Elastic Job学习笔记

目标:
第一章:概述
1、理解任务调度的概念
2、理解分布式任务调度的概念
3、能够说出Elastic-Job是什么
第二章:Elastic-Job快速入门
1、能够搭建Elastic-Job快速入门工程环境
2、能够编写Elastic-Job快速入门的程序
3、理解Elastic-Job整体架构的组成部分的职责
4、理解ZooKeeper在Elastic-Job中的作用
第三章:Spring Boot开发分布式任务调度
1、能够采用Spring Boot搭建Elastic-Job程序环境
2、理解作业分片的概念
3、能够实现Elastic-Job作业分片案例
第四章:Elastic-Job高级
1、能够使用事件跟踪
2、能够使用elastic-job-lite-console
3、能够使用Dump命令
Elastic-Job分布式任务调度
1.概述
1.1.什么是任务调度
我们可以先思考一下下面业务场景的解决方案:
- 某电商系统需要在每天上午10点,下午3点,晚上8点发放一批优惠券。
- 某银行系统需要在信用卡到期还款日的前三天进行短信提醒。
- 某财务系统需要在每天凌晨0:10结算前一天的财务数据,统计汇总。
- 12306会根据车次的不同,而设置某几个时间点进行分批放票。
- 某网站为了实现天气实时展示,每隔5分钟就去天气服务器获取最新的实时天气信息。
以上场景就是任务调度所需要解决的问题。
- 任务调度是指系统为了自动完成特定任务,在约定的特定时刻去执行任务的过程。有了任务调度即可解放更多的人力由系统自动去执行任务。
任务调度如何实现? 多线程方式实现: 学过多线程的同学,可能会想到,我们可以开启一个线程,每sleep一段时间,就去检查是否已到预期执行时间。 以下代码简单实现了任务调度的功能:
public static void main(String[] args) {
//任务执行间隔时间
final long timeInterval=3000;
Runnable runnable=new Runnable() {
@Override
public void run() {
while(true){
System.out.printf("time:%s,to do...\n",LocalDateTime.now().getSecond());
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
};
Thread thread=new Thread(runnable);
thread.start();
}
上面的代码实现了按一定的间隔时间执行任务调度的功能。
Jdk也为我们提供了相关支持,如Timer、ScheduledExecutor,下边我们了解下。
Timer方式实现:
public static void main(String[] args) {
Timer timer=new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.printf("time:%s,to do111...\n",LocalDateTime.now().getSecond());
}
},1000,2000);//1秒后开始调度,每2秒执行一次
Timer timer2=new Timer();
timer2.schedule(new TimerTask() {
@Override
public void run() {
System.out.printf("time:%s,to do222...\n",LocalDateTime.now().getSecond());
}
},1000,3000);//1秒后开始调度,每2秒执行一次
}
Timer 的优点在于简单易用,每个Timer对应一个线程,因此可以同时启动多个Timer并行执行多个任务,同一个Timer中的任务是串行执行。
ScheduledExecutor方式实现:
public static void main(String[] args) {
ScheduledExecutorService service= Executors.newScheduledThreadPool(10);
service.scheduleAtFixedRate(
new Runnable() {
@Override
public void run() {
System.out.printf("time:%s,to do...\n",LocalDateTime.now().getSecond());
}
},1,3, TimeUnit.SECONDS);
}
Java 5 推出了基于线程池设计的 ScheduledExecutor,其设计思想是,每一个被调度的任务都会由线程池中一个线程去执行,因此任务是并发执行的,相互之间不会受到干扰。
Timer 和 ScheduledExecutor 都仅能提供基于开始时间与重复间隔的任务调度,不能胜任更加复杂的调度需求。
比如,设置每月第一天凌晨1点执行任务、复杂调度任务的管理、任务间传递数据等等。
Quartz 是一个功能强大的任务调度框架,它可以满足更多更复杂的调度需求,Quartz 设计的核心类包括Scheduler, Job 以及 Trigger。其中,Job 负责定义需要执行的任务,Trigger 负责设置调度策略,Scheduler 将二者组装在一起,并触发任务开始执行。Quartz支持简单的按时间间隔调度、还支持按日历调度方式,通过设置
CronTrigger表达式(包括:秒、分、时、日、月、周、年)进行任务调度。
第三方Quartz方式实现:
public static void main(String[] args) throws SchedulerException {
//创建一个Scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//创建JobDetail
JobBuilder jobDetailBuilder = JobBuilder.newJob(MyJob.class);
jobDetailBuilder.withIdentity("jobName","jobGroupName");
JobDetail jobDetail = jobDetailBuilder.build();
//创建触发的CronTrigger 支持按日历调度
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName", "triggerGroupName")
.startNow().withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?"))
