100天精通Python(数据分析篇)——第73天:Pandas文本数据处理方法之查找、替换、拼接、正则、虚拟变量
文章目录
- 每篇前言
- 一、Python字符串内置方法
-
- 1. 文本查找
- 2. 文本替换
- 3. 文本拼接
- 4. 正则提取
- 二、Pandas实现文本查找
-
- 1. str.startswith(字符串)
- 2. str.endswith(字符串)
- 3. str.index(字符串, start=0, end=len(string))
- 4. str.rindex(字符串, start=0, end=len(string))
- 5. str.find(字符串, start=0, end=len(string))
- 6. str.rfind(字符串, start=0, end=len(string))
- 8. str.contains(字符串)
- 三、Panda实现文本替换
-
- 1. str.replace(old_str, new_str)
-
- 1)普通替换
- 2)正则替换
- 四、Pandas实现文本拼接
-
- 1. string.cat()
-
- 1)默认拼接
- 2)指定符号
- 3)指定空值
- 4)连接列表
- 五、Panda实现正则提取
-
- 1. str.match()
- 2. str.findall()
- 3. str.extract() 重要!!!
- 4. str.extractall()
- 六、Pandas实现文本虚拟变量
-
- 1. str.get_dummies
-
- 1)默认情况
- 2)指定分隔符
- 书籍介绍
每篇前言
作者介绍:Python领域优质创作者、华为云享专家、阿里云专家博主、2021年CSDN博客新星Top6
- 本文已收录于Python全栈系列专栏:《100天精通Python从入门到就业》
- 此专栏文章是专门针对Python零基础小白所准备的一套完整教学,从0到100的不断进阶深入的学习,各知识点环环相扣
- 订阅专栏后续可以阅读Python从入门到就业100篇文章;还可私聊进千人Python全栈交流群(手把手教学,问题解答); 进群可领取80GPython全栈教程视频 + 300本计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!


本文是上篇的补充,基础不会的小伙伴请看上文:100天精通Python(数据分析篇)——第71天:Pandas文本数据处理方法之str/object类型转换、大小写转换、文本对齐、获取长度、出现次数、编码
一、Python字符串内置方法
1. 文本查找
| 方法 | 说明 |
|---|---|
| string.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| string.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| string.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| string.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| string.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1 |
| string.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| string.contains(str) | 检测是否包含指定字符串,返回TRUE或者FALSE,常用于数据筛选中 |
2. 文本替换
| 方法 | 说明 |
|---|---|
| string.replace(old_str, new_str, num=string.count(old)) | 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次 |
3. 文本拼接
| 方法 | 说明 |
|---|---|
| string.cat() | 将一个序列的内容进行拼接,默认情况下会忽略缺失值,我们亦可指定缺失值 |
4. 正则提取
| 方法 | 说明 |
|---|---|
| re.match() | 尝试从字符串的起始位置匹配一个模式 |
| re.findall() | 返回所有查询到的值 |
二、Pandas实现文本查找
| 方法 | 说明 |
|---|---|
| ser_obj.str.startswith(str) | 检查字符串是否是以 str 开头,是则返回 True |
| ser_obj.str.endswith(str) | 检查字符串是否是以 str 结束,是则返回 True |
| ser_obj.str.index(str, start=0, end=len(string)) | 跟 find() 方法类似,不过如果 str 不在 string 会报错 |
| ser_obj.str.rindex(str, start=0, end=len(string)) | 类似于 index(),不过是从右边开始 |
| ser_obj.str.find(str, start=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1 |
| ser_obj.str.rfind(str, start=0, end=len(string)) | 类似于 find(),不过是从右边开始查找 |
| ser_obj.str.findall() | 返回查询到的值 |
| ser_obj.str.contains() | 检测是否包含指定字符串,返回TRUE或者FALSE,常用于数据筛选中 |
1. str.startswith(字符串)
检查字符串是否是以
某字符串开头,是则返回 True。
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'a', 'ab', None, np.NaN]
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.startswith('a')) # 是否以a开头
运行结果:

