精读论文:Feature Pyramid Networks for Object Detection(附翻译)
Feature Pyramid Networks for Object Detection(附翻译)
这篇文章是菜菜的小孙本学期的第三篇文章,结构看懂了, 但是实验非常懵,大概是因为faster rcnn就懵。本周状态不好,下周调整!
开始于2020年7月26日
结束于2020年8月
(中间看了个faster rcnn,太难了)
目录
- Feature Pyramid Networks for Object Detection(附翻译)
- 一、总结
-
- 1.1 问题
- FPN(特征提取器)
- FPN+head(RPN和fast rcnn)
-
- 流程
-
- 细节
- 二、翻译
-
- 0. 摘要
- 1. 介绍
- 2. 相关工作
-
- 手工提取特征和更早的神经网络
- 深度卷积网络object detector
- 使用多层级方法
- 3. Feature Pyramid Networks
-
- 自下而上的通道
- 自上而下的通道和横向连接
- 4. 应用
-
- Feature Pyramid Networks for RPN
- 4.2 Feature Pyramid Networks for Fast R-CNN
- 5. 目标检测实验
-
- 5.1 Region Proposal with RPN
-
- 5.1.1 Ablation Experiments(消融实验)
- 5.2 Object Detection with Fast/Faster R-CNN
-
- 5.2.1 Fast R-CNN(on fixed proposals)
一、总结
1.1 问题
图像金字塔:
原图像的尺寸进行放大或者缩小变换。一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似。我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
特征金字塔:
图像中存在不同尺寸的目标,而不同的目标具有不同的特征,利用浅层的特征就可以将简单的目标的区分开来;利用深层的特征可以将复杂的目标区分开来。
人工设计特征:
传统算法中人工设计特征,比如DPM就要用到它产生密集尺度的样本以提升检测水平。
convnet提取特征:
cnn相比人工设计特征,能够自己学习到更高级的语义特征,同时CNN对尺度变化鲁棒。
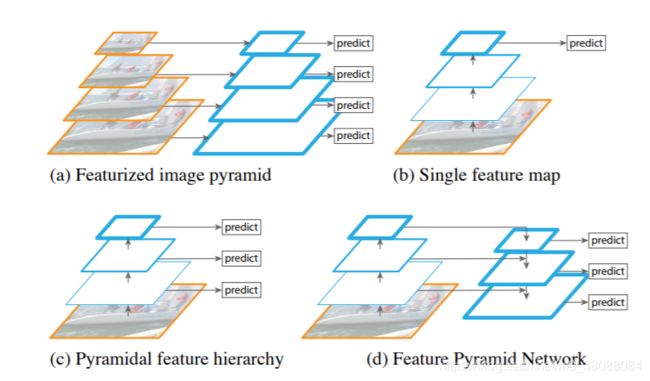
特征化图像金字塔(featurized image pyramids):
如a所示,多尺度检测需要金字塔结构去进一步提升准确性,金字塔结构的优势是其产生的特征每一层都是语义信息加强的。对图像金字塔每一层都提取特征,形成特征化金字塔有很大的局限性,首先运算耗时会增加4倍,训练深度网络的时候太吃显存,几乎没法用,即使用了,也只能在检测的时候。
CNN提取高层特征:
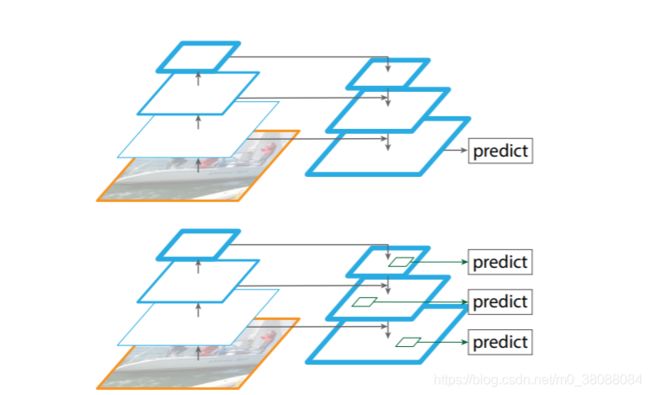
如b所示,CNN计算的时候本身就存在多级特征图(feature map hierarchy),且不同层的特征图尺度就不同,形似金字塔结构。浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
CNN提取特征模仿图像金字塔形成特征金字塔:
如c所示,SSD方法借鉴利用featurized image pyramid,但是为了避免利用太低层的特征,SSD从偏后的conv4_3开始,又往后加了几层,分别抽取每层特征,进行综合利用。作者认为SSD对于高分辨率的底层特征没有再利用,而这些层对于检测小目标很重要。
FPN(特征提取器)
our idea:
