目标检测之Generalized Focal Loss介绍
Generalized Focal Loss介绍
论文地址:https://arxiv.org/abs/2006.04388
mmdetection已经实现了GFL,简单的说是继承的onestage,loss改成作者提出的qfl+dfl,正负样本选择继承ATSS。
对于onestage检测来说,在box生成阶段,会生成大量的候选框,由于目标在图像中往往只占据少部分,所以大量的候选框其实是没有前景的,都是背景框(负样本),直接对这些box做分类/回归,大量的负样本会主导整个loss,使网络学不到什么东西,所以retinanet提出focalloss,在原有交叉熵损失基础之上加了一个系数,就相对比较好的解决了这个问题
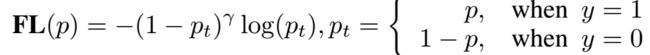
在ATSS中,作者对基于中心点的FCOS和基于anchor的retinanet进行各种对比试验,发现anchor free和base anchor的本质区别是正负样本的选择,于是提出了一种更为合适的正负样本策略,这里可以参考我前面那一篇博客:ATSS。算法再一次提升,在这个基础之上PAA又做了改进。至此ATSS和PAA一套效果已经大幅度超过了FasterRcnn那一套。
我们以作者研究的基础之一ATSS做对比,复习一下ATSS的核心部分:
1.对于每个输出的检测层,选计算每个anchor的中心点和目标的中心点的L2距离,选取K(mmdetection的topK是9)个anchor中心点离目标中心点最近的anchor为候选正样本(candidate positive samples)
2.计算每个候选正样本和groundtruth之间的IOU,计算这组IOU的均值和方差
根据方差和均值,设置选取正样本的阈值:t=m+g ;m为均值,g为方差
3.根据每一层的t从其候选正样本中选出真正需要加入训练的正样本
然后进行训练
然后很明显ATSS还是存在很多问题:
首先就是ATSS本质还是onestage的anchor分类和回归,ATSS的改进只是正负样本策略的改进(当然这很有效),用anchor的分类回归就会有一个共性问题:
问题一:classification score 和 IoU/centerness score 训练测试不一致。
这个不一致主要体现在两个方面:
1) 用法不一致。训练的时候,box分类和box回归是隔开的,,但测试的时候却又是乘在一起作为NMS score排序的依据,没有end-to-end,就会存在一定的gap。
训练阶段:
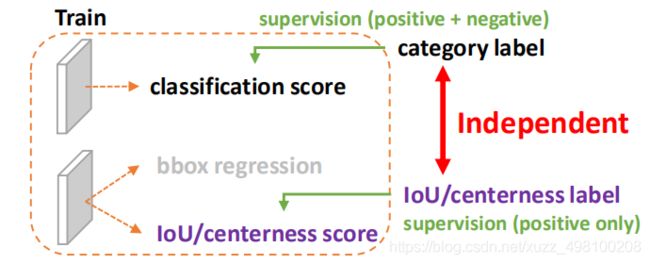
测试阶段:
(作者认为训练分开。测试乘在一起,是gap的来源)
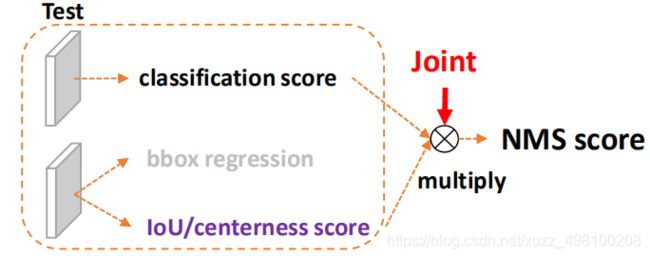
