计算机视觉基础知识点(根据cs231n以及博客内容整理)
1、计算机视觉
1.1 经典网络
https://blog.csdn.net/liuxiao214/article/details/81914743
AlexNet(errot15.4%)
-
第一个成功展现出卷积神经网络潜力的网络结构,自从Alexnet之后,卷积神经网络开始迅速发展
-
使用relu而不是sigmoid
-
添加了dropout层
-
提出了数据增强(对原图片进行随机裁剪256x256裁剪为227x227)
Vgg16/19(errot7.3%)
-
使用了3x3的filter取代了5x5和7x7,在实测中展示了两个3x3与5x5相比有更好的效果并且参数更少;增加卷积核层数降低空间维度,增加深度效果更好。
(小的卷积核可使我们采用更深的深度来训练神经网络,可以给神经网络带来更多的非线性
一个5*5的卷积核的感受野相当于2层3x3的卷积核)
-
使用pre-training,先训练层数少的再慢慢加深
-
这个网络说明了深层的卷积神经网络有十分好的表现
GoogleNet(error6.7%)
- 第一个使用相叠加的方式的卷积的网络结构,即可以横向扩展。
- 让网络通过不同的路径再拼接到一起,用密集的块结构达到稀疏化的效果
- 最后用了全局平均池化,使得参数数量比vgg少了很多。
ResNet(error 3.6%)(152层)
- 提出残差块理念,解决了网络层数过多导致的梯度消失爆炸问题和网络退化问题
- 在不同的层之间建立一架高速公路,使得网络没有必要在残差几乎为零的层浪费时间
1.2 目标检测系列
- RCNN
在候选区域网络的基础上,把2000个候选区域框中的图像送入图像分类网络进行分类定位
(速度过慢,每一个目标提案都会通过卷积神经网络进行前向计算,而不共享计算;
训练空间和时间消耗大 特征需要磁盘存储)
- Fast RCNN(使用交叉熵函数做分类,L1smooth做回归,对误差鲁棒性更好)
将一幅完整的图像和一系列目标提案作为输入。先用一些卷积层和池化层生成卷积特征映射来处理整个图像。然后,对于每一个目标提案,感兴趣区域(RoI)池化层从特征映射中提取出一个固定长度的特征向量。每一个特征向量被送到全连接层(fc)以便产生目标类别概率估计;另一边生成边界框位置。
- Faster RCNN
RPN
RPN是一个全卷积网络,可以同时在每个位置预测目标边界和目标分数。RPN经过端到端的训练,可以生成高质量的区域提出,由Fast R-CNN用于检测。
RPN先接收CNN的特征图,然后在其上进行3x3卷积,然后在特征图上每一个点生成9个候选框,再连接到两个全连接网络进行前景/目标的分类;以及目标框具体位置的回归;再使用nms筛选概率高的候选框送去ROI层,由ROL层将所有候选框中特征图转化为相同尺寸送入RCNN后面的分类和框回归网络中。
对于每一个位置,通过两个全连接层(目标分类+边框回归)对每个候选框(anchor)进行判断,并且结合概率值进行舍弃(仅保留约300个anchor), 没有显式地提取任何候选窗口 ,完全使用网络自身完成判断和修正。
(然而RCNN系列网络都是在候选区域网络的基础上实现的,但是这个过程要搜索潜在的边界框、提取特征、SVM评分等一系列复杂过程,一张图片就要弄40多秒,还是太慢)
4.mask-RCNN
faster-RCNN检测出来的目标由于各种卷积映射,会把除出来的小数都约掉了,就会使得误差不断增大,引入了mask-RCNN,用RolAlign代替Rol层。
RolAlign不把映射过程中处出来的小数约掉,而是在最后的时候使用双线性插值法,由虚拟坐标点周围的四个像素点的平均值来估计改虚拟坐标点的像素值,再进行池化,过程中更没有引入误差,因此会更加精确;更加有利于实例分割。
除此之外还添加了mask分支,特征图会同时送进mask和FastRcnn,在mask层中二进制说明给定像素是否是目标的一部分,疯狂反卷积以提升分辨率。
损失:
losses可分为两部分组成,一是rpn网络的损失,包括rpn前景/背景分类损失rpn_class_loss和 rpn目标框回归损失rpn_bbox_loss;二是mask_rcnn heads损失,包括分类损失class_loss、回归损失bbox_loss和像素分割损失mask_loss。
