CiteSpace入门教程
本文最早发布在简书上,链接为:https://www.jianshu.com/p/c3139ee1cf1f,现转载来微信公众号,充实一下内容- -
在科研工作中,我们常常需要面对海量的文献,如何在这些文献当中找出值得精读、细读的关键文献,挖掘学科前沿,找到研究热点就成为了开展研究之前首先需要解决的问题。CiteSpace作为一款优秀的文献计量学软件,能够将文献之间的关系以科学知识图谱的方式可视化的展现在操作者面前,既能帮助我们梳理过去的研究轨迹,也能使得我们对未来的研究前景有一个大概的认识。
CiteSpace 又翻译为“引文空间”,是一款着眼于分析科学分析中蕴含的潜在知识,是在科学计量学、数据可视化背景下逐渐发展起来的引文可视化分析软件。由于是通过可视化的手段来呈现科学知识的结构、规律和分布情况,因此也将通过此类方法分析得到的可视化图形称为“科学知识图谱”。摘自 李杰.CiteSpace中文版指南
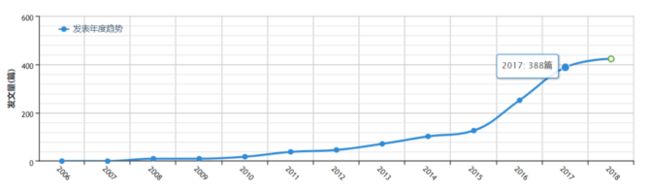
正如科学计量学界的权威专家刘则渊教授对CiteSpace知识图谱形态的概括一样,“一图展春秋,一览无余;一图胜万言,一目了然”。近年来,使用CiteSpace开展的研究、发表的论文呈现不断上升的趋势。根据中国知网的统计,2017年相关论文已经达到388篇;到2018年预测将达到423篇。
在如此多同质化的文章面前,我们应当如何做好自己的研究才能够不落入俗套,进而脱颖而出呢?我认为,在深入的把握CiteSpace的原理的基础上,熟稔相关操作背后的含义,对CiteSpace软件的应用达到游刃有余,这样才能知道自己的研究需要什么,做到“知己”。同时了解相关文章的研究套路,清晰他们的研究内容和研究思路,取其精华,规避其错误,做到“知彼”。下面根据我个人的一些学习的体会和实际使用的情况对CiteSpace使用过程来跟大家做一个基础性的介绍。
一、CiteSpace的下载与界面介绍
访问http://cluster.ischool.drexel.edu/~cchen/citespace/download/下载CiteSpace,一般下载最新版。当前(2018年10月14日)最新版为5.3.R4,新版本在原来版本的基础上增加了引文级联引用功能。
使用CiteSpace需要先安装JAVA 8,安装教程参考jdk 8下载和安装步骤
下载完成后解压,打开StartCiteSpace_Windows.bat。一般选择英文。
进入下一个界面,提醒使用者在使用这个软件开展研究的发表论文的时候,别忘了把软件开发者的论文引用上,不同意就用不了,那我们当然选择同意。

