吴恩达深度学习第一课 — 神经网络与深度学习1.2
cal构建神经网络
· 2.1 二分分类 (Binary Classification)
计算机保存一张图片,要保存三个独立矩阵:红,绿,蓝(其他颜色都是由这三原色组合形成),如果保存的图片是 64x64的,那每个矩阵也是64x64的。且每个矩阵里的元素值,代表着颜色的强度。把像素值取出放入一个特征向量x(三个矩阵元素变成一列向量), 且特征向量的维度是64x64x3=12288(三个矩阵元素总数量)。

在二分分类问题中,目标是训练出一个分类器,以图片的特征向量x作为输入 ,预测输出的结果标签y 是1还是0(是否有猫)
★常用符号
一对(x,y)表示一个单独的样本,x是nx的特征向量,y是标签值为0或1
训练集由m个训练样本构成
(x^(1),y^(1))表示样本一的输入和输出.......(x^(2),y^(2))样本二
m表示训练样本的个数 m下标train训练集样本数 m下标test测试集样本数

计算机就是通过不断地通过训练集的输入,可以得出输出的答案,列如输入一张猫的图案,计算机能够立即识别出来。
· 2.2 Logistic Regression回归
一个学习算法,用在监督学习问题中,输出y标签是0或1时

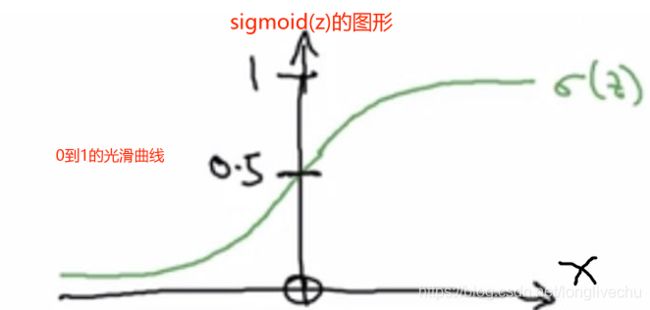
 · 2.3 Logistic Regression cost function (logistic回归成本函数)
· 2.3 Logistic Regression cost function (logistic回归成本函数)
损失函数loss是在单个训练样本中定义的,它衡量了在单个训练样本上的表现

-
2.4 Gradient Descent 梯度下降法

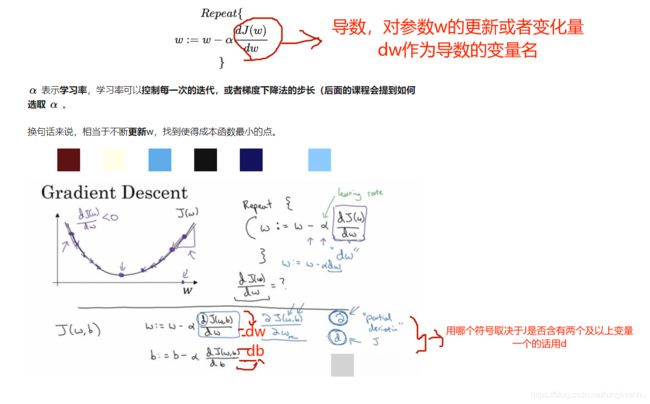
-
2.5 derivative 导数
-
2.6 更多导数的例子
-
2.7 计算图
-
2.8 计算图的导数计算
-
2.9 logistic回归中的梯度下降法
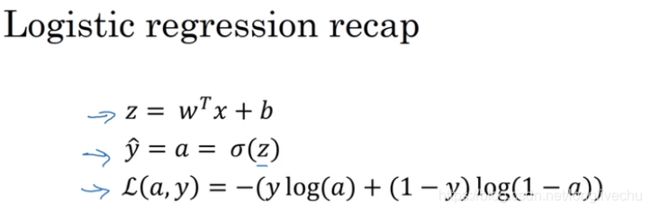 (a是logistic回归的输出,y是样本的基本真值标签值)
(a是logistic回归的输出,y是样本的基本真值标签值)

这是正向的计算损失函数的过程,接下来在此写明了关于怎样向后计算偏导数。


-
2.10 m个样本的梯度下降
在2.9我们把梯度下降法应用到logistic回归的一个训练样本上。现在我们想要把它应用到m个训练样本上。
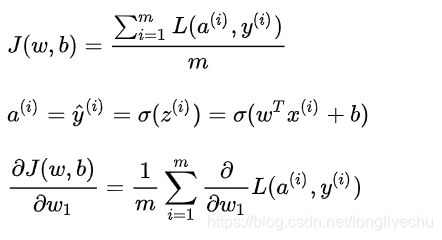

