关于在python中TagMe包的使用说明以及测试
关于在python中TagMe包的使用说明以及测试
最近一段时间,忙着解决wikipedia-miner这个折磨人的自然语言处理工具,工具很强大,可以获取概念在维基百科当中的许多信息,还可以解决概念的歧义和标注问题。但是唯一的缺点就是安装很麻烦(是一个类似于SSM的javaweb项目),因为维基百科数据库很大,因此在数据的预处理阶段需要使用大数据的Hadoop等技术。从去年一直到今年都没解决这个安装问题(详细安装过程点击这里,但是很复杂),问了一些已经工作的人也没什么结果,前段时间导师要我仔细研究内部代码使其运行部分功能即可,代码翻来翻去看了一个星期感觉还是没什么突破(但是感觉只要有类似于page.csv文件还是可以运行起来,但是网络上找了很多都没有),发现都没办法跟老师交代了,还想让老师继续带我做科研的。
不过在绝望当中我翻开导师要我阅读的文献,又看了看老外的研究,发现还有一个强大的工具可以代替wikipedia-miner做标注(Annotate)功能,这就是今天我们的主角“TagMe”,上网找了找资料,发现国内这个工具用的比较少,所以特写此文章,希望对各位对维基百科感兴趣的研究者和爱好者有所帮助。
接下来的部分首先会介绍该工具,之后就是工具的安装和使用过程,最后通过老外文章当中的例子以及老师给我的一段小新闻语料做个实验来验证该工具的有效性。
-
Tagme工具的介绍
TagMe目前是科学界最好的实体链接工具之一,具有非常好的性能,特别是在注释短文本时(即由几十个术语组成的那些)。
简单来讲这个工具主要解决一段文本当中的概念标注问题,任意一段文本当中需要提取相关的概念来对整段文本进行分析,因此筛选出来的概念既要满足“可查询”还要满足“无二义性”,可查询在这里本文要保证概念可以在维基百科当中找到对应的页面,例如概念“Artificial neural network”其实就是概念“Neural Network”更正式的定义,也就是概念“Neural Network”在维基百科当中没有其页面,但是“Artificial neural network”有,因此当文章当中出现概念“Neural Network”时我们要想办法把它转化成“Artificial neural network”使之能够查询和计算。再者就是无二义性,例如概念“Apple”包含的含义有很多,其中就有指代“水果苹果”或者“苹果公司”,要想知道其真正含义要结合其上下文,如果指代苹果公司,那么应该把该概念转化成“Apple Inc.”,该概念就可以明确表达苹果公司的含义。 -
安装过程
使用该工具有多种多样的方式,在本文我们选择Python语言来调用对应的API进行,还有一种方法是直接通过Http请求来访问获取到json数据的格式,但是个人感觉不太方便。
既然使用Python,那就说明该工具有对应的第三方的包可以下载,我在这里使用Pychram来进行安装,包名“tagme”,细节就不多介绍了。安装完后还不能用,因为还要有个号,对,没错,你还要去注册一个账号使其拥有一个叫“Authorization Token”的序列号,当然注册是免费的。
注册的话就去这里,注册完毕后进入你的主页,即你的Tagme Home,类似于下面的页面:
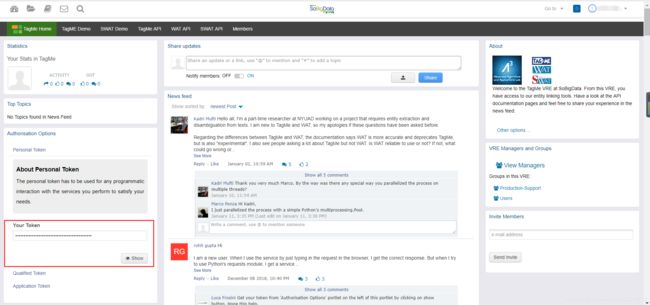
在左下角会看到你的“Your Token”,把它复制出来就可以了,具体用在哪里见后。 -
使用过程
当然使用该工具是必须要写代码的,我在这里已经帮大家写好了函数直接调用,这样可以避免接触那些底层代码,详细见下:
# -*- coding:utf-8 -*-
# Author:Zhou Yang
# Time:2019/3/30
import tagme
import logging
import sys
import os.path
# 标注的“Authorization Token”,需要注册才有
tagme.GCUBE_TOKEN = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx-xxxxxxxxx"
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
def Annotation_mentions(txt):
"""
发现那些文本中可以是维基概念实体的概念
:param txt: 一段文本对象,str类型
:return: 键值对,键为本文当中原有的实体概念,值为该概念作为维基概念的概念大小,那些属于维基概念但是存在歧义现象的也包含其内
"""
annotation_mentions = tagme.mentions(txt)
dic = dict()
for mention in annotation_mentions.mentions:
try:
dic[str(mention).split(" [")[0]] = str(mention).split("] lp=")[1]
except:
logger.error('error annotation_mention about ' + mention)
return dic
def Annotate(txt, language="en", theta=0.1):
"""
解决文本的概念实体与维基百科概念之间的映射问题
:param txt: 一段文本对象,str类型
:param language: 使用的语言 “de”为德语, “en”为英语,“it”为意语.默认为英语“en”
