新版mmdetection跑通自己的voc数据集【2020MMdetection】【详细】
问题:
用新版mmdetection跑通自己的数据集。数据集的格式是voc格式的。
解决办法:
一、数据集准备
将所有的图片放在
./data/VOCdevkit/VOC2007/JPEGImage
将所有的标签放在
./data/VOCdevkit/VOC2007/Annotations
将图片划分训练集、验证集和测试集,名字存在txt文件里
./data
└── VOCdevkit
└── VOC2007
├── Annotations # 标注的VOC格式的xml标签文件
├── JPEGImages # 数据集图片
└── ImageSet
└── Main
├── test.txt # 划分的测试集
├── train.txt # 划分的训练集
├── trainval.txt
└── val.txt # 划分的验证集
划分代码在下面,将生成4个txt文件:
#读取文件夹下的文件并将其文件名(无后缀)分成4份保存在保存在一个txt文件中
#作者:阿玉
#时间:2020.5.12
#说明:文件分为训练集、验证集和测试集,tranval为训练集和验证机的合集。
#为了划分数据集写的
#可修改参数:将被划分的文件夹路径,存储txt文件的路径及4个文件的名字,固定随机数的seed,
#训练集和验证集的占比,共8个参数
import os
import random
trainval_percent = 0.8 #确定用于训练的数据占比
train_percent = 0.75 #确定在用于训练的数据中,训练集的占比
xmlfilepath = r'F:\AdatabaseForGraduation\vocModify\all_voc' #将被划分的xml文件
txtsavepath = r'F:\AdatabaseForGraduation\vocModify' #划分后 得到的txt保存的地方
#固定随机数的生成
random.seed(4)
total_xml = os.listdir(xmlfilepath) #读取文件夹下所有文件的名字
num = len(total_xml) #文件夹下文件的数目
list = range(num)
tv = int(num * trainval_percent) #trainval的数目
tr = int(tv * train_percent) #train的数目
trainval = random.sample(list, tv) #被选中的文件编号
train = random.sample(trainval, tr)
ftrainval = open(os.path.join(txtsavepath,'trainval.txt'), 'w') #打开文件等待写入
ftest = open(os.path.join(txtsavepath,'test.txt'), 'w')
ftrain = open(os.path.join(txtsavepath,'train.txt'), 'w')
fval = open(os.path.join(txtsavepath,'val.txt'), 'w')
for i in list:
name = total_xml[i][:-4] + '\n' #去后缀,换行
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
附
坏图检测程序,程序报 NoneType has no attribute to shape很可能数据集中有坏图,可以先查一遍是不是数据出错,再考虑程序问题。
# coding=utf-8
import os.path
import cv2 #导入opencv库
path = r'/data/scratchData/VOCdevkit/VOC2007/JPEGImages'
# 得到文件夹下所有文件名称
pics = os.listdir(path)
i = 1
for pic_name in pics: # 遍历文件夹
#print('修改第' + str(i) + '个pic' + ' 名字是:' + pic_name)
i = i + 1
# 得到一个pic完整的路径
pic_path = os.path.join(path, pic_name)
img1 = cv2.imread(pic_path, cv2.IMREAD_GRAYSCALE) # 读取图片,第二个参数表示以灰度图像读入
if img1 is None: # 判断读入的img1是否为空,为空就继续下一轮循环
print(img1,pic_path,'这是一张坏图')
二、mmdetection参数修改
1、修改模型配置文件
(如果不想直接替换可以重新命名一个文件,运行的时候调用新文件即可)
./mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py
我的做法是复制了一份并改名为:
./mmdetection/configs/faster_rcnn/faster_rcnn_r50_fpn_1x_voc.py
修改内容如下:
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn_voc.py',
'../_base_/datasets/voc0712.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
将数据处理部分调用的文件由coco_detection改成了voc0712.
