【目标检测】数据集准备全流程记录
三种经典的数据集格式介绍
VOC格式
此处只以展示数据集中会用到的文件夹,数据集的格式如下:
- VOC2007/
- Annotations/
- 0000001.xml
- 0000002.xml
- …
- ImageSets/
- Main
- train.txt
- test.txt
- val.txt
- Main
- JPEGImages/
- 0000001.jpg
- 0000002.jpg
- …
- Annotations/
VOC格式的标签是xml格式,其中包含图片的诸多属性,示例如下:
<annotation>
<folder>images</folder>
<filename>000001.jpg</filename>
<path>D:\360安全浏览器下载\Official-SSDD-OPEN\BBox_RBox_PSeg_SSDD\data_for_label\images\000001.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>416</width>
<height>323</height>
<depth>1</depth>
</size>
<segmented>0</segmented>
<object>
<name>ship</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>209</xmin>
<ymin>44</ymin>
<xmax>281</xmax>
<ymax>148</ymax>
</bndbox>
</object>
</annotation>
其中
COCO格式
- coco/
- annotations/
- instances_train2017.json
- instances_val2017.json
- images/
- train2017
- 000001.jpg
- …
- val2017
- 000002.jpg
- …
- train2017
- annotations/
数据集的标签均存放在json文件中,示例如下:
"annotations": [
{"area": 537.209371539205,
"iscrowd": 0,
"image_id": 2,
"bbox": [211.51439299123905, 152.56570713391739, 49.56195244055067, 15.14392991239049],
"category_id": 0,
"id": 1,
"ignore": 0}]
其中"bbox"就是框的gt值,数值依次表示框的左上角坐标和宽高。
YOLO格式
- dataset_name/
- images/
- train
- 000001.jpg
- …
- val
- 000002.jpg
- …
- train
- labels/
- train
- 000001.txt
- …
- val
- 000002.txt
- …
- train
- train.txt
- val.txt
- test.txt
- images/
YOLO数据集标签为txt格式,里面存放5个值:
0 0.469062 0.439437 0.115768 0.090141
分别表示:图像中框的类别,归一化后中心点的坐标,归一化后的宽高。
train.txt、val.txt以及test.txt 存放训练、验证和测试集图片的绝对路径,train.txt的示例如下:
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_0_800_7200_8000.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_0_800_8400_9200.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_0_800_9000_9800.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_0_800_9600_10400.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_1200_2000_0_800.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_1200_2000_4200_5000.jpg
D:/360安全浏览器下载/HRSID_JPG/images/train/P0001_1200_2000_7800_8600.jpg
数据集标注软件LabelImg安装
conda create -n labelimg python=3.6
conda activate labelimg
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyqt5
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple labelImg
最后在名为labelimg的虚拟环境中输入labelimg即可启动该标注软件。
数据集标注过程
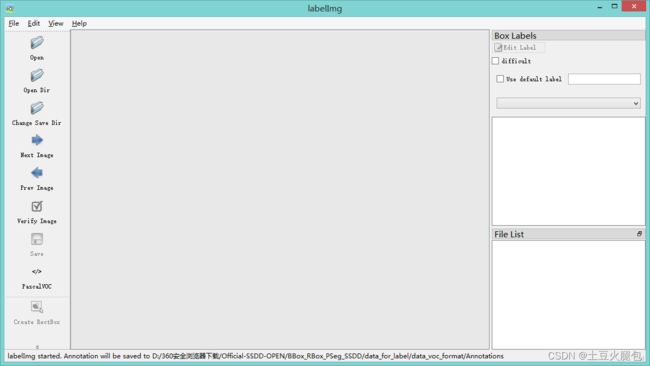
可以直接选择左侧工具栏的Open Dir打开需要标注的图像文件夹路径,选择Change Save Dir确定好保存的标签的路径。VOC格式可创建文件夹名为Annotations;YOLO格式可创建文件夹名为labels。底下可以切换数据集的标注格式,有VOC、YOLO和ML格式。然后就可以选择Create Rectbox进行标注,标注完会弹出框让输入类别,最后Save即可!