:param theta:阈值[0, 1],选择标注得分,阈值越大筛选出来的映射就越可靠,默认为0.1
:return:键值对[(A, B):score] A为文本当中的概念实体,B为维基概念实体,score为其得分
"""
annotations = tagme.annotate(txt, lang=language)
dic = dict()
for ann in annotations.get_annotations(theta):
# print(ann)
try:
A, B, score = str(ann).split(" -> ")[0], str(ann).split(" -> ")[1].split(" (score: ")[0], str(ann).split(" -> ")[1].split(" (score: ")[1].split(")")[0]
dic[(A, B)] = score
except:
logger.error('error annotation about ' + ann)
return dic
if __name__ == '__main__':
f = open("text.txt", "r", encoding="utf8")
txt = f.read()
obj = Annotation_mentions(txt)
for i in obj.keys():
print(i + " " + obj[i])
print("=" * 30)
obj = Annotate(txt, theta=0.2)
for i in obj.keys():
print(i[0] + " ---> " + i[1] + " " + obj[i])
pass
可以看见你的“Authorization Token”就放在上面代码的第13行引号内即可,上面的代码有两个函数,一个Annotation_mentions是可以发现那些文本当中可以是维基概念实体的概念,Annotate解决文本的概念实体与维基百科概念之间的映射问题,main函数里面要访问一个txt文件,把其文件和该python文件放在一个文件夹即可,txt文件编码为utf8,这是为了解决那些希腊文等单词。txt文件里面放着要分析的文本对象。
Tagme还可以计算概念之间的相似度,但是这个计算过程和通过gensim不同,Tagme主要计算维基概念之间的相似度,而gensim计算的是单个词语之间的相似度,Tagme依赖的是维基百科的数据库,而gensim数据来源多种多样,也可以是维基百科数据库。但是感觉gensim的数据库训练特别麻烦,我在本机上(8G内存,i7-6500U处理器)基本上要花1个月去训练维基百科数据,英文数据更难实现,因为内存不够,后来我是用导师的32G内存电脑完成的,有时间我会写一写详细训练过程。
代码附后:
# -*- coding:utf-8 -*-
# Author:Zhou Yang
# Time:2019/3/30
import tagme
import logging
import sys
import os.path
# 标注的“Authorization Token”,需要注册才有
tagme.GCUBE_TOKEN = "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx-xxxxxxxxx"
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
def similarity(A, B, flag=0):
if flag == 0:
rels = tagme.relatedness_title((A, B))
return rels.relatedness[0].rel
else:
rels = tagme.relatedness_wid((A, B))
return rels.relatedness[0].rel
if __name__ == '__main__':
A, B = "Machine learning", "Artificial neural network"
A_id, B_id = 21523, 233488
obj = similarity(A, B)
print(obj)
obj = similarity(A_id, B_id, flag=1)
print(obj)
- 实验
首先使用在发现这个工具的那篇论文当中的文本进行实验,选用Artificial Neural Network主题的文本。详细内容可以直接复制下面的文本。
An Artificial Neural Network (ANN) is an information processing paradigm that is inspired by the way biological nervous systems, such as the brain, process information. The key element of this paradigm is the novel structure of the information processing system. It is composed of a large number of highly interconnected processing elements (neurons) working in unison to solve specific problems.
