10分钟搞定 Spring 批处理组件 —— spring-batch
SpringBatch是什么
Spring Batch 是一个轻量级、全面的批处理框架,旨在支持开发对企业系统的日常运营至关重要的健壮批处理应用程序。Spring Batch 建立在人们所期望的 Spring Framework 的特性(生产力、基于 POJO 的开发方法和一般易用性)之上,同时使开发人员可以在必要时轻松访问和利用更先进的企业服务。Spring Batch 不是调度框架。在商业和开源空间中都有许多优秀的企业调度程序(例如 Quartz、Tivoli、Control-M 等)可用。它旨在与调度程序一起工作,而不是取代调度程序。 Spring Batch 提供了在处理大量记录时必不可少的可重用功能,包括日志记录/跟踪、事务管理、作业处理统计、作业重新启动、跳过和资源管理。它还提供更先进的技术服务和功能,通过优化和分区技术实现极高容量和高性能的批处理作业。Spring Batch 既可以用于简单的用例(例如将文件读入数据库或运行存储过程),也可以用于复杂的大容量用例(例如在数据库之间移动大量数据、对其进行转换等)上)。大批量批处理作业可以以高度可扩展的方式利用该框架来处理大量信息。
使用场景
一个典型的批处理程序通常:
- 从数据库、文件或队列中读取大量记录。
- 以某种方式处理数据。
- 以修改后的形式写回数据。
业务场景
- 定期提交批处理
- 并发批处理:一个作业的并行处理
- 分阶段的企业消息驱动处理
- 大规模并行批处理
- 失败后手动或计划重启
- 相关步骤的顺序处理(扩展工作流驱动的批处理)
- 部分处理:跳过记录(例如,在回滚时)
- 整批事务,适用于小批量或现有存储过程/脚本的情况
Spring Batch 架构
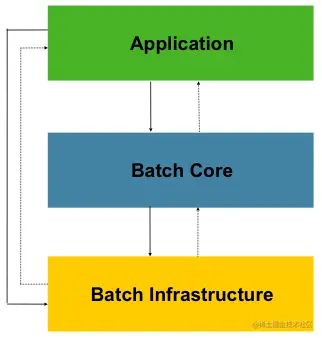
- Application 应用程序
- Batch Core 包含启动和控制批处理作业所需的核心运行时类。它包括 JobLauncher、Job和的实现Step
- Batch Infrastructure 基础架构
- 应用程序和Batch核心都建立在基础架构之上,此基础架构包含常见的读取器和写入器以及服务(RestTemplete),
一般批次原则和指南
在构建批处理解决方案时,应考虑以下关键原则、指南和一般注意事项。
-
请记住,批处理架构通常会影响在线架构,反之亦然。尽可能使用通用构建块进行设计,同时考虑架构和环境。
-
尽可能简化,避免在单批应用程序中构建复杂的逻辑结构。
-
将数据的处理和存储物理上紧密地结合在一起(换句话说,将您的数据保存在您进行处理的地方)。
-
最小化系统资源使用,尤其是 I/O。在内部存储器中执行尽可能多的操作。
-
查看应用程序 I/O(分析 SQL 语句)以确保避免不必要的物理 I/O。特别是,需要寻找以下四个常见缺陷:
- 当数据可以被读取一次并缓存或保存在工作存储中时,为每个事务读取数据。
- 重新读取在同一事务中较早读取数据的事务的数据。
- 导致不必要的表或索引扫描。
- 未在 SQL 语句的 WHERE 子句中指定键值。
-
不要在批处理中做两次。例如,如果您需要出于报告目的进行数据汇总,您应该(如果可能)在最初处理数据时增加存储的总数,这样您的报告应用程序就不必重新处理相同的数据。
-
在批处理应用程序开始时分配足够的内存,以避免在此过程中进行耗时的重新分配。
-
在数据完整性方面始终假设最坏的情况。插入足够的检查和记录验证以保持数据完整性。
-
尽可能为内部验证实施校验和。例如,平面文件应该有一个预告记录,告诉文件中的记录总数和关键字段的聚合。
-
在具有真实数据量的生产环境中尽早计划和执行压力测试。
-
在大批量系统中,备份可能具有挑战性,尤其是当系统以 24-7 的方式同时在线运行时。数据库备份通常在联机设计中得到很好的照顾,但文件备份应该被认为同样重要。如果系统依赖于平面文件,则文件备份程序不仅应到位并记录在案,而且还应定期进行测试
批处理策略
- 转换应用程序: 对于由外部系统提供或生成到外部系统的每种类型的文件,必须创建一个转换应用程序来将提供的交易记录转换为处理所需的标准格式。这种类型的批处理应用程序可以部分或全部由翻译实用程序模块组成(请参阅基本批处理服务)。
- 验证应用程序: 验证应用程序确保所有输入/输出记录正确且一致。验证通常基于文件头和尾、校验和和验证算法以及记录级交叉检查。
- 提取应用程序: 从数据库或输入文件中读取一组记录、根据预定义规则选择记录并将记录写入输出文件的应用程序。
- 提取/更新应用程序: 从数据库或输入文件中读取记录并根据在每个输入记录中找到的数据对数据库或输出文件进行更改的应用程序。
- 处理和更新应用程序: 对来自提取或验证应用程序的输入事务执行处理的应用程序。处理通常涉及读取数据库以获取处理所需的数据,可能会更新数据库并创建用于输出处理的记录。
- 输出/格式化应用程序: 读取输入文件、根据标准格式重组来自该记录的数据并生成输出文件以供打印或传输到另一个程序或系统的应用程序。
此外,应该为无法使用前面提到的构建块构建的业务逻辑提供一个基本的应用程序外壳。
除了主要构建块之外,每个应用程序都可以使用一个或多个标准实用程序步骤,例如:
- 排序:读取输入文件并生成输出文件的程序,其中记录已根据记录中的排序键字段重新排序。排序通常由标准系统实用程序执行。
- 拆分:读取单个输入文件并根据字段值将每条记录写入多个输出文件之一的程序。拆分可以由参数驱动的标准系统实用程序定制或执行。
