点云 3D 目标跟踪 - SimTrack: Exploring Simple 3D Multi-Object Tracking for Autonomous Driving(ICCV 2021)
点云 3D 目标跟踪 - SimTrack(ICCV 2021)
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 方法
-
- 3.1 准备工作
- 3.2 概述
- 3.3 联合检测和跟踪
- 4. 实验
-
- 4.1 数据集
- 4.2 评估指标
- 4.3 实施细节
- 4.4 nuScene结果
- 4.5 消融研究
- 4.6 Waymo结果
- 5. 结论
- References
声明:此翻译仅为个人学习记录
文章信息
- 标题:Exploring Simple 3D Multi-Object Tracking for Autonomous Driving (ICCV 2021)
- 作者:Chenxu Luo, Xiaodong Yang1*, Alan Yuille
- 文章链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Luo_Exploring_Simple_3D_Multi-Object_Tracking_for_Autonomous_Driving_ICCV_2021_paper.pdf
- arxiv链接:https://arxiv.org/pdf/2108.10312.pdf
- 文章代码:https://github.com/qcraftai/simtrack
摘要
LiDAR点云中的3D多目标跟踪是自动驾驶车辆的关键组成部分。现有方法主要基于tracking-by-detection的管道,并且不可避免地需要用于检测关联的启发式匹配步骤。在本文中,我们提出了SimTrack,通过提出一个端到端可训练的模型来从原始点云进行联合检测和跟踪,从而简化了手工制作的跟踪范式。我们的关键设计是预测给定片段中每个目标的首次出现位置,以获得跟踪身份,然后基于运动估计更新位置。在推理中,启发式匹配步骤可以通过简单的读取操作完全放弃。SimTrack将跟踪目标关联、新生目标检测和废弃的轨迹消除集成在一个统一的模型中。我们对两个大型数据集进行了广泛的评估:nuScenes和Waymo Open Dataset。实验结果表明,在排除了启发式匹配规则的情况下,我们的简单方法与最先进的方法相比具有优势。
1. 引言
3D多目标跟踪是自动驾驶系统的关键组成部分,因为它提供关键信息,以促进从感知、预测到规划的各种车载模块。激光雷达是自动驾驶车辆感知周围环境最常用的传感器。因此,随着近年来自动驾驶车辆的快速发展,激光雷达点云跟踪一直吸引着越来越多的兴趣。
多目标跟踪是计算机视觉中的一项长期任务,在图像序列领域得到了广泛的研究。可以说,tracking-by-detection是最流行的跟踪范式,它首先检测每帧的目标,然后跨帧关联它们。这些方法已显示出有希望的结果,并受益于图像目标检测的巨大进步。他们通常将关联步骤公式化为二分匹配问题。因此,大多数现有工作集中于更好地定义跟踪目标和新检测之间的亲和矩阵。在匹配标准设计中,运动[2]和外观[32]被广泛采用作为关联线索。
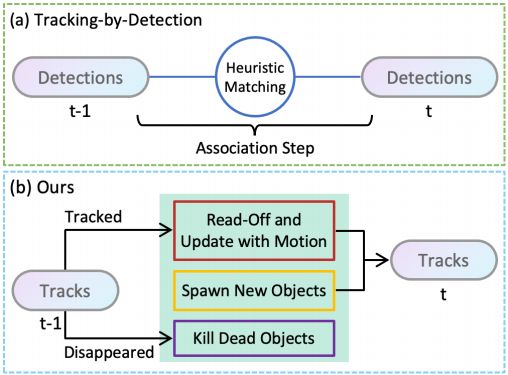
图1. tracking-by-detection的管道和我们方法的概述。(a) 在每个点云中执行3D目标检测,然后通过关联步骤匹配检测到的目标,该关联步骤涉及复杂的启发式规则。(b) 读取跟踪标识并使用估计的运动更新目标位置,同时管理新生和废弃的轨迹。我们的模型在一次前向传递中处理这三种情况,而不需要启发式匹配。
对于使用LiDAR的3D多目标跟踪,tracking-by-detection的管道也起着主导作用[6,27]。因此,为了获得最终的跟踪结果,当前的方法不可避免地需要启发式匹配步骤来在单独的阶段中随时间链接检测到的目标。在执行这样的步骤时,存在许多手工制定的规则。如补充材料中所比较的,每个特定目标类别的不同匹配标准和相应阈值实质上影响最终跟踪性能。这也发生在轨迹寿命管理中,用于处理新生目标和废弃的轨迹。对于这些方法来说,通常的做法是仅当目标连续出现一定数量的帧时才初始化轨迹,以过滤错误检测,并将消失的目标保留几帧以解决遮挡问题。不幸的是,所有这些启发式规则都是不可训练的,并且高度依赖于它们的超参数,需要付出巨大的努力来调整。更糟糕的是,这些规则和超参数通常依赖于数据和模型,因此在应用于新场景时很难进行类推和重新调整。