2. str.endswith(字符串)
检查字符串是否是以
某字符串结束,是则返回 True
import pandas as pd
import numpy as np
data = [1, 'A', 'Ab', 'a', 'ab', None, np.NaN]
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.endswith('b')) # 是否以b结尾
运行结果:

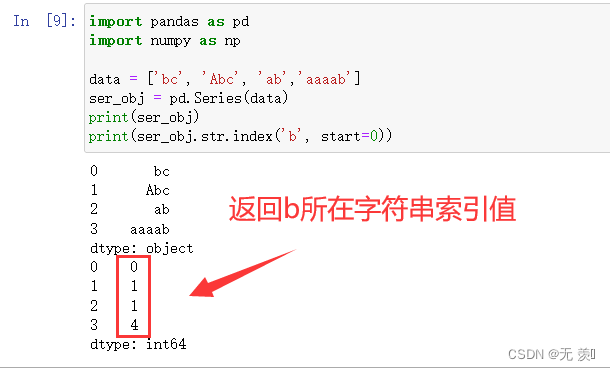
3. str.index(字符串, start=0, end=len(string))
跟 find() 方法类似,不过如果 字符串不在 string 会报错
import pandas as pd
import numpy as np
data = ['bc', 'Abc', 'ab','aaaab']
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.index('b', start=0))
运行结果:
4. str.rindex(字符串, start=0, end=len(string))
类似于 index(),不过是从右边开始
import pandas as pd
import numpy as np
data = ['bc', 'Abc', 'ab', 'aaaab']
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.rindex('b'))
运行结果,不知道还是和index一样:

5. str.find(字符串, start=0, end=len(string))
检测 某字符串 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1
import pandas as pd
import numpy as np
data = [1, 'A', 'Abc', 'a', 'ab', None, np.NaN]
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.find('b', start=0, end=len('abc')))
运行结果:

6. str.rfind(字符串, start=0, end=len(string))
类似于 find(),不过是从右边开始查找
import pandas as pd
import numpy as np
data = [1, 'A', 'Abc', 'a', 'ab', None, np.NaN]
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.rfind('b', start=0))
运行结果:

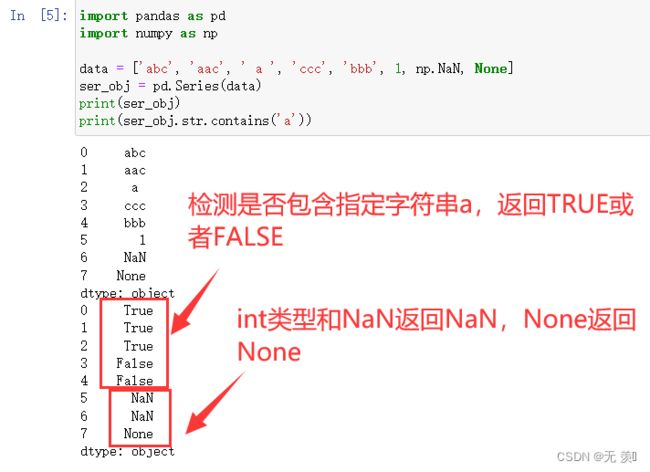
8. str.contains(字符串)
检测是否包含指定字符串,返回TRUE或者FALSE,常用于数据筛选中
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.contains('a'))
运行结果:
三、Panda实现文本替换
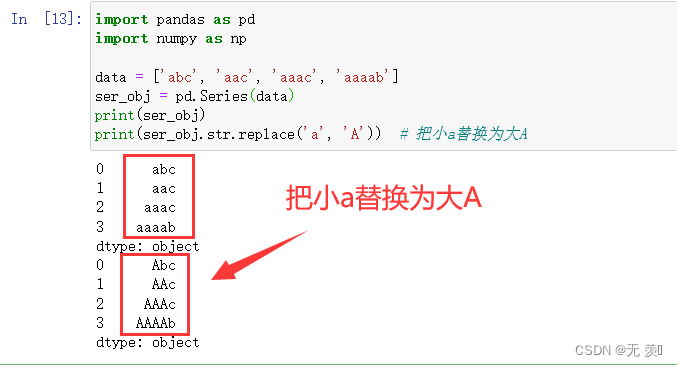
1. str.replace(old_str, new_str)
把 string 中的 old_str 替换成 new_str
1)普通替换
import pandas as pd
import numpy as np
data = ['abc', 'aac', 'aaac', 'aaaab']
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.replace('a', 'A')) # 把小a替换为大A
运行结果:
2)正则替换
replace方法中还可以用正则语法,需要加上
regex=True参数
import pandas as pd
import numpy as np
data = ['abc', 'aac', 'aaac', 'aaaab']
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.replace('a|b|c', 'A', regex=True)) # 把全部替换为大A
运行结果:

四、Pandas实现文本拼接
1. string.cat()
将一个序列的内容进行拼接,默认情况下会忽略缺失值,我们亦可指定缺失值
1)默认拼接
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.cat())
运行结果:

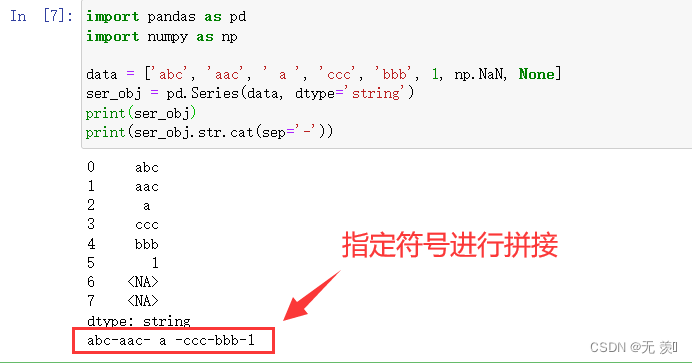
2)指定符号
设置
sep参数指定符号进行拼接
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.cat(sep='-'))
运行结果:
3)指定空值
设置
na_rep参数指定缺失值填充
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.cat(na_rep='空值'))
运行结果:

4)连接列表
连接一个序列和另一个等长的列表,默认情况下如果有缺失值,则会导致结果中也有缺失值,不过可以通过指定缺失值na_rep的情况进行处理
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
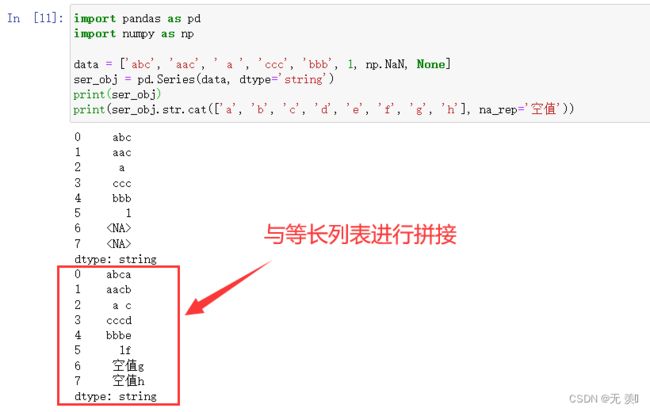
print(ser_obj.str.cat(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'], na_rep='空值'))
运行结果:
五、Panda实现正则提取
1. str.match()
尝试从字符串的起始位置匹配一个模式,返回TRUE或者FALSE
import pandas as pd
import numpy as np
data = ['abc', 'aac', ' a ', 'ccc', 'bbb', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.match('^a')) # 匹配以a开头的内容
运行结果:

2. str.findall()
返回所有查询到的值,返回的是一个列表
import pandas as pd
import numpy as np
data = ['abc', 'aac', 'aaac', 'aaaab']
ser_obj = pd.Series(data)
print(ser_obj)
print(ser_obj.str.findall('[ab]')) # 匹配包含字母a或者b
运行结果:

3. str.extract() 重要!!!
我们在日常中经常遇到需要提取某序列文本中特定的字符串,这个时候采用str.extract()方法就可以很好的进行处理,它是用正则表达式将文本中满足要求的数据提取出来形成单独的列。注意:仅返回匹配到的首个字符串!!!
0.23版本之前expand默认为FALSE:
- 当
expand=Fasle时如果返回结果是一列则为Series,否则是Dataframe。- 当
expand=True返回一个数据帧
import pandas as pd
import numpy as np
data = ['a1', 'b2', 'c3', 'c3c3', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
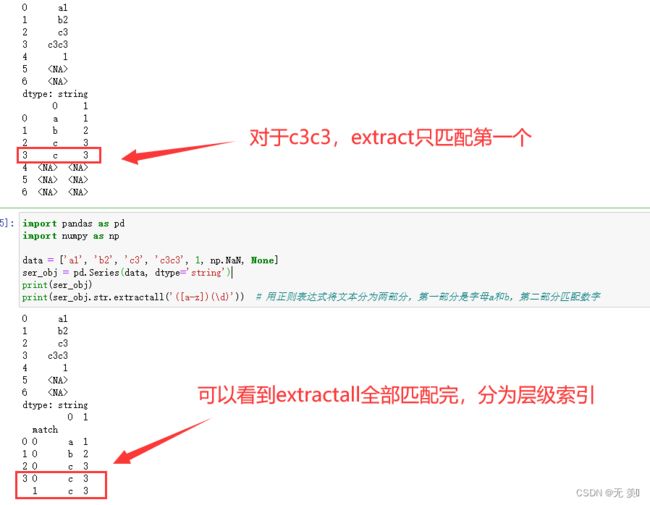
print(ser_obj.str.extract('([a-z])(\d)')) # 用正则表达式将文本分为两部分,第一部分是字母a和b,第二部分匹配数字
运行结果:

4. str.extractall()
与extracta()用法相似,区别是:
- extracta:仅返回匹配到的首个字符串
- extractall:会提取全部匹配项,会将一个文本中所有符合规则的内容匹配出来,最后形成一个多层索引数据
import pandas as pd
import numpy as np
data = ['a1', 'b2', 'c3', 'c3c3', 1, np.NaN, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.extractall('([a-z])(\d)')) # 用正则表达式将文本分为两部分,第一部分是字母a和b,第二部分匹配数字
运行结果:
六、Pandas实现文本虚拟变量
get_dummies可以将一个列变量自动生成虚拟变量,这种方法在特征衍生中经常使用。
1. str.get_dummies
1)默认情况
import pandas as pd
import numpy as np
data = ['小明', '小红', '小张', '小白']
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.get_dummies())
运行结果:

2)指定分隔符
设置
sep参数可以指定分隔符
import pandas as pd
import numpy as np
data = ["A", "A|B", "A|B|C", 1, np.nan, None]
ser_obj = pd.Series(data, dtype='string')
print(ser_obj)
print(ser_obj.str.get_dummies(sep="|"))
运行结果:第一行1ABC只有A,第二行有A和B,第三行都ABC都有,第四行有1,剩下的行数都没了

书籍介绍
《ZooKeeper+Dubbo 3分布式高性能RPC通信》

本教程详细介绍了ZooKeeper + Dubbo 3联合开发时的高频实战技能,包含ZooKeeper的数据模型、Watch观察者机制、服务器角色、领导选举、ZAB协议、ZooKeeper架构、节点类型、ZooKeeper运用场景、搭建单机和主从环境、常用的Command命令、ACL授权、配额等高频使用技术点。在Dubbo 3章节中详细介绍了单体/水平集群/垂直集群/SOA架构的发展历程、CAP理论、Dubbo特性、RPC原理、Dubbo中的五大核心组件、直连提供者、隐式参数、服务分组、多版本、启动时检查、令牌验证、超时和线程池大小、Nacos注册中心、服务提供者集群、集群容错、负载均衡等实用技能。
如果不想抽奖京东自营购买链接:https://item.jd.com/13465437.html