.build();//每隔两秒执行一次
//创建触发的SimpleTrigger 简单的间隔调度
/*
SimpleTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName","triggerGroupName")
.startNow().withSchedule(SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(2).repeatForever()).build();
*/
scheduler.scheduleJob(jobDetail,trigger); scheduler.start();
}
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.printf("time:%s,to do...\n", LocalDateTime.now().getSecond());
}
}
1.2.什么是分布式任务调度
什么是分布式?
当前软件的架构正在逐步转变为分布式架构,将单体结构分为若干服务,服务之间通过网络交互来完成用户的业务处理,如下图,电商系统为分布式架构,由订单服务、商品服务、用户服务等组成:

分布式系统具体如下基本特点:
分布性:每个部分都可以独立部署,服务之间交互通过网络进行通信,比如:订单服务、商品服务。伸缩性:每个部分都可以集群方式部署,并可针对部分结点进行硬件及软件扩容,具有一定的伸缩能力。高可用:每个部分都可以集群部分,保证高可用。
什么是分布式调度?
通常任务调度的程序是集成在应用中的,比如:优惠卷服务中包括了定时发放优惠卷的调度程序,结算服务中包括了定期生成报表的任务调度程序,由于采用分布式架构,一个服务往往会部署多个冗余实例来运行我们的业务,在这种分布式系统环境下运行任务调度,我们称之为分布式任务调度,如下图:

分布式调度要实现的目标:
不管是任务调度程序集成在应用程序中,还是单独构建的任务调度系统,如果采用分布式调度任务的方式就相当于将任务调度程序分布式构建,这样就可以具有分布式系统的特点,并且提高任务的调度处理能力:
1、并行任务调度
并行任务调度实现靠多线程,如果有大量任务需要调度,
此时光靠多线程就会有瓶颈了,因为一台计算机CPU的处理能力是有限的。
如果将任务调度程序分布式部署,每个结点还可以部署为集群,
这样就可以让多台计算机共同去完成任务调度,我们可以将任务分割为若干个分片,
由不同的实例并行执行,来提高任务调度的处理效率。
2、高可用
若某一个实例宕机,不影响其他实例来执行任务。
3、弹性扩容
当集群中增加实例就可以提高并执行任务的处理效率。
4、任务管理与监测
对系统中存在的所有定时任务进行统一的管理及监测。
让开发人员及运维人员能够时刻了解任务执行情况,从而做出快速的应急处理响应。
5、避免任务重复执行
当任务调度以集群方式部署,同一个任务调度可能会执行多次,
比如在上面提到的电商系统中到点发优惠券的例子,就会发放多次优惠券,
对公司造成很多损失,所以我们需要控制相同的任务在多个运行实例上只执行一次,
考虑采用下边的方法:
分布式锁,多个实例在任务执行前首先需要获取锁,如果获取失败那么久证明有其他服务已经再运行,
如果获取成功那么证明没有服务在运行定时任务,那么就可以执行。
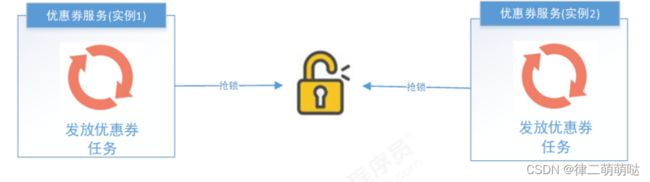
- ZooKeeper选举,利用ZooKeeper对Leader实例执行定时任务,有其他业务已经使用了ZK,那么执行定时任务的时候判断自己是否是Leader,如果不是则不执行,如果是则执行业务逻辑,这样也能达到我们的目的。
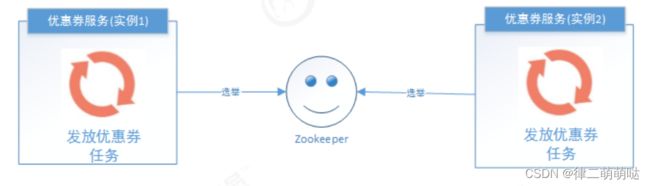
2 Elastic-Job介绍
针对分布式任务调度的需求市场上出现了很多的产品:
1)Elastic-job:当当网基于quartz 二次开发的弹性分布式任务调度系统,功能丰富强大,采用zookeeper实现分布式协调,实现任务高可用以及分片。
2)Saturn: 唯品会开源的一个分布式任务调度平台,可以全域统一配置,统一监控,任务高可用以及分片并发处理。它是在elastic-job基础之上改良出来的。
3)xxl-job:大众点评的分布式任务调度平台,是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
