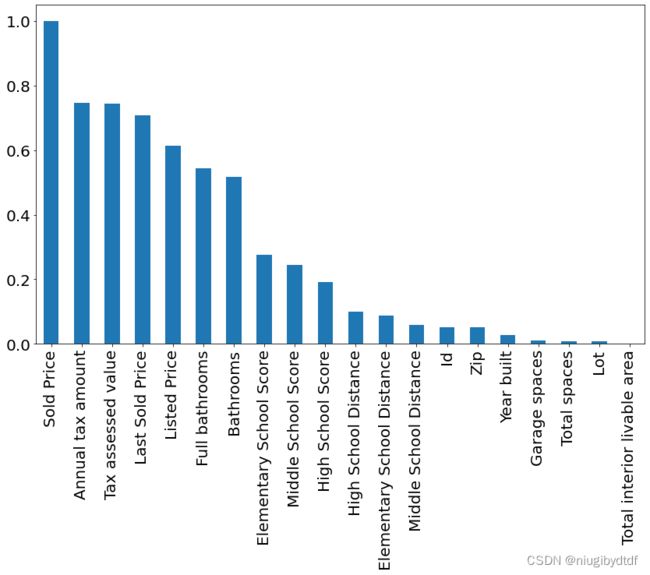
图1-3
结合上面两步,可以看到相关性大于0.5有这些:Annual tax amount,Tax assessed value,Last Sold
Price,Listed Price,Full bathrooms,Bathrooms。它们全是数值类型,将被加入用于训练的特征列。
1.3 数据预处理
在开始建模前,需要对特征进行预处理。
1.3.1 异常值处理
通过画出上一节中分析出的相关性高的特征的值的分布,通过分析剔除异常的值。
#异常值处理
figure=plt.figure()
sns.pairplot(x_vars=['Annual tax amount','Tax assessed value','Last Sold Price','Listed Price','Full bathrooms','Bathrooms'],
y_vars=['Sold Price'],data=train_data,dropna=True)
plt.show()
运行结果:
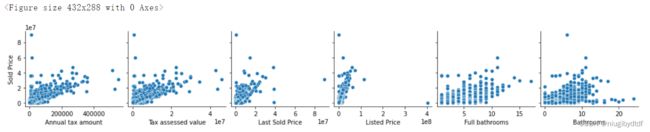
图1-4
分析第三个坐标轴,存在Last Sold Price大于8,但Sold
Price只有41e7的数据,删除。分析第五个坐标轴,存在Full bathrooms大于15,但Sold
Price小于51e7的数据,删除。分析第六个坐标轴,存在Bathrooms大于20,但Sold Price小于2*1e7的数据,删除。
删除异常值后重新打印出特征值的分布图,代码和运行结果如下。
#删除异常值
train_data = train_data.drop(train_data[(train_data['Last Sold Price']>8*1e7) &
(train_data['Sold Price']<4*1e7)].index)
train_data = train_data.drop(train_data[(train_data['Full bathrooms']>15) &
(train_data['Sold Price']<5*1e7)].index)
train_data = train_data.drop(train_data[(train_data['Bathrooms']>20) &
(train_data['Sold Price']<2*1e7)].index)
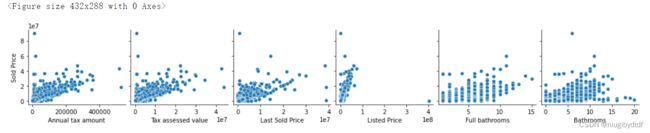
图1-5
1.3.2 特征归一化
适当地特征缩放可以加速梯度下降过程。通过将特征缩放到均值为0,方差为1来标准化数据:←(−)/