5.YOLO
核心思想是将目标检测转化为回归问题求解,把整张图片切成网格,要是目标物体落在格子中,这个网格就要负责预测这个物体的位置和类别,最后会输出SXSX(5xB+类别数)的向量
6.SSD
算法步骤是将VGG的两个全连接层,然后抽取六个不同卷积层的特征图,分别在这些特征图的每一个点上构造6个大小不同的bbox,分别进行检测和分类,将生成的多个bbox结果结合起来,用nms去掉一部分重叠或不正确的bbox最后生成检测结果。
7.nms
nms极大值抑制算法原理是每次都把类别概率得分最高的bbox和其他的bbox进行交并比计算,把交并比大于0.6的删掉;并重复进行。
1.3 交叉验证
- 留一验证
比如每次留一个数据点作为验证集,重复n次;适用于小数据集,但是只针对一个数据点进行测试,模型估计值受到数据点的很大影响。
-
K折交叉验证
每次把训练集分成k份,每次从k份中留1份作为验证集,重复k次;适合大样本数据集,对数据使用率更高;不适合包很不同类别的数据集,比如其中1折全是B类,用ACDE数据去训练B模型准确率会很低。
-
分层交叉验证
每一折都按照总体数据比例进行了划分比如一共有50个A,30个B,20个C;则每一折里面都会是5:3:2的数据比例。
1.4 loss
回归损失函数
-
均方差损失MSE(L2loss)
预测值和目标值的差的平方的和除以n,比MAE收敛快但对误差点的鲁棒性不太好。
-
平均绝对误差损失MAE(L1loss)
预测值和目标值的绝对值的和除以n,虽然收敛比较慢但是对误差点鲁班性好
-
Huber Loss(前两者结合,误差大用L1loss,误差小用L2loss)
分类损失函数
-
0-1损失函数
对就0,不对就1,太严格不好训练
-
log对数损失函数
如果需要知道结果属于每个类别的置信度或是逻辑回归则效果很好;但是对噪声比较敏感
-
hinge损失函数
L(y,f(x))=max(0,1-yf(x)), y (-1,1)是目标值,f(x) (-1,1)是预测值
对异常点、噪声不敏感
-
交叉熵函数(p是期望,q是输出)
交叉熵刻画的是实际输出(概率)与期望输出(概率)的距离
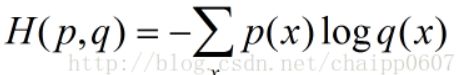
1.5 Normalization
https://blog.csdn.net/liuxiao214/article/details/81037416
BN层作用:
BN层位于激活函数之前全连接层之后,它先对数据进行标准化,再进行缩放和平移。
-
加快网络的训练和收敛的速度
在深度神经网络中中,每层数据的分布都是一样的训练会比较容易收敛。
-
控制梯度爆炸防止梯度消失
-
防止过拟合
BN的使用使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,网络不会朝这一个方向使劲学习。一定程度上避免了过拟合
BN基本方式
-
Batch Normalization(有了BN就不用dropout,有正则化效果)
batch normalization就是强行将数据拉回到均值为0,方差为1的正太分布上,这样不仅数据分布一致,而且避免发生梯度消失。
-
算法过程:
沿着通道计算每个batch的均值u
沿着通道计算每个batch的方差σ^2
对x做归一化,x’=(x-u)/开根号(σ^2+ε)
加入缩放和平移变量γ和β ,归一化后的值,y=γx’+β
加入缩放平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数
-
1.6 NLP系列
-
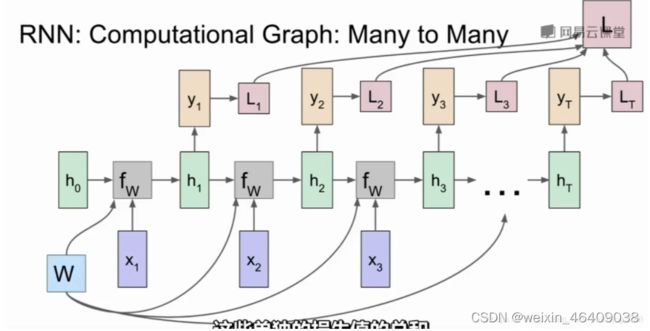
RNN
多对一:输入句子,输出情感
多对多:多对一再一对多 句子翻译
一对多:生成图片描述
-
LSTM(Long-short term memeory)
RNN跟着时间推移对前面时间节点的感知力会下降,网络一深就不好训练了
LSTM拥有输入门、遗忘门、输出门
遗忘门:将前一时间隐藏层和新的输入放入sigmoid趋于零就丢弃,趋于1就保留
例如,他今天有事,所以我。。。当处理到‘’我‘’的时候选择性的忘记前面的’他’,或者 说减小这个词对后面词的作用。