4)TBSchedule:淘宝的一款非常优秀的高性能分布式调度框架,目前被应用于阿里、京东、支付宝、国美等很多互联网企业的流程调度系统中。
Elastic-Job是一个分布式调度的解决方案,由当当网开源,它由两个相互独立的子项目Elastic-Job-Lite和ElasticJob-Cloud组成,使用Elastic-Job可以快速实现分布式任务调度。
Elastic-Job的github地址:https://github.com/elasticjob
功能列表:
分布式调度协调在分布式环境中,任务能够按指定的调度策略执行,并且能够避免同一任务多实例重复执行。
丰富的调度策略:
基于成熟的定时任务作业框架Quartz cron表达式执行定时任务。
弹性扩容缩容
当集群中增加某一个实例,它应当也能够被选举并执行任务;当集群减少一个实例时,它所执行的任务能被转移到别的实例来执行。
失效转移
某实例在任务执行失败后,会被转移到其他实例执行。
错过执行作业重触发若因某种原因导致作业错过执行,自动记录错过执行的作业,并在上次作业完成后自动触发。
支持并行调度
支持任务分片,任务分片是指将一个任务分为多个小任务项在多个实例同时执行。
作业分片一致性
当任务被分片后,保证同一分片在分布式环境中仅一个执行实例。
支持作业生命周期操作
可以动态对任务进行开启及停止操作。
丰富的作业类型
支持Simple、DataFlow、Script三种作业类型,后续会有详细介绍。
Spring整合以及命名空间支持
对Spring支持良好的整合方式,支持spring自定义命名空间,支持占位符。
运维平台提供运维界面,可以管理作业和注册中心。
3 Elastic-Job快速入门
3.1 环境搭建
3.1.1 版本要求
JDK要求1.7及以上版本
Maven要求3.0.4及以上版本
zookeeper要求采用3.4.6及以上版本
3.1.2 Zookeeper安装&运行
https://archive.apache.org/dist/zookeeper/ 下载某版本Zookeeper,并解压。
执行解压目录下的bin/zkServer.cmd。
关于Zookeeper后续章节会有介绍。
3.1.3 创建maven工程
创建maven工程elastic-job-quickstart,并导入以下依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.itheima.schedulergroupId>
<artifactId>elastic-job-quickstartartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
<dependencies>
<dependency>
<groupId>com.dangdanggroupId>
<artifactId>elastic-job-lite-coreartifactId>
<version>2.1.5version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.0version>
dependency>
dependencies>
project>
工程结构如下:
3.2 代码实现
3.2.1.编写定时任务类
此任务在每次执行时获取一定数目的文件,进行备份处理,由File实体类的backedUp属性来标识该文件是否已备份。
/*
文件备份任务
*/
public class FileBackupJob implements SimpleJob {
//文件列表(模拟)
public static List<FileCustom> files=new ArrayList<>();
//每次任务执行要备份文件的数量
private final int FETCH_SIZE=1;
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片信息:"+shardingContext.getShardingItem());
//1.获取未备份文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
//获取未备份文件
public List<FileCustom> fetchUnBackupFiles(int count){
