第2章 马尔可夫决策过程
2.1 马尔可夫决策过程(上)
Markov Decision Process(MDP)
- Markov Decision Process can model a lot of real-world problem. It formally describes the framework of reinforcement learning
- Under MDP, the environment is fully observable.
- Optimal control primarily deals with continuous MDPs
- Partially observable problems can be converted into MDPs
Markov Property
-
The history of states: h t = { s 1 , s 2 , s 3 , . . . , s t } h_{t}=\left \{ s_{1},s_{2},s_{3},...,s_{t} \right \} ht={s1,s2,s3,...,st}
-
State s t s_{t} st is Markovian if and only if:
p ( s t + 1 ∣ s t ) = p ( s t + 1 ∣ h t ) p(s_{t+1}|s_{t})=p(s_{t+1}|h_{t}) p(st+1∣st)=p(st+1∣ht)p ( s t + 1 ∣ s t , a t ) = p ( s t + 1 ∣ h t , a t ) p(s_{t+1}|s_{t},a_{t})=p(s_{t+1}|h_{t},a_{t}) p(st+1∣st,at)=p(st+1∣ht,at)
-
“The future is independent of the past given the present”
Markov Process/Markov Chain
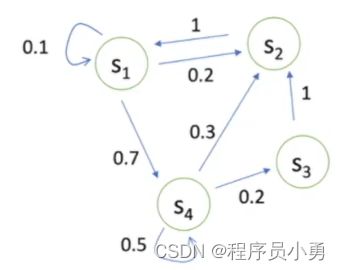
- State transition matrix P specifies p ( s t + 1 = s ′ ∣ s t = s ) p(s_{t+1}=s'|s_{t}=s) p(st+1=s′∣st=s)
P = [ P ( s 1 ∣ s 1 ) P ( s 2 ∣ s 1 ) . . . P ( s N ∣ s 1 ) P ( s 1 ∣ s 2 ) P ( s 2 ∣ s 2 ) . . . P ( s N ∣ s 2 ) . . . . . . ⋱ . . . P ( s 1 ∣ s N ) P ( s 2 ∣ s N ) . . . P ( s N ∣ s N ) ] P=\begin{bmatrix} P(s_{1}|s_{1}) & P(s_{2}|s_{1}) & ... & P(s_{N}|s_{1})\\ P(s_{1}|s_{2}) & P(s_{2}|s_{2}) & ... & P(s_{N}|s_{2})\\ ... & ... & \ddots & ...\\ P(s_{1}|s_{N}) & P(s_{2}|s_{N}) & ... & P(s_{N}|s_{N}) \end{bmatrix} P= P(s1∣s1)P(s1∣s2)...P(s1∣sN)P(s2∣s1)P(s2∣s2)...P(s2∣sN)......⋱...P(sN∣s1)P(sN∣s2)...P(sN∣sN)
Example of MP

- Sample episodes starting from s 3 s_{3} s3
- s 3 , s 4 , s 5 , s 6 , s 6 s_{3},s_{4},s_{5},s_{6},s_{6} s3,s4,s5,s6,s6
- s 3 , s 2 , s 3 , s 2 , s 1 s_{3},s_{2},s_{3},s_{2},s_{1} s3,s2,s3,s2,s1
- s 3 , s 4 , s 4 , s 5 , s 5 s_{3},s_{4},s_{4},s_{5},s_{5} s3,s4,s4,s5,s5
Markov Reward Process (MRP)
- Markov Reward Process is a Markov Chain + reward
- Definition of Markov Reward Process (MRP)
- S is a (finite) set of states (s ∈ S)
- P is dynamics/transition model that specifies P ( S t + 1 = s ′ ∣ s t = s ) P(S_{t+1}=s'|s_{t}=s) P(St+1=s′∣st=s)
- R is a reward function R ( s t = s ) = E [ r t ∣ s t = s ] R(s_{t}=s)=E[r_{t}|s_{t}=s] R(st=s)=E[rt∣st=s]
- Discount factor γ ∈ [ 0 , 1 ] \gamma ∈[0,1] γ∈[0,1]
- If finite number of states, R can be a vector
Example of MRP

Reward: +5 in s 1 s_{1} s1, +10 in s 7 s_{7} s7, 0 in all other states. So that we can represent R = [5, 0, 0, 0, 0, 0, 10]
Return and Value function
-
Definition of Horizon
- Number of maximum time steps in each episode
- Can be infinite, otherwise called finite Markov (reward) Process
-
Definition of Return
- Discounted sum of rewards from time step t to horizon
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + . . . + γ T − t − 1 R T G_{t}=R_{t+1}+γR_{t+2}+γ^{2}R_{t+3}+γ^{3}R_{t+4}+...+γ^{T-t-1}R_{T} Gt=Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+...+γT−t−1RT
- Discounted sum of rewards from time step t to horizon
-
Definition of state value function V t ( s ) V_{t}(s) Vt(s) for a MRP
-
Expected return from t in state s
V t ( s ) = E [ G t ∣ s t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + . . . + γ T − t − 1 R T ∣ s t = s ] {V_{t}(s)=E[G_{t}|s_{t}=s]} =E[R_{t+1}+γR_{t+2}+γ^{2}R_{t+3}+γ^{3}R_{t+4}+...+γ^{T-t-1}R_{T}|s_{t}=s] Vt(s)=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+...+γT−t−1RT∣st=s] -
Present value of future rewards
-
Why Discount Factor γ
- Avoid infinite returns in cycle Markov processes
- Uncertainly about the future may not be fully represented
- If the reward is financial, immediate rewards may earn more interest than delayed rewards
- Animal/human behaviour shows preference for immediate reward
- It is sometimes possible to use undiscounted Markov reward processes (i.e. γ = 1), e.g if all sequences terminate.
