独家 | 感悟注意力机制

作者:Greg Mehdiyev, Ray Hong, Jinghan Yu, Brendan Artley翻译:陈之炎校对:ZRX
本文约2800字,建议阅读12分钟
本文由Simon Fraser大学计算机科学专业硕士生撰写并维护,同时这也是他们课程学分的一部分。
本博由Simon Fraser大学计算机科学专业硕士生撰写并维护,同时这也是他们课程学分的一部分。
想了解更多关于该项目的信息,请访问:
sfu.ca/computing/mpcs
简介
看到这张照片时,首先映入眼帘的是什么?相信大多数人的眼神会被蓝色小鸭子吸引。对人类而言,显然这只蓝色小鸭子在图片中异常突出。不知何故,人类总是具备发现特定模式的能力,并会将注意力转移到那些与众不同的特征之上。
为什么会是这样子的?究竟是什么让我们注意到“蓝色鸭子“呢?
如果仔细观察这张照片,还会看到有其他不同特征的鸭子。例如,其中有三只鸭子面朝侧面而非正面向前。

是什么让蓝色鸭子比侧向鸭子更突出?是否能教会电脑学习这一特征呢?
这正是注意力机制解决的目标问题。“注意力机制是一种尝试行为,旨在有选择性地聚焦某些相关的事物,同时忽略深度神经网络中的其他事物。”⁷
从一般意义上说,注意力机制是对编码-解码器结构的改进。编码器-解码器模型利用神经网络将输入的编码特征转换成另一种编码特征。注意机力制组件赋予了神经网络在编码数据时对特定特征赋予 “注意力”的能力,它有助于解决神经网络中经常发生的梯度消失/爆炸问题。

编码器-解码器GIF 结构图
对注意力机制的实现可概述如下:
1. 为编码器中的每个状态分配一个分值: 对输入序列进行编码之后,称这部分编码为内部状态,可以为包含“注意力”的状态分配高的分值,为不包含任何相关信息的状态分配低分值,从而达到识别相关编码器状态的目的。
2. 计算注意力的权重: 在第一步得出的分值基础上计算出注意力权重。
3. 计算语境向量: 语境向量为包含第1步和第2步中信息的聚合向量。
4. 前馈: 将从语境向量中收集到的信息输入到编码器/解码器层中。
5. 解码: 解码器利用注意力机制解码信息。
这便是注意力机制的工作原理,接下来深入研究一些真实的应用程序!
常见用例
1. 自然语言处理(NLP)
自然语言处理是机器学习的一个子集,它赋予了计算机解释人类语言的能力,诸如翻译软件、聊天机器人和虚拟助手等工具均来自于这一研究领域。与自然语言处理相关的主要挑战之一是将句子中每个单词的上下文翻译为计算机所能理解的格式。
通常,使用编码器和解码器形式的两个RNNs/LSTMs来完成语境信息的翻译。编码器利用特征表示提炼出句子信息,解码器再将特征表示转换为摘要。
这种方法对短句子很有效,但是,由于存在梯度消失/爆炸的问题,对长句子来说就变得不那么准确了。如果没有注意力机制,对于复杂的人类语言来说,该方法的有效性便不太可靠了。例如,来看下面的句子。

例句
可以比较未包含注意力机制的模型与包含有注意力机制的模型来验证它的有效性。通过可视化文本,为更加 “重要”的单词赋予一个更深颜色的文本。可以看到,如果没有注意力机制组件,模型会受到梯度爆炸/消失的影响,无法在早期找到单词,从而遗漏了句子中那些对整体意义提供重要信息的那部分文本。

未包含注意力机制
这便是注意力机制的价值所在。在创建语境向量时,无论句子有多长,它均能够考虑到整个句子,为句子中的每个单词赋予重要程度,并将模型的“注意力”集中在句子中最重要的单词上。该模型的注意力可表示如下。

包含注意力机制
2. 计算机视觉
机器学习中受益于注意力机制的另一个领域是计算机视觉,该领域专注于实现人类视觉系统的自动化。目前,计算机视觉的应用包括目标检测、图像分类和图像字幕。

计算机视觉图像
图像字幕可自动生成图像的文本描述,该描述以清晰的格式准确地表达出图像中的内容。下面,来深入了解一下在模型架构中加入注意力机制的好处。
首先,在没有注意力机制的情况下实现图像字幕,模型生成一个文本表示,如“一群黄色橡胶鸭”。由于模型是基于整个图像进行的概括,这已经相当准确了。话虽如此,即便是图像中的一个明显的焦点,但结果中并没有提及蓝色鸭子。由于图像的每个区域都赋予同等的重要性,并没有将蓝鸭子描述出来。