//获取的文件列表
List<FileCustom> fileCustoms=new ArrayList<>();
int num=0;
for (FileCustom file : files) {
if(count<=num){
break;
}
//未备份
if(!file.getBackedUp()){
fileCustoms.add(file);
num++;
}
}
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),num);
return fileCustoms;
}
/*
文件备份
*/
public void backupFiles(List<FileCustom> files){
for (FileCustom file : files) {
file.setBackedUp(true);
System.out.printf("time:%s,备份文件,名称:%s,类型:%s\n", LocalDateTime.now(),file.getName(),file.getType());
}
}
}
文件实体类如下:
@Data
public class FileCustom {
private String id;//标识
private String name;//文件名
private String type;//文件类型,如text、image、radio、vedio
private String content;//文件内容
private Boolean backedUp=false;//是否已备份
public FileCustom(String id, String name, String type, String content) {
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
3.2.2 编写启动类
public class JobMain {
//zookeeper端口
private static final int ZOOKEEPER_PORT=2181;
//zookeeper连接字符串 localhost:2181
private static final String ZOOKEEPER_CONNECTION_STRING="localhost:"+ZOOKEEPER_PORT;
//定时任务命名空间
private static final String JOB_NAMESPACE="elastic-job-example-java";
//启动任务
public static void main(String[] args) {
//制造一些测试数据
generateTestFiles();
//配置注册中心
CoordinatorRegistryCenter registryCenter = setUpRegistryCenter();
//启动任务
startJob(registryCenter);
}
//zk的配置
//注册中心配置
private static CoordinatorRegistryCenter setUpRegistryCenter(){
//注册中心配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING,JOB_NAMESPACE);
//减少zk的超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
//创建注册中心
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
registryCenter.init();
return registryCenter;
}
//配置并启动任务
private static void startJob(CoordinatorRegistryCenter registryCenter){
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量1