- γ = 0: Only care about the immediate reward
- γ = 1: Future reward is equal to the immediate reward.
Example of MRP

- Reward: +5 in s 1 s_{1} s1, +10 in s 7 s_{7} s7, 0 in all other states. So that we can represent R = [5, 0, 0, 0, 0, 0, 10]
- Sample returns G for a 4-step episodes with γ = 1/2
- return for s 4 , s 5 , s 6 , s 7 s_{4},s_{5},s_{6},s_{7} s4,s5,s6,s7 : 0 + 1 2 × 0 + 1 4 × 0 + 1 8 × 10 = 1.25 0+\frac{1}{2}×0+\frac{1}{4}×0+\frac{1}{8}×10=1.25 0+21×0+41×0+81×10=1.25
- return for s 4 , s 3 , s 2 , s 1 s_{4},s_{3},s_{2},s_{1} s4,s3,s2,s1 : 0 + 1 2 × 0 + 1 4 × 0 + 1 8 × 5 = 0.625 0+\frac{1}{2}×0+\frac{1}{4}×0+\frac{1}{8}×5=0.625 0+21×0+41×0+81×5=0.625
- return for s 4 , s 5 , s 6 , s 6 s_{4},s_{5},s_{6},s_{6} s4,s5,s6,s6 : = 0
- How to compute the value function? For example, the value of state s 4 s_{4} s4 as V ( s 4 ) V(s_{4}) V(s4)
Compute the Value of a Markov Reward Process
-
Value function: expected return from starting in state s
V ( s ) = E [ G t ∣ s t = s ] = E [ R t + 1 + γ R t + 2 + γ 2 R t + 3 + γ 3 R t + 4 + . . . + γ T − t − 1 R T ∣ s t = s ] {V(s)=E[G_{t}|s_{t}=s]} =E[R_{t+1}+γR_{t+2}+γ^{2}R_{t+3}+γ^{3}R_{t+4}+...+γ^{T-t-1}R_{T}|s_{t}=s] V(s)=E[Gt∣st=s]=E[Rt+1+γRt+2+γ2Rt+3+γ3Rt+4+...+γT−t−1RT∣st=s] -
MRP value function satisfies the following Bellman equation:
V ( s ) = R ( s ) ⏟ I m m e d i a t e r e w a r d + γ ∑ s ∈ S ′ P ( s ′ ∣ s ) V ( s ′ ) ⏟ D i s c o u n t e d s u m o f f u t u r e r e w a r d V(s)=\underset{Immediate \,reward}{\underbrace{R(s)}}+\underset{Discounted \, sum\, of \, future \, reward}{\underbrace{\gamma \sum_{s\in S'}^{}P(s'|s)V(s')}} V(s)=Immediatereward R(s)+Discountedsumoffuturereward γs∈S′∑P(s′∣s)V(s′) -
Practice: To derive the Bellman equation for V(s)
- Hint: V ( s ) = E [ R t + 1 + γ E [ R t + 2 + γ 2 R t + 3 + . . . ] ∣ s t = s ] V(s)=E[R_{t+1}+γE[R_{t+2}+γ^{2}R_{t+3}+...]|s_{t}=s] V(s)=E[Rt+1+γE[Rt+2+γ2Rt+3+...]∣st=s]
Understanding Bellman equation
- Bellman equation describes the iterative relations of states
V ( s ) = R ( s ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s ) V ( s ′ ) V(s)=R(s)+\gamma \sum_{s'\in S}^{}P(s'|s)V(s') V(s)=R(s)+γs′∈S∑P(s′∣s)V(s′)

Matrix Form of Bellman Equation for MRP
Therefore, we can express V(s) using the matrix form:
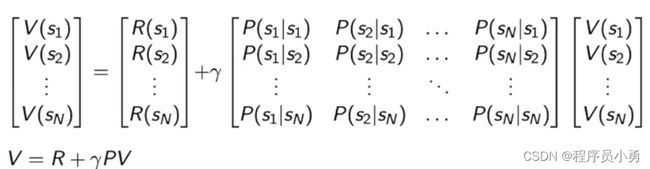
- Analytic solution for value of MRP: V = ( I − γ P ) − 1 R V=(I-γP)^{-1}R V=(I−γP)−1R
- Matrix inverse takes the complexity O ( N 3 ) O(N^{3}) O(N3) for N states
- Only possible for a small MRPs
Iterative Algorithm for Computing Value of a MRP
- Iterative methods for large MRPs:
- Dynamic Programming
- Monte-Carlo evaluation
- Temporal-Difference learning
Monte Carlo Algorithm for Computing Value of a MRP
Algorithm 1 Monte Carlo simulation to calculate MRP value function
-
i ← 0 , G t ← 0 i\leftarrow 0,G_{t}\leftarrow 0 i←0,Gt←0
-
while i ≠ N i≠N i=N do
-
generate an episode, starting from state s and time t
-
Using the generated episode, calculate return g = ∑ i = t H − 1 γ i − t r i g=\sum_{i=t}^{H-1}\gamma ^{i-t}r_{i} g=∑i=tH−1γi−tri
-
G t ← G t + g , i ← i + 1 G_{t}\leftarrow G_{t}+g,i\leftarrow i+1 Gt←Gt+g,i←i+1
-
end while
-
V t ( s ) ← G t / N V_{t}(s)\leftarrow G_{t}/N Vt(s)←Gt/N
-
For example: to calculate V ( s 4 ) V(s_{4}) V(s4) we can generate a lot of trajectories then take the average of the returns:
- return for s 4 , s 5 , s 6 , s 7 s_{4},s_{5},s_{6},s_{7} s4,s5,s6,s7 : 0 + 1 2 × 0 + 1 4 × 0 + 1 8 × 10 = 1.25 0+\frac{1}{2}×0+\frac{1}{4}×0+\frac{1}{8}×10=1.25 0+21×0+41×0+81×10=1.25
- return for s 4 , s 3 , s 2 , s 1 s_{4},s_{3},s_{2},s_{1} s4,s3,s2,s1 : 0 + 1 2 × 0 + 1 4 × 0 + 1 8 × 5 = 0.625 0+\frac{1}{2}×0+\frac{1}{4}×0+\frac{1}{8}×5=0.625 0+21×0+41×0+81×5=0.625
- return for s 4 , s 5 , s 6 , s 6 s_{4},s_{5},s_{6},s_{6} s4,s5,s6,s6 : = 0
- more trajectories
Iterative Algorithm for Computing Value of a MRP
Algorithm 1 Iterative Algorithm to calculate MRP value function
- for all states s ∈ S , V ′ ( s ) ← 0 , V ( s ) ← ∞ s∈S,V'(s)\leftarrow 0,V(s)\leftarrow ∞ s∈S,V′(s)←0,V(s)←∞
- while ∣ ∣ V − V ′ ∣ ∣ > ϵ ||V-V'||>\epsilon ∣∣V−V′∣∣>ϵ do
- V ← V ′ V\leftarrow V' V←V′
- For all states s ∈ S , V ′ ( s ) = R ( s ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s ) V ( s ′ ) s∈S,V'(s)=R(s)+\gamma \sum_{s'\in S}^{}P(s'|s)V(s') s∈S,V′(s)=R(s)+γ∑s′∈SP(s′∣s)V(s′)
- end while
- return V ′ ( s ) V'(s) V′(s) for all s ∈ S s∈S s∈S
Markov Decision Process (MDP)
-
Markov Decision Process is Markov Reward Process with decisions.
