推荐系统入门(十):新闻推荐实践5(附代码)
推荐系统入门(十):新闻推荐实践5(附代码)
目录
- 推荐系统入门(十):新闻推荐实践5(附代码)
-
- 前言
-
- LGB模型
- DIN模型
- 一、排序模型
-
- 1.LGB排序模型
- 2.LGB分类模型
- 3.DIN模型
- 二、模型融合
-
- 1.加权融合
- 2.Staking
- 三、总结
- 参考资料
前言
相关系列笔记:
推荐系统入门(一):概述
推荐系统入门(二):协同过滤(附代码)
推荐系统入门(三):矩阵分解MF&因子分解机FM(附代码)
推荐系统入门(四):Wide&Deep(附代码)
推荐系统入门(五):GBDT+LR(附代码)
推荐系统入门(六):新闻推荐实践1(附代码)
推荐系统入门(七):新闻推荐实践2(附代码)
推荐系统入门(八):新闻推荐实践3(附代码)
推荐系统入门(九):新闻推荐实践4(附代码)
推荐系统入门(十):新闻推荐实践5(附代码)
通过召回的操作, 我们已经进行了问题规模的缩减, 对于每个用户, 选择出了N篇文章作为了候选集,并基于召回的候选集构建了与用户历史相关的特征,以及用户本身的属性特征,文章本省的属性特征,以及用户与文章之间的特征,下面就是使用机器学习模型来对构造好的特征进行学习,然后对测试集进行预测,得到测试集中的每个候选集用户点击的概率,返回点击概率最大的topk个文章,作为最终的结果。
排序阶段选择了三个比较有代表性的排序模型,它们分别是:
1. LGB的排序模型
2. LGB的分类模型
3. 深度学习的分类模型DIN
得到了最终的排序模型输出的结果之后,还选择了两种比较经典的模型集成的方法:
1. 输出结果加权融合
2. Staking(将模型的输出结果再使用一个简单模型进行预测)
LGB模型
论文地址:LightGBM A Highly Efficient Gradient Boosting
提升树是利用加模型与前向分布算法实现学习的优化过程,它有一些高效实现,如XGBoost, pGBRT,GBDT(Gradient Boosting Decision Tree)等。其中GBDT采用负梯度作为划分的指标(信息增益),XGBoost则利用到二阶导数。他们共同的不足是,计算信息增益需要扫描所有样本,从而找到最优划分点。在面对大量数据或者特征维度很高时,它们的效率和扩展性很难使人满意。解决这个问题的直接方法就是减少特征量和数据量而且不影响精确度,有部分工作根据数据权重采样来加速booisting的过程,但由于GBDT没有样本权重不能应用。
微软开源的LightGBM(基于GBDT的)则很好的解决这些问题,它主要包含两个算法:
- 单边梯度采样,Gradient-based One-Side Sampling(GOSS)
GOSS(从减少样本角度):排除大部分小梯度的样本,仅用剩下的样本计算信息增益。GBDT虽然没有数据权重,但每个数据实例有不同的梯度,根据计算信息增益的定义,梯度大的实例对信息增益有更大的影响,因此在下采样时,我们应该尽量保留梯度大的样本(预先设定阈值,或者最高百分位间),随机去掉梯度小的样本。我们证明此措施在相同的采样率下比随机采样获得更准确的结果,尤其是在信息增益范围较大时。- 互斥特征绑定,Exclusive Feature Bundling(EFB)
EFB(从减少特征角度):捆绑互斥特征,也就是他们很少同时取非零值(也就是用一个合成特征代替)。通常真是应用中,虽然特征量比较多,但是由于特征空间十分稀疏,是否可以设计一种无损的方法来减少有效特征呢?特别在稀疏特征空间上,许多特征几乎是互斥的(例如许多特征不会同时为非零值,像one-hot),我们可以捆绑互斥的特征。最后,我们将捆绑问题归约到图着色问题,通过贪心算法求得近似解。
结合使用 GOSS 和 EFB 的 GBDT 算法就是 LightGBM。
LightGBM比Xgboost更强大、速度更快的模型,性能上有很大的提升,与传统算法相比具有的优点:
- 更快的训练效率
- 低内存使用
- 更高的准确率
- 支持并行化学习
- 可处理大规模数据
- 原生支持类别特征,不需要对类别特征再进行0-1编码这类的
LightGBM处理分类特征大致流程:
为了解决one-hot编码处理类别特征的不足。LightGBM采用了Many vs many的切分方式,实现了类别特征的最优切分。用LightGBM可以直接输入类别特征。在1个k维的类别特征中寻找最优切分,朴素的枚举算法的复杂度是O(2k),而LightGBM采用了如On Grouping For Maximum Homogeneity的方法实现了O(klogk)的算法。
算法流程下图所示:在枚举分割点之前,先把直方图按每个类别的均值进行排序;然后按照均值的结果依次枚举最优分割点。从下图可以看到,Sum(y)/Count(y)为类别的均值。当然,这个方法很容易过拟合,所以在LGBM中加入了很多对这个方法的约束和正则化。

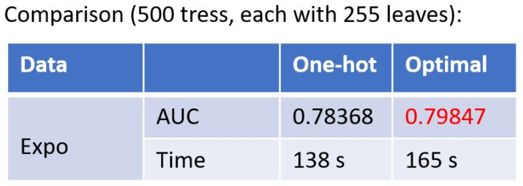
下图是一个简单的对比实验,可以看到该最优方法在AUC上提升了1.5个点,并且时间只多了20%。
下面具体来讲下在代码中如何求解类别特征的最优切分的流程:
- 离散特征建立直方图的过程:统计该特征下每一种离散值出现的次数,并从高到低排序,并过滤掉出现次数较少的特征值, 然后为每一个特征值,建立一个bin容器, 对于在bin容器内出现次数较少的特征值直接过滤掉,不建立bin容器。
- 计算分裂阈值的过程:
o 先看该特征下划分出的bin容器的个数,如果bin容器的数量小于4,直接使用one vs other方式, 逐个扫描每一个bin容器,找出最佳分裂点;
o 对于bin容器较多的情况,先进行过滤,只让子集合较大的bin容器参加划分阈值计算, 每一个符合条件的bin容器进行公式计算(公式如下: 该bin容器下所有样本的一阶梯度之和/该bin容器下所有样本的二阶梯度之和 +正则项(参数cat_smooth),这里为什么不是label的均值呢?其实上例中只是为了便于理解,只针对了学习一棵树且是回归问题的情况,这时候一阶导数是Y,二阶导数是1),得到一个值,根据该值对bin容器从小到大进行排序,然后分从左到右、从右到左进行搜索,得到最优分裂阈值。但是有一点,没有搜索所有的bin容器,而是设定了一个搜索bin容器数量的上限值,程序中设定是32,即参数max_num_cat。LightGBM中对离散特征实行的是many vs many策略,这32个bin中最优划分的阈值的左边或者右边所有的bin容器就是一个many集合,而其他的bin容器就是另一个many集合。
o 对于连续特征,划分阈值只有一个,对于离散值可能会有多个划分阈值,每一个划分阈值对应着一个bin容器编号,当使用离散特征进行分裂时,只要数据样本对应的bin容器编号在这些阈值对应的bin集合之中,这条数据就加入分裂后的左子树,否则加入分裂后的右子树。
DIN模型
DIN模型的全称是Deep Interest Network,这是阿里2018年基于前面的深度学习模型无法表达用户多样化的兴趣而提出的一个模型,它可以通过考虑 【给定的候选广告】和【用户的历史行为】的相关性,来计算用户兴趣的表示向量。具体来说就是通过引入局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和来获得有关候选广告的用户兴趣的表示。与候选广告相关性较高的行为会获得较高的激活权重,并支配着用户兴趣。该表示向量在不同广告上有所不同,大大提高了模型的表达能力。所以该模型对于此次新闻推荐的任务也比较适合, 我们在这里通过当前的候选文章与用户历史点击文章的相关性来计算用户对于文章的兴趣。该模型的结构如下:

输入层:
(1)用户的画像特征,例如性别、年龄、学历等;
(2)用户的行为序列数据,例如点击商品的行为序列、购买商品的行为序列;
(3)候选商品的画像特征,例如品类、品牌等;
(4)上下文特征,例如设备终端、时间、地点等;
Embedding层:
将输入层的特征映射为固定长度的向量;
Concat层:
将Embedding向量组合为一个向量;
Activation Unit层:
计算候选商品与历史行为商品之间的权重。该模块可以认为是一个独立的MLP;
Sum Pooling层:
将用户历史行为的商品Embedding进行Sum操作;
Concat和Flatten层:
将以上的Embedding合并,并展平;
全连接网络层:
经过两层全连接,并使用自定义Dice激活函数激活神经元;
输出层:
对全连接网络层的结果进行Softmax操作,返回最大值的索引作为预测结果;
一、排序模型
import numpy as np
import pandas as pd
import pickle
from tqdm import tqdm
import gc, os
import time
from datetime import datetime
import lightgbm as lgb
from sklearn.preprocessing import MinMaxScaler
import warnings
warnings.filterwarnings('ignore')
读取排序特征
data_path = './data_raw/'
save_path = './temp_results/'
offline = False
# 重新读取数据的时候,发现click_article_id是一个浮点数,所以将其转换成int类型
trn_user_item_feats_df = pd.read_csv(save_path + 'trn_user_item_feats_df.csv')
trn_user_item_feats_df['click_article_id'] = trn_user_item_feats_df['click_article_id'].astype(int)
if offline:
val_user_item_feats_df = pd.read_csv(save_path + 'val_user_item_feats_df.csv')
val_user_item_feats_df['click_article_id'] = val_user_item_feats_df['click_article_id'].astype(int)
else:
val_user_item_feats_df = None
tst_user_item_feats_df = pd.read_csv(save_path + 'tst_user_item_feats_df.csv')
tst_user_item_feats_df['click_article_id'] = tst_user_item_feats_df['click_article_id'].astype(int)
# 做特征的时候为了方便,给测试集也打上了一个无效的标签,这里直接删掉就行
del tst_user_item_feats_df['label']
返回排序后的结果
def submit(recall_df, topk=5, model_name=None):
recall_df = recall_df.sort_values(by=['user_id', 'pred_score'])
recall_df['rank'] = recall_df.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 判断是不是每个用户都有5篇文章及以上
tmp = recall_df.groupby('user_id').apply(lambda x: x['rank'].max())
assert tmp.min() >= topk
del recall_df['pred_score']
submit = recall_df[recall_df['rank'] <= topk].set_index(['user_id', 'rank']).unstack(-1).reset_index()
submit.columns = [int(col) if isinstance(col, int) else col for col in submit.columns.droplevel(0)]
# 按照提交格式定义列名
submit = submit.rename(columns={'': 'user_id', 1: 'article_1', 2: 'article_2',
3: 'article_3', 4: 'article_4', 5: 'article_5'})
save_name = save_path + model_name + '_' + datetime.today().strftime('%m-%d') + '.csv'
submit.to_csv(save_name, index=False, header=True)
# 排序结果归一化
def norm_sim(sim_df, weight=0.0):
# print(sim_df.head())
min_sim = sim_df.min()
max_sim = sim_df.max()
if max_sim == min_sim:
sim_df = sim_df.apply(lambda sim: 1.0)
else:
sim_df = sim_df.apply(lambda sim: 1.0 * (sim - min_sim) / (max_sim - min_sim))
sim_df = sim_df.apply(lambda sim: sim + weight) # plus one
return sim_df
1.LGB排序模型
# 防止中间出错之后重新读取数据
trn_user_item_feats_df_rank_model = trn_user_item_feats_df.copy()
if offline:
val_user_item_feats_df_rank_model = val_user_item_feats_df.copy()
tst_user_item_feats_df_rank_model = tst_user_item_feats_df.copy()
# 定义特征列
lgb_cols = ['sim0', 'time_diff0', 'word_diff0','sim_max', 'sim_min', 'sim_sum',
'sim_mean', 'score','click_size', 'time_diff_mean', 'active_level',
'click_environment','click_deviceGroup', 'click_os', 'click_country',
'click_region','click_referrer_type', 'user_time_hob1', 'user_time_hob2',
'words_hbo', 'category_id', 'created_at_ts','words_count']
# 排序模型分组
trn_user_item_feats_df_rank_model.sort_values(by=['user_id'], inplace=True)
g_train = trn_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
if offline:
val_user_item_feats_df_rank_model.sort_values(by=['user_id'], inplace=True)
g_val = val_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
# 排序模型定义
lgb_ranker = lgb.LGBMRanker(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16)
# 排序模型训练
if offline:
lgb_ranker.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'], group=g_train,
eval_set=[(val_user_item_feats_df_rank_model[lgb_cols], val_user_item_feats_df_rank_model['label'])],
eval_group= [g_val], eval_at=[1, 2, 3, 4, 5], eval_metric=['ndcg', ], early_stopping_rounds=50, )
else:
lgb_ranker.fit(trn_user_item_feats_df[lgb_cols], trn_user_item_feats_df['label'], group=g_train)
# 模型预测
tst_user_item_feats_df['pred_score'] = lgb_ranker.predict(tst_user_item_feats_df[lgb_cols], num_iteration=lgb_ranker.best_iteration_)
# 将这里的排序结果保存一份,用户后面的模型融合
tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']].to_csv(save_path + 'lgb_ranker_score.csv', index=False)
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_ranker')
# 五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
# 这一部分与前面的单独训练和验证是分开的
def get_kfold_users(trn_df, n=5):
user_ids = trn_df['user_id'].unique()
user_set = [user_ids[i::n] for i in range(n)]
return user_set
k_fold = 5
trn_df = trn_user_item_feats_df_rank_model
user_set = get_kfold_users(trn_df, n=k_fold)
score_list = []
score_df = trn_df[['user_id', 'click_article_id','label']]
sub_preds = np.zeros(tst_user_item_feats_df_rank_model.shape[0])
# 五折交叉验证,并将中间结果保存用于staking
for n_fold, valid_user in enumerate(user_set):
train_idx = trn_df[~trn_df['user_id'].isin(valid_user)] # add slide user
valid_idx = trn_df[trn_df['user_id'].isin(valid_user)]
# 训练集与验证集的用户分组
train_idx.sort_values(by=['user_id'], inplace=True)
g_train = train_idx.groupby(['user_id'], as_index=False).count()["label"].values
valid_idx.sort_values(by=['user_id'], inplace=True)
g_val = valid_idx.groupby(['user_id'], as_index=False).count()["label"].values