★一个for循环,遍历所有n个特征,当你应用深度学习算法,你会发现在代码中显式地使用for循环,会使算法很低效。
尽量不要写for循环,这会拖慢程序速度,先在数学上优化。
· 2.11 向量化 vectorization
在训练大的数据集时,深度学习算法表现才更加优越,所以你的代码运行得非常快非常重要,否则,如果它运行在一个大的数据集上面,你的代码可能花费很长时间去运行,因此向量化非常重要
什么是向量化?
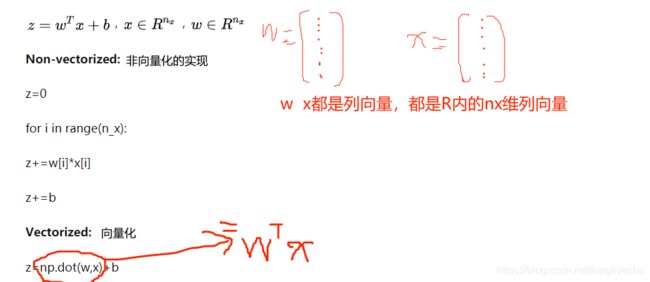

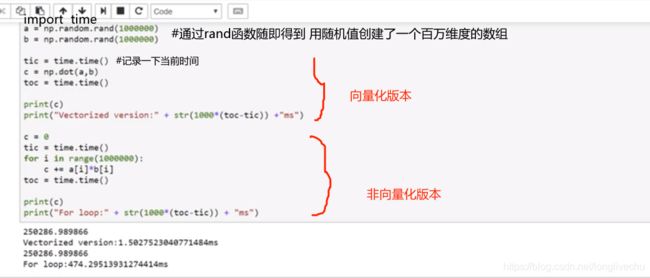 ★用向量的运算比用for循环提高300倍的速度!!
★用向量的运算比用for循环提高300倍的速度!!
-
2.12 向量化的更多例子
★使用内置函数,尽量避免for循环



-
2.13 向量化logistic回归


这节介绍了如何使用向量化高效计算激活函数,同时输出所有a,下一节会介绍如何用向量化来高效地计算反向传播,从而计算梯度。
-
2.14 向量化logistic回归的梯度输出
向量化计算m个训练数据的梯度(同时计算)
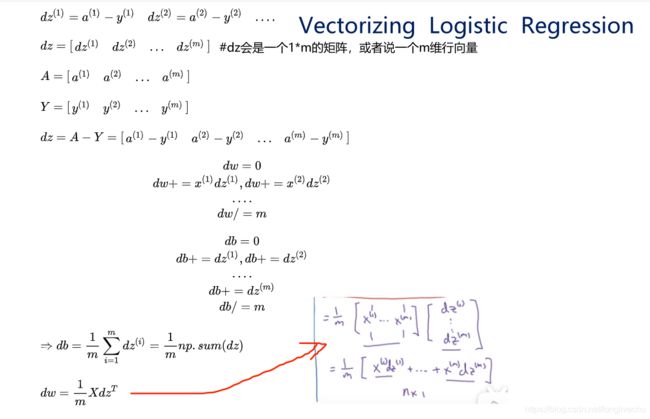
下面是没有向量化的过程,非常低效

我们现在要做的是去掉整个for循环,提升算法的效率。

尽管老师说尽量不用for循环,但是如果你想要多次迭代进行梯度下降,那么你仍然需要for循环

-
2.15 Python中的广播

计算四种食物中 卡路里有多少百分比来自碳水化合物、蛋白质和脂肪
e.g苹果 一竖列加起来59cal 其中来自碳水化合物的为56/59=94.9%
将上边表看成一个3*4的矩阵


注:axis=0意味着我希望python在竖直方向求和,axis=1意味着我希望水平求和。
reshape在这里其实不需要的,因为cal本身就是1乘4的矩阵,但是当编写python代码时,如果不完全确定是什么矩阵,为了保证矩阵计算的准确性,don't be shy to use reshape!!!,


-
2.16 关于python_numpy向量的说明
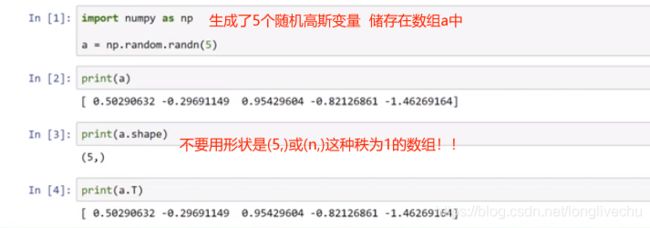
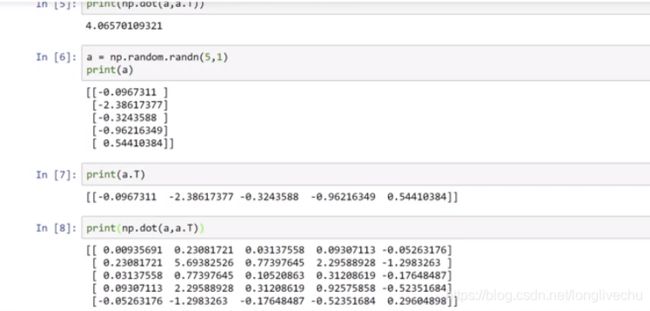
In【6】表示 a是一个5*1的矩阵

这里又推荐使用reshape命令对数组设订所需的维度。DON'T BE SHAY TO USE RESHAPE!
-
2.18(选修)logistic损失函数的解释