-
Definition of MDP
-
S is a finite set of states
-
A is a finite set of actions
-
P a P^{a} Pa is dynamics/transition model for each action
P ( s t + 1 = s ′ ∣ s t = s , a t = a ) P(s_{t+1}=s'|s_{t}=s,a_{t}=a) P(st+1=s′∣st=s,at=a)
-
R is a reward function R ( s t = s , a t = a ) = E [ r t ∣ s t = s , a t = a ] R(s_{t}=s,a_{t}=a)=E[r_{t}|s_{t}=s,a_{t}=a] R(st=s,at=a)=E[rt∣st=s,at=a]
-
Discount factor γ ∈ [ 0 , 1 ] γ∈[0,1] γ∈[0,1]
-
-
MDP is a turple: ( S , A , P , R , γ ) (S,A,P,R,γ) (S,A,P,R,γ)
Policy in MDP
-
Policy specifies what action to take in each state
-
Give a state, specify a distribution over actions
-
Policy: π ( a ∣ s ) = P ( a t = a ∣ s t = s ) \pi(a|s)=P(a_{t}=a|s_{t}=s) π(a∣s)=P(at=a∣st=s)
-
Policies are stationary (time-independent), A t ∼ π ( a ∣ s ) A_{t}\sim \pi(a|s) At∼π(a∣s) for any t > 0
-
Given an MDP ( S , A , P , R , γ ) (S,A,P,R,γ) (S,A,P,R,γ) and a policy π \pi π
-
The state sequence S 1 , S 2 , . . . S_{1},S_{2},... S1,S2,... is a Markov process ( S , P π ) (S,P^{\pi}) (S,Pπ)
-
The state and reward sequence S 1 , R 1 , S 2 , R 2 , . . . S_{1},R_{1},S_{2},R_{2},... S1,R1,S2,R2,... is a Markov reward process ( S , P π , R π , γ ) (S,P^{\pi},R^{\pi},γ) (S,Pπ,Rπ,γ) where,
P π ( s ′ ∣ s ) = ∑ a ∈ A π ( a ∣ s ) P ( s ′ ∣ s , a ) P^{\pi}(s'|s)=\sum_{a∈A}\pi(a|s)P(s'|s,a)\\ Pπ(s′∣s)=a∈A∑π(a∣s)P(s′∣s,a)
R π ( s ) = ∑ a ∈ A π ( a ∣ s ) P ( s , a ) R^{\pi}(s)=\sum_{a∈A}\pi(a|s)P(s,a) Rπ(s)=a∈A∑π(a∣s)P(s,a)
Comparison of MP/MRP and MDP

Value function for MDP
-
The state-value function v π ( s ) v^{\pi}(s) vπ(s) of an MDP is the expected return starting from state s, and following policy π \pi π
v π ( s ) = E π [ G t ∣ s t = s ] v^{\pi}(s)=E{\pi}[G_{t}|s_{t}=s] vπ(s)=Eπ[Gt∣st=s] -
The action-value function q π ( s , a ) q^{\pi}(s,a) qπ(s,a) is the expected return starting from state s, taking action a, and following policy π \pi π
q π ( s , a ) = E π [ G t ∣ s t = s , A t = a ] q^{\pi}(s,a)=E{\pi}[G_{t}|s_{t}=s,A_{t}=a] qπ(s,a)=Eπ[Gt∣st=s,At=a] -
We have the relation between v π ( s ) v^{\pi}(s) vπ(s) and q π ( s , a ) q^{\pi}(s,a) qπ(s,a)
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v^{\pi}(s)=\sum_{a∈A}\pi(a|s)q^{\pi}(s,a) vπ(s)=a∈A∑π(a∣s)qπ(s,a)
Bellman Expection Equation
-
The state-value function can be decomposed into immediate reward plus discounted value of successor state,
v π ( s ) = E π [ R t + 1 + γ v π ( s t + 1 ) ∣ s t = s ] v^{\pi}(s)=E_{\pi}[R_{t+1}+γv^{\pi}(s_{t+1})|s_{t}=s] vπ(s)=Eπ[Rt+1+γvπ(st+1)∣st=s] -
The action-value function can similarly be decomposed
q π ( s , a ) = E π [ R t + 1 + γ q π ( s t + 1 , A t + 1 ) ∣ s t = s , A t = a ] q^{\pi}(s,a)=E_{\pi}[R_{t+1}+γq^{\pi}(s_{t+1},A_{t+1})|s_{t}=s,A_{t}=a] qπ(s,a)=Eπ[Rt+1+γqπ(st+1,At+1)∣st=s,At=a]
Bellman Expection Equation for V π V^{\pi} Vπ and Q π Q^{\pi} Qπ
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v^{\pi}(s)=\sum_{a∈A}\pi(a|s)q^{\pi}(s,a) vπ(s)=a∈A∑π(a∣s)qπ(s,a)
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) q^{\pi}(s,a)=R_{s}^{a}+γ\sum_{s'∈S}P(s'|s,a)v^{\pi}(s') qπ(s,a)=Rsa+γs′∈S∑P(s′∣s,a)vπ(s′)
Thus
