Keras中如何设置学习率和优化器以及两者之间的关系
在集成式机器学习类库Keras中,对优化器和学习率做了很好的封装,以至于很多人搞不清楚怎么设置学习率,怎么使用优化器,两者到底有什么区别。
不同的学习率对模型训练过程中的损失值loss影响如下图所示,好的学习率可以使得模型的loss即下降的快,又能达到很低的值。而设置不当的优化器,要么梯度下降的速度很慢,要么梯度反复震荡,或者陷入局部极值导致loss难以降低。
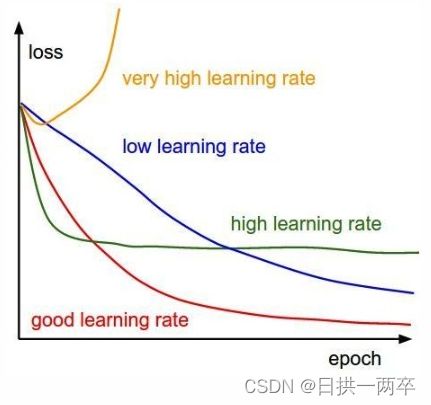
零、基本概念
优化器(optimizer) 的主要功能是在梯度下降的过程中,使得梯度更快更好的下降,从而尽快找到目标函数的最小值。
学习率(LearningRate) 是优化器中会用到的一个重要的参数。
然而学习率又不是和优化器完全独立开的,因为学习率可以作为一个固定的参数传入优化器中(SGD);也可以在优化器中对传入的学习率进行自适应衰减计算(Adam);或者干脆不传入学习率参数,而是通过每次迭代中动量参数的变化动态生成学习率(Adadelta)。
之前我花了一周时间整理了常见的11种优化器的原理和推导过程的文章,可以作为扩展内容学习一下,链接如下:机器学习各优化器推导过程详解(SGD,BGD,MBGD.Momentum,NAG,Adagrad,Adadelta,RMSprop,Adam,Nadma,Adamx)_日拱一两卒的博客-CSDN博客 https://forecast.blog.csdn.net/article/details/124882119?spm=1001.2014.3001.5502
https://forecast.blog.csdn.net/article/details/124882119?spm=1001.2014.3001.5502
通过上面的文章可以了解到学习率和优化函数之间的理论关系,下面直接讲一下在Keras种如何设置优化器和学习率等参数。
一、常规定义参数法
首先定义一个优化器,在优化器中设置学习率,这里我们定义一个SGD优化器:
from keras import optimizers
sgd = optimizers.SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True)参数说明:
lr:大或等于0的浮点数,学习率LearningRate,可以自己定义大小;
decay:衰减率,用于对学习率进行衰减运算
momentum:大或等于0的浮点数,动量参数
nesterov:布尔值,确定是否使用Nesterov动量
注:如果想设置成固定学习率,只要把衰减率decay和动量momentum都设置为0即可
将定义好参数的优化器带入模型:
model = Sequential()
model.compile(loss='mean_squared_error', optimizer=sgd)二、通过回调函数实现自定义学习率
使用回调函数流程:
1.首先定义了一个学习率随着训练周期epoch更新的算法myScheduler
2.用LearningRateScheduler定义个回调函数
3.在model.fit()中配置回调参数callbacks=,即可在每轮训练中按照给定算法更新学习率
核心部分代码示例,细节见代码注释:
import keras.backend as K
from keras.callbacks import LearningRateScheduler
# 定义一个学习率更新函数
def myScheduler(epoch):
# 每隔100个epoch,学习率减小为原来的1/10
if epoch % 100 == 0 and epoch != 0:
# 获取在model.compile()中设置的学习率lr
lr = K.get_value(model.optimizer.lr)
# 按照lr * 0.1,重新更新学习率
K.set_value(model.optimizer.lr, lr * 0.1)
return K.get_value(model.optimizer.lr)
# 定义一个学习率的回调函数
myReduce_lr = LearningRateScheduler(myScheduler)
model= Sequential()
sgd= SGD(lr=0.1, momentum=0.9, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
# 在模型中调用这个回调函数,模型在训练的过程中就会按照定义的算法myReduce_lr自动更新学习率。
# 这里注意参数类型要为数组类型
model.fit(train_x, train_y, batch_size=32, epochs=300, callbacks=[myReduce_lr])三、当评价指标不再提升时,更新学习率
当学习停滞时,减少2倍或10倍的学习率常常能获得较好的效果。该回调函数检测指标的情况,如果在patience个epoch中看不到模型性能提升,则减少学习率。
参数说明:
monitor:被监测的量
factor:每次减少学习率的因子,学习率将以lr = lr*factor的形式被减少
patience:当patience个epoch过去而模型性能不提升时,学习率减少的动作会被触发
mode:‘auto’,‘min’,‘max’之一,在min模式下,如果检测值触发学习率减少。在max模式下,当检测值不再上升则触发学习率减少。
epsilon:阈值,用来确定是否进入检测值的“平原区”
cooldown:学习率减少后,会经过cooldown个epoch才重新进行正常操作
min_lr:学习率的下限
代码示例:
from keras.callbacks import ReduceLROnPlateau
myReduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=10, verbose=0, mode='auto', epsilon=0.0001, cooldown=0, min_lr=0)
model.fit(train_x, train_y, batch_size=32, epochs=300, validation_split=0.1, callbacks=[myReduce_lr])四、收集的其他一些示例
示例一、常规学习率设置
按照epoch的次数自动调整学习率,每10轮下降50%的学习率
def step_decay(epoch):
initial_lrate = 0.01
drop = 0.5
epochs_drop = 10.0
lrate = initial_lrate * math.pow(drop,math.floor((1+epoch)/epochs_drop))
return lrate
lrate = LearningRateScheduler(step_decay)
sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False)
model.fit(train_set_x, train_set_y, validation_split=0.1, nb_epoch=200, batch_size=256, callbacks=[lrate])
示例二、衰减学习率设置