输入门:用于更新细胞状态,将前一层隐藏状态的信息和当前输入的信息传递到 sigmoid 函数 中去。将值调整到 0~1 之间来决定要新加入哪些信息
他今天有事,所以我。。。。当处理到‘’我‘’这个词的时候,就会把主语我更新到细胞中 去。
输出门:输出门用来确定下一个隐藏状态的值
例如:上面的例子,当处理到‘’我‘’这个词的时候,可以预测下一个词,是动词的可能性 较大,而且是第一人称。
会把前面的信息保存到隐层中去。Gated Recurrent Unit (GRU)就是lstm的一个变态,这是由 Cho, et al. (2014) 提出。*它将忘记门和输入门合成了一个单一的 更新门。*
1.7 优化方法
https://www.baidu.com/link?url=ws6cxNIhWmVA1gbrUgFMRtACQhCMdYvcwZtLWOZfWZ0Iuujyt5Y4w08KNj7gn2ExUBD4jIybSJ8e3xb95cMWcL6hZXEn4IUJ5mRYnPoQbNC&wd=&eqid=ce9adcb10004685c000000035b5d4fb6
https://blog.csdn.net/chenchunyue11/article/details/51290638
-
SGD
最简单原始的迭代算法,就是减去learning_rate*梯度值。
这个算法具有的问题就是如果各个维度的步长相差很大,就会不断震荡,而且收敛缓慢.
-
Momentum

入了能量损失机制,即每次在mu*v的基础上改变。mu的值通常是0.5,0.9,0.99。v被初始化为0.
Momentum通过对于速度的修改间接影响高度,所以具有延迟作用以及累加作用,有效的解决了震荡的问题。同时因为会累加小梯度的维度上的速度值,所以可以加快收敛速度。 -
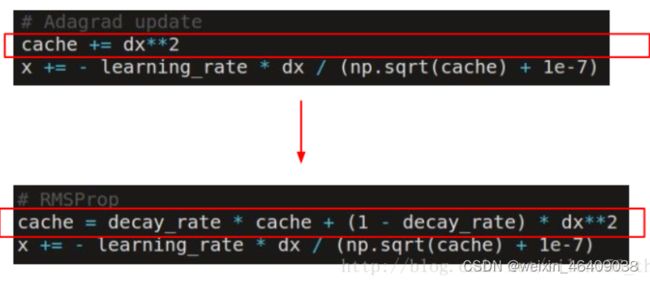
AdaGrad
实际应用中,我们在开始的时候需要高学习率收敛到最优值附近,然后使用低学习率收敛到最优值(因为如果步长过大,参数会在最优点附近震荡而不收敛(此处的震荡无法被Momentum解决))这里就需要引入自适应的算法,可以在迭代过程中合理的减小学习率,使得收敛效果更好。
AdaGrad是第一个自适应算法,通过每次除以根号下之前所有梯度值的平方和,从而使得步长单调递减。同时因为cache的变化与每个维度上的值有关,所以此方法可以解决各个维度梯度值相差较大的问题。

-
RMSProp
RMSProp对于AdaGrad的改进在于cache的更新方法。不同于不断的累加梯度的平方,RMSProp中引入了泄露机制,使得cache每次都损失一部分,从而使得步长不再是单调递减了。
-
Adam
可以理解为Momentum和RMSProp的融合,兼顾了利用动量离开局部最小值的理念和RMSProp的自适应学习率概念。
1.8 上采样、反卷积
https://blog.csdn.net/a_a_ron/article/details/79181108
https://blog.csdn.net/amor_tila/article/details/75635283
https://www.cnblogs.com/cvtoEyes/p/8513958.html
常用于语义分割,将图片中不同类别物体用不同颜色标识
先将vgg丢弃全连接层进行疯狂池化卷积提取图像特征;再上采样(反卷积)恢复到原始图片大小
反卷积:3x3卷积核在5x5图像上卷积,生成2x2特征图;现要将其上采样为4x4图像
把卷积核按照步长为2,复制抻开为16x4 把2x2拉为4x1 二者相乘为16x1 把16x1还原为4x4
1.9 有哪些激活函数,各自的优缺点
https://blog.csdn.net/nuannuanyingying/article/details/70064353
https://blog.csdn.net/yangdashi888/article/details/78015448
-
sigmoid:数据压缩到[0,1]之间
- 输入过小或者过大梯度接近0,梯度消失
- 输出不是以0为均值
- 指数计算计算量大,求导涉及除法
-
tanh:数据压缩到[-1,1]之间
- 优点:均值为0