# 定义模型
lgb_ranker = lgb.LGBMRanker(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16)
# 训练模型
lgb_ranker.fit(train_idx[lgb_cols], train_idx['label'], group=g_train,
eval_set=[(valid_idx[lgb_cols], valid_idx['label'])], eval_group= [g_val],
eval_at=[1, 2, 3, 4, 5], eval_metric=['ndcg', ], early_stopping_rounds=50, )
# 预测验证集结果
valid_idx['pred_score'] = lgb_ranker.predict(valid_idx[lgb_cols], num_iteration=lgb_ranker.best_iteration_)
# 对输出结果进行归一化
valid_idx['pred_score'] = valid_idx[['pred_score']].transform(lambda x: norm_sim(x))
valid_idx.sort_values(by=['user_id', 'pred_score'])
valid_idx['pred_rank'] = valid_idx.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 将验证集的预测结果放到一个列表中,后面进行拼接
score_list.append(valid_idx[['user_id', 'click_article_id', 'pred_score', 'pred_rank']])
# 如果是线上测试,需要计算每次交叉验证的结果相加,最后求平均
if not offline:
sub_preds += lgb_ranker.predict(tst_user_item_feats_df_rank_model[lgb_cols], lgb_ranker.best_iteration_)
score_df_ = pd.concat(score_list, axis=0)
score_df = score_df.merge(score_df_, how='left', on=['user_id', 'click_article_id'])
# 保存训练集交叉验证产生的新特征
score_df[['user_id', 'click_article_id', 'pred_score', 'pred_rank', 'label']].to_csv(save_path + 'trn_lgb_ranker_feats.csv', index=False)
# 测试集的预测结果,多次交叉验证求平均,将预测的score和对应的rank特征保存,可以用于后面的staking,这里还可以构造其他更多的特征
tst_user_item_feats_df_rank_model['pred_score'] = sub_preds / k_fold
tst_user_item_feats_df_rank_model['pred_score'] = tst_user_item_feats_df_rank_model['pred_score'].transform(lambda x: norm_sim(x))
tst_user_item_feats_df_rank_model.sort_values(by=['user_id', 'pred_score'])
tst_user_item_feats_df_rank_model['pred_rank'] = tst_user_item_feats_df_rank_model.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 保存测试集交叉验证的新特征
tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score', 'pred_rank']].to_csv(save_path + 'tst_lgb_ranker_feats.csv', index=False)
# 预测结果重新排序, 及生成提交结果
# 单模型生成提交结果
rank_results = tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_ranker')
2.LGB分类模型
# 模型及参数的定义
lgb_Classfication = lgb.LGBMClassifier(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=500, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16, verbose=10)
# 模型训练
if offline:
lgb_Classfication.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'],
eval_set=[(val_user_item_feats_df_rank_model[lgb_cols], val_user_item_feats_df_rank_model['label'])],
eval_metric=['auc', ],early_stopping_rounds=50, )
else:
lgb_Classfication.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'])
# 模型预测
tst_user_item_feats_df['pred_score'] = lgb_Classfication.predict_proba(tst_user_item_feats_df[lgb_cols])[:,1]
# 将这里的排序结果保存一份,用户后面的模型融合
tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']].to_csv(save_path + 'lgb_cls_score.csv', index=False)
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_cls')
# 五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
# 这一部分与前面的单独训练和验证是分开的
def get_kfold_users(trn_df, n=5):
user_ids = trn_df['user_id'].unique()
user_set = [user_ids[i::n] for i in range(n)]
return user_set
k_fold = 5
trn_df = trn_user_item_feats_df_rank_model
user_set = get_kfold_users(trn_df, n=k_fold)
score_list = []
score_df = trn_df[['user_id', 'click_article_id', 'label']]
sub_preds = np.zeros(tst_user_item_feats_df_rank_model.shape[0])
# 五折交叉验证,并将中间结果保存用于staking
for n_fold, valid_user in enumerate(user_set):
train_idx = trn_df[~trn_df['user_id'].isin(valid_user)] # add slide user
valid_idx = trn_df[trn_df['user_id'].isin(valid_user)]
# 模型及参数的定义
lgb_Classfication = lgb.LGBMClassifier(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16, verbose=10)
# 训练模型
lgb_Classfication.fit(train_idx[lgb_cols], train_idx['label'],eval_set=[(valid_idx[lgb_cols], valid_idx['label'])],
eval_metric=['auc', ],early_stopping_rounds=50, )
# 预测验证集结果
valid_idx['pred_score'] = lgb_Classfication.predict_proba(valid_idx[lgb_cols],
num_iteration=lgb_Classfication.best_iteration_)[:,1]
# 对输出结果进行归一化 分类模型输出的值本身就是一个概率值不需要进行归一化
# valid_idx['pred_score'] = valid_idx[['pred_score']].transform(lambda x: norm_sim(x))
valid_idx.sort_values(by=['user_id', 'pred_score'])
valid_idx['pred_rank'] = valid_idx.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 将验证集的预测结果放到一个列表中,后面进行拼接
score_list.append(valid_idx[['user_id', 'click_article_id', 'pred_score', 'pred_rank']])
# 如果是线上测试,需要计算每次交叉验证的结果相加,最后求平均
if not offline:
sub_preds += lgb_Classfication.predict_proba(tst_user_item_feats_df_rank_model[lgb_cols],
num_iteration=lgb_Classfication.best_iteration_)[:,1]
score_df_ = pd.concat(score_list, axis=0)
score_df = score_df.merge(score_df_, how='left', on=['user_id', 'click_article_id'])
# 保存训练集交叉验证产生的新特征
score_df[['user_id', 'click_article_id', 'pred_score', 'pred_rank', 'label']].to_csv(save_path + 'trn_lgb_cls_feats.csv', index=False)
# 测试集的预测结果,多次交叉验证求平均,将预测的score和对应的rank特征保存,可以用于后面的staking,这里还可以构造其他更多的特征
tst_user_item_feats_df_rank_model['pred_score'] = sub_preds / k_fold
tst_user_item_feats_df_rank_model['pred_score'] = tst_user_item_feats_df_rank_model['pred_score'].transform(lambda x: norm_sim(x))
tst_user_item_feats_df_rank_model.sort_values(by=['user_id', 'pred_score'])
tst_user_item_feats_df_rank_model['pred_rank'] = tst_user_item_feats_df_rank_model.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 保存测试集交叉验证的新特征
tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score', 'pred_rank']].to_csv(save_path + 'tst_lgb_cls_feats.csv', index=False)
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df_rank_model[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
submit(rank_results, topk=5, model_name='lgb_cls')
3.DIN模型
用户的历史点击行为列表
这个是为后面的DIN模型服务的
if offline:
all_data = pd.read_csv('./data_raw/train_click_log.csv')
else:
trn_data = pd.read_csv('./data_raw/train_click_log.csv')
tst_data = pd.read_csv('./data_raw/testA_click_log.csv')
all_data = trn_data.append(tst_data)
hist_click =all_data[['user_id', 'click_article_id']].groupby('user_id').agg({list}).reset_index()
his_behavior_df = pd.DataFrame()
his_behavior_df['user_id'] = hist_click['user_id']
his_behavior_df['hist_click_article_id'] = hist_click['click_article_id']
trn_user_item_feats_df_din_model = trn_user_item_feats_df.copy()
if offline:
val_user_item_feats_df_din_model = val_user_item_feats_df.copy()
else:
val_user_item_feats_df_din_model = None
tst_user_item_feats_df_din_model = tst_user_item_feats_df.copy()
trn_user_item_feats_df_din_model = trn_user_item_feats_df_din_model.merge(his_behavior_df, on='user_id')
if offline:
val_user_item_feats_df_din_model = val_user_item_feats_df_din_model.merge(his_behavior_df, on='user_id')
else:
val_user_item_feats_df_din_model = None
tst_user_item_feats_df_din_model = tst_user_item_feats_df_din_model.merge(his_behavior_df, on='user_id')
我们这里直接调包来使用这个模型。下面说一下该模型如何具体使用:deepctr的函数原型如下:
def DIN(dnn_feature_columns, history_feature_list, dnn_use_bn=False,
dnn_hidden_units=(200, 80), dnn_activation=‘relu’, att_hidden_size=(80, 40), att_activation=“dice”,
att_weight_normalization=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, seed=1024,
task=‘binary’):
• dnn_feature_columns: 特征列, 包含数据所有特征的列表
• history_feature_list: 用户历史行为列, 反应用户历史行为的特征的列表
• dnn_use_bn: 是否使用BatchNormalization
• dnn_hidden_units: 全连接层网络的层数和每一层神经元的个数, 一个列表或者元组
• dnn_activation_relu: 全连接网络的激活单元类型
• att_hidden_size: 注意力层的全连接网络的层数和每一层神经元的个数
• att_activation: 注意力层的激活单元类型
• att_weight_normalization: 是否归一化注意力得分
• l2_reg_dnn: 全连接网络的正则化系数
• l2_reg_embedding: embedding向量的正则化稀疏
• dnn_dropout: 全连接网络的神经元的失活概率
• task: 任务, 可以是分类, 也可是是回归
在具体使用的时候, 我们必须要传入特征列和历史行为列, 但是再传入之前, 我们需要进行一下特征列的预处理。具体如下:
- 首先,我们要处理数据集, 得到数据, 由于我们是基于用户过去的行为去预测用户是否点击当前文章, 所以我们需要把数据的特征列划分成数值型特征, 离散型特征和历史行为特征列三部分, 对于每一部分, DIN模型的处理会有不同
1)对于离散型特征, 在我们的数据集中就是那些类别型的特征, 比如user_id这种, 这种类别型特征, 我们首先要经过embedding处理得到每个特征的低维稠密型表示, 既然要经过embedding, 那么我们就需要为每一列的类别特征的取值建立一个字典,并指明embedding维度, 所以在使用deepctr的DIN模型准备数据的时候, 我们需要通过SparseFeat函数指明这些类别型特征, 这个函数的传入参数就是列名, 列的唯一取值(建立字典用)和embedding维度。
2)对于用户历史行为特征列, 比如文章id, 文章的类别等这种, 同样的我们需要先经过embedding处理, 只不过和上面不一样的地方是,对于这种特征, 我们在得到每个特征的embedding表示之后, 还需要通过一个Attention_layer计算用户的历史行为和当前候选文章的相关性以此得到当前用户的embedding向量, 这个向量就可以基于当前的候选文章与用户过去点击过得历史文章的相似性的程度来反应用户的兴趣, 并且随着用户的不同的历史点击来变化,去动态的模拟用户兴趣的变化过程。这类特征对于每个用户都是一个历史行为序列, 对于每个用户, 历史行为序列长度会不一样, 可能有的用户点击的历史文章多,有的点击的历史文章少, 所以我们还需要把这个长度统一起来, 在为DIN模型准备数据的时候, 我们首先要通过SparseFeat函数指明这些类别型特征, 然后还需要通过VarLenSparseFeat函数再进行序列填充, 使得每个用户的历史序列一样长, 所以这个函数参数中会有个maxlen,来指明序列的最大长度是多少。- 对于连续型特征列, 我们只需要用DenseFeat函数来指明列名和维度即可。
- 处理完特征列之后, 我们把相应的数据与列进行对应,就得到了最后的数据。
下面根据具体的代码感受一下, 逻辑是这样, 首先我们需要写一个数据准备函数, 在这里面就是根据上面的具体步骤准备数据, 得到数据和特征列, 然后就是建立DIN模型并训练, 最后基于模型进行测试。
# 导入deepctr
from deepctr.models import DIN
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat, get_feature_names