CiteSpace的功能区域很质朴,分为执行操作区、时间选择区、文本处理功能区和网络配置功能区等。在随后的论述中,再对这些功能区进行逐一展开。

二、CiteSpace的数据来源与下载:分析的原料在哪里
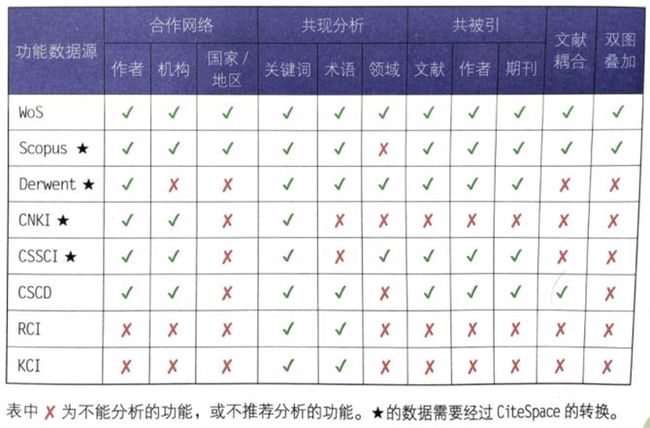
使用CiteSpace分析某一主题的研究历史与研究前沿,第一步就是要从文献数据库上下载到一定数量的文献信息。外文文献信息一般在web of science(WoS)上下载得到,中文文献信息一般在中国知网(CNKI)上下载。CiteSpace是基于WoS的数据格式进行开发的,可以根据下载得到的数据进行合作网络分析、共现分析和共被引分析,在非WoS数据库下载得到的数据都需要先转化为WoS的数据格式,根据相应数据库的数据维度各有其相对应的适用范围。就数据库的深度看,外文数据库我们一般使用WoS,中文数据库一般使用CNKI。
另外,中文的文献数据库还有CSSCI数据库、CSCD数据库等,外文的文献数据库还包括Scopus数据库、Derwent专利数据和其他专业领域的数据库等,下载方法参考《CiteSpace:科技文本挖掘及可视化》第2讲。
在数据检索时,一般有两种检索策略,分别是:
按照关键词检索
按照期刊检索
我们以按照关键词检索为例,说明如何从文献数据库中,下载得到我们所需要的文献数据。
1、在WoS上下载数据
在WoS上下载数据,访问WoS的官网http://apps.webofknowledge.com。操作的第一步是登录,假如没有账号,需要先行注册一个。没有登录的话,是无法下载数据的。

以关键词“学习成果评价”为例,键入其英文“learning outcome assessment”,数据库选择“Web of Science核心合集”,检索类型选择“主题”,时间跨度选择“所有年份”。我所在的学校购买到的数据库是从1985年开始的,时间跨度可能对有些朋友而言不够长。当前国内购买WoS数据库跨度最长的地方是中科院文献情报中心,是从20世纪初期就开始的,有需要的朋友可以到那里进行数据下载。

得到如下页面。从页面中可以看出,该主题词下的索引结果有10054条。下一步,需要对检索结果进行精炼。

文献类型选择“文章”,点击精炼。得到的最终检索结果为7050条,这些文献数据是我们最终想要的。
随后,滑到底部,将记录改成每页显示50条。
回到顶部,按照下图步骤,分别点击“选择页面”,“添加到标记结果列表”,就完成了这一页面的数据添加。最后点击“下一页”,循环这个过程。WoS最多支持500条数据保存一次。

在标记完500条数据后,选择“保存为其他文件格式”。
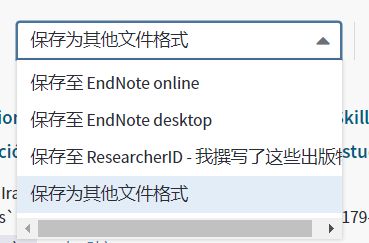
随后,记录内容选择“全纪录与引用的参考文献”,文件格式选择“纯文本”,点击“发送”,就可以得到刚才我们标记过的500条文献信息了。

下载得到的内容包括论文标题、作者、资助基金、关键词、来源期刊、所属领域、论文摘要、参考文献等等。对余下文献信息做相同的操作,即可以得到所需要的数据全集。
Tips:
关键词的翻译,例如“学习成果评价”,找出几篇以“学习成果评价”为关键词的引用率较高的文献,中外比较类(例如比较教育学)的研究最好。参考其下的英文对照翻译,综合选择即可以得到我们需要的英文关键词。
查看相关数据时,最好时候Notepad++、sublimetext等编辑器。格式更加醒目、清晰。
2、在CNKI上下载数据
在CNKI上,同理,访问www.cnki.net,键入检索词“学习成果评价”,每页显示选择“50”,勾选“全部选中”按钮,点击到下一页,同样以500条数据为一次下载。