需要额外的启发式匹配步骤的主要原因是在进行目标检测时帧之间缺乏连接。最近,一些方法[18,31]在连续帧中估计速度或预测目标的位置,以提供跨帧的这种连接。然而,他们只是将预测的检测作为目标匹配的桥梁,而不是将其用作最终的跟踪输出。此外,它们只考虑帧之间目标的位置关系,而没有对关联的置信度进行建模。因此,置信度分数仅反映单个帧中的检测置信度。因此,这些方法往往容易出现虚假检测,并且必须手动决定要保留的帧数,以处理被遮挡的目标。另一个问题在于如何在在线跟踪系统中处理新生目标。现有方法[1,18]重新检测当前帧中的所有目标,以便仍然需要匹配来区分新生目标和跟踪目标。
鉴于上述观察,我们提出了SimTrack:一个用于点云中三维多目标跟踪的简单模型。我们简化了现有的手工跟踪算法,而不需要启发式匹配步骤。我们的方法可以灵活地建立在常用的基于柱或体素的3D目标检测网络上[9,36]。我们提出了一种新的混合时间中心图,它通过目标在给定输入周期内的首次出现位置来表示目标。基于该映射,我们可以将当前检测直接链接到先前跟踪的目标,而不需要额外的匹配。由于该映射同时表示目标的检测和关联,因此我们的模型能够固有地提供帧之间的关联置信度。此外,我们引入了一个运动更新分支来估计被跟踪目标的运动,以便从它们的首次出现位置更新到当前位置。对于新生目标和废弃的轨迹,它们可以简单地通过置信阈值作为同一图上的常规检测来确定,从而也消除了手动轨迹寿命管理。如图1所示,我们的模型消除了突发匹配步骤,并在一次前向传递中统一了跟踪目标链接、新生目标检测以及废弃的轨迹消除。
据我们所知,这项工作提供了第一个学习范式,能够摆脱点云中3D多目标跟踪的启发式匹配步骤,因此显著简化了整个跟踪系统。我们介绍了一种新的端到端可训练模型,用于通过混合时间中心图和运动更新分支进行联合检测和跟踪。实验结果表明,与现有方法相比,这种简单的方法更为有效。我们的代码和模型将提供在https://github.com/qcraftai/simtrack.
2. 相关工作
2D多目标跟踪。随着图像目标检测的不断进步[20,21,22,25],大多数方法遵循tracking-by-detection的管道,其首先检测各个帧的目标,然后随时间关联两组检测。我们可以将关联步骤分为两个主要组:基于运动的和基于外观的。基于运动的方法利用时间建模[30]来更新检测并实现距离或交并比度量(IOU)的的匹配。卡尔曼滤波器[8]被该组的方法广泛用于状态估计[2]。一些工作预测位置偏移以促进运动建模[7,18,34]。相反,基于外观的方法考虑序列中同一目标的视觉外观相关性。他们中的大多数应用重新识别[33,38]来驱动外观特征学习以建立身份对应[13,32]。
与仅将预测框作为匹配代理的基于运动的tracking-by-detection的管道方法不同,tracking-by-regression 范式通过将先前位置直接回归到当前帧中的新位置来执行跟踪。在[1]中,跟踪器从每个目标的过去位置开始,并从当前帧应用区域合并的目标检测特征以获得更新的位置。它依赖于额外的目标检测器来处理新生目标,并且必须更新多个感兴趣区域,并通过一些启发式规则将跟踪目标与新检测到的目标分离。相比之下,我们的方法可以在一次前向传递中直接生成被跟踪的和新生的目标,而无需启发式后处理。
最近,受Transformer[26]的成功启发,开发了几种方法,通过注意力操作进行联合检测和多目标跟踪。TrackFormer[16]采用跟踪查询嵌入以自回归的方式跟踪目标位置随时间的变化,并采用[4]中的目标查询来处理新生目标。TransTrack[23]采用查询关键字机制来检测当前帧中的目标,并通过学习的目标查询在帧之间关联它们。