其中 和 分别表示均值和标准差。 现在,这些特征具有零均值和单位方差,即 [−]=−=0 和 [(−)2]=(2+2)−22+2=2 。 直观地说,我们标准化数据有两个原因: 首先,它方便优化。 其次,因为我们不知道哪些特征是相关的, 所以我们不想让惩罚分配给一个特征的系数比分配给其他任何特征的系数更大。
特征缩放代码如下:
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
1.3.3 空缺值填补
空缺值,如NaN会影响计算,所以需要填补空缺值。一般用该特征的均值来填补,因为之前进行过了特征归一化为均值0,所以每个数值特征的均值都为0,将0对空缺值进行替换。代码如下:
all_features[numeric_features] = all_features[numeric_features].fillna(0)
1.3.4 独热编码处理
在进行one-hot之前先观察object类型的特征有哪些,并且他们共有多少种不同的类别。代码和结果如下:
for in_object in all_features.dtypes[all_features.dtypes=='object'].index:
print(in_object.ljust(20),len(all_features[in_object].unique()))
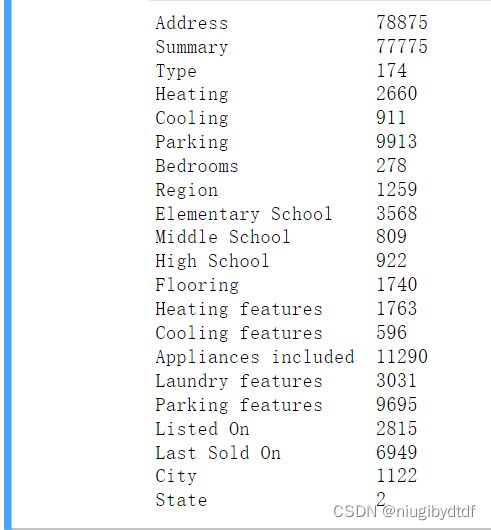
图1-6
> 最终选取了State、Type、Bedrooms加入用于训练的特征,并进行了one-hot。
# 选择特征列
features = list(numeric_features)
features.extend(['State','Type',"Bedrooms"])
all_features = all_features[features[1:]]
# 原本第一列是Id,去掉
print(all_features.shape)
#“Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指示符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
print(all_features.shape)
运行结果:
(79065, 21)
(79065, 474)
可以观察到,进行one-hot之后,特征列从21变成了474。
1.4 本章小结
本节对数据的来源和数据指标进行了说明,分析了影响因素的特征,对数据进行了预处理。数据预处理是房价预测的重要一环,正确的数据预处理使得模型预测事半功倍。这里的预处理做了异常值处理、特征归一化、空缺值填补和独热编码处理。
2. 基于简单MLP的房价预测模型
2.1 MLP模型
MLP又名多层感知机,也叫人工神经网络(ANN,Artificial Neural Network),除了输入输出层,它中间可以有多个隐藏层,如果没有隐藏层即可解决线性可划分的数据问题。最简单的MLP模型只包含一个隐藏层,即三层的结构,如下图。