- 缺点:输入过小或者过大梯度接近0,梯度消失
-
ReLU: max(0, x)
- 优点:计算高效 ,没有梯度消失问题;Relu会使一部分神经元的输出为0,网络稀疏,减少了参数的相互依存关系,缓解了过拟合;收敛速度快
- 缺点:均值非零;输入过负会梯度消失
-
Leaky-ReLU、P-ReLU:会解决ReLU挂掉的问题
max(0.01x,x) max(ax,x)
-
ELU(x x>=0,a(e^x-1))x<0)
优点:梯度不会消失,过负不会挂掉,均值接近0
缺点:计算量大。要指数计算
1.10 过拟合是什么,如何处理过拟合(正则化基本方式)
过拟合
过拟合就是模型的泛化能力不够强;
训练时准确率高而验证时准确率低;
产生的原因有 神经网络复杂度过高,训练时间太久,数据量太少
如何处理过拟合
降低模型复杂度(dropout,随机删除隐层单元,一般设为0.5放在FC之后,大数据集效果更好,但训练时间更长)
BN层(每个输出都与样本所属的mini-batch相关联,不会从某一个样本产生确定结果)
正则化(L1产生稀疏矩阵,L2让模型参数尽可能小)对模型加上限制
即时停止训练
数据增强(用于小数据集 可随机旋转,随机裁剪,高斯噪声,水平竖直翻转)
1.11 梯度消失和梯度爆炸
梯度消失
产生原因:网络过深,采用不合适的激活函数如sigmoid
解决方案:使用relu函数,加BN层(x的值比较平均缩小了反向传播乘x带来的影响),使用残差网络F(x)+x求导有一个1,不至于梯度消失
梯度爆炸
产生原因:网络过深,权值初始化过大
解决方案:加BN层(x的值比较平均缩小了反向传播乘x带来的影响),梯度剪切,正则化(权重趋于0或者变小)
1.12 bagging和dropout
https://blog.csdn.net/m0_37477175/article/details/77145459
bagging:取多组不同的训练数据,用相同的算法训练不同的模型,最后将几个模型进行均衡合并。
dropout:每个batch随机抑制一部分神经元,相当于做了不同的模型
1.13 L1、L2范数,区别是什么,为什么L1范数会趋于0,而L2范数不会。
L1范数是指向量中各个元素绝对值之和。L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
L2范数是指向量中各元素的平方和然后开根。我们让L2范数的规则项||W||2最小,可以使得W的每个元素都很小,都接近于0。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
1.14不收敛和过拟合的区别
https://blog.csdn.net/limiyudianzi/article/details/79626702
不收敛一般是形容一些基于梯度下降算法的模型,收敛是指这个算法有能力找到局部的或者全局的最小值,从而得到一个问题的最优解。
过拟合
过拟合就是模型的泛化能力不够强;
训练时准确率高而验证时准确率低;
1.15 为什么训练不收敛,如何解决
有可能是陷入局部最优,若是sgd就调大学习率,换用adam,调小batch跳出局部最优,后面再调大batch让模型收敛;有可能是梯度消失,更换激活函数
1.16 全连接层作用
zhihu.com/question/41037974
全连接网络的作用就是将最后一层卷积得到的feature map stretch成向量,对这个向量做乘法,最终降低其维度,然后输入到softmax层中得到对应的每个类别的得分。
1.17 全连接层的作用
https://www.zhihu.com/question/41037974
全连接层起到把前面卷积层的结果拉伸成一个长条,把里面的每个申晋源映射到样本标记空间的作用。
全局平均池化
https://blog.csdn.net/qq_23304241/article/details/80292859
全局平均池化GAP:以feature map为单位进行均值化。即一个feature map输出一个值。有多少个类就产生多少个feature map。
GAP的优势在于:各个类别于feature map之间的联系更加直观(相比于全连接层的黑箱来说),feature map被转化为分类概率更加容易;因为在GAP中没有参数需要调,所以避免了过拟合问题;GAP汇总了空间信息,因此对输入的空间转换更为鲁棒。