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras import backend as K
from tensorflow.keras.layers import *
from tensorflow.keras.models import *
from tensorflow.keras.callbacks import *
import tensorflow as tf
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"] = "2"
# 数据准备函数
def get_din_feats_columns(df, dense_fea, sparse_fea, behavior_fea, his_behavior_fea, emb_dim=32, max_len=100):
"""
数据准备函数:
df: 数据集
dense_fea: 数值型特征列
sparse_fea: 离散型特征列
behavior_fea: 用户的候选行为特征列
his_behavior_fea: 用户的历史行为特征列
embedding_dim: embedding的维度, 这里为了简单, 统一把离散型特征列采用一样的隐向量维度
max_len: 用户序列的最大长度
"""
sparse_feature_columns = [SparseFeat(feat, vocabulary_size=df[feat].nunique() + 1, embedding_dim=emb_dim) for feat in sparse_fea]
dense_feature_columns = [DenseFeat(feat, 1, ) for feat in dense_fea]
var_feature_columns = [VarLenSparseFeat(SparseFeat(feat, vocabulary_size=df['click_article_id'].nunique() + 1,
embedding_dim=emb_dim, embedding_name='click_article_id'), maxlen=max_len) for feat in hist_behavior_fea]
dnn_feature_columns = sparse_feature_columns + dense_feature_columns + var_feature_columns
# 建立x, x是一个字典的形式
x = {}
for name in get_feature_names(dnn_feature_columns):
if name in his_behavior_fea:
# 这是历史行为序列
his_list = [l for l in df[name]]
x[name] = pad_sequences(his_list, maxlen=max_len, padding='post') # 二维数组
else:
x[name] = df[name].values
return x, dnn_feature_columns
# 把特征分开
sparse_fea = ['user_id', 'click_article_id', 'category_id', 'click_environment', 'click_deviceGroup',
'click_os', 'click_country', 'click_region', 'click_referrer_type', 'is_cat_hab']
behavior_fea = ['click_article_id']
hist_behavior_fea = ['hist_click_article_id']
dense_fea = ['sim0', 'time_diff0', 'word_diff0', 'sim_max', 'sim_min', 'sim_sum', 'sim_mean', 'score',
'rank','click_size','time_diff_mean','active_level','user_time_hob1','user_time_hob2',
'words_hbo','words_count']
# dense特征进行归一化, 神经网络训练都需要将数值进行归一化处理
mm = MinMaxScaler()
# 下面是做一些特殊处理,当在其他的地方出现无效值的时候,不处理无法进行归一化,刚开始可以先把他注释掉,在运行了下面的代码
# 之后如果发现报错,应该先去想办法处理如何不出现inf之类的值
# trn_user_item_feats_df_din_model.replace([np.inf, -np.inf], 0, inplace=True)
# tst_user_item_feats_df_din_model.replace([np.inf, -np.inf], 0, inplace=True)
for feat in dense_fea:
trn_user_item_feats_df_din_model[feat] = mm.fit_transform(trn_user_item_feats_df_din_model[[feat]])
if val_user_item_feats_df_din_model is not None:
val_user_item_feats_df_din_model[feat] = mm.fit_transform(val_user_item_feats_df_din_model[[feat]])
tst_user_item_feats_df_din_model[feat] = mm.fit_transform(tst_user_item_feats_df_din_model[[feat]])
# 准备训练数据
x_trn, dnn_feature_columns = get_din_feats_columns(trn_user_item_feats_df_din_model, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
y_trn = trn_user_item_feats_df_din_model['label'].values
if offline:
# 准备验证数据
x_val, dnn_feature_columns = get_din_feats_columns(val_user_item_feats_df_din_model, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
y_val = val_user_item_feats_df_din_model['label'].values
dense_fea = [x for x in dense_fea if x != 'label']
x_tst, dnn_feature_columns = get_din_feats_columns(tst_user_item_feats_df_din_model, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
WARNING:tensorflow:From /home/ryluo/anaconda3/lib/python3.6/site-packages/tensorflow/python/keras/initializers.py:143: calling RandomNormal.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
# 建立模型
model = DIN(dnn_feature_columns, behavior_fea)
# 查看模型结构
model.summary()
# 模型编译
model.compile('adam', 'binary_crossentropy',metrics=['binary_crossentropy', tf.keras.metrics.AUC()])
WARNING:tensorflow:From /home/ryluo/anaconda3/lib/python3.6/site-packages/tensorflow/python/ops/init_ops.py:1288: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
WARNING:tensorflow:From /home/ryluo/anaconda3/lib/python3.6/site-packages/tensorflow/python/autograph/impl/api.py:255: add_dispatch_support.<locals>.wrapper (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.where in 2.0, which has the same broadcast rule as np.where
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
user_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_article_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