VOC格式数据集划分
基于VOC格式划分,会在Main文件夹下生成train.txt、val.txt、test.txt三个txt文件,代码如下:
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations/', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='Main/', type=str, help='output txt label path')
opt = parser.parse_args()
train_percent = 0.8 # 训练集所占比例
val_percent = 0 # 验证集所占比例
test_persent = 0.2 # 测试集所占比例
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list = list(range(num)) #list中存放除了train和val最后剩余的
t_train = int(num * train_percent)
t_val = int(num * val_percent)
train = random.sample(list, t_train) #随机选号
num1 = len(train)
for i in range(num1):
list.remove(train[i])
val_test = [i for i in list if not i in train]
val = random.sample(val_test, t_val)
num2 = len(val)
for i in range(num2):
list.remove(val[i])
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
for i in train:
name = total_xml[i][:-4] + '\n'
file_train.write(name)
for i in val:
name = total_xml[i][:-4] + '\n'
file_val.write(name)
for i in list:
name = total_xml[i][:-4] + '\n'
file_test.write(name)
file_train.close()
file_val.close()
file_test.close()
运行示例:
python split_train_val.py --xml_path D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_voc_format/Annotations --txt_path D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_voc_format/Main
YOLO格式数据集划分
import os
import shutil
import random
random.seed(0)
def split_data(file_path, new_file_path, train_rate, val_rate, test_rate):
eachclass_image = []
for image in os.listdir(file_path):
eachclass_image.append(image)
total = len(eachclass_image)
random.shuffle(eachclass_image)
train_images = eachclass_image[0:int(train_rate * total)]
val_images = eachclass_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = eachclass_image[int((train_rate + val_rate) * total):]
#创建三个txt 存放图像的绝对路径
train_txt= open(new_file_path+'/train.txt', 'w', encoding='utf-8')
if val_images:
val_txt= open(new_file_path+'/val.txt', 'w', encoding='utf-8')
if test_images:
test_txt= open(new_file_path+'/test.txt', 'w', encoding='utf-8')
#将训练集图片从原来的位置移动到新位置中的train文件夹
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'images' + '/' + 'train' #yolo/images/train
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image #新图片存放位置
shutil.copy(old_path, new_path)
train_txt.write(new_path + '\n')
new_name = os.listdir(new_file_path + '/' + 'images' + '/' + 'train')
#移动label到新位置
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
new_xmlpath1 = new_file_path + '/' + 'labels' + '/' + 'train' #yolo/labels/train
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
shutil.copy(old_xmlpath, new_xmlpath)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'images' + '/' + 'val'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
val_txt.write(new_path + '\n')
if val_images:
new_name = os.listdir(new_file_path + '/' + 'images' + '/' + 'val')
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
new_xmlpath1 = new_file_path + '/' + 'labels' + '/' + 'val'
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
shutil.copy(old_xmlpath, new_xmlpath)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'images' + '/' + 'test'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
test_txt.write(new_path + '\n')
if test_images:
new_name = os.listdir(new_file_path + '/' + 'images' + '/' + 'test')
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
new_xmlpath1 = new_file_path + '/' + 'labels' + '/' + 'test'
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
shutil.copy(old_xmlpath, new_xmlpath)
train_txt.close()
if val_images:
val_txt.close()
if test_images:
test_txt.close()
if __name__ == '__main__':
base_path= "D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/"
file_path = base_path+'images'
xmlpath = base_path+'labels'
new_file_path = "D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/yolo"
split_data(file_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)
该代码会将图片和标签复制到新目录下,并创建train,test文件夹进行存放。
VOC转YOLO格式
import os
from os import getcwd
import xml.etree.ElementTree as ET
sets = ['train', 'test']
#这里使用要改成自己的类别
classes = ['ship']
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
x = round(x, 6)
w = round(w, 6)
y = round(y, 6)
h = round(h, 6)
return x, y, w, h
# 后面只用修改各个文件夹的位置
def convert_annotation(image_id,image_set):
# try:
in_file = open('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_voc_format/Annotations/%s.xml' % (image_id), encoding='utf-8')
out_file = open('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/%s/%s.txt' % (image_set,image_id), 'w', encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " +
" ".join([str(a) for a in bb]) + '\n')
# except Exception as e:
# print(e, image_id)
wd = getcwd()
#创建yolo格式所需的labels文件夹,接着创建labels下的train和test文件夹
if not os.path.exists('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/'):
os.makedirs('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/')
if not os.path.exists('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/train/'):
os.makedirs('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/train/')
if not os.path.exists('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/test/'):
os.makedirs('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/labels/test/')
for image_set in sets:
image_ids = open('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_voc_format/Main/%s.txt' %
(image_set)).read().strip().split() #打开train.txt
list_file = open('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/%s.txt' % (image_set), 'w')#最终要写入的txt文件
for image_id in image_ids:
print(image_id)
list_file.write('D:/360安全浏览器下载/Official-SSDD-OPEN/BBox_RBox_PSeg_SSDD/data_for_label/data_yolo_format/images/%s/%s.jpg\n' % (image_set,image_id))
convert_annotation(image_id,image_set)
list_file.close()