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration.newBuilder("files‐job", "0/3 * * * * ?", 1) .build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(jobCoreConfiguration, FileBackupJob.class.getCanonicalName());
//启动任务
new JobScheduler(registryCenter, LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build()).init();
}
//生成测试文件
private static void generateTestFiles(){
for(int i=1;i<11;i++){
FileBackupJob.files.add(new FileCustom(String.valueOf(i+10),"文件"+ (i+10),"text","content"+ (i+10)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+20),"文件"+ (i+20),"image","content"+ (i+20)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+30),"文件"+ (i+30),"radio","content"+ (i+30)));
FileBackupJob.files.add(new FileCustom(String.valueOf(i+40),"文件"+ (i+40),"video","content"+ (i+40)));
}
System.out.println("生成测试数据完成");
}
}
2.2.3 测试
(1)启动main方法查看控制台

定时任务每3秒批量执行一次,符合基础预期。
(2)测试窗口1不关闭,再次运行main方法观察控制台日志(窗口2)
会出现以下两种情况:
- 窗口1继续执行任务,窗口2不执行任务
- 窗口2接替窗口1执行任务,窗口1停止执行任务
可通过反复启停窗口2查看到以上现象。
(3)窗口1、窗口2同时运行的情况下,停止正在执行任务的窗口
未停止的窗口开始执行任务。
分片测试:
当前作业没有被分片,所以多个实例共同执行时只有一个实例在执行,如果我们将作业分片执行,作业将被拆分为多个独立的任务项,然后由分布式的应用实例分别执行某一个或几个分片项。
修改上边的代码,改为作业分3片执行:
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration jobCoreConfiguration = JobCoreConfiguration.newBuilder("files‐job", "0/3 * * * * ?", 3) .build();
同时启动三个JobMain:
每个JobMain窗口分别执行一片作业。
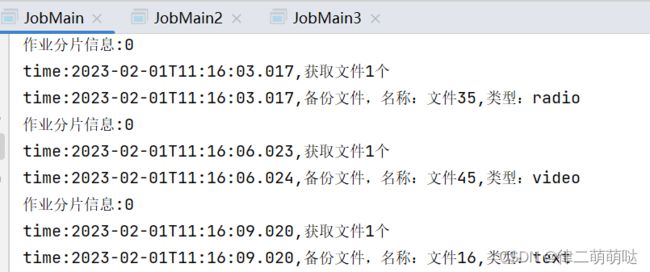
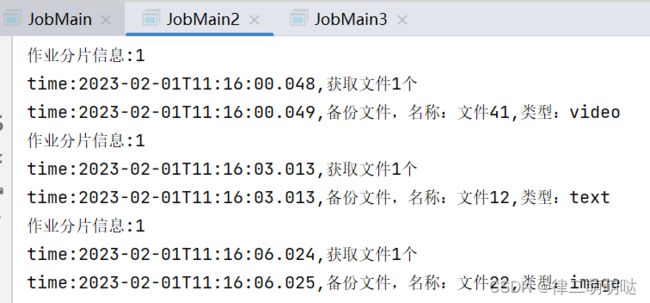
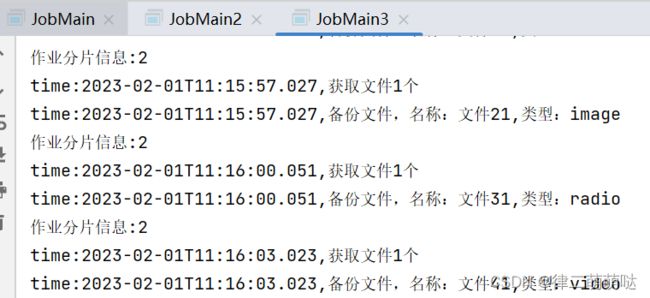
总结:
通过以上简单的测试,就可以看出Elastic-Job帮我们解决了分布式调度的以下三个问题:
1)多实例部署时避免任务重复执行,在任务执行时间到来时,从所有实例中选举出来一个,让它来执行任务,从而避免多个实例同时执行任务。
2)高可用,若某一个实例宕机,不影响其他实例来执行任务。
3)弹性扩容,当集群中增加某一个实例,它应当也能够被选举并执行任务,如果作业分片将参与执行某个分片作业。
3.3 Elastic-Job工作原理
3.3.1.Elastic-Job整体架构
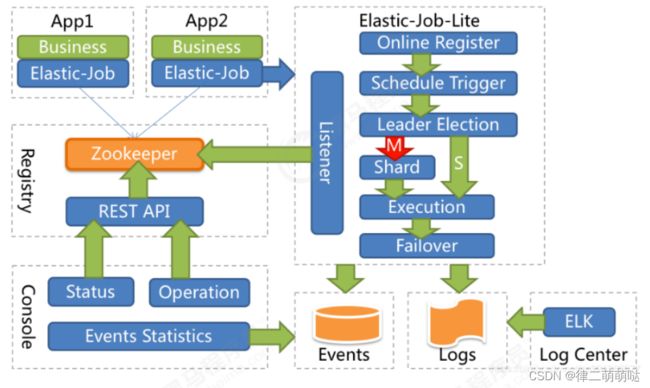
- App:应用程序,内部包含任务执行业务逻辑和Elastic-Job-Lite组件,其中执行任务需要实现ElasticJob接口完成与Elastic-Job-Lite组件的集成,并进行任务的相关配置。应用程序可启动多个实例,也就出现了多个任务执行实例。