2) 对象不一致。通过Focal Loss,分类分支能够使得少量的正样本和大量的负样本一起成功训练(能够从大量的负样本和少量正样本中选出合适的正负样本出来),但是质量估计通常就只针对正样本训练。那么,对于one-stage的检测器而言,在做NMS score排序的时候,NMS排序基础是分类score*质量score,这就会带来一个问题,有可能存在这么一个框,他是负样本(背景)但是因为模型的问题,导致质量score的分数很高(比如0.99),但是分类没问题,分数比较低,两个一乘,可能就会比一个正样本分数高(分类score比较低而且质量score也比较低):

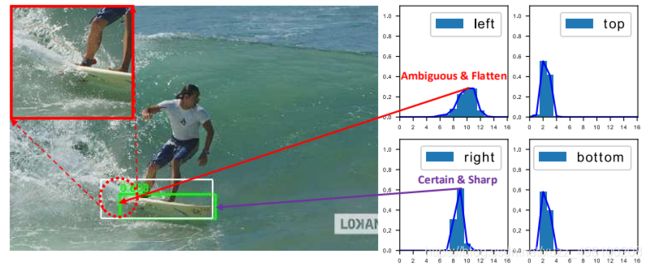
所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,有就是说对于大量可能的负样本,他们的质量预测是一个未定义行为。这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。问题一如图所示:
问题二:bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty(很多时候边界框其实没有那么的清晰)
边框回归一般是smooth_l1回归,输入box的特征向量,loss为anchor和GT的偏差,回归网络输出anchor的平移量和变化尺度,通过这样的方式来修正anchor的位置(本质其实就是一个卷积层)
self.retina_reg = nn.Conv2d(
self.feat_channels, self.num_anchors * 4, 3, padding=1)
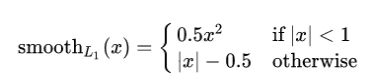
这个回归本质都是建模了非常单一的狄拉克分布,非常不flexible。我们希望用一种general的分布去建模边界框的表示
狄拉克分布解释(源于百度百科):
在除了零以外的点函数值都等于零,而其在整个定义域上的积分等于1
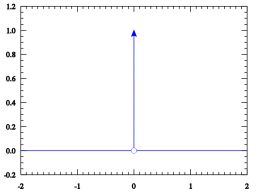
那么这是框的图,确实挺像的
标准FL:
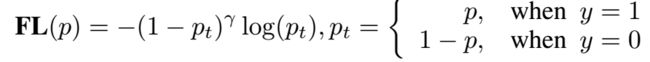
在标准的FL中,y的label是[0,1]是离散的(结果非0即1),回归的分布是狄拉克分布
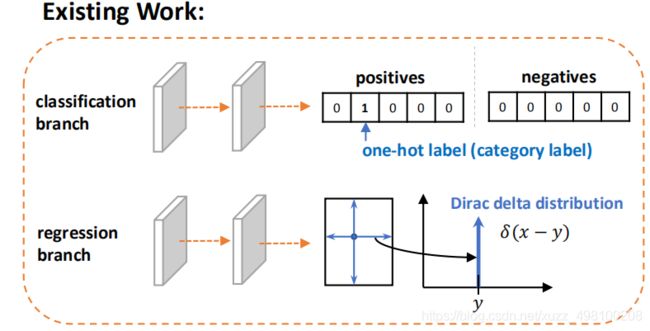
因此,作者设计了一个新的包围框和定位质量得分的表示方式。对于定位得分的表示,我们将其合并到类别得分中,得到一个统一的表示方式:类别向量,其中,ground truth的类别index上的值就用来表示对应框的定位质量(在文中用的是预测框和对应的gt框的IOU值)。这样就可以端到端的进行训练,在推理的时候也可以直接使用,这也很好理解,类别概率和定位得分的范围都是0~1,因此预测出来的这个概率即表示类别概率又表示定位质量在数学上是没问题的,关键是如何去利用这个定位质量的预测值。这样,训练和推理就一致起来了,而且,负样本的质量得分会被压制到0,总体的质量的预测会更加的可信。这对于dense的物体检测器尤为有用