如d所示,FPN是利用卷积神经网络固有的、多尺度的金字塔层去构建特征金字塔。考虑到固有的金字塔层间存在语义鸿沟(高分辨率层低语义,低分辨率层高语义),作者建立了一个自上而下的带有横向连接的结构,使得所有尺度的特征都有丰富的语义信息。
和FCN的区别
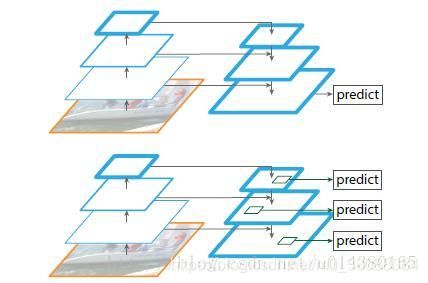
上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。而FPN网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面的实验证明finest level的效果不如FPN好,原因在于FPN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外虽然finest level有更多的anchor,但仍然效果不如FPN好,说明增加anchor的数量并不能有效提高准确率。
自上而下的路径
CNN的前馈计算就是自下而上的路径,特征图经过卷积核计算,通常是越变越小的,也有一些特征层的输出和原来大小一样,称为“相同网络阶段”(same network stage )。对于本文的特征金字塔,作者为每个阶段定义一个金字塔级别, 然后选择每个阶段的最后一层的输出作为特征图的参考集,因为每个阶段的最深层应该具有最强的特征。
自下而上的路径
把高层特征做2倍上采样(最邻近上采样法,可以参考反卷积),然后将其和对应的前一层特征结合(前一层要经过1 ×1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。迭代开始阶段,作者在C5层后面加了一个1×1的卷积核来产生最粗略的特征图。最后,作者用3 * 3的卷积核去处理已经融合的特征图(为了消除上采样的混叠效应),以生成最后需要的特征图。
FPN+head(RPN和fast rcnn)
RPN是一个滑动窗口类不可知的目标检测器,cnn提取特征
Fast RCNN是一个基于区域的目标检测器,通过RoI提取特征
流程
- 选择一张需要处理的图片,然后对该图片进行预处理操作;
- 将处理过的图片送入预训练的backbone中(如ResNet等),构建bottom-up网络
- 构建对应的top-down网络(上采样后的特征图和用1x1的卷积降维处理后的特征图相加(对应元素相加),最后进行3x3的卷积操作
- 在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作
- 将上一步获得的候选ROI分别输入到4、5、6层上面(根据wh分配)分别进行ROI Pool操作(固定为7x7的特征)
- 连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层
细节
RPN是Faster R-CNN中用于区域选择的子网络,RPN是在一个特征图上应用9种不同尺度的anchor。
本篇论文另辟蹊径,把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺度。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \{32^2, 64^2, 128^2, 256^2, 512^2 \} {322,642,1282,2562,5122}三种比例 { 1 : 2 , 1 : 1 , 2 : 1 } \{1:2, 1:1, 2:1\} {1:2,1:1,2:1},所以金字塔结构中共有15种anchors。
Fast R-CNN 中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。 不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。作者定义了一个系数k,其定义为:
k = ⌊ k 0 + l o g 2 ( w h / 224 ) ⌋ k = \lfloor k_0+log_2(\sqrt{wh}/224)\rfloor k=⌊k0+log2(wh/224)⌋
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归,认为这样还能使速度更快一些。
二、翻译
0. 摘要
abstract:
在检测不同尺度物体的识别系统中,特征金字塔是一个基本的组件。但是最近的深度学习物体检测器都避免了金字塔表达,在某种程度上因为需要大量计算和内存。在这篇文章,我们利用了深度卷积网络固有的、多尺度的、金字塔层级来构建几乎没有额外损失(marginal extra cost)的特征金字塔。我们提出了一个带有横向连接的自上而下的结构,用来建立所有尺度的高层语义特征图。这个被称为FPN的网络结构作为通用的特征提取器在不同应用中都展现了显著的改进。在一个基本的Faster R-CNN系统中使用FPN,没有一些花里胡哨的东西,我们的方法可以在COCO检测基准数据集上取得最先进的单模型结果,结果超过了所有现有的单模型输入,包括COCO 2016挑战赛的获奖者。除此以外,我们的方法在一个GPU上以每秒6帧的速度运行,因此在多目标检测中,是一个实际的、准确的方法。
1. 介绍
introduction:
在计算机视觉中识别不同尺度的物体是一个基本的挑战。基于图像金字塔建立的特征金字塔(我们简称为特征化图像金字塔 featurized image pyramids)形成了一个标准解决方案的基础。这些金字塔是尺度不变的,在某种意义上说,一个物体尺度的改变可以通过移动它在金字塔上的层级来进行抵消。直观地说,这个属性通过在空间位置和金字塔层级上扫描模型,可以使一个模型在很大范围尺度上去检测目标。
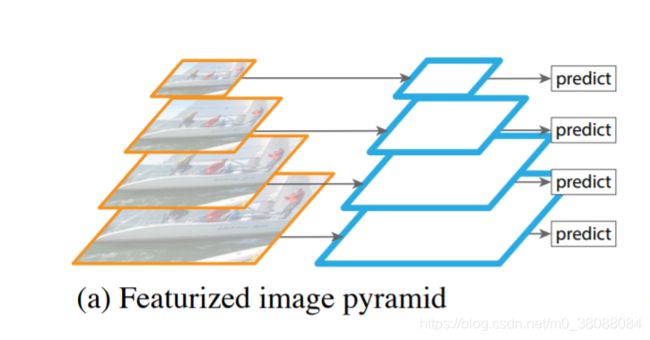
特征化图像金字塔在手工设计特征时代经常被使用。他们是非常重要的,一些目标检测方法例如DPM需要密集尺度(每octave需要10个尺度)的下采样来达到很好的效果。对于识别任务,人工设计特征已经很大程度上被深度卷积网络计算特征所替代了。除了能获取高层语义信息,卷积网络针对尺度变化的鲁棒性也更强,因此有利于利用单个输入尺度提取的特征进行识别。但是即使有了这种鲁棒性,金字塔仍需要得到最精确的结果。在ImageNet和COCO识别挑战赛的近期顶级参赛作品都在特征化图像金字塔上使用了多尺度测试。特征化图像金字塔的每一个层的主要优点是,它产生一个多尺度的特征表达,使得每一层都有很强的语义信息,包括高分辨率层。
然而,特征化图像金字塔的每一层也存在明显的限制。推理时间大大增加(例如,增加了4倍),使得这种方法不适用于实际应用。此外,就内存而言,进行训练是不可行的,因此,如果被利用,则仅在测试时使用图像金字塔,这也造成了训练/测试时推理的不一致。基于这些原因,Fast 和Faster R-CNN选择在默认设置下不使用特征化的图像金字塔。
但是,图像金字塔并不是计算多尺度特征表示的唯一方法。一个深度卷积网络逐层计算特征层次(feature hierarchy),并且通过下采样层,特征层次有了一个固定的、多尺度的、金字塔形状。在这个网络内部的特征层次产生了不同空间分辨率的特征图,但是因为不同的深度产生了很大的语言差异。高分辨率的特征图有着低层特征,影响了它们勇于物体识别的表述能力。
Single Shot Detecter(SSD)第一次尝试使用ConvNet的金字塔特征层次,它就像下图的特征图像金字塔。理想情况下,SSD形式的金字塔可以重新利用在前向传播中计算出来的来自不同层次的多尺度特征图,因此没有其他消耗。但是为了避免使用低层特征,SSD放弃重用已经计算的层,而是从网络的高层开始建立金字塔(例如,VGG网络的conv4_3),然后增加几个新的层。因此这个方法失去了重新利用特征层次结构中高分辨率特征图的机会,(在后文)我们显示了这些高分辨率图对于检测小物体是非常重要的。