- 合并:从多个输入文件中读取记录并使用来自输入文件的组合数据生成一个输出文件的程序。可以通过参数驱动的标准系统实用程序来定制或执行合并。
批处理应用程序还可以按其输入源进行分类:
- 数据库驱动的应用程序由从数据库中检索的行或值驱动。
- 文件驱动的应用程序由从文件中检索的记录或值驱动。
- 消息驱动的应用程序由从消息队列中检索的消息驱动。
任何批处理系统的基础都是处理策略。影响策略选择的因素包括:估计的批处理系统容量、与在线系统或其他批处理系统的并发性、可用的批处理窗口。(请注意,随着越来越多的企业希望 24x7 全天候运行,清晰的批处理窗口正在消失)。
批处理的典型处理选项是(按实现复杂度递增的顺序):
- 离线模式下批处理窗口期间的正常处理。
- 并发批处理或在线处理。
- 同时并行处理许多不同的批处理运行或作业。
- 分区(同时处理同一作业的多个实例)。
- 上述选项的组合。
商业调度程序可能支持这些选项中的一些或全部。
以下部分将更详细地讨论这些处理选项。重要的是要注意,根据经验,批处理采用的提交和锁定策略取决于执行的处理类型,并且在线锁定策略也应该使用相同的原则。因此,在设计整体架构时,批处理架构不能简单地成为事后的想法。
锁定策略可以是仅使用普通的数据库锁,也可以在架构中实现额外的自定义锁定服务。锁定服务将跟踪数据库锁定(例如,通过将必要的信息存储在专用的数据库表中)并授予或拒绝请求数据库操作的应用程序的权限。此架构还可以实现重试逻辑,以避免在锁定情况下中止批处理作业。
1.批处理窗口中的正常处理对于在单独的批处理窗口中运行的简单批处理,在线用户或其他批处理不需要正在更新的数据,并发不是问题,可以在单独的批处理窗口中完成单个提交批处理运行结束。
在大多数情况下,更稳健的方法更合适。请记住,批处理系统有随着时间的推移而增长的趋势,无论是在复杂性还是它们处理的数据量方面。如果没有锁定策略并且系统仍然依赖于单个提交点,那么修改批处理程序可能会很痛苦。因此,即使使用最简单的批处理系统,也要考虑重新启动恢复选项的提交逻辑的需求,以及本节后面描述的有关更复杂情况的信息。
2. 并发批处理或在线处理批处理应用程序处理在线用户可以同时更新的数据,不应锁定在线用户可能需要的任何数据(无论是在数据库中还是在文件中)超过一个几秒钟。此外,更新应该在每几个事务结束时提交到数据库。这最大限度地减少了其他进程不可用的数据部分以及数据不可用的经过时间。
最小化物理锁定的另一个选择是使用乐观锁定模式或悲观锁定模式实现逻辑行级锁定。
- 乐观锁定假设记录争用的可能性很小。这通常意味着在批处理和在线处理同时使用的每个数据库表中插入一个时间戳列。当应用程序获取一行进行处理时,它也会获取时间戳。当应用程序尝试更新已处理的行时,更新使用 WHERE 子句中的原始时间戳。如果时间戳匹配,则更新数据和时间戳。如果时间戳不匹配,这表明另一个应用程序在获取和更新尝试之间更新了同一行。因此,无法执行更新。
- 悲观锁定是任何锁定策略,它假定记录争用的可能性很高,因此需要在检索时获得物理或逻辑锁。一种悲观逻辑锁定在数据库表中使用专用的锁定列。当应用程序检索要更新的行时,它会在锁定列中设置一个标志。使用该标志,尝试检索同一行的其他应用程序在逻辑上会失败。当设置标志的应用程序更新行时,它也会清除标志,从而使其他应用程序能够检索该行。请注意,在初始获取和标志设置之间也必须保持数据的完整性,例如通过使用数据库锁(例如
SELECT FOR UPDATE)。另请注意,此方法与物理锁定有相同的缺点,只是它更容易管理构建一个超时机制,如果用户在记录被锁定时去吃午饭,则释放锁。
这些模式不一定适用于批处理,但它们可能用于并发批处理和在线处理(例如在数据库不支持行级锁定的情况下)。一般来说,乐观锁更适合在线应用,而悲观锁更适合批量应用。无论何时使用逻辑锁,所有访问受逻辑锁保护的数据实体的应用程序都必须使用相同的方案。
请注意,这两种解决方案都仅解决锁定单个记录的问题。通常,我们可能需要锁定一组逻辑相关的记录。使用物理锁,您必须非常小心地管理这些锁,以避免潜在的死锁。使用逻辑锁,通常最好构建一个逻辑锁管理器,该管理器了解您要保护的逻辑记录组,并且可以确保锁是连贯的和非死锁的。这个逻辑锁管理器通常使用自己的表来进行锁管理、争用报告、超时机制和其他问题。
3. 并行处理并行处理允许多个批处理运行或作业并行运行,以最大限度地减少批处理运行的总时间。只要作业不共享相同的文件、数据库表或索引空间,这不是问题。如果他们这样做,则应使用分区数据来实现此服务。另一种选择是构建一个架构模块,通过使用控制表来维护相互依赖关系。控制表应该包含每个共享资源的一行,以及它是否正在被应用程序使用。然后,批处理架构或并行作业中的应用程序将从该表中检索信息,以确定它是否可以访问所需的资源。
如果数据访问没有问题,可以通过使用额外的线程并行处理来实现并行处理。在大型机环境中,传统上使用并行作业类,以确保所有进程都有足够的 CPU 时间。无论如何,解决方案必须足够健壮,以确保所有运行进程的时间片。
并行处理中的其他关键问题包括负载平衡和通用系统资源(如文件、数据库缓冲池等)的可用性。另请注意,控制表本身很容易成为关键资源。
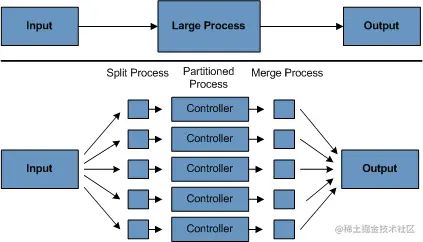
4. 分区使用分区允许多个版本的大批量应用程序同时运行。这样做的目的是减少处理长批处理作业所需的时间。可以成功分区的进程是可以拆分输入文件和/或对主数据库表进行分区以允许应用程序针对不同数据集运行的进程。