1.18 深度学习在图像领域效果为什么这么好
比如说深度学习在图像识别领域比文本语义领域效果更好
一来图像识别是一个相对固定的工作,像素、大小基本确定,不像语言一样复杂,涉及语句长短不一,语境模糊,多语言等问题,还可能有语法不规范。二来,更重要的是,CNN几乎是还原了人类的眼睛在生理学上如何工作(滤波、压缩,转换信号);而在语言领域,目前无论是CNN还是RNN甚至是两者结合,都不能全然模拟人类理解一段文字的生理学过程(我们甚至还不是特别清楚大脑到底是怎么样理解语言的,就要模拟这个过程)。
1.19 卷积层参数量、计算量是多少

1.20 感受野的计算
https://www.cnblogs.com/objectDetect/p/5947169.html
概念:在卷积神经网络中,感受野的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
某一层的感受野=前一层的感受野+(当前层kernel_size-1)*前一层的strides
1.21 LSTM用在行为识别为什么不好
https://blog.csdn.net/stdcoutzyx/article/details/79117869
LSTM属于循环神经网络,更多适用于语义理解,文本翻译等领域
行为识别更倾向于使用yolo
1.22 线性回归和逻辑回归的区别
https://blog.csdn.net/yunhaitianguang/article/details/43877591
https://blog.csdn.net/viewcode/article/details/8794401
逻辑回归的要拟合的模型 是一个非线性模型,sigmoid函数,又称逻辑回归函数。但是它本质上又是一个线性回归模型,因为除去sigmoid映射函数关系,其他的步骤,算法都是线性回归的。可以说,逻辑回归,都是以线性回归为理论支持的。
只不过,线性模型,无法做到sigmoid的非线性形式,sigmoid可以轻松处理0/1分类问题。
在二分类问题中softmax和sigmoid函数是一样的
1.23 权重初始化方法有哪些
-
把w初始化为0,或者相同值(不好),
会使得从第二层网络开始,所有的输入、神经元都一样,打破非对称性原则,没有办法学习多样不同的特征
-
对w随机初始化
要成0.01以防权重参数过大梯度爆炸(引起网络不稳定或出现无法更新的Nan权重值),激活函数要是sigmoid会梯度消失
-
Xavier initialization(适用于tanh)
尽可能的让输入和输出服从相同的分布,这样就能够避免后面层的激活函数的输出值趋向于0;
但是在relu函数中到了后面还是会趋向于0
-
He initialization(针对relu的初始化方法)
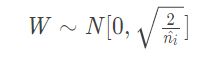
现在神经网络中,隐藏层常使用ReLU,权重初始化常用He initialization这种方法。
1.24 精确率很高、召回率很低什么原因
召回率 就是用你查出来的正确的数量除以所有正确的数量,可以跟准确率对比着记忆,
准确率是用你查出来的正确的数量除以所有的数量(包含正确和不正确的数量)。
数据小物体多,容易漏检,预测的少,但是准
1.25 有个类别的准确率比较低
别的都高,就说明算法没问题,这一类数据有问题
对这个类的数据做一个清洗
1.26 非平衡数据集的处理方法有哪些?
- 采用更好的评价指标,例如F1、AUC曲线等,而不是Recall、Precision
- 进行过采样,随机重复少类别的样本来增加它的数量;
- 进行欠采样,随机对多类别样本降采样
- 通过在已有数据上添加噪声来生成新的数据
- 修改损失函数,添加新的惩罚项,使得小样本的类别被判断错误的损失增大,迫使模型重视小样本的数据
- 使用组合/集成方法解决样本不均衡,在每次生成训练集时使用所有分类中的小样本量,同时从分类中的大样本量中随机抽取数据来与小样本量合并构成训练集,这样反复多次会得到很多训练集和训练模型。最后在应用时,使用组合方法(例如投票、加权投票等)产生分类预测结果;