随机梯度下降的学习率设定为0.1。该模型训练了50个周期,衰变参数设置为0.002,计算为0.1 / 50,在使用自适应学习率时,动量值设置为0.8
# Time Based Learning Rate Decay
from pandas import read_csv
import numpy
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from sklearn.preprocessing import LabelEncoder
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = read_csv(“ionosphere.csv”, header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:34].astype(float)
Y = dataset[:,34]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
Y = encoder.transform(Y)
# create model
model = Sequential()
model.add(Dense(34, input_dim=34, kernel_initializer=’normal’, activation=’relu’))
model.add(Dense(1, kernel_initializer=’normal’, activation=’sigmoid’))
# Compile model
epochs = 50
learning_rate = 0.1
decay_rate = learning_rate / epochs
momentum = 0.8
sgd = SGD(lr=learning_rate, momentum=momentum, decay=decay_rate, nesterov=False)
model.compile(loss=’binary_crossentropy’, optimizer=sgd, metrics=[‘accuracy’])
# Fit the model
model.fit(X, Y, validation_split=0.33, epochs=epochs, batch_size=28, verbose=2)示例三、分段学习率设置
通过到每一个固定周期时学习率减半来实现。例如,初始学习率为0.01,每10个周期下降0.5。前10个训练周期将使用0.01的值,在接下来的10-20个周期,将使用0.05的学习率,在20-30周期,使用0.025等等。将这个例子的学习率绘制到100个周期,你可以得到下面的图表。显示学习率(y轴)与周期(x轴)的关系。
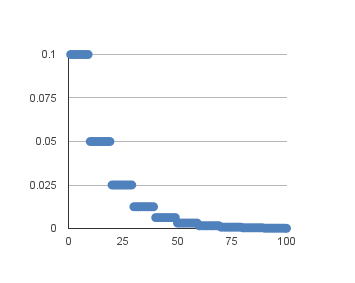
定义一个算法即可实现:lr= Initial_lr * DropRate^floor(Epoch/ EpochDrop) 。
Initial_lr是初始学习率,如0.1。
DropRate是每次改变时学习率修改的量,如0.5。
Epoch是当前的周期数,EpochDrop是学习率改变的频率,如10 。
# Drop-Based Learning Rate Decay
import pandas
from pandasimport read_csv
import numpy
import math
from keras.modelsimport Sequential
from keras.layersimport Dense
from keras.optimizersimport SGD
from sklearn.preprocessingimport LabelEncoder
from keras.callbacksimport LearningRateScheduler
# learning rate schedule
def step_decay(epoch):
initial_lrate= 0.1
drop= 0.5
epochs_drop= 10.0
lrate= initial_lrate* math.pow(drop, math.floor((1+epoch)/epochs_drop))
return lrate
# fix random seed for reproducibility
seed= 7
numpy.random.seed(seed)
# load dataset
dataframe= read_csv("ionosphere.csv", header=None)
dataset= dataframe.values
# split into input (X) and output (Y) variables
X= dataset[:,0:34].astype(float)
Y= dataset[:,34]
# encode class values as integers
encoder= LabelEncoder()
encoder.fit(Y)
Y= encoder.transform(Y)
# create model
model= Sequential()
model.add(Dense(34, input_dim=34, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
sgd= SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
# learning schedule callback
lrate= LearningRateScheduler(step_decay)
callbacks_list= [lrate]
# Fit the model
model.fit(X, Y, validation_split=0.33, epochs=50, batch_size=28, callbacks=callbacks_list, verbose=2)示例四、指数衰减学习率设置
另一个常见的时间表是指数衰减。 它具有数学形式lr = lr0 * e^(-kt),其中lr,k是超参数,t是迭代数。 同样,我们可以通过定义指数衰减函数并将其传递给LearningRateScheduler来实现。 实际上,可以使用此方法在Keras中实现任何自定义衰减时间表。 唯一的区别是定义了不同的自定义衰减函数。
def exp_decay(epoch):
initial_lrate = 0.1
k = 0.1
lrate = initial_lrate * exp(-k*t)
return lrate
lrate = LearningRateScheduler(exp_decay)
示例五、自适应学习率使用
keras类库自带的一些优化器,可以自适应的调整学习率大小。
keras.optimizers.Adagrad(lr=0.01, epsilon=1e-08, decay=0.0)
keras.optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=1e-08, decay=0.0)
keras.optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)