此外,必须将已分区的进程设计为仅处理其分配的数据集。分区架构必须与数据库设计和数据库分区策略密切相关。请注意,数据库分区并不一定意味着数据库的物理分区,尽管在大多数情况下这是可取的。下图说明了分区方法:
分区进程图:
代码实例
初始化数据库
-- BATCH JOB 实例表 包含与aJobInstance相关的所有信息
-- JOB ID由batch_job_seq分配
-- JOB 名称,与spring配置一致
-- JOB KEY 对job参数的MD5编码,正因为有这个字段的存在,同一个job如果第一次运行成功,第二次再运行会抛出JobInstanceAlreadyCompleteException异常。
CREATE TABLE BATCH_JOB_INSTANCE (
JOB_INSTANCE_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_NAME VARCHAR(100) NOT NULL,
JOB_KEY VARCHAR(32) NOT NULL,
constraint JOB_INST_UN unique (JOB_NAME, JOB_KEY)
) ENGINE=InnoDB;
-- 该BATCH_JOB_EXECUTION表包含与该JobExecution对象相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT ,
JOB_INSTANCE_ID BIGINT NOT NULL,
CREATE_TIME DATETIME NOT NULL,
START_TIME DATETIME DEFAULT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
JOB_CONFIGURATION_LOCATION VARCHAR(2500) NULL,
constraint JOB_INST_EXEC_FK foreign key (JOB_INSTANCE_ID)
references BATCH_JOB_INSTANCE(JOB_INSTANCE_ID)
) ENGINE=InnoDB;
-- 该表包含与该JobParameters对象相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION_PARAMS (
JOB_EXECUTION_ID BIGINT NOT NULL ,
TYPE_CD VARCHAR(6) NOT NULL ,
KEY_NAME VARCHAR(100) NOT NULL ,
STRING_VAL VARCHAR(250) ,
DATE_VAL DATETIME DEFAULT NULL ,
LONG_VAL BIGINT ,
DOUBLE_VAL DOUBLE PRECISION ,
IDENTIFYING CHAR(1) NOT NULL ,
constraint JOB_EXEC_PARAMS_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该表包含与该StepExecution 对象相关的所有信息
CREATE TABLE BATCH_STEP_EXECUTION (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY ,
VERSION BIGINT NOT NULL,
STEP_NAME VARCHAR(100) NOT NULL,
JOB_EXECUTION_ID BIGINT NOT NULL,
START_TIME DATETIME NOT NULL ,
END_TIME DATETIME DEFAULT NULL ,
STATUS VARCHAR(10) ,
COMMIT_COUNT BIGINT ,
READ_COUNT BIGINT ,
FILTER_COUNT BIGINT ,
WRITE_COUNT BIGINT ,
READ_SKIP_COUNT BIGINT ,
WRITE_SKIP_COUNT BIGINT ,
PROCESS_SKIP_COUNT BIGINT ,
ROLLBACK_COUNT BIGINT ,
EXIT_CODE VARCHAR(2500) ,
EXIT_MESSAGE VARCHAR(2500) ,
LAST_UPDATED DATETIME,
constraint JOB_EXEC_STEP_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该BATCH_STEP_EXECUTION_CONTEXT表包含ExecutionContext与Step相关的所有信息
CREATE TABLE BATCH_STEP_EXECUTION_CONTEXT (
STEP_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint STEP_EXEC_CTX_FK foreign key (STEP_EXECUTION_ID)
references BATCH_STEP_EXECUTION(STEP_EXECUTION_ID)
) ENGINE=InnoDB;
-- 该表包含ExecutionContext与Job相关的所有信息
CREATE TABLE BATCH_JOB_EXECUTION_CONTEXT (
JOB_EXECUTION_ID BIGINT NOT NULL PRIMARY KEY,