3D多目标跟踪。在这一领域,主要的方法是利用tracking-by-detection的管道。由于点云中缺少外观和纹理线索,基于LiDAR的跟踪模型依赖于运动进行关联。AB3DMOT[27]将卡尔曼滤波器扩展到3D,用于运动状态估计。CenterPoint[31]通过添加速度回归头来估计每个目标的速度。FaF[15]通过预测关联目标。PnPNet[10]使用3D特征和轨迹学习目标之间的亲和矩阵。Chiu等人[5]将相机的外观特征距离纳入距离度量,以增强关联。它们中的大多数需要使用匈牙利算法或贪婪匹配算法的二分匹配步骤来获得最终的跟踪输出。
检测和运动。3D目标检测为3D多目标跟踪提供了基本工具。在[36]中,VoxelNet对[19]提取的体素特征应用3D卷积。SECOND[29]通过使用稀疏3D卷积来提高效率。CBGS[37]通过类平衡分组和抽样提高了准确性。PointPillars[9]被开发用于折叠高度维度,并使用2D卷积来实现更好的效率。同时,一些最近的方法[14,28]展示了使用自监督或从跟踪导出的代理运动监督进行点云柱运动估计的有希望的结果。
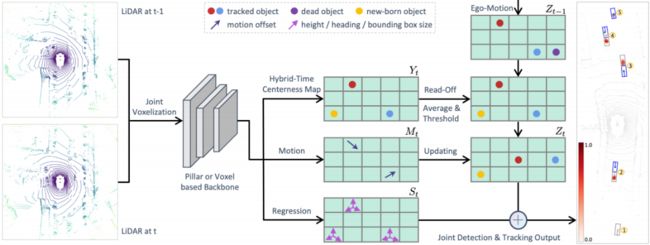
图2. SimTrack的示意图。我们的模型由一个混合时间中心映射分支组成,该分支检测输入片段中每个目标的首次出现位置,一个运动更新分支预测一个目标在周期内的运动,以及一个回归分支估计其他目标属性。在推断过程中,我们首先通过自我运动将先前更新的中心度图Zt−1转换为当前坐标系,并将其与当前混合时间中心度图Yt进行平均,然后对其进行阈值化以移除废弃的目标,然后读取Yt和Zt−1上共享相同单元的跟踪标识。之后,我们使用预测的运动将跟踪的目标更新到其当前位置,以获得Zt。我们显示了点云的放大区域,以说明检测和跟踪输出,其中灰色和蓝色框是在先前和当前扫描中检测到的目标。ID(1)是具有低置信度的废弃的目标。ID(2-4)是根据置信热图中的峰值正确定位的跟踪目标,并且它们的当前位置通过预测的运动准确更新。ID(5)是新生目标。
3. 方法
如图2所示,SimTrack将跟踪目标链接、新生目标检测和废弃的目标移除统一在一个端到端可训练模型中。我们排除启发式匹配步骤并实现期望的简化跟踪的关键设计基于所提出的混合时间中心图和运动更新分支。
3.1 准备工作
我们的方法利用3D目标的基于中心的表示。由于在这种表示下检测和跟踪之间的内在联系,轨迹可以被描述为由空间和时间点形成的路径。这里我们简要回顾了基于中心的3D目标检测。给定一个原始点云,我们首先使用柱[9]或体素[36]将其体素化为规则网格。我们通过小PointNet提取每个柱或体素的特征[19]。之后,使用标准2D或3D卷积来计算鸟瞰图(BEV)中的特征。对于检测头,我们通过其在中心度图上的中心位置来表示每个目标,类似于[31]。对于训练,围绕每个目标的中心创建二维高斯热图,以形成目标中心度图。检测头可以生成所有检测输出,包括中心度图、局部偏移、目标大小和航向。
3.2 概述
设Pt={(x,y,z,r)i}表示由时间t的坐标(x,y,z)和反射率r的测量值组成的无序点云。我们的模型将点云片段作为输入。为了简单起见,我们通过自我运动补偿将过去的扫描转换为当前坐标系,从而直接组合多个点云。作为一种常见的做法,我们还为每个点添加一个相对时间戳,以便将一个点表示为(x,y,z,r,∆t),其中∆t是当前扫描的相对时间戳。在体素化和特征提取之后,我们的检测头使用中心度图来检测输入片段中目标的首次出现位置,并估计该时间段内的目标运动。在推断中,我们只需从先前的中心度图中读取目标的跟踪标识,然后使用预测的运动将目标更新到其当前位置。
3.3 联合检测和跟踪
如上所述,为了消除启发式匹配和手动跟踪寿命管理,我们建议通过混合时间中心图和运动更新分支的组合在简化模型中执行联合检测和跟踪。
混合时间中心图。为了提供与先前检测的链接并同时检测新生目标,我们提出了一种混合时间中心图。具体而言,我们的模型以t−1和t处的两次连续激光雷达扫描作为输入。对于目标中心度图,我们通过每个目标的中心位置表示每个目标,该目标在输入序列中首次出现的位置。假设在帧t−1和t处的真值目标位置分别为 { d i t − 1 } i = 1 , ⋅ ⋅ , n t − 1 \{d^{t−1}_i\}_{i=1,··,n_{t−1}} {dit−1}i=1,⋅⋅,nt−1和 { d i t } i = 1 , ⋅ ⋅ , n t \{d^t_i\}_{i=1,··,n_t} {dit}i=1,⋅⋅,nt。我们的目标分配策略定义如下。