未包含注意力机制
再来考虑一下使用了注意力机制的情况,这时,模型赋予了包含蓝鸭子图像区域更高的重要性,在生成图像描述时,将这些信息的描述考虑进来。

包含注意力机制
生成的描述将类似于“一群黄色橡皮鸭中的一只蓝色橡皮鸭”。注意,描述中的主题是“蓝色鸭子”。随着注意力机制对这一区域图像的重视,得出了更为准确的文本描述。
在讨论了注意力机制的常见用例之后,再来看看底层的数学。
数学
多年来,注意力机制出现了很多变种。其中最著名的三个版本是Vaswani ³注意力机制,Bahdanau ²注意力机制和Luong ¹¹注意力机制。在本文中,将重点关注Vaswani注意力机制和Bahdanau注意力机制。
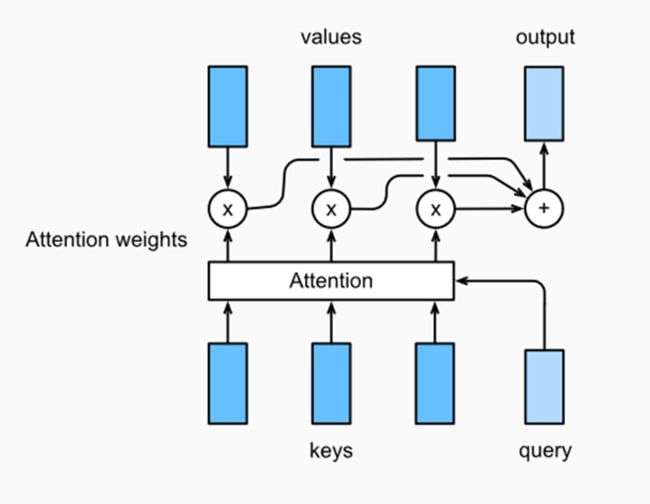
注意力层
注意力机制背后的思想是将一个query值和一组 key-value对映射到一个输出当中。
1. Key / Value / Query
“key/value/query的概念类似于检索系统。例如,当在Youtube上搜索视频时,搜索引擎会将 query (搜索栏中的文本)映射到一组keys (视频标题、描述等)上,与数据库中的候选视频相关联,然后展示最匹配的视频(values)。”⁵
Key向量、Query向量和Value向量是嵌入向量在不同子空间中的抽象,因此可以通过将嵌入E乘以一个权矩阵来得到向量,“嵌入(向量)是一个相对低维的空间,可以将其转换为高维向量“⁶
2. 输出
输出是权重和values的组合,其中权重是在query和key的点积的基础上,应用softmax函数获得的。
Vaswani注意力机制
Vaswani注意力机制中,key向量、query向量和value向量是编码器-解码器层的输入,key向量和query向量的长度可以用变量d来表示,当输入由长度为d的key向量和query向量组成时,则计算出所有key向量和query向量的点积。
然后将每个结果除以d的平方根。最后,应用softmax函数得出其值的权重。
假设有一个有四字单词的句子(s1,s2, s3,s4),要想计算s4的注意力,s4依赖于s3,s3依赖于s2等等。首先,将s3的query向量命名为q3,将s1, s2, s3的key向量命名为k1, k2, k3。为了计算出权值,需要计算query向量q3与所有key向量的点积,将其除以d的平方根。然后,应用softmax函数。结果得出以下三个权重,称之为(w1,w2,w3)。

