【自动驾驶论文阅读笔记——精读QDTrack】
[阅读心得] 自动驾驶经典论文——QDTrack
- 写在前面
-
- 1. Abstract
- 2. Introduction
- 3. QDTrack
-
- 3.1 Object Detection
- 3.2 Quasi-Dense Similarity Learning
- 3.3 Loss
- 3.4 Association
- 4. Experiment
-
- 4.1 Main Result
- 4.2 Ablation Study
- 5. Analysis
写在前面
本文把关注点放在了MOT算法的REID环节,提出了“ReID环节学习不充分,且给予的重视程度不足,导致影响整体跟踪性能”的观点,使用contrastive learning的训练方法对ReID模型进行多正例学习,增强学习效果。
【论文】Quasi-Dense Similarity Learning for Multiple Object Tracking
【代码】https://github.com/SysCV/qdtrack
1. Abstract
提出了一种集成在检测器上的跟踪算法,QDTrack,利用一种稠密的相似度学习方法,对上百个region proposals进行对比学习。依次方法训练的ReID网络区分能力很好,仅用简单的associate方法就能获得很好的跟踪性能。QDTrack在MOT、BDD100K、Waymo、TAO等数据集中取得了优异的性能。
2. Introduction

本章主要围绕ReID和跟踪的关系表达了如下观点:
1)ReID在跟踪的地位低: 通常作为检测的后续环节进行,起辅助作用。这与人类完成跟踪任务中ReID的地位不同,人类可以仅依赖ReID完成跟踪。可以想象,在理想情况下,如果ReID网络能够出色地区分不同实例,则不需要其他花里胡哨(w\o bells and whistles)就能出色地完成跟踪;
2)ReID的效果不好: 这可能是由于其没有被完全训练好导致的,因为目前的工作中,ReID只利用了稀疏的Ground Truth进行训练,忽略了很多有价值的正例。
3)ReID的训练改进思考: 观察到GT稀疏地分布在图像中,除此之外还能有很多有训练价值的区域没有被利用:靠近GT的区域可以提供更多正例、背景区域可以提供更多负例。据此,本工作用一种Quasi-dense的学习方法,充分利用了图像的大部分学习进行相似度(ReID)学习
3. QDTrack
3.1 Object Detection
本文方法可以添加在现有的大多数检测器上,并完成端到端训练。本文中使用了Faster R-CNN+FPN作为检测器。
Faster R-CNN是两阶段检测器,用RPN生成RoI,后通过cls和loc分支完成分类和位置回归,检测部分的损失函数定义为RPN和分类、位置回归任务的损失函数的加权和:
L d e t = L r p n + λ 1 L c l s + λ 2 L r e g L_{det} = L_{rpn} + \lambda_1 L_{cls}+\lambda_2L_{reg} Ldet=Lrpn+λ1Lcls+λ2Lreg
其中, λ 1 , λ 2 \lambda_1,\lambda_2 λ1,λ2均设置为1.0
3.2 Quasi-Dense Similarity Learning
本节是本论文的主要工作,即通过多正例的形式来增强ReID的训练效果,利用RPN网络生成的region proposal,以quasi-dense matching的方法完成ReID网络的的学习。

网络的结构如上图所示:
- 一次训练需要输入两张图片 I 1 I_1 I1和 I 2 I_2 I2,其中 I 1 I_1 I1是用于训练的Key Frame, I 2 I_2 I2是在 I 1 I_1 I1附近3帧内随机选取的Reference Frame。
- 两图各自经过RPN网络生成RoI,后另接一个轻量的Embedding Head用于提取RoI的特征向量。
- 随后,对于两图的每个RoI,分别对GT依据IOU判别正负例:
I O U > α 1 IOU>\alpha_1 IOU>α1,判定为正例; I O U < α 2 IOU<\alpha_2 IOU<α2,判定为负例,其中 α 1 , α 2 \alpha_1,\alpha_2 α1,α2取0.7,0.3
3.3 Loss
L e m b e d = − ∑ k + l o g e x p ( v ⋅ k + ) e x p ( v ⋅ k + ) + ∑ k − e x p ( v ⋅ k − ) ( 1 ) L_{embed} = -\sum_{k^+} log\frac{exp(v \cdot k^+)}{exp(v\cdot k^+) + \sum_{k^-}exp(v \cdot k^-)}(1) Lembed=−∑k+logexp(v⋅k+)+∑k−exp(v⋅k−)exp(v⋅k+)(1)
其中, v v v表示Key Frame中的实例的embeddings, k k k表示Reference Frame中对应的实例的embeddings。
上式可以理解为,将v和k正例的距离拉近,v和k负例的距离远离,达到相似学习的目的。而且可以看出,上式对于key frame中每个样例,用到了多个对应的正负样本进行学习,这不同于之前的工作中只用到GT进行训练的设计。对样本空间利用更加充分。
然而上式存在一定的问题,即对Reference Frame中正负样例使用不均衡,每个正样例只用到了一次,而每个负样例被多次使用。因此,对上述公式进行了改进:
L e m b e d = l o g [ 1 + ∑ k + ∑ k − e x p ( v ⋅ k − − v ⋅ k + ) ] ( 2 ) L_{embed} = log[1 + \sum_{k^+}\sum_{k^-}exp(v \cdot k^- - v \cdot k^+)](2) Lembed=log[1+∑k+∑k−exp(v⋅k−−v⋅k+)](2)
且为了避免上述损失函数和余弦距离(v与k之间)出现梯度消失,添加了辅助损失函数:
L a u x = ( v ⋅ k ∣ ∣ v ∣ ∣ ⋅ ∣ ∣ k ∣ ∣ − c ) 2 ( 3 ) L_{aux} = (\frac{v \cdot k }{||v|| \cdot ||k||} - c)^2 (3) Laux=(∣∣v∣∣⋅∣∣k∣∣v⋅k−c)2(3)
因此,总的损失函数设计如下:
L = L d e t + γ 1 L e m b e d + γ 2 L a u x L = L_{det} + \gamma_1 L_{embed} + \gamma_2 L_{aux} L=Ldet+γ1Lembed+γ2Laux
其中, γ 1 = 0.25 , γ 2 = 1.0 \gamma_1=0.25, \gamma_2=1.0 γ1=0.25,γ2=1.0,正样例全部采用,负样例按照正样例数量的三倍进行采样
3.4 Association