-
对于同时出现在t−1和t帧(表示为 d i t − 1 d^{t−1}_i dit−1和 d j t d^t_j djt)中的跟踪目标,我们在 d i t − 1 d^{t−1}_i dit−1处创建其目标热图,这是该目标在输入序列中的第一个出现位置。
-
对于仅在第一帧t−1中出现但在第二帧t中消失的废弃的目标,我们将其视为反面示例,不为该目标分配任何目标热图。
-
对于只出现在第二帧t中的新生目标,我们在 d i t d^t_i dit处创建其目标热图。
以这种方式,对于被跟踪的目标,我们可以通过从先前的时间戳中读取更新的中心度图(参见下面的详细信息)的同一位置处的身份来直接与其先前的检测相关联。对于废弃的目标,可以通过阈值化置信度分数来简单地去除它们。对于新生目标,我们在同一混合时间中心图上执行常规检测。因此,我们的混合时间中心图为在单个统一模型中合并跟踪目标关联、废弃的目标移除和新生目标检测奠定了基础。此外,我们可以利用从该混合时间中心图获得的置信度分数来暗示检测置信度(即,目标存在于当前时间戳中的概率)和关联置信度(例如,目标链接到其先前位置的概率)。
运动更新分支。如上所述,我们将每个跟踪目标链接到混合时间中心图上的先前位置,以建立身份对应关系。然而,要实现在线跟踪系统,我们需要进一步获取目标的当前位置。因此,我们引入了运动更新分支来估计两次扫描之间目标的偏移。实际上,对于每个目标,在第一帧的中心位置,我们将偏移量回归到其当前位置:(∆u,∆v)=(ut−ut−1,vt−vt−1),其中(u,v)是目标中心坐标。然后,我们利用这个运动场将混合时间中心图转换为更新的中心图。
我们注意到,一些先前的方法(如CenterPoint[31])也可以估计目标速度。然而,主要区别在于,他们只将运动视为进行匹配的助手。它们使用运动来传播当前帧的检测,并使用它们来与来自前一帧的检测相匹配。换句话说,传播的框仅用作跨帧匹配检测到的目标的桥梁,而不是用作最终跟踪结果。然而,SimTrack表明,我们的混合时间检测和运动估计可以结合起来产生跟踪输出,而不需要启发式匹配。此外,在推断过程中,CenterPoint需要手动调整特定于类的距离阈值,以确定运动导出的框是否可以与检测到的框匹配。相比之下,我们的模型显著简化了通过单个前向传递来获得检测和对应的跟踪管道。
其他回归分支。除了运动之外,我们回归了其他3D目标属性,包括高度z、边界框大小(w、l、h)和以(sinθ,cosθ)格式显示的头,其中θ是边界框的偏航角。
损失函数。在训练混合时间中心图时,我们采用类似[31,35]的焦点损失:
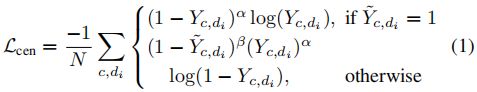
其中 Y ~ \tilde{Y} Y~和Y表示目标和预测的混合时间中心图,N表示目标的数量,α和β是焦点损失的超参数[11]。对于运动更新分支,我们执行标准l1损失:
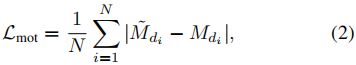
其中 M ~ \tilde{M} M~表示真值运动图,M表示预测运动图。同样,我们也使用其他回归分支的标准l1损失:

其中 S ~ \tilde{S} S~和S表示其他真值,以及目标高度、大小和航向的预测回归图。我们只在相应图上的中心位置di计算这些损失。总之,总目标是三个损失函数的加权和:
![]()
其中,ωcen、ωmot和ωreg是控制三个损失项重要性的平衡系数。
骨干网络。SimTrack可灵活构建在各种主干上。在实验中,我们主要使用PointPillars[9]作为基于支柱的主干,这是因为它对于上板部署的计算效率。为了与其他方法进行比较,我们还使用更精确和更大的VoxelNet[37]作为基于体素的主干进行评估。
在线推理。在推断过程中,更新的中心度图Z记录每个目标的跟踪身份、中心位置和置信度分数。并且跟踪标识被放置在目标中心位置。对于序列中的初始帧,我们的方法只接受一次扫描作为输入,并执行检测以初始化更新的中心度图Z0。对于后面的帧,模型将当前扫描和上一次扫描作为输入。使用自我运动将所有点云转换为当前车辆坐标系。