SHORT_CONTEXT VARCHAR(2500) NOT NULL,
SERIALIZED_CONTEXT TEXT ,
constraint JOB_EXEC_CTX_FK foreign key (JOB_EXECUTION_ID)
references BATCH_JOB_EXECUTION(JOB_EXECUTION_ID)
) ENGINE=InnoDB;
CREATE TABLE BATCH_STEP_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_STEP_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_STEP_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_EXECUTION_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_EXECUTION_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_EXECUTION_SEQ);
CREATE TABLE BATCH_JOB_SEQ (
ID BIGINT NOT NULL,
UNIQUE_KEY CHAR(1) NOT NULL,
constraint UNIQUE_KEY_UN unique (UNIQUE_KEY)
) ENGINE=InnoDB;
INSERT INTO BATCH_JOB_SEQ (ID, UNIQUE_KEY) select * from (select 0 as ID, '0' as UNIQUE_KEY) as tmp where not exists(select * from BATCH_JOB_SEQ);
-- 新建student业务表
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`age` int(11) NOT NULL,
`sex` varchar(20) NOT NULL,
`address` varchar(100) NOT NULL,
`cid` int(11) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8;
复制代码新建SpringBoot项目
pom文件
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.7.2
com.example.springbatch
demo
0.0.1-SNAPSHOT
demo
Demo project for Spring Boot
1.8
org.springframework.boot
spring-boot-starter-batch
org.springframework.boot
spring-boot-starter-test
test
org.springframework.batch
spring-batch-test
test
org.projectlombok
lombok
1.18.12
compile
org.springframework.boot
spring-boot-starter-data-jpa
2.7.2
compile
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-maven-plugin
复制代码配置文件
server:
port: 9876
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/test?serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true
hikari:
password: 12345678
username: root
jpa:
open-in-view: true
show-sql: true
hibernate:
ddl-auto: update
database: mysql
# 禁止项目启动时运行job
batch:
job:
enabled: false
复制代码创建Student实体类;要操作的业务数据
package com.example.springbatch.demo.model;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import javax.persistence.*;
/**
* @author yingtao
* @ClassName Student
* @description: TODO
* @datetime 2022年 08月 12日 14:00
* @version: 1.0
*/
@Data
@Entity
@Table(name = "student")
@NoArgsConstructor
@AllArgsConstructor
public class Student {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private Integer age;
private String sex;
private String address;
private Integer cid;
}
复制代码创建线程池