图2-1
从上图可以看到,多层感知机的层与层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
2.2 预测评价指标
2.2.1 均方误差
均方误差(mean-square error, MSE)是反映估计量与被估计量之间差异程度的一种度量。设t是根据子样确定的总体参数θ的一个估计量,(θ-t)2的数学期望,称为估计量t的均方误差。它等于σ2+b2,其中σ2与b分别是t的方差与偏倚。
均方误差的公式:

2.3 模型与方法
本文提出的MLP模型的组成为:Linear+relu()+Linear+relu()+Linear。输入层的输入为474,输出为256。第二层Linear的输入是256,输出64。第三层Linear的输入是64,输出为1。损失函数用的是均方误差函数。
class MLP(nn.Module):
def __init__(self,in_features):
super().__init__()
self.layer1 = nn.Linear(in_features,256)
self.layer2 = nn.Linear(256,64)
self.out = nn.Linear(64,1)
def forward(self,X):
X = F.relu(self.layer1(X))
X = F.relu(self.layer2(X))
return self.out(X)
loss = nn.MSELoss()
房价就像股票价格一样,我们关心的是相对数量,而不是绝对数量。 因此,[我们更关心相对误差 −̂ ,] 而不是绝对误差
−̂ 。 例如,如果我们在俄亥俄州农村地区估计一栋房子的价格时, 假设我们的预测偏差了10万美元,
然而那里一栋典型的房子的价值是12.5万美元, 那么模型可能做得很糟糕。
另一方面,如果我们在加州豪宅区的预测出现同样的10万美元的偏差,在那里,房价中位数超过400万美元。这可能是一个不错的预测。
解决这个问题的一种方法是用价格预测的对数来衡量差异。 事实上,这也是比赛中官方用来评价提交质量的误差指标。 即将 转换为 。这使得预测价格的对数与真实标签价格的对数之间出现以下均方根误差:
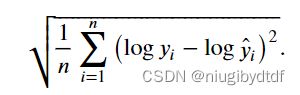
def log_rmse(net, features, labels):
# 为了在取对数时进一步稳定该值,将小于1的值设置为1
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()
训练函数借助了Adam优化器,它的优点是在一开始对学习率不那么敏感。
def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这里使用的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls
使用了K折交叉验证。它有助于模型选择和超参数调整。首先需要定义一个函数,在i交叉验证过程中返回第i的数据。具体地说,它选择第i个切片作为验证数据,其余部分作为训练数据。K折交叉验证在数据少的情况下合适使用。一般使用3折或5折。需要注意的是K折交叉验证比较费计算。
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
一般来讲模型的训练误差和验证误差会取K折交叉验证计算结果的平均值。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
in_features = X_train.shape[1]
net = MLP(in_features)
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k
3. 模型的预测结果
经过上面的步骤之后对模型进行训练,得到以下结果:
、
图3-1
3.1 测试集预测结果
在测试集上进行预测,并且将预测结果保存在.cvs文件中,用于上传到Kaggle平台。

图3-2
3.2 Kaggle上的预测结果
经过Kaggle平台的评测,得到1.02246的成绩。

图3-3
3.3 对比简单线性模型
这里的简单线性模型仅有一层线性层。且没有做独热编码。其测试结果log rmse为1.066426。其在Kaggle上的score为:1.12455。本文所提出的模型的lg rmse为0.784812。其在Kaggle上的score为1.02246,较前者在精度上有进步。

图3-4
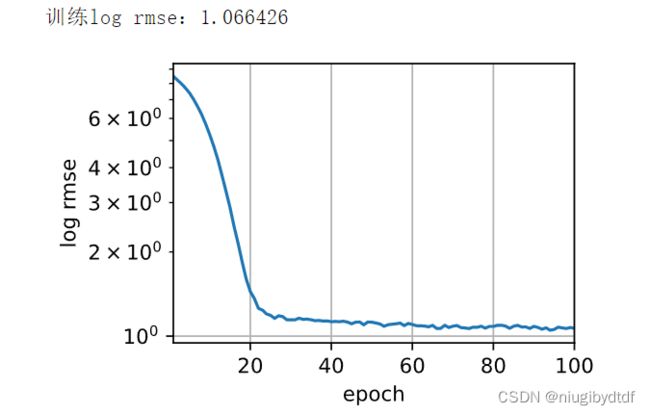
图3-5
3.4 本章小结
本章展示了所提出的模型在测试集上的预测结果以及在Kaggle上获得的score。最后与简单线性模型进行了对比,结果表明所提出的模型预测精度更好。
4. 总结与展望
本文通过实战Kaggle平台的竞赛California House
Prices,将机器学习课堂所学知识付诸于实践,深刻了知识理解,提高了动手能力。本文提出了基于简单MLP的加州房价预测模型,介绍了研究背景和意义,对数据进行预处理,最终得到了用于训练的特征。构建了一个简单MLP模型。使用了网格搜索结合K折交叉验证对超参数进行了调整。训练结束后将获得的模型应用于测试集,并提交到Kaggle查看结果。最终在Kaggle上获得的score为。
将我的预测结果与简单线性模型的预测结果进行对比,结果显示在这次竞赛的数据上,所提出的模型预测精度更好,具有稳健性,适合用于加州房价预测。
参考文献
[1]伍玉莹. 基于深度学习的房价预测方法研究[D].辽宁大学,2021.DOI:10.27209/d.cnki.glniu.2021.001036.