- Elastic-Job-Lite:Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务,此组件负责任务的调度,并产生日志及任务调度记录。无中心化,是指没有调度中心这一概念,每个运行在集群中的作业服务器都是对等的,各个作业节点是自治的、平等的、节点之间通过注册中心进行分布式协调。
- Registry:以Zookeeper作为Elastic-Job的注册中心组件,存储了执行任务的相关信息。同时,Elastic-Job利用该组件进行执行任务实例的选举。
- Console:Elastic-Job提供了运维平台,它通过读取Zookeeper数据展现任务执行状态,或更新Zookeeper数据修改全局配置。通过Elastic-Job-Lite组件产生的数据来查看任务执行历史记录。
- 应用程序在启动时,在其内嵌的Elastic-Job-Lite组件会向Zookeeper注册该实例的信息,并触发选举(此时可能已经启动了该应用程序的其他实例),从众多实例中选举出一个Leader,让其执行任务。当到达任务执行时间时,Elastic-Job-Lite组件会调用由应用程序实现的任务业务逻辑,任务执行后会产生任务执行记录。当应用程序的某一个实例宕机时,Zookeeper组件会感知到并重新触发leader选举。
3.3.2 ZooKeeper
在学习Elastic-Job执行原理时,有必要大致了解一下ZooKeeper是用来做什么的,因为:
- Elastic-Job依赖ZooKeeper完成对执行任务信息的存储(如任务名称、任务参与实例、任务执行策略等);
- Elastic-Job依赖ZooKeeper实现选举机制,在任务执行实例数量变化时(如在快速上手中的启动新实例或停止实例),会触发选举机制来决定让哪个实例去执行该任务。
ZooKeeper是一个分布式一致性协调服务,它是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
咱们可以把ZooKeeper想象为一个特殊的数据库,它维护着一个类似文件系统的树形数据结构,ZooKeeper的客户端(如Elastic-Job任务执行实例)可以对数据进行存取:
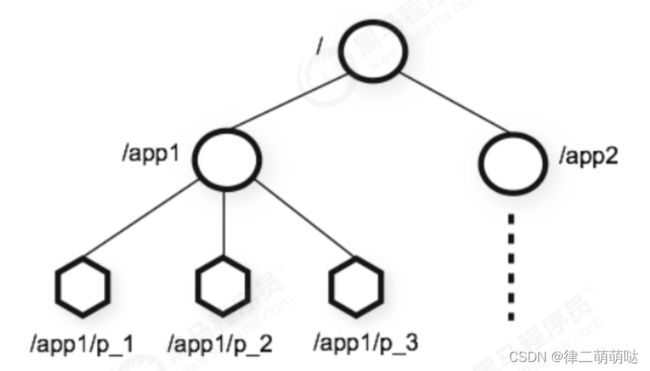
每个子目录项如 /app1都被称作为 znode(目录节点),和文件系统一样,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,唯一的不同在于znode是可以存储数据的。
ZooKeeper为什么称之为一致性协调服务呢?因为ZooKeeper拥有数据监听通知机制,客户端注册监听它关心的znode,当znode发生变化(数据改变、被删除、子目录节点增加删除)时,ZooKeeper会通知所有客户端。简单来说就是,当分布式系统的若干个服务都关心一个数据时,当这个数据发生改变,这些服务都能够得知,那么这些服务就针对此数据达成了一致。
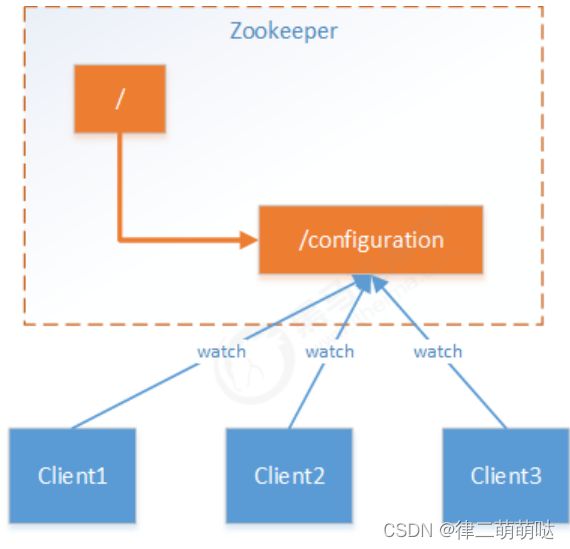
应用场景思考,使用ZooKeeper管理分布式配置项的机制:
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,
需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,
保存在 zookeeper 的某个目录节点中,然后所有相关应用程序作为ZooKeeper的客户端
对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 ZooKeeper的通知,
从而获取新的配置信息应用到系统中。
3.3.2.1.Elastic-Job任务信息的保存
- Elastic-Job使用ZooKeeper完成对任务信息的存取,任务执行实例作为ZooKeeper客户端对其znode操作,任务信息保存在znode中。
使用ZooInspector查看zookeeper节点
1、zookeeper图像化客户端工具的下载地址:
https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
2、下载完后解压压缩包,双击地址为ZooInspector\build\zookeeper-dev-ZooInspector.jar的jar包;
如果双击没有反应?首先电脑要配好java环境,使用java -jar 再加上你的jar文件的路径 启动即可.