在选择完毕后,点击“导出/参考文献”。
选择Refworks,点击“导出”,就完成了本次下载。

得到的数据维度比WoS得到的数据维度要少一下,仅包括作者、标题、来源期刊、关键词、摘要等。对余下数据做同样的操作,就可以得到中文的数据集。

在得到数据集后,需要将这些数据集转化为CiteSpace可以识别、读取的数据格式。参考如下tips即可完成转换。
Tips:
CiteSpace自带有数据转换的功能,但不太好用,容易出现一些问题。推荐下载使用格式转换器。转换器下载链接
转换后会将原本集合在一个txt文件中的数据打散,生成一条数据一个txt的形式,txt文件过多会极大的降低了CiteSpace的运算速度。为了解决这个问题,打开命令行工具(cmd),输入下面的代码,将这些TXT合并成一个。 引自:将多个txt文件合并成一个
二、CiteSpace的分析原理:我们如何挖掘现有数据
在获取特定主题的数据后,自然而言我们会冒出一个问题:“我们拿这些数据用来做什么?”CiteSpace的最大的作用,就是能够在这些枯燥乏味、机械重复的数据中挖掘出我们想要的东西。那么,这是依靠什么原理实现的呢?
1、共被引分析
在了解共被引分析前我们需要对引文分析有个概念,引文就是论文后面的参考文献。有学者认为,引文分析就是对科学期刊、论文、作者等分析对象的引用和被引用现象进行分析,以揭示其数量特征和内在规律的一种信息计量研究方法。在了解引文分析法之前我们首先要知道,学者为什么要在其论文中印证前人的研究成果。
为什么要引证:
为了对先驱者表示崇敬。
为了对相关工作表示赞赏,同时表示对同行的尊敬。
为了对方法或仪器设备表示认同。
为了向读者提供阅读背景。
为了纠正自己的工作。
为了纠正别人的工作。
为了批评前人的工作。
为了支持某种论断。
为了提醒人们注意即将发表的工作。
为了找到那些传播不广、索引很差又未被引证的文献而提供线索。
为了验证科学事实和数据,例如援引物理常数等。
为了鉴别曾讨论过某个思想或概念的原始文献。
为了鉴别某个时代的某个概念或术语的原始文献或其他著作。
为了对别人的工作或思想提出反证-否定性论断。
为了与别人论争某个观点的优先权。
引自:引证论文的理由
从上面这么多引用原因我们不难看出,被引文献与当前文献在内容上是相关的。论文引用其他论文的行为可以看做是知识从不同的研究主题流动到当前所进行的研究,是知识单元从游离状态到重组产生新知识的过程。发表的论文被其他论文引用是这个过程的持续。由于这种引证行为的客观存在,随着科学研究的不断推进,引文网络也就自然而然的形成了。一篇特定的论文,引用的文献称为引用文献(即后向引证关系),这篇论文发表后,引用这篇文章的论文称为施引文献(前向引证关系)。在引证网络的基础上,延伸出两个重要的概念,一个是共被引分析,另一个是耦合分析。共被引分析挖掘参考文献之间的关系,耦合分析挖掘施引文献之间的关系,这里着重讲共被引分析。