假设s1、s2、s3的值是(v1、v2、v3),那么s4的语境向量则是(w1、w2、w3)和(v1、v2、v3)的点积。
![]()
点积图
接下来,需要计算一组query向量的注意力,将key向量、query向量和value向量打包成矩阵Q、K、V。通过将嵌入向量的组合矩阵乘以权重矩阵Wq、Wk、Wv来得到key、query和value矩阵。这里给出了以下形式的注意力矩阵,可以将这一注意力矩阵应用到机器学习模型(如:Seq2Seq、图像字幕、BERT等等)中去。
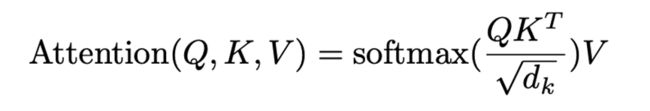
注意力矩阵公式
Bahdanau注意力机制
Bahdanau注意力机制又可称为加性注意力机制。Bahdanau注意力机制和Vaswani注意力机制之间的主要区别是:Bahdanau注意力机制使用了一种加法策略,而Vaswani注意力机制使用的是一种乘法策略,二者的实现方式采用了各自不同的缩放因子。
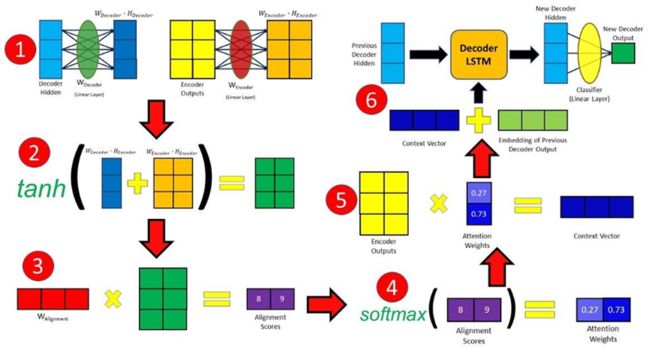
Bahdanau 注意力机制
可以将Bahdanau注意力机制划分为以下步骤:首先,将上一个时间步长中的解码器隐含态与编码器隐含态(输入句子中的每个元素对应一个隐含态)相组合,生成对齐分值。类似于Vaswani注意力机制中的sqrt(d),Bahdanau注意力机制采用Tanh作为缩放因子,可以用下面的公式来表示:
![]()
Bahdanau 分值公式
然后,使用softmax函数将分值归一化成权重值,将权重值乘以隐含的编码器状态,得到语境向量。最后,将语境向量和前一个解码器的输出连接起来,生成一个新的输出。每个时间步长均重复上述过程。
该注意力机制的详细实现过程将在“代码”小节中做详细描述。
附加信息
1. 什么是Seq2Seq?
序列到序列的学习模型将句子从一个维度转换成另一维度,在语言翻译时,便是将句子从一种语言翻译成另一种语言。
2. 为什么要softmax?
softmax函数取n个实数的输入向量v1,并将其归一化为包含n个分量的概率分布。每个输出分量在(0,1)范围内,各向量分量的和加起来为1。利用softmax函数,可以为每个分量生成概率分布函数,从而影响解码器输出的概率。最后,将语境向量与之前的解码器输出连接,输入到解码器RNN单元中去,以生成新的隐含态。
3. 为什么要缩放?
如果d的维数很大,点积的大小就会很大,Softmax函数会使得梯度变得很小,通过对点积进行缩放来减少这种影响。Bahdanau 注意力机制用Tanh实现缩放,Vaswani 注意力机制用1/sqrt(d)实现缩放。
代码
在下一节中,将Bahdanau注意力机制应用于序列任务,利用Keras实现一个编码器-解码器架构,可以从Google Colab Notebook.上下载该例子的完整代码。
文中的代码对“注意力机制文章⁹”中的第三方实现代码进行了修改和优化。与“注意力机制文章⁹”不同,这里利用注意力机制来设计一个系统,将给定的英语句子翻译成法语。
下面是模型的输入示例和预测输出序列示例。
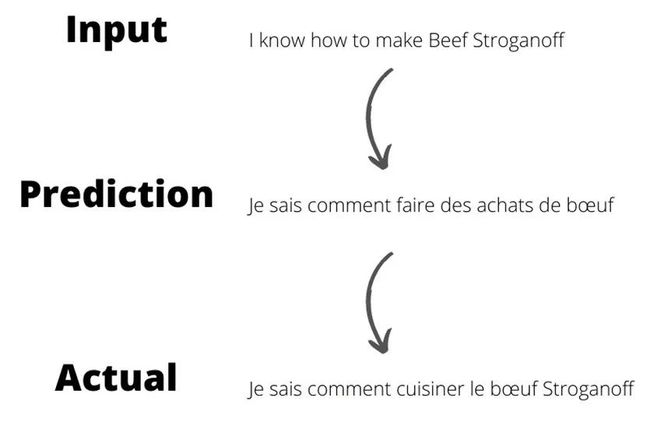
预测示例
导入包
1. 首先使用下面的代码导入所需的python包。
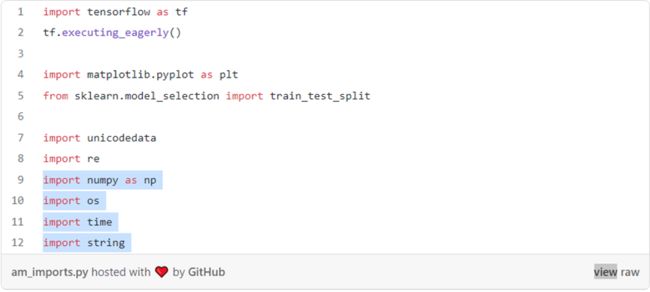
LanguageIndex类
2. 接下来,创建一个执行索引映射的语言索引类(LanguageIndex类)。目的是存储字典中的所有单词,并能够引用它们的索引。这个类还存储了每种语言的最长句的长度。