category_id (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_environment (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_deviceGroup (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_os (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_country (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_region (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_referrer_type (InputLayer [(None, 1)] 0
__________________________________________________________________________________________________
is_cat_hab (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
sparse_emb_user_id (Embedding) (None, 1, 32) 1600032 user_id[0][0]
__________________________________________________________________________________________________
sparse_seq_emb_hist_click_artic multiple 525664 click_article_id[0][0]
hist_click_article_id[0][0]
click_article_id[0][0]
__________________________________________________________________________________________________
sparse_emb_category_id (Embeddi (None, 1, 32) 7776 category_id[0][0]
__________________________________________________________________________________________________
sparse_emb_click_environment (E (None, 1, 32) 128 click_environment[0][0]
__________________________________________________________________________________________________
sparse_emb_click_deviceGroup (E (None, 1, 32) 160 click_deviceGroup[0][0]
__________________________________________________________________________________________________
sparse_emb_click_os (Embedding) (None, 1, 32) 288 click_os[0][0]
__________________________________________________________________________________________________
sparse_emb_click_country (Embed (None, 1, 32) 384 click_country[0][0]
__________________________________________________________________________________________________
sparse_emb_click_region (Embedd (None, 1, 32) 928 click_region[0][0]
__________________________________________________________________________________________________
sparse_emb_click_referrer_type (None, 1, 32) 256 click_referrer_type[0][0]
__________________________________________________________________________________________________
sparse_emb_is_cat_hab (Embeddin (None, 1, 32) 64 is_cat_hab[0][0]
__________________________________________________________________________________________________
no_mask (NoMask) (None, 1, 32) 0 sparse_emb_user_id[0][0]
sparse_seq_emb_hist_click_article
sparse_emb_category_id[0][0]
sparse_emb_click_environment[0][0
sparse_emb_click_deviceGroup[0][0
sparse_emb_click_os[0][0]
sparse_emb_click_country[0][0]
sparse_emb_click_region[0][0]
sparse_emb_click_referrer_type[0]
sparse_emb_is_cat_hab[0][0]
__________________________________________________________________________________________________
hist_click_article_id (InputLay [(None, 50)] 0
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 1, 320) 0 no_mask[0][0]
no_mask[1][0]
no_mask[2][0]
no_mask[3][0]
no_mask[4][0]
no_mask[5][0]
no_mask[6][0]
no_mask[7][0]
no_mask[8][0]
no_mask[9][0]
__________________________________________________________________________________________________
no_mask_1 (NoMask) (None, 1, 320) 0 concatenate[0][0]
__________________________________________________________________________________________________
attention_sequence_pooling_laye (None, 1, 32) 13961 sparse_seq_emb_hist_click_article
sparse_seq_emb_hist_click_article
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 1, 352) 0 no_mask_1[0][0]
attention_sequence_pooling_layer[
__________________________________________________________________________________________________
sim0 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
time_diff0 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
word_diff0 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
sim_max (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
sim_min (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
sim_sum (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
sim_mean (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
score (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
rank (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
click_size (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
time_diff_mean (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
active_level (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
user_time_hob1 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
user_time_hob2 (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