此线程池主要是为了体现多任务并行处理
@Configuration
public class ExecutorConfiguration {
@Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor threadPoolTaskExecutor = new ThreadPoolTaskExecutor();
threadPoolTaskExecutor.setCorePoolSize(5);
threadPoolTaskExecutor.setMaxPoolSize(10);
threadPoolTaskExecutor.setQueueCapacity(50);
threadPoolTaskExecutor.setThreadNamePrefix("Data-Job");
return threadPoolTaskExecutor;
}
}
复制代码创建Job
由上述简述可知,BatchCore中会包含基本的Job,用来处理数据的核心。一个Job由多个Step组成,比如:做菜这个Job由洗菜,切菜,炒菜这三个Step组成,我们再业务中也会存在这种复杂多步骤的业务处理流程。
一个基本的job一般由至少一个Step组成。
一个Step一般由三部分组成
ItemReader读取数据ItemProcessor处理数据ItemWriter写数据
代理示例:
package com.example.springbatch.demo.task.job;
import com.example.springbatch.demo.model.Student;
import com.example.springbatch.demo.task.listener.JobListener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.core.launch.support.RunIdIncrementer;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.batch.item.ItemReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.item.database.JpaPagingItemReader;
import org.springframework.batch.item.database.orm.JpaNativeQueryProvider;
import org.springframework.stereotype.Component;
import javax.persistence.EntityManagerFactory;
/**
* @author yingtao
* @ClassName DataBatchJob
* @description: TODO
* @datetime 2022年 08月 12日 14:00
* @version: 1.0
*/
@Slf4j
@Component
public class DataBatchJob {
/**
* Job构建工厂,用于构建Job
*/
private final JobBuilderFactory jobBuilderFactory;
/**
* Step构建工厂,用于构建Step
*/
private final StepBuilderFactory stepBuilderFactory;
/**
* 实体类管理工工厂,用于访问表格数据
*/
private final EntityManagerFactory emf;
/**
* 自定义的简单Job监听器
*/
private final JobListener jobListener;
public DataBatchJob(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory,
EntityManagerFactory emf, JobListener jobListener) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
this.emf = emf;
this.jobListener = jobListener;
}
/**
* 一个最基础的Job通常由一个或者多个Step组成
*/
public Job dataHandleJob() {
return jobBuilderFactory.get("dataHandleJob").
incrementer(new RunIdIncrementer()).
// start是JOB执行的第一个step
start(handleDataStep()).
// 可以调用next方法设置其他的step,例如:
// next(xxxStep()).
// next(xxxStep()).
// ...
// 设置我们自定义的JobListener
listener(jobListener).
build();
}
/**
* 一个简单基础的Step主要分为三个部分
* ItemReader : 用于读取数据
* ItemProcessor : 用于处理数据
* ItemWriter : 用于写数据
* @return
*/
private Step handleDataStep() {
return stepBuilderFactory.get("getData").