文本清洗
3. 接下来,创建一些辅助函数来生成编解码的数据序列,辅助函数为执行特征工程而设。辅助函数删除所有的标点符号、空格和不常见的字符,实现句子清洗,它把每个句子转换成一个向量列表,每个向量表示一个句子中的各单词的索引。
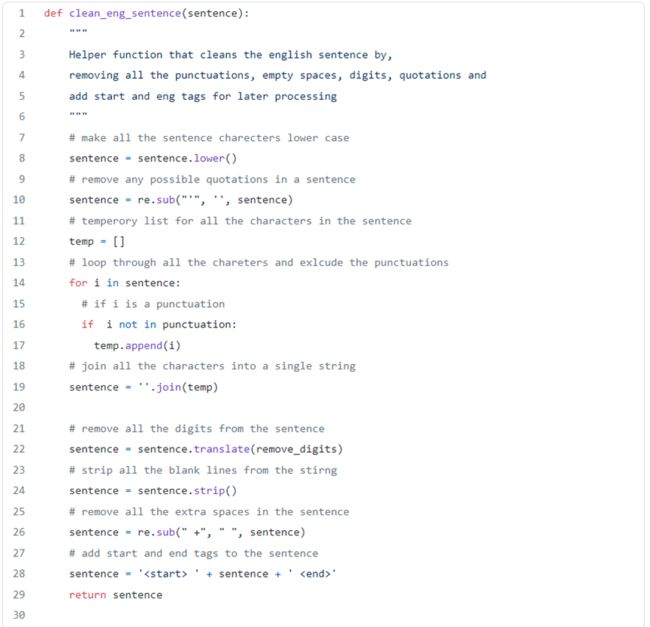
加载数据集+损失函数
4. 接下来,定义数据转换函数,并将其加载到数据集中。该部分代码段中还包括了损失函数。
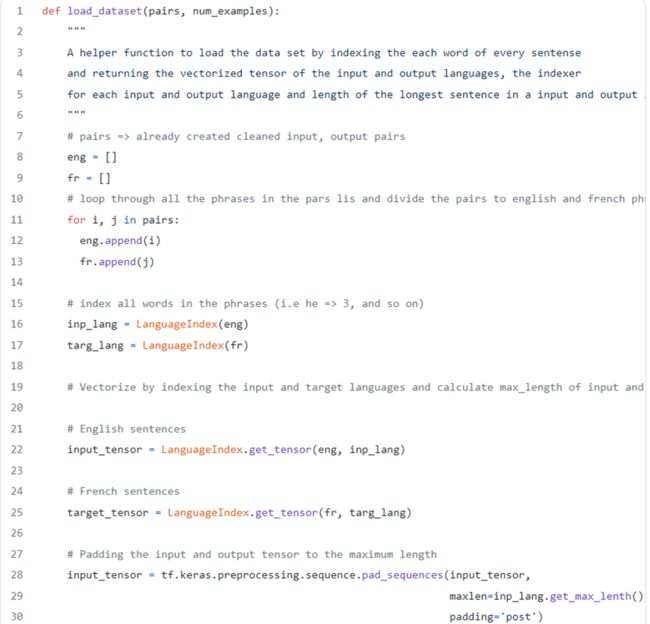
创建数据集
5. 把上述内容归集起来。清理输入数据、向量化输入和输出语言的张量、计算输入和输出句子的最大长度,并添加必要的填充。这些操作通过下述代码来实现。