与依赖于启发式匹配步骤的现有方法相比,SimTrack使用简单的读取来建立关联。如图2所示,在时间t,我们首先使用自我运动将先前时间戳的更新中心度图Zt−1转换为当前坐标系。然后,我们用当前的混合时间中心图Yt对Zt−1进行平均。对于每个目标中心,如果在Zt−1上的相同位置存在现有的跟踪标识,则该目标被视为被跟踪目标并读取该跟踪标识。我们为每个其他目标中心初始化一个新轨迹。在我们的方法中,不需要专门处理废弃的目标,因为在对Yt取阈值时,它们可以被自然丢弃。然后,我们使用预测的运动图Mt将Yt更新为Zt,以获得跟踪目标的当前位置。我们总结了算法1中我们方法的推理概要。
4. 实验
在本节中,我们首先描述了我们的实验设置,包括数据集、评估指标和实现细节。然后提供各种消融研究和相关分析,以深入了解我们方法中的不同设计选择。我们报告了在两个基准上最先进方法的广泛比较。

4.1 数据集
我们在两个大型自动驾驶数据集上广泛评估了我们提出的方法:nuScenes[3]和Waymo开放数据集[24]。nuScenes包含1000个场景,每个场景大约20秒,点云由32线激光雷达捕捉。该数据集分为700、150和150个场景,分别用于训练、验证和测试。LiDAR的频率为20Hz,注释以2Hz提供。共有10个类用于检测,其中7个移动类用于跟踪评估。根据官方评估协议,我们将检测和跟踪范围设置为[51.2m,51.2m]×[51.2m、51.2m]。Waymo包含798个训练序列和202个验证序列,点云由5个LiDAR以10 Hz捕获。官方评估在[-75m,75m]×[-75m、75m]范围内进行,并将表现分为两个难度等级:LEVEL_1和LEVEL_2,前者评估的目标得超过5个点,后者包括至少一个点的目标。
4.2 评估指标
我们遵循两个基准定义的官方评估指标进行比较。nuScenes采用BEV中阈值为2m的中心距离,即距离真值2m以内的目标被认为是真正的。Waymo对车辆类别使用0.7的3D IOU。它将MOTA作为主要的评估指标,在每个时间戳处惩罚三种错误类型:错误报警(FP)、丢失目标(FN)和身份切换(IDS)。Waymo评估系统自动选择MOTA的最佳置信阈值。另一方面,nuScene使用AMOTA计算不同召回情况下的平均MOTA。我们还报告了对缺失检测导致的轨迹碎片进行计数的FRAGS。
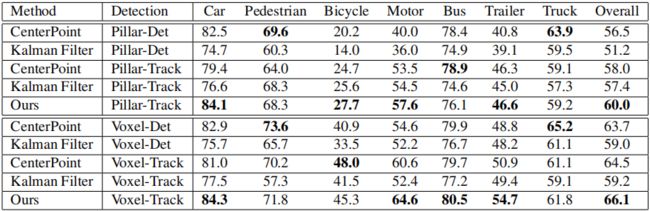
表1. 在nuScene的验证集上使用基于柱和体素的主干的不同检测模式的跟踪结果的比较。我们报告了AMOTA的总体和每个类别。

表2. nuScenes测试集的跟踪结果比较。*表示使用可变形卷积和测试时间增强。体素表示基于体素的主干,1024和1440表示特征图大小。
4.3 实施细节
我们在PyTorch[17]中基于CenterPoint[31]和Det3D[37]的代码库实现了我们的方法。我们在8个TITAN RTX GPU上训练我们的模型,每个GPU的批量大小分别为8个和4个,用于nuScenes和Waymo。每个模型在nuScenes上训练了20个epochs,在Waymo上训练了12个epochs。我们利用AdamW[12]作为优化器和单周期学习率调度。我们应用标准数据增强,包括全局旋转和缩放、沿X轴和Y轴翻转,以及从其他点云剪切和粘贴3D目标。
我们将方程(4)中的平衡系数(ωcen、ωmot、ωreg)设置为nuScenes的(1,1,0.25),Waymo的(1、1,1)。我们将我们的方法与卡尔曼滤波器和CenterPoint进行了广泛的比较,这两种方法主要用于三维多目标跟踪。我们用两种不同的主干(包括基于柱的主干和基于体素的主干)进行实验,以验证我们方法的可推广性。我们将柱大小设置为[0.2m,0.2m],体素大小设置为[0.1m,0.1m,0.2m]。注意,考虑到推理过程中的计算效率,我们没有使用更高的体素化分辨率。在创建目标混合时间中心图时,我们遵循[31]设置高斯热图半径。对于混合时间中心图的阈值,我们采用默认值0.1作为[31]中用于检测的值。注意,该阈值没有进一步调整以去除废弃的轨迹,因此不会引入额外的超参数。
4.4 nuScene结果