java -jar zookeeper-dev-ZooInspector.jar
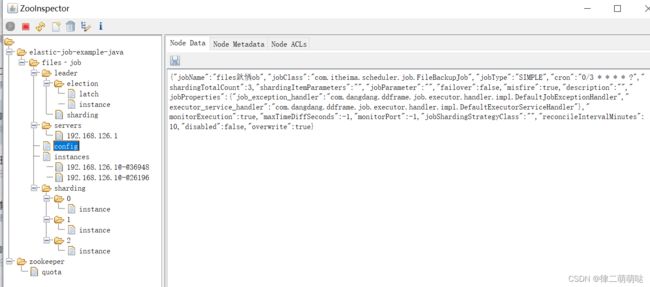
节点记录了任务的配置信息,包含执行类,cron表达式,分片算法类,分片数量,分片参数。默认状态下,如果你修改了Job的配置比如cron表达式,分片数量等是不会更新到zookeeper上去的,需要把LiteJobConfiguration的参数overwrite修改成true,或者删除zk的结点再启动作业重新创建。


2.3.2.2.Elastic-Job任务执行实例选举
Elastic-Job使用ZooKeeper实现任务执行实例选举,若要使用ZooKeeper完成选举,就需要了解ZooKeeper的znode类型了,ZooKeeper有四种类型的znode,客户端在创建znode时可以指定:
- PERSISTENT-持久化目录节点
客户端创建该类型znode,此客户端与ZooKeeper断开连接后该节点依旧存在,如果创建了重复的key,比如/data,第二次创建会失败。
- PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与ZooKeeper断开连接后该节点依旧存在,允许重复创建相同key,Zookeeper给该节点名称进行顺序编号,如zk会在后面加一串数字比如 /data/data0000000001,如果重复创建,会创建一个/data/data0000000002节点(一直往后加1)
- EPHEMERAL-临时目录节点
客户端与ZooKeeper断开连接后,该节点被删除,不允许重复创建相同key。
- EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与ZooKeeper断开连接后,该节点被删除,允许重复创建相同key,依然采取顺序编号机制。
实例选举实现过程分析:
每个Elastic-Job的任务执行实例作为ZooKeeper的客户端来操作ZooKeeper的znode
1)任意一个实例启动时首先创建一个 /server 的PERSISTENT节点
2)多个实例同时创建 /server/leader EPHEMERAL子节点
3) /server/leader子节点只能创建一个,后创建的会失败。创建成功的实例被选为leader节点 , 用来执行任务。
4)所有任务实例监听 /server/leader 的变化,一旦节点被删除,就重新进行选举,抢占式地创建 /server/leader节点,谁创建成功谁就是leader。
3.4 小结
通过本章,我们完成了对Elastic-Job技术的快速入门程序,并了解了Elastic-Job整体架构
和工作原理。对于应用程序,只需要将任务执行细节包装为ElasticJob接口的实现类
并对任务细节进行配置即可完成与ElasticJob的集成,而Elastic-Job需要依赖Zookeeper
进行执行任务信息的存取,执行任务实例的选举。通过对快速入门程序的测试,
我们可以看到Elastic-Job确实解决了分布式任务调度的核心问题。
4. Spring Boot开发分布式任务
4.1 集成Spring Boot
将Elastic-job快速入门中的例子改造为spring boot集成方式。
4.1.1 导入maven依赖
创建elastic-job-springboot工程,依赖如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.7.8version>
<relativePath/>
parent>
<groupId>com.itheimagroupId>
<artifactId>elastic-job-springbootartifactId>
<version>0.0.1-SNAPSHOTversion>
<name>elastic-job-springbootname>
<description>elastic-job-springbootdescription>
<properties>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.0version>
dependency>
<dependency>
<groupId>com.dangdanggroupId>
<artifactId>elastic-job-lite-springartifactId>
<version>2.1.5version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
工程结构图如下:
4.1.2 编写spring boot配置文件及启动类
spring boot 配置文件:
server.port=${PORT:56081}
spring.application.name=task‐scheduling‐springboot
logging.level.root=info
spring boot 启动类:
@SpringBootApplication
public class ElasticJobApp {
public static void main(String[] args) {
SpringApplication.run(ElasticJobApp.class, args);
}
}
4.1.3 编写Elastic-Job配置类及任务类
Zookeeper配置类:
@Configuration
public class RegistryCenterConfig {
//zookeeper端口
private final int ZOOKEEPER_PORT=2181;
//zookeeper连接字符串 localhost:2181