这篇文章的目标是自然地利用ConvNet的特征层级结构的金字塔形状,同时创造一个在所有尺度有着强语义的特征金字塔。为了实现这个目标,我们依赖一个结构,这个结构通过一个自上而下的路径和横向连接把低分辨率、强语义的特征和高分辨率、弱语义的特征结合起来。种结构可以产生一个在所有层都有着丰富语义的特征金字塔,并且可以从单个输入图像上快速建立。换句话说,我们展示了怎样建立一个网络内的特征金字塔,可以用来代替特征图像金字塔,并且不影响性能、速度和内存。
在近期的研究中很流行采用自上而下和跳跃连接的类似结构。他们的目标是生成一个高分辨率的高层特征图,并在上面进行预测。相反我们的方法是将架构作为一个特征金字塔来利用,在每一层上独立进行预测。我们的作品呼应了特征化图像金字塔,在这类工作用这个方法从来没有被用过。
我们在不同的检测和分割系统中评估我们的特征金字塔网络(Feature Pyramid Network)。没有其他影响的情况下,基于FPN和Faster R-CNN检测器,我们在COCO识别挑战中获得了非常好的结果,超越了所有先前参赛胜利者设计的单模型参赛作品。在ablation实验中,我们发现对于边界框候选区域(bounding box proposals),FPN在平均召回率方面(Average Recall)显著提升了8.0个百分点。对于目标检测,在COCO-style Average Precision (AP) 提高了2.3个百分点 ,在PASCAL-style AP提高了3.8个百分点,超越了Faster R-CNN的强的、单一尺度的baseline——resnet。我们的思想也很容易扩展到mask proposals并且提高实例分割AR(召回率)和速度,超过那些严重依靠图像金字塔的SOTA模型。
除此以外,我们的金字塔结构可以在所有尺度端到端地训练,并且在训练、测试时具有一致性,而这点在使用图像金字塔时会因为内存而不可行。相比于所有STOA方法,FPN可以达到更高的准确率。除以以外,这个改进在单尺度baseline上没有提升测试时间。我们相信这些提高将帮助未来的研究和应用。
2. 相关工作
手工提取特征和更早的神经网络
Hand-engineered features and early neural networks:
SIFT特征最初是在尺度空间极值处提取的,用于特征点匹配。HOG特征和后来的SIFT特征在整个图像金字塔上密集计算得到的。这些HOG和SIFT金字塔用于图像分类、目标检测、人体姿态估计等等。快速计算特征化图像金字塔也引起了人们极大的兴趣。Dollar´等人通过计算稀疏采样金字塔和线性插入消失层(missing level)演示了快速金字塔方法。在HOG和SIFT之前,早期的工作是使用convnets计算图像金字塔上的浅网络,以检测跨越尺度的人脸。
深度卷积网络object detector
Deep ConvNet object detectors:
随着深度卷积网络的发展,object detector例如Over-Feat、R-CNN在精度上有了明显提高。Over-Feat采取了一种和早期神经网络人脸识别方法相似的策略,将convnet作为图像金字塔上的滑动窗口检测器。R-CNN采取了一个基于区域提案的策略,其中每个提案在使用convnet进行分类之前都进行了规模标准化。SPPnet证明了这种基于区域提案的检测器可以更有效地应用于在单个图像尺度上提取的特征图上。更高精准检测方法如Fast R-CNN和Faster R-CNN提倡使用单个尺度图像计算的特征,因为它在准确性和速度之间提供了良好的权衡。然而,多尺度检测仍然表现得更好,特别是对于小物体。
使用多层级方法
Methods using multiple layers:
最近很多方法都通过在ConvNets使用了不同层来改进检测和分割。FCN在多个尺度上对每个类别的部分分数求和,以实现语义分割。 Hypercolumns使用类似的方法进行对象实例分割。其他几种方法(HyperNet、ParseNet和ION)在计算预测值之前对多层特征进行连接,这相当于变化后的特征进行相加。SSD和MS-CNN在特征层次的多个层上预测对象,而不组合特征或分数。
最近有利用横向/跳跃连接的方法,将低级特征图关联到分辨率、语义层,例如U-Net和SharpMask用于分割,Recombinator networks用于人脸识别,Stacked Hourglass networks用于关键点估计。Ghiasi等人提出一个拉普拉斯金字塔呈现的FCN逐步完善分割。尽管这些方法采用了金字塔形状的建筑,但是他们不同于特征化图像金字塔,在所有层级独立做预测。事实上,上图中显式的金字塔结构,图像金字塔仍然需要跨越多个尺度识别物体。
3. Feature Pyramid Networks
FPN:
我们的目标是去利用Convnet的金字塔形的特征层级结构(这种结构有着从低到高水平的语义),并建立一个全部是高水平语义的特征金字塔。由此产生的特征金字塔网络是通用的,本文主要研究sliding window proposers滑动窗口候选区域器(Region Proposal Network,简称RPN)和region-based detectors基于区域的检测器(Fast R-CNN)。在 Section 6,我们也推广FPN到实例分割方案中。
我们的方法以任意大小的单尺度图像作为输入,并以完全卷积的方式在多个层次上输出成比例大小的特征图。这个过程独立于主干卷积体系结构(the backbone convolutional architectures ),本文中我们使用ResNet给出结果。金字塔的建造包括一个自下而上的通道,自上而下的通道和横向连接,如下所述。
自下而上的通道
bottom - up
自底向上方式是主体ConvNet的前向计算,它计算了一个由多个尺度特征图组成的特征层次结构,每步的缩放大小为2。通常有许多层生成相同大小的输出图,我们称这些层处于同一网络阶段(stage)。对于我们的特征金字塔,我们给每一个stage定义一个金字塔级。我们选择每个stage最后一层的输出作为我们的特征参考集,然后将丰富它来创建我们特征金字塔。这种选择是自然合理的的,因为每个阶段的最深层应该具有最强的特性。
具体来说,对于ResNets,我们使用每个阶段最后的残差块的特征激活层的输出。我们将这些残差块最后的输出(即conv2、conv3、conv4和conv5的输出)表示为{C2,C3,C4,C5},注意,与输入图像相比,它们的步长为 {4,8,16,32}。由于conv1占用了大量内存,所以我们不将其包含在金字塔中。
自上而下的通道和横向连接
top-down pathway and lateral connections
自上而下的路径产生高分辨率的特征,而这些高分辨的特征是通过对来自更高的金字塔层次上空间粗糙的但是语义上更强的特征图上采样产生的。这些特征和自下而上路径的特征图横向连接,进一步被增强。每个横向连接合并了具有相同空间大小的特征图,这些特征图来自自下而上的路径和自上而下的路径。自底向上的特征图具有较低层次的语义,但是它激活后具有更精确定位效果,因为它的下采样次数更少。
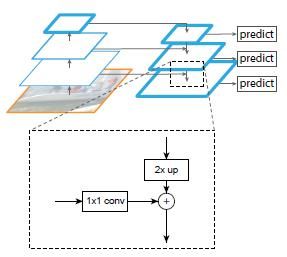
下图显示了构造自顶向下特征图的构建模块。
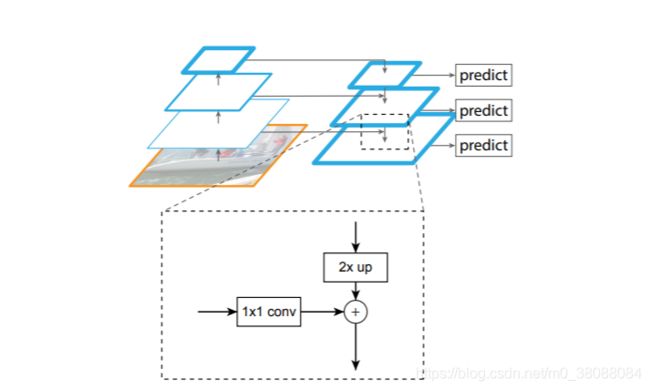