验证集。表1显示了验证集的跟踪比较。我们在AMOTA的总体和每个类别中报告结果。由于跟踪方法在很大程度上受检测性能的影响,为了更好地理解SimTrack,我们提供了两种类型的跟踪性能,基于(i)支柱/体素检测的检测结果:原始跟踪方法使用的定期训练的检测模型;以及(ii)支柱/体素追踪:我们的联合检测和追踪模型。
如表1所示,我们的方法在基于柱的主干上显著优于原始的CenterPoint和卡尔曼滤波器3.5%和8.8%,在基于体素的主干上分别优于2.4%和7.1%。通过使用我们方法的检测结果,可以提高CenterPoint和卡尔曼滤波器的跟踪性能。这是由于我们更好的检测和运动估计(详见消融研究),这得益于端到端耦合检测和跟踪训练。尽管如此,当他们使用我们的检测结果时,我们的方法仍然比他们两个都好约2%,这表明我们更好的跟踪性能不仅是由于更好的检测,而且是由于所提出的跟踪设计。
值得注意的是,CenterPoint的一组重要超参数是允许考虑匹配每个不同类别的最大距离阈值。CenterPoint根据验证集使用速度误差统计数据仔细选择阈值。其跟踪性能对所选阈值敏感。例如,如果汽车的阈值从4米变为1米,其AMOTA从82.5%降至81.0%,如果阈值限制放宽至10米,AMOTA进一步降至72.1%。相比之下,我们的方法完全摆脱了这种手动调整的阈值,因此在部署到新场景时更加稳健和方便。
测试集。我们将基于体素的模型的结果提交给nuScenes跟踪基准的测试服务器。对于本次提交,我们不使用任何测试时间增加。如表2所示,我们的方法没有铃和哨声,优于增强型CenterPoint,后者配备了可变形卷积和测试时间增强。特别是对于自动驾驶中最重要的汽车类,我们的汽车类将IDS和FRAGS从315和296降低到214和186。

表3. nuScenes验证集的一组消融研究。
4.5 消融研究
遮挡分析。能够处理遮挡是3D多目标跟踪中的挑战之一,因为目标可以在点云中部分或完全遮挡一段时间。一种常见的做法是在一定数量的帧中保持废弃的轨迹,并通过假设恒定速度模式来更新它们的位置。我们观察到,这一启发式规则对IDS产生了重大影响,例如,如果废弃的目标在CenterPoint中未保留一定的预定义时间,IDS将从238恶化到500。相比之下,SimTrack通过结合先前更新的中心度图上的置信度得分并使用估计的运动进行更新,来隐式地处理遮挡。如果一个目标在当前帧中被遮挡,但在前一帧中有很强的线索,我们的方法能够保持该目标并推测其当前位置。图3显示了一个示例,橙色的汽车被严重遮挡了几帧。我们的模型可以成功地跟踪这辆车,而CenterPoint无法与原始身份相关联。另一个例子表明,由于行人等小目标的速度估计很困难,CenterPoint估计的速度不准确会导致身份转换。我们的方法也能更好地处理此类案件。
统一或分离图。在这里,我们证明了在统一图上进行跟踪目标关联和新生目标检测可以获得更好的性能。我们还实现了一个使用分离图进行跟踪和检测的模型。具体来说,我们通过为每个类提供两个通道来修改混合时间中心图,一个用于跟踪目标,另一个用于新生目标。目标分配策略保持不变。表3a将两种设计与基于支柱的主干进行了比较。研究发现,使用分离的图比使用统一的图效果差得多。我们假设这是由于两幅图之间的极度不平衡造成的。对于正常场景,新生目标只占所有目标的一小部分,因此训练很困难。
组合图。如算法1所述,当前混合时间中心图与先前更新的中心图进行平均。在表3c中,我们将这种组合设计与仅使用当前混合时间中心图的备选方案进行了比较。通过组合这两个图,总体和每类结果都得到了一致和显著的改善。这种简单的平均操作提供了有效的时间融合,特别是对于解决如上所述的遮挡至关重要。
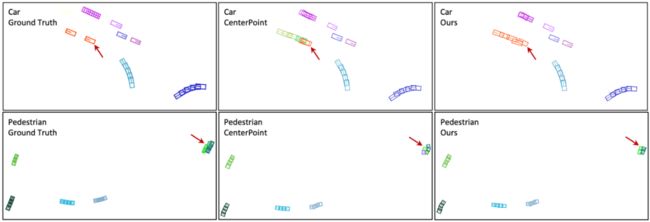
图3. nuScene验证集的定性跟踪结果比较。随着时间的推移,每种颜色都会对目标标识进行编码。注意,由于遮挡,真值不提供橙色汽车的注释。

表4. Waymo验证集的车辆跟踪性能比较。我们使用基于支柱的主干报告跟踪结果,数字的格式为LEVEL_1/LEVEL_2。
分辨率。接下来,我们表明,通过简单地提高中心度图分辨率,可以大大提高我们方法的性能,这对于行人和摩托车等小目标尤其有效。在原始骨干网络中,我们将支柱大小设置为[0.2m,0.2m],下采样率设置为4,这意味着在中心度图上,每个单元的大小为[0.8m,0.8m]。为了提高分辨率,我们保持编码器的完整性,但只修改解码器中的上采样层,将下采样率更改为2。表3d显示了两个小目标类别(行人和摩托车)的总体跟踪性能和具体结果。与较低分辨率相比,使用较高分辨率显著提高了两类的跟踪性能。