words_hbo (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
words_count (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
flatten (Flatten) (None, 352) 0 concatenate_1[0][0]
__________________________________________________________________________________________________
no_mask_3 (NoMask) (None, 1) 0 sim0[0][0]
time_diff0[0][0]
word_diff0[0][0]
sim_max[0][0]
sim_min[0][0]
sim_sum[0][0]
sim_mean[0][0]
score[0][0]
rank[0][0]
click_size[0][0]
time_diff_mean[0][0]
active_level[0][0]
user_time_hob1[0][0]
user_time_hob2[0][0]
words_hbo[0][0]
words_count[0][0]
__________________________________________________________________________________________________
no_mask_2 (NoMask) (None, 352) 0 flatten[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 16) 0 no_mask_3[0][0]
no_mask_3[1][0]
no_mask_3[2][0]
no_mask_3[3][0]
no_mask_3[4][0]
no_mask_3[5][0]
no_mask_3[6][0]
no_mask_3[7][0]
no_mask_3[8][0]
no_mask_3[9][0]
no_mask_3[10][0]
no_mask_3[11][0]
no_mask_3[12][0]
no_mask_3[13][0]
no_mask_3[14][0]
no_mask_3[15][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 352) 0 no_mask_2[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 16) 0 concatenate_2[0][0]
__________________________________________________________________________________________________
no_mask_4 (NoMask) multiple 0 flatten_1[0][0]
flatten_2[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 368) 0 no_mask_4[0][0]
no_mask_4[1][0]
__________________________________________________________________________________________________
dnn_1 (DNN) (None, 80) 89880 concatenate_3[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 1) 80 dnn_1[0][0]
__________________________________________________________________________________________________
prediction_layer (PredictionLay (None, 1) 1 dense[0][0]
==================================================================================================
Total params: 2,239,602
Trainable params: 2,239,362
Non-trainable params: 240
__________________________________________________________________________________________________
# 模型训练
if offline:
history = model.fit(x_trn, y_trn, verbose=1, epochs=10, validation_data=(x_val, y_val) , batch_size=256)
else:
# 也可以使用上面的语句用自己采样出来的验证集
# history = model.fit(x_trn, y_trn, verbose=1, epochs=3, validation_split=0.3, batch_size=256)
history = model.fit(x_trn, y_trn, verbose=1, epochs=2, batch_size=256)
Epoch 1/2
290964/290964 [==============================] - 55s 189us/sample - loss: 0.4209 - binary_crossentropy: 0.4206 - auc: 0.7842
Epoch 2/2
290964/290964 [==============================] - 52s 178us/sample - loss: 0.3630 - binary_crossentropy: 0.3618 - auc: 0.8478
# 模型预测
tst_user_item_feats_df_din_model['pred_score'] = model.predict(x_tst, verbose=1, batch_size=256)
tst_user_item_feats_df_din_model[['user_id', 'click_article_id', 'pred_score']].to_csv(save_path + 'din_rank_score.csv', index=False)
500000/500000 [==============================] - 20s 39us/sample
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df_din_model[['user_id', 'click_article_id', 'pred_score']]
submit(rank_results, topk=5, model_name='din')
# 五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
# 这一部分与前面的单独训练和验证是分开的
def get_kfold_users(trn_df, n=5):
user_ids = trn_df['user_id'].unique()
user_set = [user_ids[i::n] for i in range(n)]
return user_set
k_fold = 5
trn_df = trn_user_item_feats_df_din_model
user_set = get_kfold_users(trn_df, n=k_fold)
score_list = []
score_df = trn_df[['user_id', 'click_article_id', 'label']]
sub_preds = np.zeros(tst_user_item_feats_df_rank_model.shape[0])
dense_fea = [x for x in dense_fea if x != 'label']
x_tst, dnn_feature_columns = get_din_feats_columns(tst_user_item_feats_df_din_model, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
# 五折交叉验证,并将中间结果保存用于staking
for n_fold, valid_user in enumerate(user_set):
train_idx = trn_df[~trn_df['user_id'].isin(valid_user)] # add slide user
valid_idx = trn_df[trn_df['user_id'].isin(valid_user)]
# 准备训练数据
x_trn, dnn_feature_columns = get_din_feats_columns(train_idx, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
y_trn = train_idx['label'].values
# 准备验证数据
x_val, dnn_feature_columns = get_din_feats_columns(valid_idx, dense_fea,
sparse_fea, behavior_fea, hist_behavior_fea, max_len=50)
y_val = valid_idx['label'].values
