特征:什么是特征和特征选择?
机器学习很重要的过程就是特征工程。在深度学习神经网络中需要特征工程吗?
理论上是不需要的,基于端到端的特点深度学习神经网络中会在训练中自行的学习特征。但是实际情况中往往和理论中是有些不一样的,在遇到数据量较少和需要减少运算资源的情况下就需要做一下特征工程。
后面是正文,关于特征和特征选择的几种方式!
在machine learning (机器学习)中,特征工程是重中之重,我们今天就来简单介绍一下特征工程里面的feature(特征),以及feature selection (特征选择)。
首先我们来看看中文字典里是怎么解释特征的:一事物异于其他事物的特点。
那我们再来看看英文字典里是怎么解释feature的:A feature of something is an interesting or important part or characteristic of it.
我们把这两个综合一下,特征就是,于己而言,特征是某些突出性质的表现,于他而言,特征是区分事物的关键,所以,当我们要对事物进行分类或者识别,我们实际上就是提取‘特征’,通过特征的表现进行判断。好了,我们先来举个例子:
事物的特征非常多,但最终,提取的特征应该要服从我们的目的,还是拿上图举例子,假如我想知道有多少个立方体, 上来就把形状,颜色,大小等feature 全提了个遍是非常不明智的,这就是在浪费计算资源, 所以我们只需要选择形状这个feature就好啦。
你可能会想,对啊,我一开始就只去提取形状这一个feature不就好了吗?这是因为你肉眼就可以做出判断了,但是,生活往往是艰难的,对于我们采集到的数据,很多情况下可能都不知道怎么去提取特征,或者我们需要去提取大量的feature来做分析。我再举个栗子,我曾经做过一个项目,是通过分析EEG (脑电波图)来查看病人是否得了癫痫,如果病人的癫痫发作,那么他的脑电波会出现一些不同寻常的变化,这些变化,我们称之为 ’spike’, 这个spike 就是癫痫病人的特征了,我们的目的,就是在EEG中把这些spike找出来。
首先我们来看看病人EEG:

红色的波形就是spike,蓝色的波形就是正常的脑电波了,我们称之为‘background’,我们的目的就是要把background和spike分别出来。我们再来看几个spike的例子:
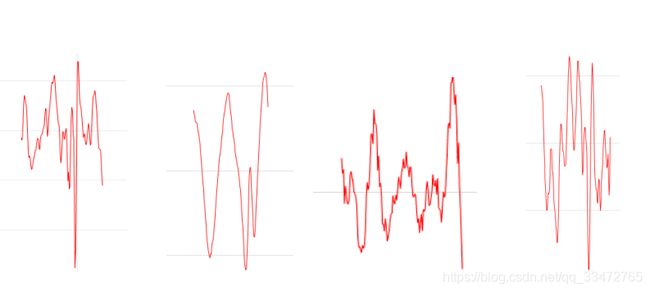
以上是不同情况下病人突发癫痫症状的脑电波,可以看见spike变换无常,我们很难找到其中规律,因此我们只能尝试通过提取更高维的特征再让机器自己做分析。
首先我提取了Peak,Nonlinear Energy Operator(NLEO), Discrete Wavelet Transform(DWT) 3类特征,每类6个特征(同种类特征参数不一样,提取的特征也不一样),共18个特征,得到的分类准确率只有76.25%,然后我又在原来的特征基础上做了一下尝试:
特征类别不变,修改特征参数(比如修改特征频率),增加每种特征个数,共30种,测试的分类准确率为76.83%,这个情况提升只有0.6%。
增加特征类别,新增了如p2t, t2p等类别的特征,测试的分类准确率为72.3%,准确率不升反降。
那么,我们就可以假设出一个结论:
我们提取得特征中有冗余特征,对模型的性能几乎没有帮助。
我们提取的特征中有些可以列为噪声(或者可以称为老鼠屎),对模型的性能不仅没有帮助,还会降低模型的性能。
那么,我们很自然就会想到要进行feature selection(特征选择)。
那么,我们接下来要讲的就是今天的主题啦,feature selection。
Q1: 我们为什么要进行feature selection?
要是你从事过machine learning相关工作,肯定会发现一个问题,模型一样,算法一样,使用的机器,软件啊也一样,甚至连原始数据都一样,但最后训练得到的model效果还是有差别,这是为啥子咧?其中一个可能的原因,不同的model, 选取的特征不一样,效果也不一样。
机器学习本质上就是针对一堆数据进行统计学的分析,最后得到的模型是根据分析的数据为基础的。所以,敲黑板!!feature selection 的本质就是对一个给定特征子集的优良性通过一个特定的评价标准(evaluation criterion)进行衡量.通过特征选择,原始特征集合中的冗余(redundant)特征和不相关(irrelevant)特征被除去。而有用特征得以保留。
很多情况下,比如上面提到分析EEG来检测癫痫,我们并不知道要提取什么特征,所以我们会提取大量特征,少则几十,多则上亿,自己手中如果有上亿元那真是好东西,一分钱都不能扔,但是手上有上亿维的特征值,那就得先想办法把那些没用的垃圾特征统统扔掉,因为分析的是垃圾,结果也是垃圾。就像鲁迅所说:“sometimes, less is better.”