速度估计。除了跟踪之外,我们还表明,我们的方法可以为运动目标产生更精确的速度。我们采用mAVE(nuScenes正式定义的度量)来测量不同召回率下真实阳性的速度估计误差。表3b报告了具有基于柱和基于体素主干的所有类的mAVE。我们将模型与基于CenterPoint的基线进行比较。对于基于支柱的主干,我们的方法将速度误差降低了33%,特别是对于摩托车,速度误差大大降低了61%。它清楚地验证了我们的联合端到端训练的检测和跟踪模型可以更好地利用移动目标的动态。这种改进的速度估计对于诸如轨迹预测和运动规划之类的各种下游任务可能是有益的。
4.6 Waymo结果
这里我们比较验证集上车辆类别的跟踪结果。在本实验中,考虑到低延迟,我们还使用了基于支柱的主干。如表4所示,与Waymo提供的基线方法相比,我们的模型提供了明显的性能增益。与CenterPoint相比,我们的方法在不同的指标下获得了更好的或同等的结果。由于nuScenes和Waymo具有不同的LiDAR和评估指标,我们对两个数据集的一致改进共同验证了SimTrack的通用性。更重要的是,我们在不需要竞争算法通常使用的启发式匹配和复杂的跟踪寿命管理的情况下获得了优异的结果。
5. 结论
在本文中,我们提出了SimTrack,这是一种用于LiDAR点云中的3D多目标跟踪的端到端可训练模型。我们的方法迈出了简化现有手工跟踪管道的第一步,这些管道涉及复杂的启发式匹配和手动跟踪寿命管理。通过将所提出的混合时间中心图和运动更新分支相结合,我们的设计在单个统一模型中无缝集成了跟踪目标关联、新生目标检测和废弃的目标移除。广泛的实验结果证明了我们方法的有效性。我们希望这项工作能够激励更多的研究,以实现简单、鲁棒的自动驾驶跟踪系统。
References
[1] Philipp Bergmann, Tim Meinhardt, and Laura Leal-Taixe. Tracking without bells and whistles. In ICCV, 2019.
[2] Alex Bewley, Zongyuan Ge, Lionel Ott, Fabio Ramos, and Ben Upcroft. Simple online and realtime tracking. In ICIP, 2016.
[3] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuScenes: A multimodal dataset for autonomous driving. In CVPR, 2020.
[4] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with Transformers. In ECCV, 2020.
[5] Hsu-kuang Chiu, Jie Li, Rares Ambrus, and Jeannette Bohg. Probabilistic 3D multi-modal, multi-object tracking for autonomous driving. In ICRA, 2021.
[6] Hsu-kuang Chiu, Antonio Prioletti, Jie Li, and Jeannette Bohg. Probabilistic 3D multi-object tracking for autonomous driving. arXiv:2001.05673, 2020.
[7] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Detect to track and track to detect. In ICCV, 2017.
[8] Rudolph Kalman. A new approach to linear filtering and prediction problems. Journal of Basic Engineering, 1960.