history = model.fit(x_trn, y_trn, verbose=1, epochs=2, validation_data=(x_val, y_val) , batch_size=256)
# 预测验证集结果
valid_idx['pred_score'] = model.predict(x_val, verbose=1, batch_size=256)
valid_idx.sort_values(by=['user_id', 'pred_score'])
valid_idx['pred_rank'] = valid_idx.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 将验证集的预测结果放到一个列表中,后面进行拼接
score_list.append(valid_idx[['user_id', 'click_article_id', 'pred_score', 'pred_rank']])
# 如果是线上测试,需要计算每次交叉验证的结果相加,最后求平均
if not offline:
sub_preds += model.predict(x_tst, verbose=1, batch_size=256)[:, 0]
score_df_ = pd.concat(score_list, axis=0)
score_df = score_df.merge(score_df_, how='left', on=['user_id', 'click_article_id'])
# 保存训练集交叉验证产生的新特征
score_df[['user_id', 'click_article_id', 'pred_score', 'pred_rank', 'label']].to_csv(save_path + 'trn_din_cls_feats.csv', index=False)
# 测试集的预测结果,多次交叉验证求平均,将预测的score和对应的rank特征保存,可以用于后面的staking,这里还可以构造其他更多的特征
tst_user_item_feats_df_din_model['pred_score'] = sub_preds / k_fold
tst_user_item_feats_df_din_model['pred_score'] = tst_user_item_feats_df_din_model['pred_score'].transform(lambda x: norm_sim(x))
tst_user_item_feats_df_din_model.sort_values(by=['user_id', 'pred_score'])
tst_user_item_feats_df_din_model['pred_rank'] = tst_user_item_feats_df_din_model.groupby(['user_id'])['pred_score'].rank(ascending=False, method='first')
# 保存测试集交叉验证的新特征
tst_user_item_feats_df_din_model[['user_id', 'click_article_id', 'pred_score', 'pred_rank']].to_csv(save_path + 'tst_din_cls_feats.csv', index=False)
二、模型融合
1.加权融合
# 读取多个模型的排序结果文件
lgb_ranker = pd.read_csv(save_path + 'lgb_ranker_score.csv')
lgb_cls = pd.read_csv(save_path + 'lgb_cls_score.csv')
din_ranker = pd.read_csv(save_path + 'din_rank_score.csv')
# 这里也可以换成交叉验证输出的测试结果进行加权融合
rank_model = {'lgb_ranker': lgb_ranker,
'lgb_cls': lgb_cls,
'din_ranker': din_ranker}
def get_ensumble_predict_topk(rank_model, topk=5):
final_recall = rank_model['lgb_cls'].append(rank_model['din_ranker'])
rank_model['lgb_ranker']['pred_score'] = rank_model['lgb_ranker']['pred_score'].transform(lambda x: norm_sim(x))
final_recall = final_recall.append(rank_model['lgb_ranker'])
final_recall = final_recall.groupby(['user_id', 'click_article_id'])['pred_score'].sum().reset_index()
submit(final_recall, topk=topk, model_name='ensemble_fuse')
get_ensumble_predict_topk(rank_model)
2.Staking
# 读取多个模型的交叉验证生成的结果文件
# 训练集
trn_lgb_ranker_feats = pd.read_csv(save_path + 'trn_lgb_ranker_feats.csv')
trn_lgb_cls_feats = pd.read_csv(save_path + 'trn_lgb_cls_feats.csv')
trn_din_cls_feats = pd.read_csv(save_path + 'trn_din_cls_feats.csv')
# 测试集
tst_lgb_ranker_feats = pd.read_csv(save_path + 'tst_lgb_ranker_feats.csv')
tst_lgb_cls_feats = pd.read_csv(save_path + 'tst_lgb_cls_feats.csv')
tst_din_cls_feats = pd.read_csv(save_path + 'tst_din_cls_feats.csv')
# 将多个模型输出的特征进行拼接
finall_trn_ranker_feats = trn_lgb_ranker_feats[['user_id', 'click_article_id', 'label']]
finall_tst_ranker_feats = tst_lgb_ranker_feats[['user_id', 'click_article_id']]
for idx, trn_model in enumerate([trn_lgb_ranker_feats, trn_lgb_cls_feats, trn_din_cls_feats]):
for feat in [ 'pred_score', 'pred_rank']:
col_name = feat + '_' + str(idx)
finall_trn_ranker_feats[col_name] = trn_model[feat]
for idx, tst_model in enumerate([tst_lgb_ranker_feats, tst_lgb_cls_feats, tst_din_cls_feats]):
for feat in [ 'pred_score', 'pred_rank']:
col_name = feat + '_' + str(idx)
finall_tst_ranker_feats[col_name] = tst_model[feat]
# 定义一个逻辑回归模型再次拟合交叉验证产生的特征对测试集进行预测
# 这里需要注意的是,在做交叉验证的时候可以构造多一些与输出预测值相关的特征,来丰富这里简单模型的特征
from sklearn.linear_model import LogisticRegression
feat_cols = ['pred_score_0', 'pred_rank_0', 'pred_score_1', 'pred_rank_1', 'pred_score_2', 'pred_rank_2']
trn_x = finall_trn_ranker_feats[feat_cols]
trn_y = finall_trn_ranker_feats['label']
tst_x = finall_tst_ranker_feats[feat_cols]
# 定义模型
lr = LogisticRegression()
# 模型训练
lr.fit(trn_x, trn_y)
# 模型预测
finall_tst_ranker_feats['pred_score'] = lr.predict_proba(tst_x)[:, 1]
# 预测结果重新排序, 及生成提交结果
rank_results = finall_tst_ranker_feats[['user_id', 'click_article_id', 'pred_score']]
submit(rank_results, topk=5, model_name='ensumble_staking')
三、总结
本章主要学习了三个排序模型,包括LGB的Rank, LGB的Classifier还有深度学习的DIN模型,我们进行了简单的模型融合策略,包括简单的加权和Stacking。
【PS:我是没有跑出最后的结果,Win10上无法完成,只要baseline出来也满足了o( ̄︶ ̄)o】
参考资料
- 零基础入门推荐系统 - 新闻推荐
- http://datawhale.club/t/topic/202