linux oops 自动重启,Linux 死机复位(oops、panic)问题定位指南
一个计算机系统和一个人类社会其实是差不多的,系统在运行中碰到的各种bug相当于人类社会中的各种案件:user space发生的bug危害性一般,可能就相当于一般的民事案件;kernel层面发生bug引起系统死机复位,属于性质特别恶劣后果特别严重的刑事案件。
既然bug相当于案件,那么我们定位bug的过程和破案是差不多的。一般过程如下:
1. 首先我们要保留案发现场。
只要bug发生的时候cpu还能执行,大部分的软件bug最后都会落入到cpu的陷阱之中。arm准备了3大陷阱来捕获最后的案发现场:undefine instruction、prefetch abort、data abort。不管程序前面发生了什么错误,最后的出错都会掉到这3大陷阱中去。类似人类社会中最后看到了刑事案件,大家会拨打110报警。
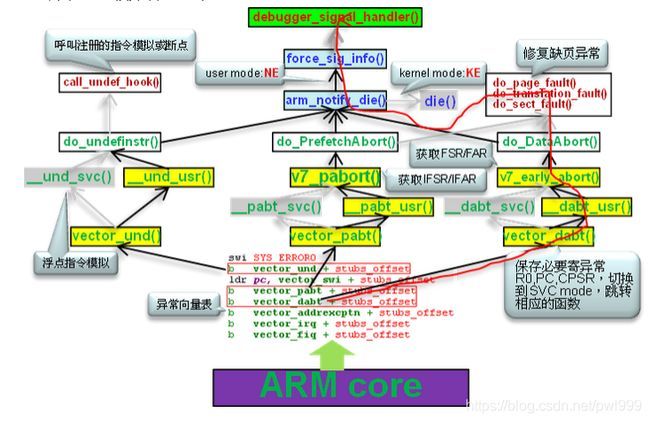
内核态的代码,只要掉入到了这3大陷阱之中,最后的结果都会触发oops然后panic()复位重启系统。在oops信息中,会打出bug的pc指针、cpu r0-r15寄存器和堆栈信息等最后的案发现场信息。
1.1 oops信息详解:
这里使用“echo “1 2” > /proc/aed/generate-oops”在mtk平台上生成一个kernel NULL pointer类型的oops,来阐释oops信息。
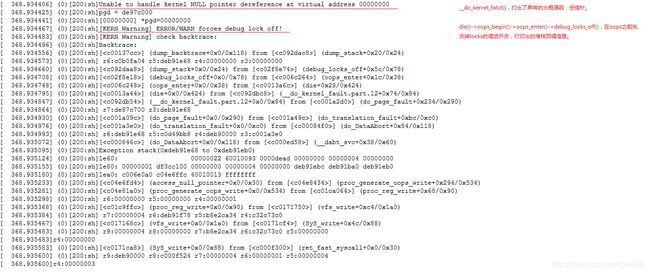
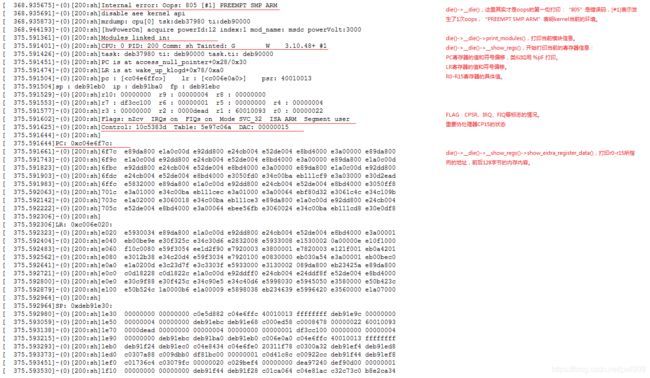
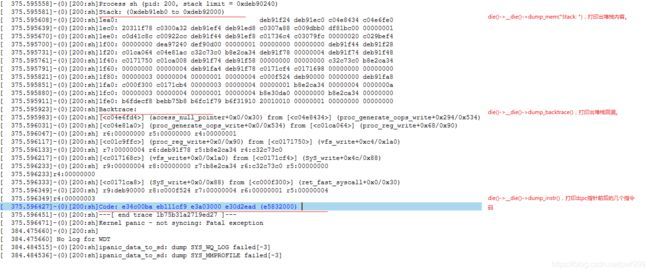
从上图的解析,通过oops的信息我们可以得到几个重要数据:最后出错的PC指针、函数调用关系、r0-r15寄存器的值、r0-r15指向内存的值、一些重要标志。