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) ) v^{\pi}(s)=\sum_{a∈A}\pi(a|s)(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{\pi}(s')) vπ(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vπ(s′))
q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q^{\pi}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)\sum_{a'∈A}\pi(a'|s')q^{\pi}(s',a') qπ(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′∈A∑π(a′∣s′)qπ(s′,a′)
Backup Diagram for V π V^{\pi} Vπ
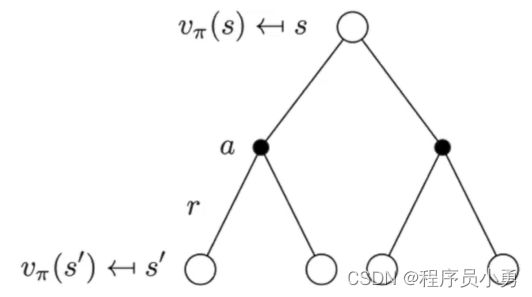
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) ) v^{\pi}(s)=\sum_{a∈A}\pi(a|s)(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{\pi}(s')) vπ(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vπ(s′))
Backup Diagram for Q π Q^{\pi} Qπ
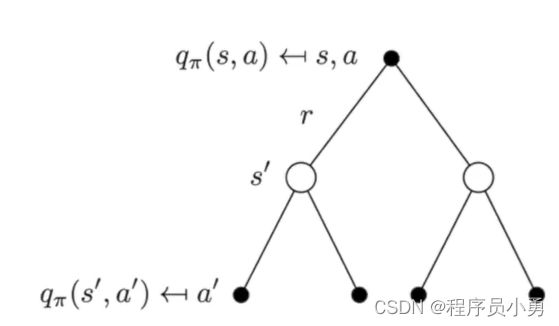
q π ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q^{\pi}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)\sum_{a'∈A}\pi(a'|s')q^{\pi}(s',a') qπ(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′∈A∑π(a′∣s′)qπ(s′,a′)
Policy Evaluation
- Evaluate the value of state given a policy π \pi π: compute v π ( s ) v^{\pi}(s) vπ(s)
- Also called as (value) prediction
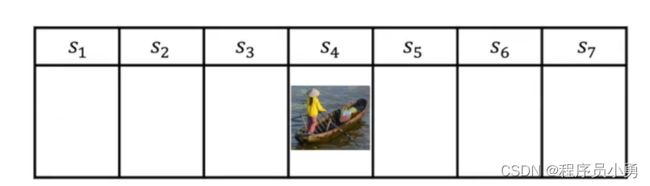
Example: Navigate the boat

Example: Policy Evaluation
-
Two actions: Left and Right
-
For all actions, reward: +5 in s 1 s_{1} s1, +10 in s 7 s_{7} s7, 0 in all other states. So that we can represent R = [5, 0, 0, 0, 0, 0, 10]
-
Let’s have a deterministic policy π ( s ) = \pi(s)= π(s)=Left and γ = 0 γ=0 γ=0 for any state s, then what is the value of the policy?
- v π = [ 5 , 0 , 0 , 0 , 0 , 0 , 10 ] v^{\pi}= [5, 0, 0, 0, 0, 0, 10] vπ=[5,0,0,0,0,0,10]
-
Iteration: v k π ( s ) = r ( s , π ( s ) ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , π ( s ) ) v k − 1 π ( s ′ ) v_{k}^{\pi}(s)=r(s,\pi(s))+γ\sum_{s'∈S}P(s'|s,\pi(s))v_{k-1}^{\pi}(s') vkπ(s)=r(s,π(s))+γ∑s′∈SP(s′∣s,π(s))vk−1π(s′)
-
R = [ 5 , 0 , 0 , 0 , 0 , 0 , 10 ] R = [5, 0, 0, 0, 0, 0, 10] R=[5,0,0,0,0,0,10]
-
Practice 1: Deterministic policy π ( s ) = \pi(s)= π(s)=Left and γ = 0.5 γ=0.5 γ=0.5 for any state s, then what are the states values under the policy?
-
Practice 2: Stochastic policy P ( π ( s ) = L e f t ) = 0.5 P(\pi(s)=Left)=0.5 P(π(s)=Left)=0.5 and P ( π ( s ) = R i g h t ) = 0.5 P(\pi(s)=Right)=0.5 P(π(s)=Right)=0.5 and γ = 0.5 γ=0.5 γ=0.5 for any state s, then what are the states values under the policy?
-
Iteration: v k π ( s ) = r ( s , π ( s ) ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , π ( s ) ) v k − 1 π ( s ′ ) v_{k}^{\pi}(s)=r(s,\pi(s))+γ\sum_{s'∈S}P(s'|s,\pi(s))v_{k-1}^{\pi}(s') vkπ(s)=r(s,π(s))+γ∑s′∈SP(s′∣s,π(s))vk−1π(s′)
2.2 马尔可夫决策过程(下)
Decison Making in Markov Decision Process(MDP)
- Prediction (evaluate a given policy):
- Input: MDP < S , A , P , R , γ >
- Output: value function v π v^{\pi} vπ
- Input: MDP < S , A , P , R , γ >
- Control (search the optimal policy):
- Input: MDP < S , A , P , R , γ >
- Output: optimal value function v ∗ v^{*} v∗ and optimal policy π ∗ \pi^{*} π∗
- Input: MDP < S , A , P , R , γ >
- Prediction and control in MDP can be solved by dynamic programming.