准备好文本后可以直接运行我上面的第一个代码块,但是注意修改Authorization Token,这个号必须自己注册才有,结果如下:
"D:\电脑软件\PyCharm\PyCharm Community Edition 2018.1.4\Python37\python.exe" "D:/周洋的程序/Python程序/项目-中英文分词/tool/wiki/Annotation/annotation.py"
Artificial Neural Network 1.0
ANN 0.007354473229497671
paradigm 0.08858010917901993
by the way 0.066006600856781
biological 0.02709045633673668
nervous systems 0.03132530301809311
brain 0.09211649000644684
key 0.014657808467745781
element 0.01208556815981865
novel 0.056948427110910416
structure 0.008445064537227154
information processing system 0.41304346919059753
composed 0.0020965386647731066
number 0.0015523502370342612
elements 0.007023656740784645
neurons 0.14055821299552917
unison 0.2199999988079071
solve 0.0023882633540779352
specific 0.0011560780694708228
==============================
Artificial Neural Network ---> Artificial neural network 0.5
Neural Network ---> Artificial neural network 0.799559473991394
ANN ---> Artificial neural network 0.28824201226234436
information processing ---> Information processing 0.2720682621002197
biological ---> Magnesium 0.36336982250213623
nervous systems ---> Nervous system 0.3632960915565491
brain ---> Brain 0.327938973903656
process ---> Cognition 0.22103366255760193
information ---> Information 0.25470319390296936
information processing system ---> Information processor 0.20652173459529877
composed ---> Function composition 0.3199237585067749
number ---> Number 0.294927179813385
neurons ---> Neuron 0.2136688083410263
Process finished with exit code 0
虚线以上的部分就是Annotation_mentions函数的运行结果,左边就是文本当中出现的概念,右边的小数可以理解为该概念有多大的可能性是属于维基百科的概念,与文献当中的进行比较:

对比后感觉还不错,差别不是很大。
虚线下面的运行结果是函数Annotate的结果,左边部分当中的箭头左侧是原文本当中出现的原概念,箭头右侧是维基百科当中对应的概念,也就是将文本当中的概念和维基概念进行映射。最右边的小数也可以是认为之间映射的概率值有多大。和文献进行对比如下:
![]()
出现的概念基本上我们实验结果都有,这里需要特别说明的是代码设置的阈值为0.2,也就是概率值大于0.2的才会被筛选出来,这是根据你所需要的量情况来定。
最后找来一段网络上的真实文本进行测试,文本内容如下:
Apple abandons AirPower wireless charging product
Dave Lee
North America technology reporter
In a highly unusual step for the firm, Apple has given up on a product because it could not make it work adequately.
AirPower, announced in 2017, was a mat meant to charge multiple devices without needing to plug them in.
But it is understood the firm's engineers were perhaps unable to stop the mat from getting too hot.
"After much effort, we've concluded AirPower will not achieve our high standards and we have cancelled the project," the firm said.
The company did not elaborate further.
However, rumours of issues with the product had been circulating since its announcement in September 2017. At the time, Apple said it would be released to the public some time in 2018, promising a "world-class wireless charging solution".
But late last year, with the product absent from the most recent iPhone launch, noted Apple insider Jon Gruber wrote: "There are engineers who looked at AirPower's design and said it could never work, thermally, and now those same engineers have that 'told you so' smug look on their faces."
In a statement emailed to the BBC, Dan Riccio, Apple's head of hardware engineering, said: "We apologise to those customers who were looking forward to this launch. We continue to believe that the future is wireless and are committed to push the wireless experience forward."
The cancelled product could affect sales of the company's wireless headphones - AirPods - which were promoted and sold with the promise they would be charged using AirPower in future. Packaging for the AirPods contained a diagram of how AirPower would work.
Apple's rivals, such as Huawei and Samsung, have already released products that charge their devices wirelessly.