// <输入对象, 输出对象> chunk通俗的讲类似于SQL的commit; 这里表示处理(processor)100条后写入(writer)一次
chunk(100).
// 捕捉到异常就重试,重试100次还是异常,JOB就停止并标志失败
faultTolerant().retryLimit(3).retry(Exception.class).skipLimit(100).skip(Exception.class).
// 指定ItemReader对象
reader(getDataReader()).
// 指定ItemProcessor对象
processor(getDataProcessor()).
// 指定ItemWriter对象
writer(getDataWriter()).
build();
}
/**
* 读取数据
*
* @return ItemReader Object
*/
private ItemReader getDataReader() {
// 读取数据,这里可以用JPA,JDBC,JMS 等方式读取数据
JpaPagingItemReader reader = new JpaPagingItemReader<>();
try {
// 这里选择JPA方式读取数据
JpaNativeQueryProvider queryProvider = new JpaNativeQueryProvider<>();
// 一个简单的 native SQL
queryProvider.setSqlQuery("SELECT * FROM student");
// 设置实体类
queryProvider.setEntityClass(Student.class);
queryProvider.afterPropertiesSet();
reader.setEntityManagerFactory(emf);
// 设置每页读取的记录数
reader.setPageSize(3);
// 设置数据提供者
reader.setQueryProvider(queryProvider);
reader.afterPropertiesSet();
// 所有ItemReader和ItemWriter实现都会在ExecutionContext提交之前将其当前状态存储在其中,
// 如果不希望这样做,可以设置setSaveState(false)
reader.setSaveState(true);
} catch (Exception e) {
e.printStackTrace();
}
return reader;
}
/**
* 处理数据
*
* @return ItemProcessor Object
*/
private ItemProcessor getDataProcessor() {
return student -> {
// 模拟处理数据,这里处理就是打印一下
log.info("processor data : " + student.toString());
return student;
};
}
/**
* 写入数据
*
* @return ItemWriter Object
*/
private ItemWriter getDataWriter() {
return list -> {
for (Student student : list) {
// 模拟写数据,为了演示的简单就不写入数据库了
log.info("write data : " + student);
}
};
}
}
复制代码 监听
我们需要自定义个监听器。在批处理作业在执行前后会调用监听器的方法;执行额外的统一逻辑
package com.example.springbatch.demo.task.listener;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.BatchStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;
import org.springframework.stereotype.Component;
/**
* @author yingtao
* @ClassName JobListener
* @description: 一个作业的监听器,批处理作业在执行前后会调用监听器的方法;这样我们就可以根据实际的业务需求在作业执行的前后进行一些日志的打印或者逻辑处理等
* @datetime 2022年 08月 12日 14:01
* @version: 1.0
*/
@Slf4j
@Component
public class JobListener implements JobExecutionListener {
private final ThreadPoolTaskExecutor threadPoolTaskExecutor;
private long startTime;
@Autowired
public JobListener(ThreadPoolTaskExecutor threadPoolTaskExecutor) {
this.threadPoolTaskExecutor = threadPoolTaskExecutor;
}
/**
* 该方法会在job开始前执行
*/
@Override
public void beforeJob(JobExecution jobExecution) {
startTime = System.currentTimeMillis();
log.info("job before " + jobExecution.getJobParameters());
}
/**
* 该方法会在job结束后执行
*/
@Override
public void afterJob(JobExecution jobExecution) {
log.info("JOB STATUS : {}", jobExecution.getStatus());
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
log.info("JOB FINISHED");
threadPoolTaskExecutor.destroy();
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
log.info("JOB FAILED");
}
log.info("Job Cost Time : {}/ms", (System.currentTimeMillis() - startTime));
}
}
复制代码模拟业务:定时读取数据库数据写入到缓存
package com.example.springbatch.demo.task;
import com.example.springbatch.demo.task.job.DataBatchJob;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.*;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.JobParametersInvalidException;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.batch.core.repository.JobExecutionAlreadyRunningException;
import org.springframework.batch.core.repository.JobInstanceAlreadyCompleteException;
import org.springframework.batch.core.repository.JobRestartException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
/**
* @author yingtao
* @ClassName TimeTask
* @description: TODO
* @datetime 2022年 08月 12日 14:01
* @version: 1.0
*/
@Slf4j
@Component
public class TimeTask {
private final JobLauncher jobLauncher;
private final DataBatchJob dataBatchJob;
@Autowired
public TimeTask(JobLauncher jobLauncher, DataBatchJob dataBatchJob) {
this.jobLauncher = jobLauncher;
this.dataBatchJob = dataBatchJob;
}
// 定时任务,每十秒执行一次
@Scheduled(cron = "0/10 * * * * ?")