2、修改数据配置文件
./mmdetection/configs/_base_/datasets/voc712.py
注释掉VOC2012的路径即可。因为我们只用了VOCC2007,没有创建VOC2012,不注释会报错。修改后内容如下,
# dataset settings
dataset_type = 'VOCDataset'
data_root = 'data/VOCdevkit/'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations', with_bbox=True),
dict(type='Resize', img_scale=(1000, 600), keep_ratio=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels']),
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1000, 600),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=32),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
data = dict(
samples_per_gpu=2,
workers_per_gpu=2,
train=dict(
type='RepeatDataset',
times=3,
dataset=dict(
type=dataset_type,
ann_file=[
# data_root + 'VOC2007/ImageSets/Main/trainval.txt',
# data_root + 'VOC2012/ImageSets/Main/trainval.txt'
data_root + 'VOC2007/ImageSets/Main/trainval.txt'
],
# img_prefix=[data_root + 'VOC2007/', data_root + 'VOC2012/'],
img_prefix=[data_root + 'VOC2007/'],
pipeline=train_pipeline)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
pipeline=test_pipeline))
evaluation = dict(interval=1, metric='mAP')
3、修改模型文件中的类别数
./mmdetection/configs/_base_/models/faster_rcnn_r50_fpn.py
修改模型中的类别数,有几类就改成几。修改部分内容如下,
model = dict(
type='FasterRCNN',
pretrained='torchvision://resnet50',
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=5),
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)),
roi_head=dict(
type='StandardRoIHead',
bbox_roi_extractor=dict(
type='SingleRoIExtractor',
roi_layer=dict(type='RoIAlign', output_size=7, sampling_ratio=0),
out_channels=256,
featmap_strides=[4, 8, 16, 32]),
bbox_head=dict(
type='Shared2FCBBoxHead',
in_channels=256,
fc_out_channels=1024,
roi_feat_size=7,
num_classes=2,
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0., 0., 0., 0.],
target_stds=[0.1, 0.1, 0.2, 0.2]),
reg_class_agnostic=False,
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=False, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))))
4、修改标签类别
./mmdetection/mmdet/core/evaluation/class_names.py
修改标签类别
# def voc_classes():
# return [
# 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
# 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
# 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
# ]
def voc_classes():
return [
'1', '2'
]
5、修改voc文件中的类别
mmdetection/mmdet/datasets/voc.py
# CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
# 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
# 'tvmonitor')
CLASSES = ('1', '2')
6、修改图片的格式
/mmdetection/mmdet/datasets/xml_style.py
修改部门的文件如下,
def load_annotations(self, ann_file):
"""Load annotation from XML style ann_file.
Args:
ann_file (str): Path of XML file.
Returns:
list[dict]: Annotation info from XML file.
"""
data_infos = []
img_ids = mmcv.list_from_file(ann_file)
for img_id in img_ids:
filename = f'JPEGImages/{img_id}.bmp'
xml_path = osp.join(self.img_prefix, 'Annotations',
f'{img_id}.xml')
tree = ET.parse(xml_path)
root = tree.getroot()
size = root.find('size')
width = 0
height = 0
if size is not None:
width = int(size.find('width').text)