当然因为一些软件错误(踩堆栈)、硬件错误(内存跳变),我们最后得到的oops信息其中一项或者几项是已经出错没有了参考价值的,我们需要利用信息之间的相互关系来排插出更多的线索。
1.2 从oops信息反查源代码:
我们从oops信息中得到最后的pc值和符号信息,最终的目的还是需要和源代码联系起来。有以下方法:
(1)、addr2line:
arm-linux-androideabi-addr2line -e vmlinux addr,会打印出addr对应的源代码行号。


上图通过addr2line工具,找到最后的异常PC指针0xc04e6ffc对应源代码ade-debug.c文件的252行。
(2)、gdb:
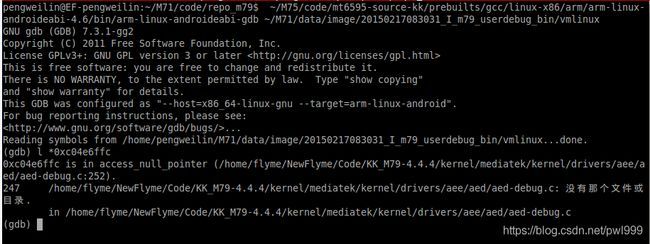
上图通过gdb的命令“l *0xc04e6ffc”实现addr2line命令同样的功能,找到对应源代码的位置ade-debug.c文件的252行。
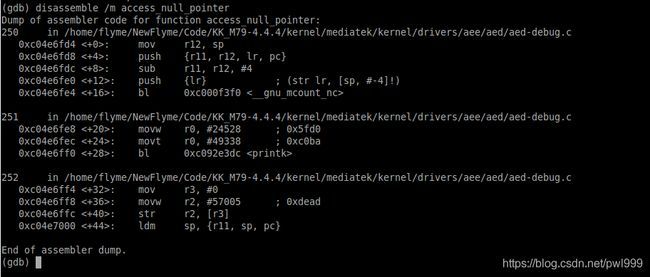
有时我们需要研究汇编代码,可以使用gdb的命令“disassemble /m access_null_pointer”来查看pc所在函数access_null_pointer()的汇编代码,/m 选项是同时打印出源码行号。
(3)、objdump:
查看汇编源代码,也可以使用objdump命令来实现。

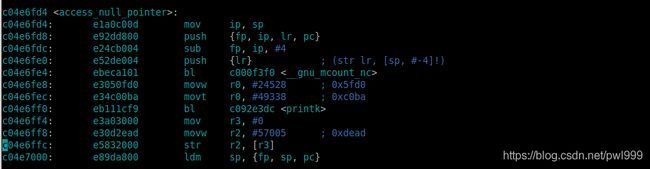
上图通过“objdump -S vmlinux > kernel.s ”命令生成kernel对应汇编文件,然后再汇编文件中根据pc地址0xc04e6ffc找到相应的位置。
1.3 Backtrace堆栈回溯原理:
在oops信息中,我们可以看到内核调用dump_backtrace()函数打印出堆栈调用关系。这其中的原理是什么样的呢?