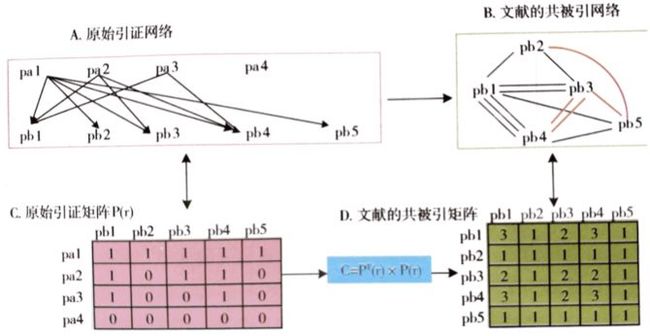
共被引分析(Co-Citation analysis)是指两篇文献共同出现在第三篇施引文献的参考文献目录中,则这两篇文献形成共被引关系。通过对一个引文网络进行文献共被引关系挖掘的过程,就可以认为是文献共被引分析的过程。例如下图文献pb1和文献pb4在三篇论文中共同引用,那么他们的共被引次数为3次,通过一定的计算方式可以得到他们的关联强度。共被引次数越多,这说明这两篇文献相似之处越大,关联强度也越大。分析的步骤为:先从文献信息中归纳得到引证矩阵,在引证矩阵的基础上生成共被引矩阵。使用可视化技术,将共被引矩阵可视化为网络。
2、共词分析
在进行共词分析之前,首先需要先了解词频分析。词频是指所分析的文档中词语出现的次数。词频分析就是在文献信息中提取能够表达文献核心内容的关键词和主题词频次高地分布,来研究该领域发展动向和研究热点的方法。
在词频分析的基础上,对词频网络进行的更高层次的分析称为共词分析。共词分析的基本原理是对一组词两两统计它们在同一组文献中出现的次数,通过这种共现次数来测度他们之间的亲疏关系。它需要满足以下几个方面的假设。
共词分析的假设前提:
作者都是很认真的选择他们的技术术语的;
当在同一篇文章中使用不同的术语时,就意味着这些不同的术语之间的关系并不是微不足道,它们一定是被作者认可和认同的;
如果有足够多的作者对同一种关系认可,那么可以认为这种关系在他们所关注的科学领域中具有一定意义;
当针对关键词时,经过专业学习的学者,在其论文中标引出来的关键词时能够反映文章的内容的,是值得信赖的指标。在作者标引关键词时,通常也会受到其他学者成果的影响而在论文中使用相同或类似的关键词标引自己的论文。
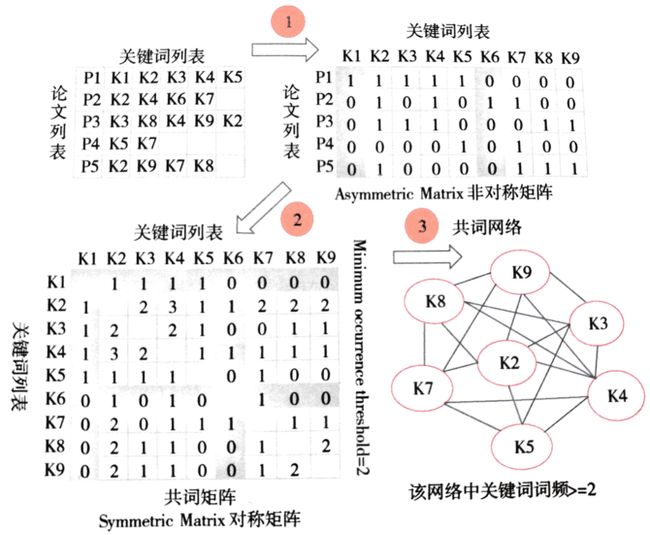
分析的步骤与共被引分析相近:先从文献信息中归纳得到关键词矩阵,在关键矩阵的基础上生成共词矩阵。使用可视化技术,将共词矩阵可视化为网络。
3、突现分析
CiteSpace提供Burst detection的功能来探测在某一时段引用量有较大变化的情况。用以发现某一个主题词、关键词衰落或者兴起的情况。