height = int(size.find('height').text)
else:
img_path = osp.join(self.img_prefix, 'JPEGImages',
'{}.bmp'.format(img_id))
img = Image.open(img_path)
width, height = img.size
data_infos.append(
dict(id=img_id, filename=filename, width=width, height=height))
return data_infos
三、开始训练
1、训练命令
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_voc.py
2、训练保存的模型
训练完成后,模型和日志文件保存在提前创建好的./mmdetection/work_dirs文件夹下,如果不需要对每一轮进行单独分析的话,每个epoch的.pth文件可以删掉,这个比较占空间。
保存好 latest.pth文件(这里面存的是模型的参数值)和最新的.log.json文件,这里面存的是训练的结果。
3、训练过程中指定参数
训练过程中可以指定参数,具体的参数可以借助这条命令查看,
python tools/train.py -h
例如我要指定使用GPU的1卡,
python tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_voc.py --gpu-ids 1
四、测试
1、测试命令
python tools/test.py configs/faster_rcnn/faster_rcnn_r50_fpn_1x_voc.py ./work_dirs/my_faster_rcnn_r50_fpn_1x_coco/latest.pth --out ./result/result.pkl --show-dir ./result/r50_voc_result
2、测试保存的文件
训练完成后,测试结果保存在提前建好的./result中,测试的图像保存在提前建好的./result/r50_voc_result中。可以根据自己的需要修改路径。
图像可以直接下载下来看,预测的框已标号,ground truth需要的话需要自己画。pkl文件保存好用来做评估。
3、测试过程中指定参数
训练过程中可以指定参数,具体的参数可以借助这条命令查看,
python tools/test.py -h
五、评估
mmdetection2.0的评估集成到了robustness_eval.py中,鲁棒性测试如果都要测一遍的话非常慢,并且占用空间很大,如果没有这个需求的话可以不用进行鲁棒性测试。
1、评估命令
python tools/my_voc_eval.py ./result/result.pkl ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_voc.py
其中,my_voc_eval.py 的代码如下,作者见注释。
'''
项目名称:计算AP
创建时间:20200528
'''
__Author__ = "Shliang"
__Email__ = "[email protected]"
from argparse import ArgumentParser
import mmcv
from mmdet import datasets
from mmdet.core import eval_map
def voc_eval(result_file, dataset, iou_thr=0.5, nproc=4):
det_results = mmcv.load(result_file)
annotations = [dataset.get_ann_info(i) for i in range(len(dataset))]
if hasattr(dataset, 'year') and dataset.year == 2007:
dataset_name = 'voc07'
else:
dataset_name = dataset.CLASSES
print(len(det_results),len(annotations))
mmap = eval_map(
det_results,
annotations,
scale_ranges=None,
iou_thr=iou_thr,
dataset=dataset_name,
logger='print',
nproc=nproc)
print(mmap[0])
def main():
parser = ArgumentParser(description='VOC Evaluation')
parser.add_argument('result', help='result file path')
parser.add_argument('config', help='config file path')
parser.add_argument(
'--iou-thr',
type=float,
default=0.5,
help='IoU threshold for evaluation')
parser.add_argument(
'--nproc',
type=int,
default=4,
help='Processes to be used for computing mAP')
args = parser.parse_args()
cfg = mmcv.Config.fromfile(args.config)
test_dataset = mmcv.runner.obj_from_dict(cfg.data.test, datasets)
voc_eval(args.result, test_dataset, args.iou_thr, args.nproc)
if __name__ == '__main__':
main()
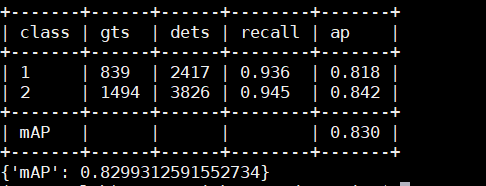
2、运行结果
由于我修改了./mmdet/core/evaluation/mean_ap.py,因此我在这一步可以同时得到PR曲线。
我写了一个不用修改原始文件的程序用来生成PR曲线和loss曲线,代码及使用方法放在了github上。
地址:https://github.com/xiaoyu1233/mmdetection2.0_visualize
六、可视化
1、训练命令
mmdetection自带的,可以把不同模型效果的对比曲线画到一张图里,具体看官方文档,在靠近底部的地方写的。
官方文档
python tools/analyze_logs.py plot_curve ./work_dirs/faster_rcnn_r50_fpn_1x_voc/20201124_194853.log.json --keys loss_cls loss_ bbox --out ./result
2、通过插件画loss曲线和PR曲线
见github
loss曲线及PR曲线绘制