OpenCV学习笔记11-Tesseract-OCR的安装和使用
目录
1 OCR介绍
2 Tesseract-OCR工具介绍
3 Tesseract-OCR安装
4 环境变量配置
5 验证环境变量是否配置成功
6 使用方法
这篇博客我写了好久好久,而且走了好多坑,为避免其他学习的人少踩坑,自认为是良心写作,希望广大阅读者喜欢!
1 OCR介绍
光学字符识别(Optical Character Recognition)简称为“OCR”。ORC是指对包含文本资料的图像文件进行分析识别处理,获取文字及版面信息的技术。
光学字符识别是通过图像处理和模式识别技术对光学的字符进行识别的意思,是自动识别技术研究和应用领域中的一个重要方面,它是一种能够将文字自动识别录入到电脑中的软件技术,是与扫描仪配套的主要软件,属于非键盘输入范畴需要图像输入设备主要是扫描仪相配合。
使用OCR技术它快速高效地实现信息采集录入,不再需要浪费人力来进行录入登记、也不用花费众多的物理,它在节省时间成本大幅度提高工作效率的同时也颠覆了传统的工作模式,为社会各行各业向信息化迈进贡献力量。
2 Tesseract-OCR工具介绍
Tesseract-OCR 是一款由HP实验室开发由Google维护的开源OCR(Optical Character Recognition , 光学字符识别)引擎。
- 目前,Tesseract可以识别超过100种语言。也可以用来训练其它的语言。
- 源码包提供了一个OCR的引擎——libtesseract 以及一个命令行程序——tesseract.exe。
- Tesseract 支持多种输出格式,如:普通文本、html、pdf 等。
github下载地址:https://github.com/tesseract-ocr/tesseract
安装包百度网盘下载链接:https://pan.baidu.com/s/1eEP3J0uSRSB4dMgac8G2Qw
提取码:0rda
3 Tesseract-OCR安装
在下载好安装包后,双击点开,然后一直下一步。




到了这个界面时,用红色圈出来的一栏是额外的语言包支持,默认是英文,可以选择自己想要的语言包来下载,也可以全部下载。
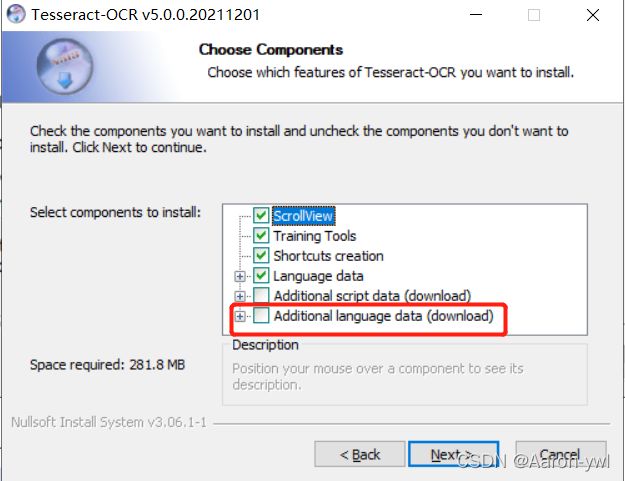
我选择了简体中文。

安装路径默认是: C:\Program Files\Tesseract-OCR,根据自己想要安装路径调整就好(不要有中文!!!)。

最后一步: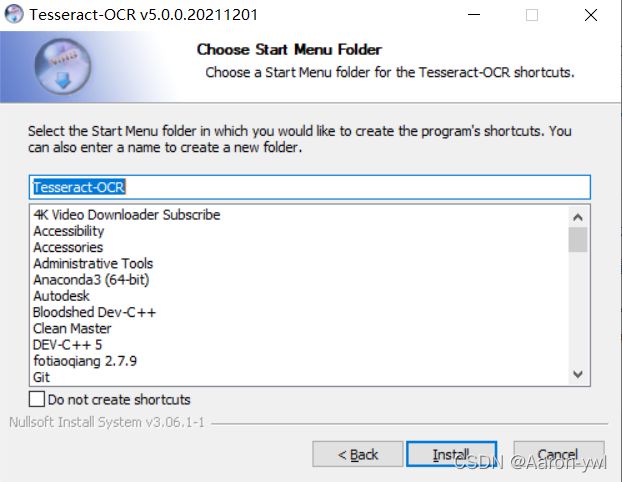
如果出现以下情况意味着语言包安装失败了,因为Tesseract-OCR是国外的资源包,如果下载失败的话就需要了。不过不用担心,我这里有已经下载好了的语言包,不过只有简体中文的。
链接:https://pan.baidu.com/s/1OTJXV26zqv_d6akhjThz8w
提取码:22gy
找到安装目录下的tessdata,替换一下就好了。