Dynamic programming
Dynamic programming is a very general solution method for problems which have two properties:
- Optimal substructure
- Principle of optimality applies
- Optimal solution can be decomposed into subproblems
- Overlapping subproblems
- Subproblems recur many times
- Solutions can be cached and reused
Markov decision processes satisfy both properties
- Bellman equation gives recursive decomposition
- Value function stores and reuses solutions
Policy evaluation on MDP
-
Objective: Evaluate a given policy π \pi π for a MDP
-
Output: the value function under policy v π v^{\pi} vπ
-
Solution: iteration on Bellman expectation backup
-
Algorithm: Synchronous backup
-
At each iteration t+1
update v t + 1 ( s ) v_{t+1}(s) vt+1(s) from v t ( s ′ ) v_{t}(s') vt(s′) for all states s ∈ S s∈S s∈S where s’ is a successor state of s
v t + 1 ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v t ( s ′ ) ) v_{t+1}(s)=\sum_{a∈A}\pi(a|s)(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v_{t}(s')) vt+1(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vt(s′))
-
-
Convergence: v 1 → v 2 → . . . → v π v_{1}\rightarrow v_{2}\rightarrow ...\rightarrow v^{\pi} v1→v2→...→vπ
Policy evaluation: Iteration on Bellman expectation backup
Bellman expectation backup for a particular policy
v t + 1 ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v t ( s ′ ) ) v_{t+1}(s)=\sum_{a∈A}\pi(a|s)(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v_{t}(s')) vt+1(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vt(s′))
Or if in the form of MRP < S , P π , R π , γ >
v t + 1 ( s ) = R π ( s ) + γ P π ( s ′ ∣ s ) V t ( s ′ ) v_{t+1}(s)=R^{\pi}(s)+\gamma P^{\pi}(s'|s)V_{t}(s') vt+1(s)=Rπ(s)+γPπ(s′∣s)Vt(s′)
Evaluating a Random Policy in the Small Gridworld
Example 4.1 in the Sutton RL textbook

- Undiscounted episodic MDP ( γ = 1 γ=1 γ=1)
- Nonterminal states 1, …, 14
- Two terminal states (two shaded squares)
- Action leading out of grid leaves state unchanged, P ( 7 ∣ 7 , r i g h t ) = 1 P(7|7,right)=1 P(7∣7,right)=1
- Reward is -1 until the terminal state is reach
- Transition is deterministic given the action, e.g., P ( 6 ∣ 5 , r i g h t ) = 1 P(6|5,right)=1 P(6∣5,right)=1
- Uniform random policy π ( l ∣ . ) = π ( r ∣ . ) = π ( u ∣ . ) = π ( d ∣ . ) = 0.25 \pi(l|.)=\pi(r|.)=\pi(u|.)=\pi(d|.)=0.25 π(l∣.)=π(r∣.)=π(u∣.)=π(d∣.)=0.25
A live demo on policy evaluation
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π ( s ′ ) ) v^{\pi}(s)=\sum_{a∈A}\pi(a|s)(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{\pi}(s')) vπ(s)=a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vπ(s′))
- https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
Optimal Value Function
-
The optimal state-value function v ∗ ( s ) v^{*}(s) v∗(s) is the maximum value function over all policies
v ∗ ( s ) = m a x π v π ( s ) v^{*}(s)=\underset{\pi}{max}\,v^{\pi}(s) v∗(s)=πmaxvπ(s) -
The optimal policy
π ∗ ( s ) = a r g m a x π v π ( s ) \pi^{*}(s)=arg\,\underset{\pi}{max}\,v^{\pi}(s) π∗(s)=argπmaxvπ(s) -
An MDP is “solved” when we know the optimal value
-
There exists a unique optimal value function, but could be multiple optimal policies (two actions that have the same optimal value function)
Finding Optimal Policy
-
An optimal policy can be found by maximizing over q ∗ ( s , a ) q^{*}(s,a) q∗(s,a),
π ∗ ( a ∣ s ) { 1 , if a = a r g m a x a ∈ A q ∗ ( s , a ) 0 , otherwise \pi^{*}(a|s)\begin{cases} 1, & \text{ if } a=arg\,max_{a\in A}\,q^{*}(s,a) \\ 0, & \text{ otherwise } \end{cases} π∗(a∣s){1,0, if a=argmaxa∈Aq∗(s,a) otherwise -
There is always a deterministic optimal policy for any MDP
-
If we know q ∗ ( s , a ) q^{*}(s,a) q∗(s,a), we immediately have the optimal policy
Policy Search
- One option is to enumerate search the best policy
- Number of deterministic policies is ∣ A ∣ ∣ S ∣ |A|^{|S|} ∣A∣∣S∣
- Other approaches such as policy iteration and value iteration are more efficient
MDP Control
-
Compute the optimal policy