在实际跟踪过程中,由于False Positive、ID Switch、New obj appear等情况,会导致目标和轨迹数目不对等的情况,而数目不对等的匹配是很困难的。而本文提出一种association策略一定程度上能够环节这一问题。
1) Bi-direction softmax
本文中相似度计算不用余弦距离,而是提出了一种新的计算规则,公式如下:
f ( i , j ) = [ e x p ( n i ⋅ m j ) ∑ k = 0 M − 1 e x p ( n i ⋅ m k ) + e x p ( n i ⋅ m j ) ∑ k = 0 N − 1 e x p ( n k ⋅ m j ) ] / 2 f(i,j) = [\frac{exp(n_i \cdot m_j)}{\sum_{k=0}^{M-1}exp(n_i \cdot m_k)} + \frac{exp(n_i \cdot m_j)}{\sum_{k=0}^{N-1}exp(n_k \cdot m_j)}]/2 f(i,j)=[∑k=0M−1exp(ni⋅mk)exp(ni⋅mj)+∑k=0N−1exp(nk⋅mj)exp(ni⋅mj)]/2
其中N,n表示当前帧中检测到的目标的embedding,M,m表示过去若干帧的待匹配轨迹。
由公式可知,bi-softmax计算了二者的双向相似性,即:前半部分度量了当前轨迹到目标的距离,后半部分度量了当前目标到所有轨迹的距离。
2) Backdrops
新出现的目标、消失的轨迹、错误的正例(FP)不应该被匹配成功,这一问题能够比较好地被bi-softmax解决:因为其会产生比较低的相似度分数。
此外,对于新出现的目标,如果置信度分数较高,就建立一个新的轨迹。
另外,剩下的没匹配上的目标(backdrops)被保留下来继续进行匹配,这样可以减少FP,这一操作不同于其他方法的直接丢弃。
3) Multi targets cases
大多检测器只做类内的NMS,但是一些情况下同一位置可能由两个cls,一个是TP另一个不是,所以有必要做类间NMS。
4. Experiment
4.1 Main Result
1) MOT
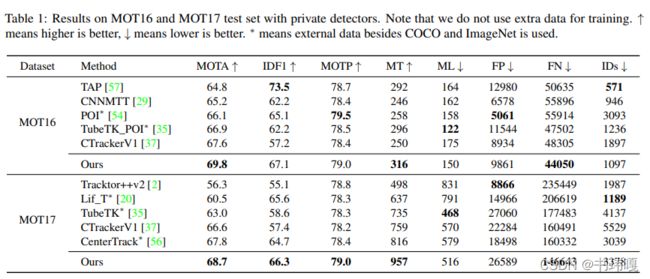
QDTrack的ID Switch并不低,作者的解释是这是因为召回率很高
Our method does not achieve a relatively low IDs, because we have a higher recall. The number of IDs will likely increase when we have more tracks. This is also why the results with public detectors have lower IDs, beacause their recall are lower(FN is higher)
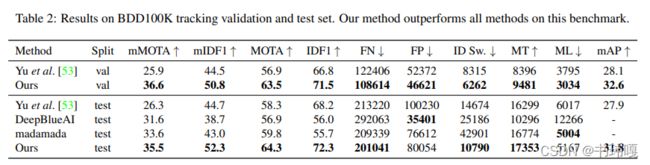
2) BDD100K
4.2 Ablation Study
1) Architecture

确实体现了QD训练和bi-softmax相似度的有效性。
2) Motion Module

实验结果表示,为QDTrack添加motion module并没有带来增益,作者的解释是因为他们的REID做的足够好了,所以不需要额外的模块辅助。但是实际上,BDD100K的跟踪标签是6FPS的,而视频是30FPS的,所以这会极大地影响运动模型的性能,后续自己做实验的时候要考虑这一点!!!
5. Analysis
总的来说,本文的视角很独特又很切实,确实在跟踪算法中,ReID环节很重要且受重视程度比较低。通过文章提出的方法确实有效地提高了ReID的训练和表现。
另外,本文相当于是在检测器Faster R-CNN的基础上做改进,调整成了跟踪器。这和之前做过的retinatrack、centertrack、yolop等算法在结构思路上有异曲同工之处,也再次印证了“目前有一种MOT的思路就是把一个检测器范式改成跟踪器”的观点。不过QDTrack很好地利用了Faster R-CNN的结构特点,充分利用了RPN网络,这点是很值得借鉴的,利用的很巧妙。
最后针对本工作,笔者还有一些自己的思考:
1)本方法似乎没有直接解决检测和REID之间的矛盾,是否在可以进一步改进,在backbone中更早地对这两个任务进行解耦?
2)本文章在训练时对每一帧图片仅选取另外的一帧参考图片进行学习,是否可以选取多帧图片进行训练,并增加时序信息,使网络鲁棒性更强?(必要性值得考虑)
3)Motion Module是否真的对此网络不必要?正如前面所说,BDD100K数据集本身对Motion Module不友好,应该在其他数据集比如MOT上再验证一下?