第一次打卡笔记
第一次打卡笔记
- pandas基础知识
-
- 数据表生成
-
- 1、导入pandas库
- 2、检查版本
- 1、文件读取与写入
- Series结构
-
- (1)Series创建
- (2)属性访问
- DataFrame
-
- (1)DataFrame创建
- (2)修改行或列名
- (3)调用属性和方法
- (4)将Series转换为DataFrame
- (5)使用T符号可以转置
pandas基础知识
数据表生成
1、导入pandas库

2、检查版本

1、文件读取与写入
文件读取格式有:(1)csv格式 df = pd.read_csv('data/table.csv')
df.head()
(2)txt格式 df_txt = pd.read_table('data/table.txt')
df_txt
(3)xls或xlsx格式 df_excel = pd.read_excel('data/table.xlsx')
df_excel.head()
此过程需要安装xlrd包
写入:(1)csv格式 df.to_csv('data/new_table.csv')
(2)xls或xlsx格式 df.to_excel('data/new_table2.xlsx', sheet_name='Sheet1')
此过程需要安装openpyxl
Series结构
(1)Series创建
Series中,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],name='这是一个Series',dtype='float64')
s
(2)属性访问
s.values
s.name
s.index
s.dtype
DataFrame
(1)DataFrame创建
df = pd.DataFrame({'col1':list('abcde'),'col2':range(5,10),'col3':[1.3,2.5,3.6,4.6,5.8]},
index=list('一二三四五'))
df
(2)修改行或列名
df.rename(index={'一':'one'},columns={'col1':'new_col1'})
输出结果

(3)调用属性和方法
df.index
Index(['一', '二', '三', '四', '五'], dtype='object')
df.columns
Index(['col1', 'col2', 'col3'], dtype='object')
df.values
array([['a', 5, 1.3],
['b', 6, 2.5],
['c', 7, 3.6],
['d', 8, 4.6],
['e', 9, 5.8]], dtype=object)
df.shape
(5, 3)
df.mean()
col2 7.00
col3 3.56
dtype: float64
(4)将Series转换为DataFrame
s = df.mean()
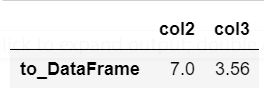
s.name='to_DataFrame'
s
col2 7.00
col3 3.56
Name: to_DataFrame, dtype: float64
(5)使用T符号可以转置
s.to_frame().T