π ∗ ( s ) = a r g m a x π v π ( s ) \pi^{*}(s)=arg\,\underset{\pi}{max}\,v^{\pi}(s) π∗(s)=argπmaxvπ(s) -
Optimal policy for a MDP in an infinite horizon problem (agent acts forever) is
- Deterministic
- Stationary (does not depend on time step)
- Unique? Not necessarily, may have state-actions with identical optimal values
Improving a Policy through Policy Iteration
-
Iterate through the two steps:
-
Evaluate the policy π \pi π (computing v given current π \pi π)
-
Improve the policy by acting greedily with respect to v π v^{\pi} vπ
π ′ = g r e e d y ( v π ) \pi'=greedy(v^{\pi}) π′=greedy(vπ)
-

Policy Improvement
-
Compute the state-action value of a policy π \pi π:
q π i ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v π i ( s ′ ) q^{\pi_{i}}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{\pi_{i}}(s') qπi(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)vπi(s′) -
Compute new policy π i + 1 \pi_{i+1} πi+1 for all s ∈ S s∈S s∈S following
π i + 1 ( s ) = a r g m a x a q π i ( s , a ) \pi_{i+1}(s)=arg\,\underset{a}{max}\,q^{\pi_{i}}(s,a) πi+1(s)=argamaxqπi(s,a)

Monotonic Improvement in Policy
-
Consider a deterministic policy a = π ( s ) a=\pi(s) a=π(s)
-
We improve the policy through
π ′ ( s ) = a r g m a x a q π ( s , a ) \pi'(s)=arg\,\underset{a}{max}\,q^{\pi}(s,a) π′(s)=argamaxqπ(s,a) -
This improves the value from any state s over one step,
q π ( s , π ′ ( s ) ) = m a x a ∈ A q π ( s , a ) ≥ q π ( s , π ( s ) ) = v π ( s ) q^{\pi}(s,\pi'(s))=\underset{a∈A}{max}\,q^{\pi}(s,a)≥q^{\pi}(s,\pi(s))=v^{\pi}(s) qπ(s,π′(s))=a∈Amaxqπ(s,a)≥qπ(s,π(s))=vπ(s) -
It therefore improves the value function, v π ′ ( s ) ≥ v π ( s ) v_{\pi'(s)}≥v^{\pi}(s) vπ′(s)≥vπ(s)
v π ( s ) ≤ q π ( s , π ′ ( s ) ) = E π ′ [ R t + 1 + γ v π ( S t + 1 ∣ S t = s ) ] v^{\pi}(s)≤q^{\pi}(s,\pi'(s))=E_{\pi'}[R_{t+1}+γv^{\pi}(S_{t+1}|S_{t}=s)] vπ(s)≤qπ(s,π′(s))=Eπ′[Rt+1+γvπ(St+1∣St=s)]
≤ E π ′ [ R t + 1 + γ q π ( S t + 1 , π ′ ( S t + 1 ) ) ∣ S t = s ) ] ≤E_{\pi'}[R_{t+1}+γq^{\pi}(S_{t+1},\pi'(S_{t+1}))|S_{t}=s)] ≤Eπ′[Rt+1+γqπ(St+1,π′(St+1))∣St=s)]
≤ E π ′ [ R t + 1 + γ R t + 2 + γ 2 q π ( S t + 2 , π ′ ( S t + 2 ) ) ∣ S t = s ) ] ≤E_{\pi'}[R_{t+1}+γR_{t+2}+γ^{2}q^{\pi}(S_{t+2},\pi'(S_{t+2}))|S_{t}=s)] ≤Eπ′[Rt+1+γRt+2+γ2qπ(St+2,π′(St+2))∣St=s)]
≤ E π ′ [ R t + 1 + γ R t + 2 + . . . ∣ S t = s ) ] = v π ′ ( s ) ≤E_{\pi'}[R_{t+1}+γR_{t+2}+...|S_{t}=s)]=v_{\pi'}(s) ≤Eπ′[Rt+1+γRt+2+...∣St=s)]=vπ′(s)
-
If iImprovements stop,
q π ( s , π ′ ( s ) ) = m a x a ∈ A q π ( s , a ) ≥ q π ( s , π ( s ) ) = v π ( s ) q^{\pi}(s,\pi'(s))=\underset{a∈A}{max}\,q^{\pi}(s,a)≥q^{\pi}(s,\pi(s))=v^{\pi}(s) qπ(s,π′(s))=a∈Amaxqπ(s,a)≥qπ(s,π(s))=vπ(s) -
Thus the Bellman optimality equation has been satisified
v π ( s ) = m a x a ∈ A q π ( s , a ) v^{\pi}(s)=\underset{a∈A}{max}\,q^{\pi}(s,a) vπ(s)=a∈Amaxqπ(s,a)
-
Therefore v π ( s ) = v ∗ ( s ) v^{\pi}(s)=v^{*}(s) vπ(s)=v∗(s) for all s ∈ S s∈S s∈S, so π \pi π is an optimal policy
Bellman Optimality Equation
1️⃣The optimal value functions are reached by the Bellman optimality equations:
v ∗ ( s ) = m a x a q π ( s , a ) v^{*}(s)=\underset{a}{max}\,q^{\pi}(s,a) v∗(s)=amaxqπ(s,a)
q ∗ ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v ∗ ( s ′ ) q^{*}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{*}(s') q∗(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)v∗(s′)
thus
v ∗ ( s ) = m a x a R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v ∗ ( s ′ ) v^{*}(s)=\underset{a}{max}R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{*}(s') v∗(s)=amaxR(s,a)+γs′∈S∑P(s′∣s,a)v∗(s′)
q ∗ ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) m a x a ′ q ∗ ( s ′ , a ′ ) q^{*}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)\,\underset{a'}{max}\,q^{*}(s',a') q∗(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)a′maxq∗(s′,a′)
Value Iteration by turning the Bellman Optimality Equation as update rule
1️⃣If we know the solution to subproblem v ∗ ( s ′ ) v^{*}(s') v∗(s′), which is optimal.