参考文章 CiteSpace中的Burst Detection
4、聚类分析
聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程,以分析对象的相似性为基础。聚类分析有许多不同的算法,CiteSpace提供的算法有3个,3个算法的名称分别是:LSI浅语义索引、LLR对数极大似然率、互信息。对不同的数据,3种算法表现一样,可在实践中多做实践。
关于这3种算法,可以参考如下文章做进一步了解:
LSI浅语义索引 文本主题模型之潜在语义索引(LSI)
LLR对数极大似然率 Likelihood ratio test
互信息 互信息(Mutual Information
5、CiteSpace其他功能区
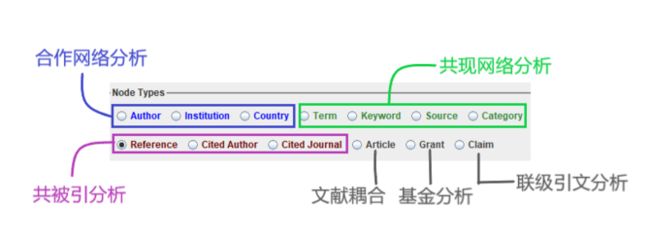
对于共被引分析,CiteSpace提供了引文共被引、作者共被引和期刊共被引3种不同类型的分析方法。对于共现分析,CiteSpace提供了术语、关键词、来源、领域4种不同的共现分析。
无论是共被引分析还是共现分析,在生成网络时都需要根据共被引次数或共现次数计算网络节点之间的连接强度。CiteSpace提供了4种网络节点强度计算的方法,一般不做改动,选择默认方法。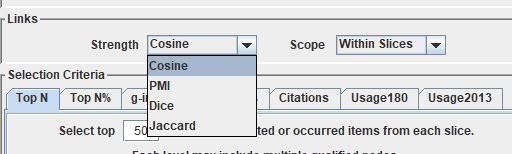
三、CiteSpace挖掘的三个方面:知识基础、学科结构、研究前沿
CiteSpace能够在海量的文献数据中,能够以较为简单的操作步骤挖掘出我们所需要的特定主题的三个方面的信息,包括该研究主题的知识基础、相应的学科结构和最新的研究前沿。在进行进一步的论述之前,我们先来简单介绍CiteSpace这个软件的操作步骤。
1、知识基础的获取
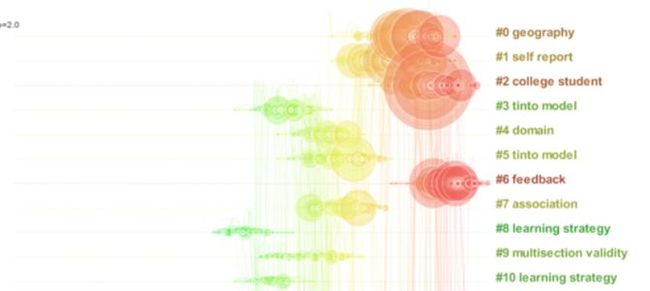
任何一个研究主题,背后都会有一个较为完整的知识体系作为支撑。这个研究主题越成熟,这个知识体系越完整,越丰富。我们知道共被引网络是由参考文献组成的网络。我们获取的这一主题的论文,其知识构成在很大程度上是由其参考文献的知识流动汇集得来的。那么由参考文献组成的共被引网络则能够很好的揭示某一个研究主题的“先验知识”,即我们可以通过获取参考文献的共被引网络的方式,得到某一研究主题的知识基础。以关键词“高等教育”为检索对象,得到2.5万余条数据,得到的共被引网络如下:
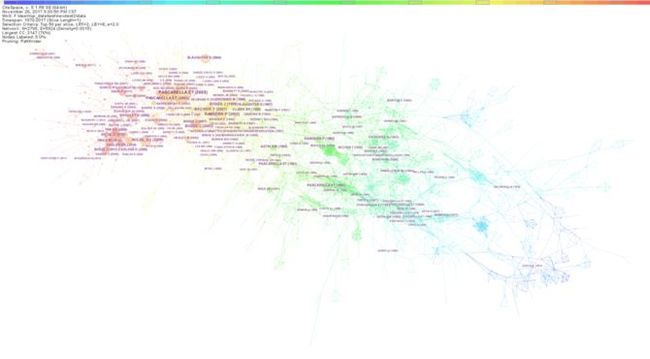