public void runBatch() throws JobParametersInvalidException, JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException {
log.info("定时任务执行了...");
// 在运行一个job的时候需要添加至少一个参数,这个参数最后会被写到batch_job_execution_params表中,
// 不添加这个参数的话,job不会运行,并且这个参数在表中中不能重复,若设置的参数已存在表中,则会抛出异常,
// 所以这里才使用时间戳作为参数
JobParameters jobParameters = new JobParametersBuilder()
.addLong("timestamp", System.currentTimeMillis())
.toJobParameters();
// 获取job并运行
Job job = dataBatchJob.dataHandleJob();
JobExecution execution = jobLauncher.run(job, jobParameters);
log.info("定时任务结束. Exit Status : {}", execution.getStatus());
}
}
复制代码上述代码中我们定义了一个定时任务去调用定义的批处理Job,用到的主要方法是jobLauncher.run(job, jobParameters); 此方法可以让我们自定义主动去调用定义好的Job.
最后需要在启动类上添加两个注解:
@EnableScheduling // 定时任务
@EnableBatchProcessing
@SpringBootApplication // 用于开启批处理作业的配置
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
复制代码运行结果:
2022-08-12 15:15:50.005 INFO 37100 --- [ scheduling-1] c.e.springbatch.demo.task.TimeTask : 定时任务执行了...
2022-08-12 15:15:50.137 INFO 37100 --- [ scheduling-1] o.s.b.c.l.support.SimpleJobLauncher : Job: [SimpleJob: [name=dataHandleJob]] launched with the following parameters: [{timestamp=1660288550007}]
2022-08-12 15:15:50.157 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.listener.JobListener : job before {timestamp=1660288550007}
2022-08-12 15:15:50.171 INFO 37100 --- [ scheduling-1] o.s.batch.core.job.SimpleStepHandler : Executing step: [getData]
Hibernate: SELECT * FROM student limit ?
Hibernate: SELECT * FROM student limit ?, ?
Hibernate: SELECT * FROM student limit ?, ?
2022-08-12 15:15:50.262 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=1, name=阿基米德, age=22, sex=男, address=希腊, cid=1)
2022-08-12 15:15:50.262 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=2, name=张三, age=21, sex=男, address=张家口, cid=1)
2022-08-12 15:15:50.262 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=3, name=李四, age=11, sex=女, address= 湖南, cid=2)
2022-08-12 15:15:50.263 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=4, name=朱朱, age=19, sex=女, address=湖南, cid=2)
2022-08-12 15:15:50.263 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=5, name=张武, age=11, sex=男, address=北京, cid=3)
2022-08-12 15:15:50.263 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=6, name=牛顿, age=22, sex=男, address=希腊, cid=4)
2022-08-12 15:15:50.263 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=7, name=戴维斯, age=39, sex=男, address=法国, cid=5)
2022-08-12 15:15:50.263 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : processor data : Student(id=8, name=詹姆斯, age=22, sex=男, address=美国, cid=6)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=1, name=阿基米德, age=22, sex=男, address=希腊, cid=1)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=2, name=张三, age=21, sex=男, address=张家口, cid=1)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=3, name=李四, age=11, sex=女, address= 湖南, cid=2)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=4, name=朱朱, age=19, sex=女, address=湖南, cid=2)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=5, name=张武, age=11, sex=男, address=北京, cid=3)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=6, name=牛顿, age=22, sex=男, address=希腊, cid=4)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=7, name=戴维斯, age=39, sex=男, address=法国, cid=5)
2022-08-12 15:15:50.264 INFO 37100 --- [ scheduling-1] c.e.s.demo.task.job.DataBatchJob : write data : Student(id=8, name=詹姆斯, age=22, sex=男, address=美国, cid=6)
2022-08-12 15:15:50.273 INFO 37100 --- [ scheduling-1] o.s.batch.core.step.AbstractStep : Step: [getData] executed in 102ms
2022-08-12 15:15:50.293 INFO 37100 --- [ scheduling-1] o.s.batch.core.job.SimpleStepHandler : Executing step: [second staep]
复制代码