2️⃣Then the solution for the optimal v ∗ ( s ) v^{*}(s) v∗(s) can be found by iteration over the following Bellman Optimality backup rule,
v ( s ) ← m a x a ∈ A ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v ∗ ( s ′ ) ) v(s)\leftarrow\underset{a∈A}{max}(R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v^{*}(s')) v(s)←a∈Amax(R(s,a)+γs′∈S∑P(s′∣s,a)v∗(s′))
3️⃣The idea of value iteration is to apply these updates iteratively
Algorithm of Value Iteration
-
Objective: find the optimal policy π \pi π
-
Solution: iteration on the Bellman optimality backup
-
Value Iteration algorithm:
-
initialize k = 1 k=1 k=1 and v 0 ( s ) = 0 v_{0}(s)=0 v0(s)=0 for all states s
-
For k = 1 : H k=1:H k=1:H
-
for each states s
q k + 1 ( s , a ) = R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v k ( s ′ ) q_{k+1}(s,a)=R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v_{k}(s') qk+1(s,a)=R(s,a)+γs′∈S∑P(s′∣s,a)vk(s′)v k + 1 ( s ) = m a x a q k + 1 ( s , a ) v_{k+1}(s)=\underset{a}{max}\,q_{k+1}(s,a) vk+1(s)=amaxqk+1(s,a)
-
k ← k + 1 k\leftarrow k+1 k←k+1
-
-
To retrieve the optimal policy after value iteration:
π ( s ) = a r g m a x a R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v k + 1 ( s ′ ) \pi(s)=arg\,\underset{a}{max}\,R(s,a)+γ\sum_{s'∈S}P(s'|s,a)v_{k+1}(s') π(s)=argamaxR(s,a)+γs′∈S∑P(s′∣s,a)vk+1(s′)
-
Example: Shortest Path
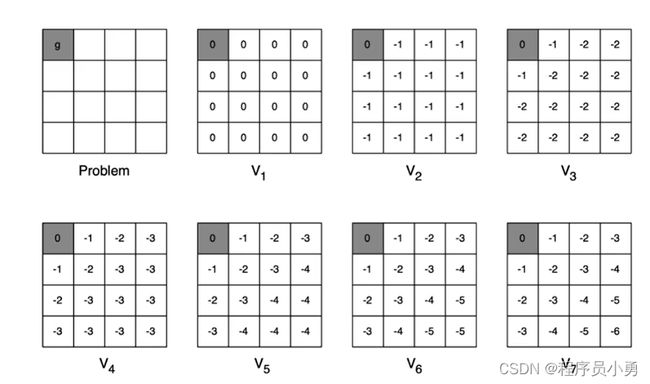
After the optimal values are reached, we run policy extraction to retrieve the optimal policy.
Demo of policy iteration and value Iteration

1️⃣Policy iteration: Iteration of policy evaluation and policy improvement(update)
2️⃣Value iteration
3️⃣https://cs.stanford.edu/people/karpathy/reinforcejs/gridworld_dp.html
Policy iteration and value iteration on FrozenLake
1️⃣https://github.com/cuhkrlcourse/RLexample/tree/master/MDP
Different between Policy Iteration and Value Iteration
1️⃣Policy iteration includes: policy evaluation + policy improvement, and the two are repeated iteratively until policy converges.
2️⃣Value Iteration includes: finding optimal value function + one policy extraction.There is no repeat of the two because once the value function is optimal, then the policy out of it should also be optimal (i.e. converged).
3️⃣Finding optimal value function can also be seen as a combination of policy improvement (due to max) and truncated policy evaluation (the reassignment of v(s) after just one sweep of all states regardless of convergence).
Summary for Prediction and Control in MDP

End
1️⃣Optional Homework 1 is available at https://github.com/cuhkrlcourse/ierg6130-assignment