QFL中,y的label是连续的0~1,负样本的时候y=0,而正样本的时候,其中,y就是正样本的IOU所以0

由于之前的FL只能处理one-hot也就是离散的情况,在转成soft-one-hot之后,就需要对现有的FL进行修改:
修改后的FL既要保留原有FL对于类别不均衡的优势,又要能够处理连续的label值,因此,对FL的扩展表现在两方面:
1、交叉熵部分
![]()
扩展到完全形式:
![]()
每个样本的缩放因子
![]()
泛化为预测值和实际值之间的绝对值:
![]()
总结起来就是这样:
![]()
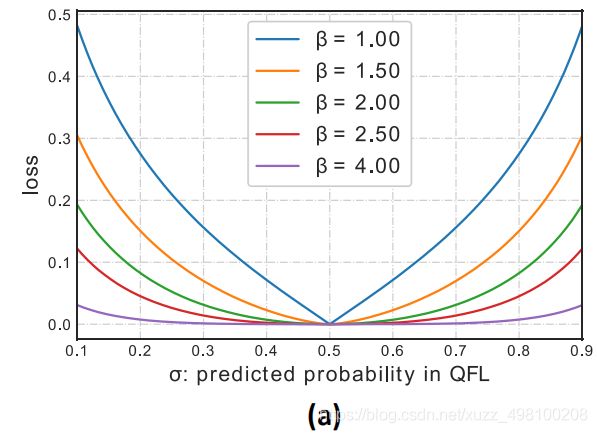
在y=0.5的时候,不同β的可视化的图如下,在文中,使用β=2:
对于包围框,我们回归的目标是当前坐标点到4条边的距离:
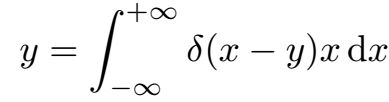
常规操作时将y作为狄拉克分布来回归,满足:
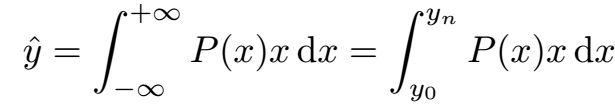
连续的积分形式是没办法用神经网络来实现的,需要改成离散形式,将这个范围分成一系列的小段,我们取间隔为Δ,文中,取Δ=1,因此,y的预测值可以表示为:
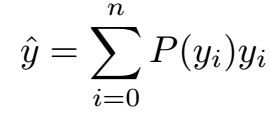
P(x)可以非常方便的使用softmax来实现,用Si来表示每个点的概率,但是,满足这个条件的分布有无穷多的可能性,这可能会降低学习的有效性,我们需要想办法让靠近目标y的点具有较高的概率,还有些情况下,真实的位置可能会距离标注的位置比较远(可能标注的不太好),因此,作者提出DFL(这个建模过程太秀了。说实话很少见到底子这么扎实的作者),可以让网络快速的聚焦到y附近的位置上,由于box的回归不涉及到正负样本的均衡问题,所以可以直接使用交叉熵的完全形式:
![]()
QFL和DFL两者结合,就是GFL:
![]()
使用GFL来训练dense目标检测器
使用loss为: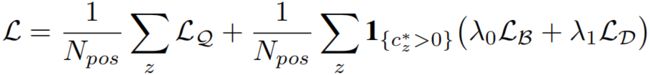
其中,LQ 是QFL,LD 是DFL, LB是GIoU Loss,在实际中,使用质量得分来作为LB 和LD 的加权值。
总结:
作者提出了QFL+DFL,基于ATSS构建了一个新的检测模型,通过COCO数据集证明了有效性:
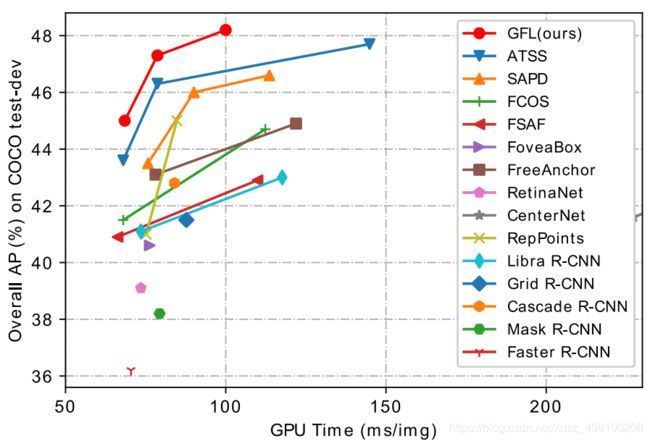
实际效果相比较ATSS有一个点以上的提升,效果可以说相当明显了,确实相比ATSS以及FasterRcnn那一套好用,说明GFL还是work的