对于更粗分辨率的特征图,我们将其空间分辨率提高了2倍(简单地使用最近邻上采样)。然后,通过像素相加(element-wise addition)的方式将上采样的图和相应的自底向上的图(经过了一个1x1卷积层的处理,目的是降低通道维度)融合。迭代这个过程,直到生成最好分辨率的图。迭代开始时,我们简单地采用1x1卷积层处理C5得到最粗分辨率的特征图。最后,我们添加一个3×3卷积处理每个融合后的特征图生成最终的特征图,这是为了减少upsampling过程的混叠效应。最终的特征图集合被称为 { P 2 , P 3 , P 4 , P 5 } \ \{P2,P3,P4,P5\} {P2,P3,P4,P5} ,和 { C 2 , C 3 , C 4 , C 5 } \ \{C2,C3,C4,C5\} {C2,C3,C4,C5}具有相同的空间尺寸。
因为金字塔的所有层使用共享分类器/回归器,就像在传统的特征化图像金字塔中一样,我们在所有特征图中固定特征维度(通道数,表示为d)。在这篇文章中d=256,因此所有额外的卷积层(即横向连接中的1x1卷积)都有256个通道的输出。在这些额外的层中没有非线性,我们在经验上发现它们影响不大。
简单性是我们设计的核心,我们发现我们的模型对许多设计选择都具有鲁棒性。我们尝试了一些更复杂的模块(例如,使用多层残差块作为连接),并观察到稍微更好的结果。设计更好的连接模块不是本文的重点,因此我们选择上述简单设计。
4. 应用
application:
我们的方法对于在深度卷积网络中构建特征金字塔是非常通用的。 接下来,我们在RPN中采用我们的方法来生成边界框建议,并在Fast R-CNN中采用我们的方法来进行对象检测。 为了证明我们方法的简单性和有效性,我们进行了最小的修改,以致于使这些网络适应我们的特征金字塔。
Feature Pyramid Networks for RPN
FPN for RPN:
RPN是一个滑动窗口类不可知的目标检测器。在原始的RPN设计中,一个小型子网络在密集的3×3滑动窗口,单尺度卷积特征图上进行评估,执行目标/非目标的二分类和边界框回归。这是通过一个3×3的卷积层实现的,后面跟着两个用于分类和回归的1×1兄弟卷积,我们称之为head。对象/非对象标准和边界框回归目标是称为“anchor”的一组参考框定义的。anchor具有多个预定义的比例和长宽比,以覆盖不同形状的对象。
我们通过用FPN替换单尺度特征图来调整RPN。我们在我们的特征金字塔的每个层级上附加一个相同设计的head(3x3 conv和两个1x1convs)。因为head在所有金字塔级上的每个位置都要滑动,所以不需要在特定层级上具有多尺度anchor。相反,我们为每个层级分配单尺度的锚点。在形式上,我们定义anchor在层级 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}分别有 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \{32^2,64^2,128^2,256^2,512^2\} {322,642,1282,2562,5122}的面积,长宽比为 { 1 : 2 , 1 : 1 , 2 : 1 } \{1:2,1:1,2:1\} {1:2,1:1,2:1},所以在金字塔中共有15种anchor。
基于anchor和ground truth bounding boxes的IoU,为每个anchor设置label。如果一个锚点对于一个给定的实际边界框具有最高的IoU或者与任何实际边界框的IoU超过0.7,则给其分配一个正标签,如果其与所有实际边界框的IoU都低于0.3,则为其分配一个负标签。请注意,ground truth box的尺度并未用于将它们分配到金字塔的层级;相反,实际边界框与已经分配给金字塔等级的anchor相关联。
我们注意到头部的参数在所有特征金字塔层级上共享;我们也评估了替代方案,没有共享参数并且观察到相似的准确性。共享参数的良好性能表明我们的金字塔的所有层级共享相似的语义级别。这个优点类似于使用特征图像金字塔的优点,其中可以将常见头部分类器应用于在任何图像尺度下计算的特征。