颜色的冷暖代表了时间的远近,颜色越暖,时间越近;颜色越冷,时代越久远。那么通过对网络进行分析,对其中关键节点(即关键文献)进行研究,就可以知道,支撑支撑高等教育发展的知识基础在时间上的发展演进情况。那么我们需要研究哪一个阶段的高等教育历史,就得找到相应时段高等教育知识基础的书籍进行研读、浏览和整理。
对这个结果网络进行聚类分析,可以看到各个阶段知识基础的主题的变化情况,方便我们进行主题聚焦。可以看到,在最近的研究中,知识基础为“反馈”类的文献,此时研究也许会以这个为出发点展开研究。
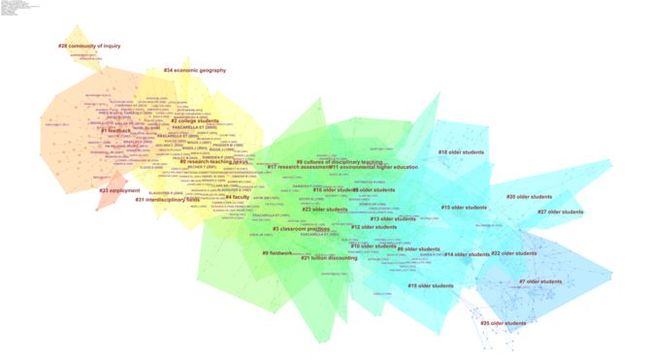
在了解整体的知识基础的框架和演进趋势后,我们如何对关键文献进行定位?我们主要关注2个方面:
高频节点:代表高被引的文献,是某个领域或多个领域的重要知识基础。
高中介中心性节点:代表与多篇文献形成共被引关系的文献,与多篇文献均有关系,起到“交通枢纽”的作用。相对而言,是本领域内的关键文献;同时,也是这段时期内的关键文献,在一定程度上代表着这段时期的研究热点主题。
中介中心性是指:一个结点担任其它两个结点之间最短路的桥梁的次数。一个结点充当“中介”的次数越高,它的中介中心度就越大。引自:度中心性(degree)、接近中心性(closeness)和中介中心性(betweenness)的理解
那么我们可以知道,同时具备高中介中心性和高频特性的节点,就是本领域内的关键文献,也是这段时期内的关键文献,代表着这段时期的研究热点主题。
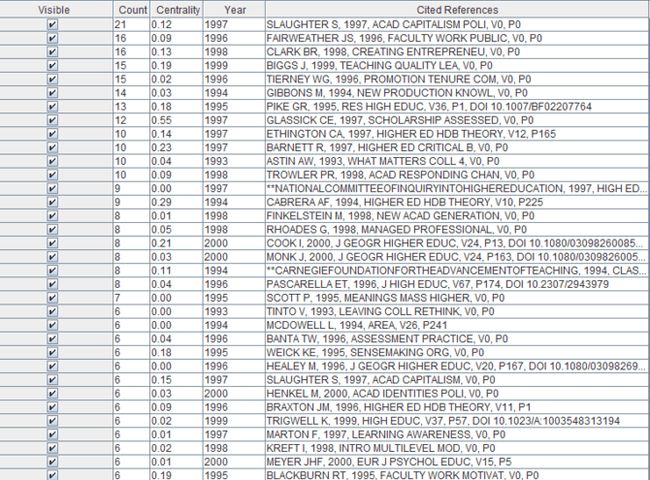
如何根据文献简略信息得到文献完整信息?
参考博文CiteSpace的介绍与使用的“根据报告分析出的文献”部分。
2、学科结构的获取
一篇论文的关键词代表着这篇论文的论述重点,在一定程度上反映了这篇论文的学科结构。使用关键词共现网络,能够将数据全集中的学科结构清晰的展示出来。每一个节点代表一篇文献,节点越大,说明该关键词词频越大,与主题的相关性越大。同样,节点的颜色代表时间:颜色越暖,时间越近;颜色越冷,时代越久远。

3、研究前沿的获取
使用前面提到的burst detection,可以获取到相关研究主题的研究前沿。在获取研究前沿前,需要先点击Noun Phrases,选择Create POS Tags。

然后把Burst Terms选中,点击detect Bursts。

在弹出框中选择noun phrases。

在知识图谱的界面,旁边有个Control Panel,点击Burstness,点击Refresh,就可以生成我们所需要的关键词图片图。