上图可以看到arm c语言到汇编语言转换的实际过程,可以看到在每一层函数调用的过程中,arm使用了fp指针来记录这一层的堆栈顶部,而且堆栈中固定位置都有保存上一级的fp指针。具体的堆栈示意图如下:
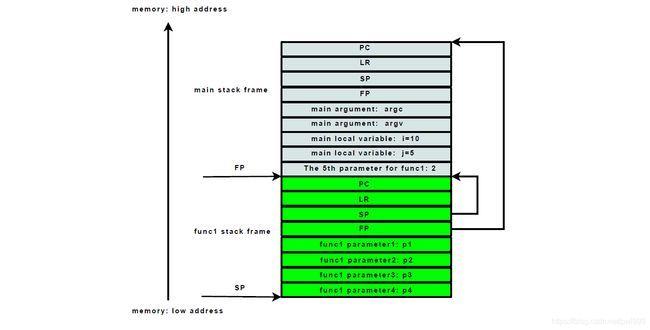
所以我们只需要找到这一层次的fp指针,就能一层层的找到函数回调的关系。对应上个oops例子,我们可以手工的来回溯。
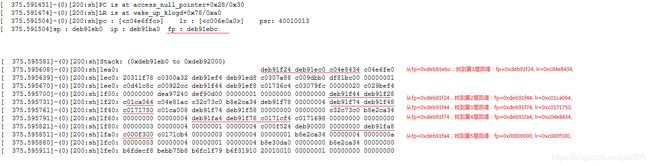
可以看到,我们手工计算的调用关系和调用dump_backtarce()打印出来的能一一对应上:

当然,在堆栈被破坏的情况下,这种方法就不适用了,这时候我们只能查看stack残存的数据,看看哪些是code信息,来推断猜测回调关系。
1.4 陷阱异常定位思路:
oops信息可以初步定位一些陷阱bug,比如我们检视代码在最后bug pc附近就发现了软件逻辑错误,那么我们很快就找到了bug的根因。
但是综上,陷阱异常提供了oops信息,信息只是线索不是定罪的证据。那么我们拿到这些线索以后,有可能能找到问题的元凶,有可能还需要要更多的分析手段。
陷阱异常定位思路 :
步骤
信息
行动
next
step1
PC指针信息OK,根据PC指针找到源代码对应的位置
观察源代码位置前后的逻辑,推导是否有符合最后错误的情况发生。
如果这一步的信息不能定位到bug根因,继续往下一步走。
step1
PC指针信息无效
根据出错的场景步骤,尝试复现bug,并往硬件错误方向尝试定位
step2
堆栈回调信息ok
分析堆栈调用链上的逻辑,分析可能产生的bug符合最后的错误情况。
如果这一步的信息不能定位到bug根因,继续往下一步走。
step2
堆栈回调信息无效
step3
反汇编代码
反汇编出错位置的代码,分析汇编代码的前后关系,来尝试推断,故障是软件造成的,还是硬件造成的
如果这一步的信息不能定位到bug根因,继续往下一步走。
step4
分析bug的前后log
分析bug发生前的kernel log,重点关注err、fail等关键字打印,分析推导是否有这些出错引起了后面的重启bug
如果这一步的信息不能定位到bug根因,继续往下一步走。
step5
更多的定位手段1 - 专项监测手段
step6
更多的定位手段2 – 更多的现场信息。
step7
硬件traceponit来监控被破坏内存地址的修改
追踪是哪个模块修改了内存
step8
最后的定位大法:复现和排除 先复现,
再来一个一个因素的排除,直到故障不出现,那么bug的相关因素就会被排除出来。
2. 更多的定位手段1 - 专项监测手段。
bug都会落入到arm的3大陷阱中去,我们能得到最后的故障现象信息。但是仅仅只是一份案发现场,我们其实很难分析出起始的案发原因,因为第一步可能只是一个小小的错误,经过多层次的反复累加,最后才酿成了刑事案件。
bug是有帮助的,比如我们检视代码在最后bug pc附近就发现了软件逻辑错误,那么我们很快就找到了bug的根因。
bug,最后现场的信息室远远不够的,我们需要更多的监测手段,在故障到达最后的陷阱之前,就能监控到它已经出错,至少能缩小定位的范围。比如我们人类公安对社会的监控:在主要街道设置了监控头,在汽车站、火车站、高速站、飞机场都有监控,在银行、互联网、电话都有监控,对于不对的苗头在发展成刑事案件之前都能监控捕捉到。