[9] Alex H Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. PointPillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
[10] Ming Liang, Bin Yang, Wenyuan Zeng, Yun Chen, Rui Hu, Sergio Casas, and Raquel Urtasun. PnPNet: End-to-end perception and prediction with tracking in the loop. In CVPR, 2020.
[11] Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. In ICCV, 2017.
[12] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In ICLR, 2019.
[13] Zhichao Lu, Vivek Rathod, Ronny Votel, and Jonathan Huang. RetinaTrack: Online single stage joint detection and tracking. In CVPR, 2020.
[14] Chenxu Luo, Xiaodong Yang, and Alan Yuille. Self-supervised pillar motion learning for autonomous driving. In CVPR, 2021.
[15] Wenjie Luo, Bin Yang, and Raquel Urtasun. Fast and furious: Real time end-to-end 3D detection, tracking and motion forecasting with a single convolutional net. In CVPR, 2018.
[16] Tim Meinhardt, Alexander Kirillov, Laura Leal-Taixe, and Christoph Feichtenhofer. TrackFormer: Multi-object tracking with Transformers. arXiv:2101.02702, 2021.
[17] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An imperative style, high-performance deep learning library. In NeurIPS, 2019.
[18] Jinlong Peng, Changan Wang, Fangbin Wan, Yang Wu, Yabiao Wang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Yanwei Fu. Chained-Tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In ECCV, 2020.
[19] Charles Qi, Hao Su, Kaichun Mo, and Leonidas Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. In CVPR, 2017.
[20] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster R-CNN: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
[21] Zhongzheng Ren, Zhiding Yu, Xiaodong Yang, Ming-Yu Liu, Yong Jae Lee, Alexander Schwing, and Jan Kautz. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In CVPR, 2020.
[22] Zhongzheng Ren, Zhiding Yu, Xiaodong Yang, Ming-Yu Liu, Alexander Schwing, and Jan Kautz. UFO2: A unified framework towards omni-supervised object detection. In ECCV, 2020.
[23] Peize Sun, Yi Jiang, Rufeng Zhang, Enze Xie, Jinkun Cao, Xinting Hu, Tao Kong, Zehuan Yuan, Changhu Wang, and Ping Luo. TransTrack: Multiple-object tracking with Transformer. arXiv:2012.15460, 2020.
[24] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. In CVPR, 2020.
[25] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: Fully convolutional one-stage object detection. In ICCV, 2019.
[26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
[27] Xinshuo Weng, Jianren Wang, David Held, and Kris Kitani. 3D multi-object tracking: A baseline and new evaluation metrics. In IROS, 2020.
[28] Pengxiang Wu, Siheng Chen, and Dimitris N Metaxas. MotionNet: Joint perception and motion prediction for autonomous driving based on bird’s eye view maps. In CVPR, 2020.
[29] Yan Yan, Yuxing Mao, and Bo Li. SECOND: Sparsely embedded convolutional detection. Sensors, 2018.
[30] Xiaodong Yang, Pavlo Molchanov, and Jan Kautz. Making convolutional networks recurrent for visual sequence learning. In CVPR, 2018.
[31] Tianwei Yin, Xingyi Zhou, and Philipp Kr¨ahenb¨uhl. Center-based 3D object detection and tracking. In CVPR, 2021.
[32] Yifu Zhan, Chunyu Wang, Xinggang Wang, Wenjun Zeng, and Wenyu Liu. FairMOT: On the fairness of detection and re-identification in multiple object tracking. arXiv:2004.01888, 2020.
[33] Zhedong Zheng, Xiaodong Yang, Zhiding Yu, Liang Zheng, Yi Yang, and Jan Kautz. Joint discriminative and generative learning for person re-identification. In CVPR, 2019.
[34] Xingyi Zhou, Vladlen Koltun, and Philipp Kr¨ahenb¨uhl. Tracking objects as points. In ECCV, 2020.
[35] Xingyi Zhou, Dequan Wang, and Philipp Kr¨ahenb¨uhl. Objects as points. arXiv:1904.07850, 2019.
[36] Yin Zhou and Oncel Tuzel. VoxelNet: End-to-end learning for point cloud based 3D object detection. In CVPR, 2018.
[37] Benjin Zhu, Zhengkai Jiang, Xiangxin Zhou, Zeming Li, and Gang Yu. Class-balanced grouping and sampling for point cloud 3D object detection. arXiv:1908.09492, 2019.
[38] Yang Zou, Xiaodong Yang, Zhiding Yu, Vijaya Kumar, and Jan Kautz. Joint disentangling and adaptation for crossdomain person re-identification. In ECCV, 2020.