4 环境变量配置
我们安装好后,配置一下环境变量。打开此电脑/属性/高级系统设置,然后找到环境变量

在系统变量找到Path,然后新建一栏,增加Tesseract-OCR的路径。
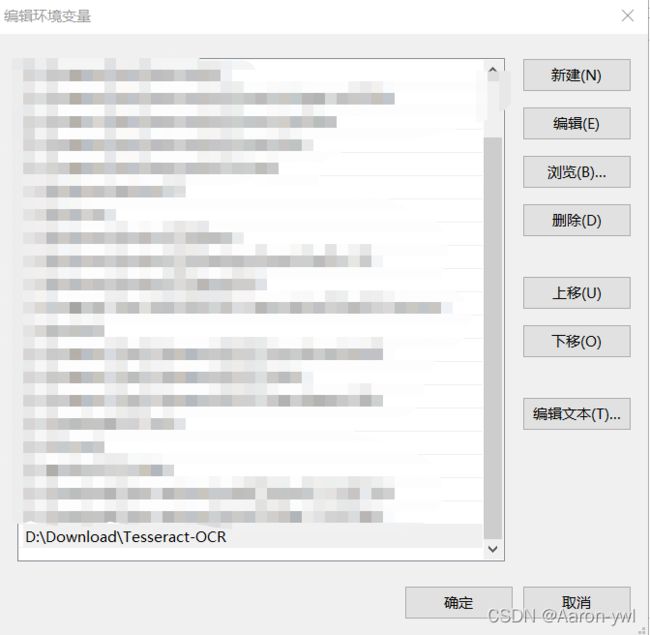
如果不知道路径怎么填的知道找到安装途径,找到自己的Tesseract-OCR,复制上方路径。![]()
然后在系统变量里再新增一栏环境变量,找到tessdata,添加进来。

最后就差不多啦!然后就去验证一下环境变量是否配置成功!
5 验证环境变量是否配置成功
同时按下Win+R, 输入cmd启动命令提示符。
弹出来的命令提示符输入tesseract,如果显示以下提示,说明环境变量配置成功的!
 我们还可以输入tesseract --version和tesseract --list-langs来查看Tesseract-OCR的版本和语言包。
我们还可以输入tesseract --version和tesseract --list-langs来查看Tesseract-OCR的版本和语言包。
其中chi_sim是中文,eng是英文。如果要同时使用中英文,就在两个语言包之间加上“+”即可。例如:chi_sim+eng
我们还可以输入tesseract --help-extra来查看检索的模式。

其中Page segmentation modes(简写psm)代表页面分割模式,用的最多的是7,8,11等等;
code function
0 只做方向和脚本的检测 (OSD)。
1 使用OSD自动分割。
2 自动分割,但不是用OSD或OCR。
3 完全自动分割,但不是用OSD。(缺省情况)
4 假定是可变大小的单列文本。
5 假定是个包含垂直对齐文本的整齐的块。
6 假定是个整齐的块。
7 把图像视为一行文字。
8 把图像视为单个单词。
9 将图像视为圆圈中的单个单词。
10 把图像视为单个字符。
11 稀疏文字,找到尽可能多的文本,不以特定的顺序。
12 稀疏文字,利用OSD处理。
13 原生线,通过传递Tesseract特殊的信息把图像视为单一的文本行。
OCR Engine modes(简写oem)代表OCR引擎模式:
· 0代表只使用传统引擎,不好用。
· 1代表只使用循环神经网络中LSTM网络,效果最好!。
· 2代表传统引擎+LSTM网络结合,效果比1差一点点!
· 3代表默认,有哪个用哪个。
如果要选择psm中的第8个模式,oem中的第1个模式,我们可以这样选择:-- psm 8 -- oem 1
6 使用方法
tesseract 要识别的图片 输出的文件 -l 使用的语言包
输出的文件格式默认是txt。
我们来测试一下效果如何,我准备了一张图片,里面有如下文字:
在当前图片目录下输入以下命令:
tesseract test.png out -l chi_sim+eng或者使用以下命令:
tesseract.exe test.png out -l chi_sim+eng执行完毕后,会生成一个txt文件:![]()
打开看看: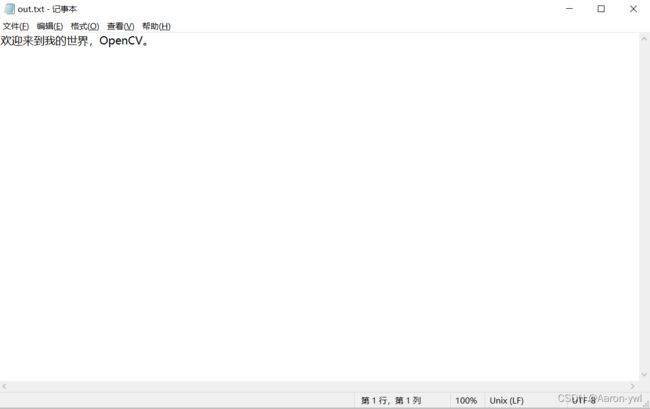 很不错!中英文都识别出来啦。
很不错!中英文都识别出来啦。
这是直接通过Tesseract-OCR来识别文字的,但是开发者更喜欢通过python接口来识别文字,那么我们下一篇来介绍学习如何通过python接口来调用api来识别文字。
而且重点是在实际生活中,我们拿到的图片或者拍到的图片并不是整整齐齐的,就是不是我们想象中的那么完美,我们还要通过对图片进行预处理,最后才识别!尽请期待吧!!!
附OpenCV目录:OpenCV学习笔记总目录汇总_Aaron-ywl的博客-CSDN博客
智科专业小白,写博文不容易,如果喜欢的话可以点个赞哦!