2.1 专项检测手段:
系统也是一样,我们设置了很多的专项监测措施来监控各个子系统,力图早点发现bug,缩小定位范围。例如:
(1)、我们在代码运行之前做代码静态扫描,相当于人类社会的基因扫描,在运行之前先剔除有问题的基因。
(2)、在运行中用”lockdep”检测可能的死锁问题,报出死锁方面的详细信息。
(3)、在运行中用”stack protect”检测可能的堆栈溢出问题,报出溢出方面的详细信息。
(4)、在运行中用”huang task detector”检测可能的任务hung死问题,报出hung死详细信息。
(5)、在运行中用”kmem leak detector”检测可能的内存泄露问题,报出kmem泄露的详细信息。
(6)、在运行中还有smp_process_id、schedule、sleep、irq、spinlock、mutex、rt-mutex、workqueue等都有各自模块的检测手段,这些检测手段检测到问题都会及时报出,提前了问题保留的时间、缩小了问题定位范围。
2.2 BUG()宏的实现原理:
除了代码逻辑错误在出错的时候会掉入arm的陷阱异常,动态检测手段检测到逻辑出错后,会调用BUG()这个宏来主动触发陷阱异常,以此来报告错误。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-spQBjxVI-1592915928346)(images/stability/BUG.png)]
3. 更多的定位手段2 – 更多的现场信息。
oops打印出来的现场信息过少,有一种思路是抓取更多的现场信息,例如coredump。
产生kernel coredump的方法:
mtk aee系统在panic的时候,会调用ipanic_mrdump_mini()创建一个mini coredump文件,就是我们在解压开aee目录后看到的SYS_MINI_RDUMP文件。这个记录的信息比较少,但是在wdt复位时拿来看每个cpu的堆栈非常方便。
调试coredump的方法:
可以使用gdb来调试coredump文件,命令格式为:gdb vmlinux coredumpfile
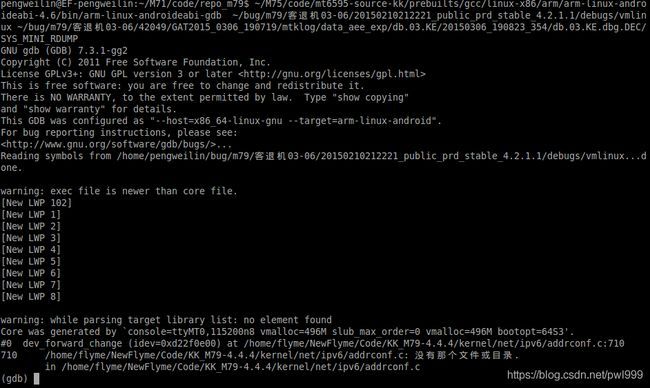
启动以后是一个多进程的调试环境,每个进程对应一个cpu,LWP1xx是出错时的CPU,LWP1-LWP8对应CPU0-CPU7。
使用命令info threads查看当前所有进程:
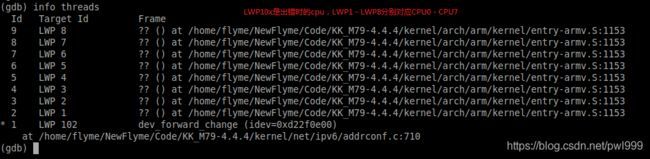
使用thread Id来切换当前调试的进程:

使用bt命令来查看当前进程的堆栈回调:
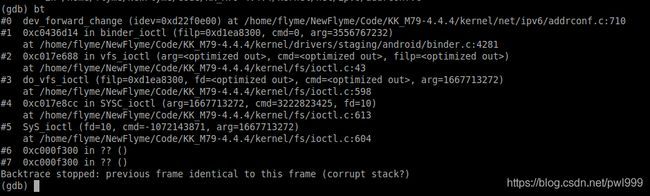
oops临终现场一样,得到更多的最后现场,不一定就能推断出bug的起始原因。更多信息只能给我们破案提供更多的线索,不能保证找到错误的根因。
4. 没有掉入陷阱的错误检测手段 - WDT。
arm的3大陷阱之中,还有一种不会落入陷阱的情况:cpu在运行,但是系统已经挂死。这种情况叫hang住,通常是代码中出现了死循环,或者是因为死锁系统产生了死循环。还有一种hang住,就是硬件的hang住,访问硬件出错造成cpu停止运行挂死。