好了,我们再来看看这个癫痫例子。我把所有的提取的特征数据都放进模型里进行训练(我这里用的是随机森林Random Forest,以后我会针对这些machine learning 的model做一个专门的解释和分析),testing 准确率为71%左右,下面是在同样的训练和测试数据情况下,针对某些特征进行单独训练和测试得到结果:

可以明显的看到,不同的特征,结果还是差别很大的,如果我只用选取上图准确率最高的一类特征来训练模型,80.32%测试结果将比使用全部特征作为训练数据71%好不少,这个DWT-Approx(4-14Hz) db2,k=1 特征就相当于我们第一个例子中找正方体的‘形状’特征,即主要特征。那么针对未来的训练,我们可以尝试提取表现最好的几个特征就好了,这样我们就:
降低了模型的复杂度,节省了大量计算资源以及计算时间。
提高了模型的泛化能力。什么是泛化能力呢,我打个比方,一个模型是通过训 测,可是有些人长的就像噪声,对模型将会产生一定的影响,这样第一个模型的泛化能力就比第二个模型好不少,因为他不看脸,普适性更强。
Q2: 有哪些feature selection的方法呢?
通常来说,我们要从两个方面来考虑特征选择:
特征是否发散:如果一个特征不发散,就是说这个特征大家都有或者非常相似,说明这个特征不需要。
特征和目标是否相关:与目标的相关性越高,越应该优先选择。
总得来说,特征选择有三种常用的思路:(以下的方法由于涉及到大量专业知识以及公式推演,全部说清楚篇幅较长,请读者们自己搜吧,网上都有)
(1)特征过滤(Filter Methods):对各个特征按照发散性或者相关 性进行评分,对分数设定阈值或者选择靠前得分的特征。
优点:简单,快。
缺点:对于排序靠前的特征,如果他们相关性较强,则引入了冗 余特征,浪费了计算资源。 对于排序靠后的特征,虽然独立作 用不显著,但和其他特征想组合可能会对模型有很好的帮助, 这样就损失了有价值的特征。
方法有:
Pearson’s Correlation,:皮尔逊相关系数,是用来度量 两个变量相互关系(线性相关)的,不过更多反应两个服从 正态分布的随机变量的相关性,取值范围在 [-1,+1] 之 间。
Linear Discriminant Analysis(LDA,线性判别分析):更 像一种特征抽取方式,基本思想是将高维的特征影到最佳鉴 别矢量空间,这样就可以抽取分类信息和达到压缩特征空 间维数的效果。投影后的样本在子空间有最大可分离性。
Analysis of Variance:ANOVA,方差分析,通过分析研究不 同来源的变异对总变异的贡献大小,从而确定可控因素对研 究结果影响力的大小。
Chi-Square:卡方检验,就是统计样本的实际观测值与理论 推断值之间的偏离程度,实际观测值与理论推断值之间的偏 离程 度就决定卡方值的大小,卡方值越大,越不符合;卡 方值越小,偏差越小,越趋于符合。
(2)特征筛选(Wrapper Methods)::通过不断排除特征或者不 断选择特征,并对训练得到的模型效果进行打分,通过预测 效果评 分来决定特征的去留。
优点:能较好的保留有价值的特征。
缺点:会消耗巨大的计算资源和计算时间。
方法有:
前向选择法:从0开始不断向模型加能最大限度提升模型效果的特征数据用以训练,直到任何训练数据都无法提升模型表现。
后向剃除法:先用所有特征数据进行建模,再逐一丢弃贡献最低的特征来提升模型效果,直到模型效果收敛。
迭代剃除法:反复训练模型并抛弃每次循环的最优或最劣特征,然后按照抛弃的顺序给特征种类的重要性评分。
(3)嵌入法(Embedded Methods):有不少特征筛选和特征过滤的共性,主要的特点就是通过不同的方法去计算不同特征对于模型的贡献。
方法:Lasso,Elastic Net,Ridge Regression,等。
嵌入法需要涉及到大量的理论基础和公式,这里就不讨论了。
实际上,特征工程实际上是一个非常大的概念,包括数据预处理,特征选择,降维等等。本篇文章仅做一个入门级的特征以及特征选取的讲解。后面我会对降维进行解析,因为降维在特征工程中也是重中之重。
本文参考:https://blog.csdn.net/bobo_jiang/article/details/78392347