编码器+解码器
1. 编码器
编码器负责步进输入序列的时间步长,并将整个序列编码成一个固定长度的向量,即语境向量。
2. 解码器
解码器负责读取语境向量,步进输出时间步长。
在下个单元中,将定义编码器和解码器架构。默认情况下,编码器和解码器配置在CPU上运行。然而,模型在基于CUDA的GPU上运行要快得多。如果在GPU上进行训练,应将第 7行至 27行代码替换为:


3. 创建模型、数据并进行训练!
最后,序列到序列翻译模型的所有片段均准备好之后,只需运行以下代码段,实例化数据集并开始训练模型。
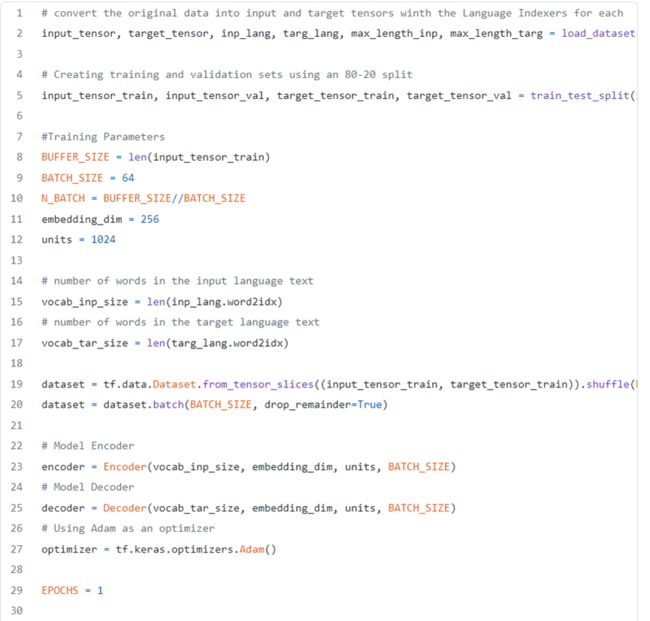
结语
引入注意力机之后制,离使用机器学习模仿人类观察又进了一步。
可以免费从 Google Colab Notebook上下载源代码。如果想了解更多关于注意力机制的信息,请查看下述资源。
参考文献
[1] 利用BERT语言模型从文本中获取语义(2020年9月1日)
https://www.youtube.com/watch?v=-9vVhYEXeyQ&t=145s
[2] 利用联合学习对齐和翻译实现神经机器翻译(2016年5月19日) https://arxiv.org/abs/1409.0473
[3] 你需要的就是注意力(2017年12月6日) https://arxiv.org/abs/1706.03762
[4] 展示、出席和讲述:带有视觉注意力的神经图像标题生成(2016年4月19日)https://arxiv.org/abs/1502.03044
[5]注意力机制中的keys、queries和values到底是什么?(2019年8月1日)
https://stats.stackexchange.com/questions/421935/what-exactly-are-keys-queries-and-values-in-attention-mechanisms
[6] 机器学习速成课程:嵌入式课程(2020年10月2日)
https://developers.google.com/machine-learning/crash-course/embeddings/video-lecture
[7]注意力机制综合指南(2019年11月20日)
https://www.analyticsvidhya.com/blog/2019/11/comprehensive-guide-attention-mechanism-deep-learning/
[8]深度学习:注意力机制(2019年9月15日)
https://blog.floydhub.com/attention-mechanism/
[9] 注意力机制的直观理解(2019年3月20日)
https://towardsdatascience.com/intuitive-understanding-of-attention-mechanism-in-deep-learning-6c9482aecf4f
[10] 博客发布代码(2022年2月11日)
https://colab.research.google.com/drive/1HRuVWssDYPdq1eDQSYL54OjLKXQlmW0_?usp=sharing
[11]基于注意力的神经机器翻译的有效方法(2015年9月15日) https://arxiv.org/abs/1508.04025
原文标题:What You Never Knew About Attention Mechanisms
原文链接:https://medium.com/sfu-cspmp/what-you-never-knew-about-attention-mechanisms-caa2a2fb0b94
编辑:黄继彦
校对:林亦霖
译者简介

陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师,现任北京吾译超群科技有限公司技术支持。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。业余时间喜爱翻译创作,翻译作品主要有:IEC-ISO 7816、伊拉克石油工程项目、新财税主义宣言等等,其中中译英作品“新财税主义宣言”在GLOBAL TIMES正式发表。能够利用业余时间加入到THU 数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织