通过上述改编,RPN可以自然地通过我们的FPN进行训练和测试。
4.2 Feature Pyramid Networks for Fast R-CNN
FPN用于fast rcnn
Fast R-CNN是一个基于区域的目标检测器,利用感兴趣区域(RoI)池化来提取特征。Fast R-CNN通常在单尺度特征图上执行。要将其与我们的FPN一起使用,我们需要为金字塔等级分配不同尺度的RoI。
我们将我们的特征金字塔看作是从图像金字塔生成的。因此,当它们在图像金字塔上运行时,我们可以调整基于区域的检测器的分配策略。在形式上,我们通过以下公式将宽度为w和高度为h(在网络上的输入图像上)的RoI分配到特征金字塔的级别 P k P_k Pk上
k = [ k 0 + l o g 2 ( w h / 224 ) ] k=[k_0+log_2(\sqrt {wh}/224)] k=[k0+log2(wh/224)]
这里的224是规范的ImageNet预训练的尺寸, k 0 k_0 k0是 w × h = 22 4 2 w×h=224^2 w×h=2242大小的RoI应该映射到的目标等级。类似于基于resnet的faster rcnn系统用C4作为单尺度特征图,所以把 k 0 k_0 k0设为4。直观地说这个等式意味着如果RoI的尺度变小(224的1/2),它应该被映射到一个更精细的分辨率层(k=3)
我们把预测器的heads(faster rcnn中heads是分类器和边界框回归)和所有层的RoIs连接在一起。预测器heads都共享参数,不管他们在什么层级。我们仅仅采用了roi去提取7×7的特征,连接了两个隐藏1024d的全连接层(每层后面跟着relu),最后是分类和边界框回归。这些层是随机初始化的,因为ResNets中没有预先训练好的fc层。
基于这些改编,我们可以在特征金字塔之上训练和测试Fast R-CNN。实现细节在实验部分给出。
5. 目标检测实验
Experiments on Object Detection:
我们在80类的COCO检测数据集上进行实验。我们训练使用80k张训练图像和35k大小的验证图像子集(trainval35k)的联合,并展示了在5k大小的验证图像子集(minival)上的消融实验。我们还展示了在没有公开标签的标准测试集(test-std)上的最终结果。
正如通常的做法,所有的网络骨干都是在ImageNet1k分类集上预先训练好的,然后在检测数据集上进行微调。我们使用公开可用的预训练的ResNet-50和ResNet-101模型。我们的代码是使用Caffe2重新实现py-faster-rcnn。
5.1 Region Proposal with RPN
用RPN做区域提案
我们评估了COCO类型的平均召回率(AR),以及在小型中型和大型目标( A R s , A R m , A R l AR_s,AR_m,AR_l ARs,ARm,ARl)的AR,我们也展示了每张图100和1000个提案的结果( A R 100 , A R 1 k AR^{100},AR^{1k} AR100,AR1k)
完成细节:下列表格中所有的结构都是端到端训练的。输入图像的大小重新调整为短边800像素。我们在8个GPUs同步训练SGD。mini batch包括每个GPU上2张图像和每张图像上256个anchor。我们使用0.0001的权重衰退,0.9的动量。最开始30k的mini batch学习率是0.02,后10k是0.002。对于所有的RPN实验(包括baseline)超出图像的anchor box我们也都用于训练了,没有像faster rcnn忽略掉。在8个GPU上用COCO数据集训练带有FPN的RPN需要8个小时。
5.1.1 Ablation Experiments(消融实验)
comparisons with baselines.