WDT监控对于MTK 平台来说, 大体的做法是每一个cpu core 对应一个Watchdog Thread [wdtk-X], 周期性(20s)的去写RGU register, 而RGU register 的timeout 时间是30s, 即如果出现一个core 的watchdog thread 没有按时踢狗, 那么就会触发一个timeout 的FIQ, 产生一个KE 引发系统完整重启。
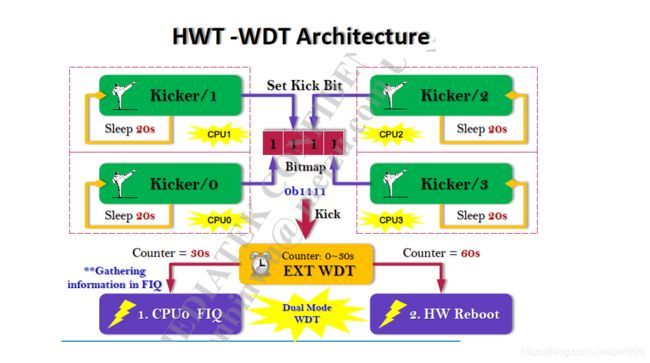
4.1 wdt log信息解析:
wdt的详细原理可以参考:。
主要的思路就是WDT超时以后,首先在cpu0上会产生一个FIQ,在FIQ中记录临终现场类似如oops,并且打印出每个cpu的调用堆栈。最后在cpu0上调用panic()复位整系统,如果FIQ或者panic()没有响应成功,后面还有一个硬件超时的reset信号发出来。

4.2 wdt复位定位思路:
WDT异常定位思路
步骤
信息
行动
next
step1
根据"kick=0x0000000X,check=0x0000000X"的信息找出是哪个cpu没有喂狗
结合每个cpu打印出的回调信息,推断出当时的死锁情景
如果这一步的信息不能定位到bug根因,继续往下一步走。
step2
分析bug的前后log
分析bug发生前的kernel log,重点关注err、fail等关键字打印,分析推导是否有这些出错引起了后面的重启bug
如果这一步的信息不能定位到bug根因,继续往下一步走。
step3
最后的定位大法:复现和排除
先复现,再来一个一个因素的排除,直到故障不出现,那么bug的相关因素就会被排除出来。
5. Hardware Reboot。
最难搞的复位,既没有被arm陷阱异常捕获到,又没有被WDT监控到,运行过程中硬件出现bug,系统直接复位。
5.1 Hardware Reboot:
HW bug,常见和以下的模块相关:
Hardware Reboot相关模块
分类
相关驱动模块
Power
CPU DVFS、CPU IDLE、CPU HotplugGPU DVFSMEM DVFSPMIC
Clock
CPU DVFS、CPU IDLE、CPU HotplugGPU DVFSMEM DVFS
Memory & Memory Controller
MEM DVFS、MEM失效
Fail IC
TP、sensor、connect等所有驱动模块IC的硬件失效
所以hardware reboot一方面可能是因为硬件本身的不合造成的,另一方面也可能是以上模块软件配置不正确造成的异常。所以我们的稳定性测试需要充分覆盖以上的所有模块。
5.2 Hardware Reboot定位思路:
对于hardware reboot故障的定位,可以依照以下的SOP先筛选出是否是haedware相关的问题,按照步骤一步步进行确认。
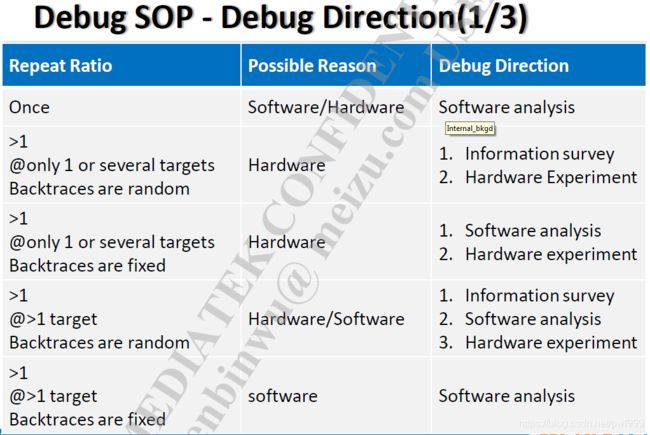
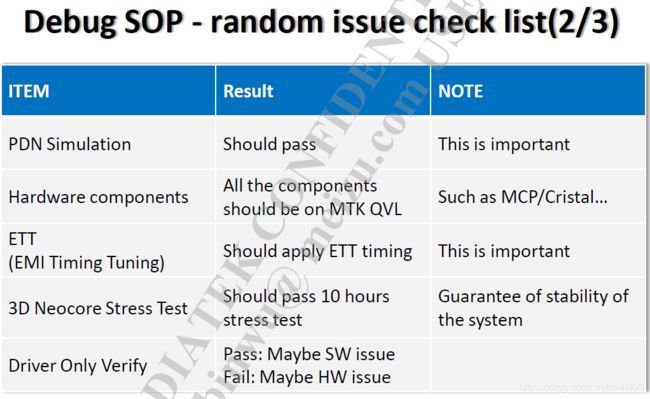

6. 最后的定位大法:复现和排除。
如果上述的所有手段都不能定位到bug根因的话,我们只有祭出最后的大招。先复现,再来一个一个因素的排除,直到故障不出现,那么bug的相关因素就会被排除出来。
这个方法的好处是针对任何bug都是适用的,但是稳定复现,是一个不小的工作量。