再次运行第一组代码,结果见下:
AirPower 0.044692736119031906
wireless charging 0.5
Dave Lee 0.31578946113586426
North America 0.30804112553596497
technology 0.023398298770189285
reporter 0.02981657162308693
step 0.004248012788593769
firm 0.00946947280317545
given up 0.006053550634533167
make it work 0.020179372280836105
mat 0.04156818985939026
charge 0.011948450468480587
devices 0.0019434246933087707
plug 0.05445897579193115
engineers 0.017148582264780998
stop 0.004503968637436628
getting 0.04302854835987091
too hot 0.024900399148464203
will 0.0036389119923114777
high standards 0.005692599806934595
standards 0.008279936388134956
cancelled 0.00203994894400239
project 0.0027154358103871346
company 0.008127721026539803
rumours 0.02806372568011284
issues 0.0018386875744909048
circulating 0.0015035081887617707
time 0.01014722604304552
public 0.01035712193697691
solution 0.04418136551976204
last year 0.009448818862438202
most recent 0.0010159160010516644
iPhone 0.6007529497146606
launch 0.01078066322952509
Apple insider 1.0
Jon 0.003474232740700245
Gruber 0.10210034996271133
who 0.003441077657043934
design 0.013331789523363113
thermally 0.005376344081014395
now 0.0018049159552901983
told you so 0.07246376574039459
smug 0.015094339847564697
faces 0.03423254191875458
statement 0.0032953915651887655
emailed 0.005708848591893911
BBC 0.432699054479599
Dan Riccio 1.0
Apple's 0.08801955729722977
hardware engineering 0.09756097197532654
customers 0.0024297982454299927
forward 0.10464910417795181
believe 0.008828372694551945
future 0.0059597305953502655
committed 0.0029403597582131624
push 0.013894888572394848
experience 0.003987394738942385
affect 0.006881630048155785
sales 0.007889042608439922
headphones 0.15149863064289093
promoted 0.0028574508614838123
promise 0.03003539703786373
charged 0.0041865818202495575
Packaging 0.044074952602386475
diagram 0.0340164490044117
rivals 0.025875970721244812
Huawei 0.9109311699867249
Samsung 0.46731290221214294
products 0.030476009473204613
wirelessly 0.008818342350423336
==============================
wireless charging ---> Inductive charging 0.25
North America ---> North America 0.24594174325466156
Apple ---> Apple Inc. 0.29451867938041687
devices ---> Electronics 0.22994622588157654
plug ---> Electrical connector 0.2197389453649521
firm ---> Business 0.20367252826690674
iPhone ---> IPhone 0.5015937089920044
launch ---> Nintendo DSi 0.2279624491930008
Apple insider ---> Apple community 0.5
Gruber ---> Franz Xaver Gruber 0.2661200761795044
BBC ---> BBC 0.31222760677337646
Dan Riccio ---> Dan Riccio 0.5755125284194946
Apple's ---> Apple Inc. 0.2375219762325287
wireless ---> Mobile phone 0.21009132266044617
wireless ---> Wireless 0.228031188249588
headphones ---> Headphones 0.2861405313014984
AirPower ---> Aerial warfare 0.21429812908172607
Huawei ---> Huawei 0.7033466100692749
Samsung ---> Samsung 0.42922958731651306
wirelessly ---> Wireless 0.20337079465389252
结果的表现还行,但是也有稍许错误,例如虚线下的概念“launch”在文章当中(But late last year, with the product absent from the most recent iPhone launch, noted Apple insider Jon Gruber wrote: )是发布、推出的含义但是Nintendo DSi,貌似感觉不符,可能是由于该文本只是一段新闻内容,不适合从维基百科当中提取比较学术的概念。但是基本上其余的映射概念还是正常的。
最后再来试一试利用Tagme计算维基概念相似度,使用概念“Machine learning”和概念“Artificial neural network”,运行第二组代码块,里面的两个函数代表既可以通过概念的标题来进行参数的传递,也可以通过其维基百科为其分配的id进行,id的获取可以见我的之前写的“通过Python获取维基百科中概念词条的维基信息”一文。结果见下:
"D:\电脑软件\PyCharm\PyCharm Community Edition 2018.1.4\Python37\python.exe" "D:/周洋的程序/Python程序/项目-中英文分词/tool/wiki/Similarity/similarity.py"
0.8110638856887817
0.8110638856887817
Process finished with exit code 0
感觉还很准,相似度0.8。
更多样例大家可以自己尝试去调用,提醒一下的是Annotate函数访问不同语言只需要修改language参数即可,但可惜的是该工具不支持中文,目前只支持三种语言,“de”为德语, “en”为英语,“it”为意语,默认为英语“en”。
本人初次接触技术博客领域,有什么不足的地方欢迎各位指正!
参考文献:
Gasparetti F, De Medio C, Limongelli C, et al. Prerequisites between learning objects: Automatic extraction based on a machine learning approach[J]. Telematics and Informatics, 2018, 35(3): 595-610.(要访问)