为了与原始RPNs进行公平比较,我们使用C4或C5的单尺度特征图运行了两个baseline,都使用与我们相同的超参数,包括使用5种尺度锚点的单尺度映射运行了两个基线(表1(a,b)),都使用与我们相同的超参数,包括使用5种尺度 { 3 2 2 , 6 4 2 , 12 8 2 , 25 6 2 , 51 2 2 } \{32^2,64^2,128^2,256^2,512^2\} {322,642,1282,2562,5122}的anchor。表(b)显示没有优于(a),这表明单个更高级别的特征映射是不够的,因为存在在较粗分辨率和较强语义之间的权衡。
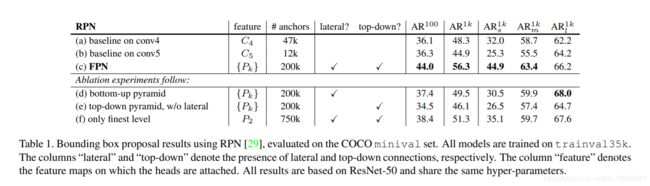
将FPN加入RPN可以将 A R 1 k AR^{1k} AR1k提高到56.3,比单尺度RPN提高了8个百分点。除此以外,在小的物体上( A R s 1 k AR_s^{1k} ARs1k)的表现增强了12.9个百分点。我们金字塔的表示极大程度上提高了RPN对于物体尺度变化的鲁棒性。
自上而下的改进有多重要?(d)显示了没有自上而下路径的特征金字塔的结果。通过这种修改,将1×1横向连接和后面的3×3卷积添加到自下而上的金字塔中。该架构模拟了重用金字塔特征层次结构的效果。
表1(d)中的结果与RPN baseline相当,并且远远落后于我们的方法。我们推测这是因为自下而上的金字塔的不同级别之间存在较大的语义鸿沟,尤其是对于非常深的ResNet。我们还评估了d中没有用head的参数变化,但是观察到了类似的性能下降。
横向连接有多重要? e显示了没有1×1横向连接的自顶向下特征金字塔的消融结果。这个自顶向下的金字塔具有强大的语义特征和良好的分辨率。但是我们认为这些特征的位置并不精确,因为这些映射已经进行了多次下采样和上采样。更精确的特征位置可以通过横向连接直接从自下而上映射的更精细层级传递到自上而下的映射。因此,FPN的 A R 1 k AR^{1k} AR1k得分比表1e高10个点。
金字塔表示有多重要? 我们将head附加到P2最高分辨率的强语义特征图上,来替代掉用金字塔表示。与单尺度基线类似,我们将所有anchor分配给P2特征映射。这个变体(f)比基线要好,但不如我们的方法。RPN是一个具有固定窗口大小的滑动窗口检测器,因此在金字塔层级上扫描可以增加其对尺度变化的鲁棒性。
另外,我们注意到由于P2较大的空间分辨率,单独使用P2会导致更多的anchor(750k)。这个结果表明,大量的anchor本身并不足以提高准确率。
5.2 Object Detection with Fast/Faster R-CNN
目标检测
接下来我们研究基于区域(没有滑动窗口)检测器的FPN。我们用COCO式平均精度(AP)和PASCAL式AP(单个IoU阈值为0.5)来评估目标检测。根据coco文章中的定义,我们还报告了小尺寸、中尺寸和大尺寸物体(即APs、apm和APl)的COCO-AP。
5.2.1 Fast R-CNN(on fixed proposals)
Fast R-CNN:
为了更好地调查FPN对仅基于区域的检测器的影响,我们在一组固定的提议上进行Fast R-CNN的消融。我们选择冻结RPN在FPN上计算的提议,因为它在能被检测器识别的小目标上具有良好的性能。为了简单起见,我们不在Fast R-CNN和RPN之间共享特征,除非指定。
用基于resnet的fast rcnn作为baseline,我们用输出为14×14的RoI pooling,连接conv5层作为head的隐藏层。这个AP是31.9。