private final String ZOOKEEPER_CONNECTION_STRING="localhost:"+ZOOKEEPER_PORT;
//定时任务命名空间
private final String JOB_NAMESPACE="elastic-job-example-java";
//zk的配置
//注册中心配置
@Bean(initMethod = "init")
public CoordinatorRegistryCenter setUpRegistryCenter(){
//注册中心配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING,JOB_NAMESPACE);
//减少zk的超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
//创建注册中心
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
//registryCenter.init();
return registryCenter;
}
}
Elastic-Job配置类:
@Configuration
public class ElasticJobConfig {
@Autowired
FileBackupJob fileBackupJob;
@Autowired
CoordinatorRegistryCenter registryCenter;
@Bean(initMethod="init")
public SpringJobScheduler initSimpleElasticJob(){
LiteJobConfiguration jobConfiguration = createJobConfiguration(fileBackupJob.getClass(), "0/3 * * * * ?", 3, null);
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileBackupJob, registryCenter,jobConfiguration);
return springJobScheduler;
}
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob>
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration configuration=builder.build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(configuration,jobClass.getCanonicalName());
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}
}
Elastic-Job任务类:
/*
文件备份任务
*/
@Component
public class FileBackupJob implements SimpleJob {
//文件列表(模拟)
public static List<FileCustom> files=new ArrayList<>();
//每次任务执行要备份文件的数量
private final int FETCH_SIZE=1;
static {
for(int i=1;i<11;i++){
files.add(new FileCustom(String.valueOf(i+10),"文件"+ (i+10),"text","content"+ (i+10)));
files.add(new FileCustom(String.valueOf(i+20),"文件"+ (i+20),"image","content"+ (i+20)));
files.add(new FileCustom(String.valueOf(i+30),"文件"+ (i+30),"radio","content"+ (i+30)));
files.add(new FileCustom(String.valueOf(i+40),"文件"+ (i+40),"video","content"+ (i+40)));
}
System.out.println("生成测试数据完成");
}
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片信息:"+shardingContext.getShardingItem());
//1.获取未备份文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
//获取未备份文件
public List<FileCustom> fetchUnBackupFiles(int count){
//获取的文件列表
List<FileCustom> fileCustoms=new ArrayList<>();
int num=0;
for (FileCustom file : files) {
if(count<=num){
break;
}
//未备份
if(!file.getBackedUp()){
fileCustoms.add(file);
num++;
}
}
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),num);
return fileCustoms;
}
/*
文件备份
*/
public void backupFiles(List<FileCustom> files){
for (FileCustom file : files) {
file.setBackedUp(true);
System.out.printf("time:%s,备份文件,名称:%s,类型:%s\n", LocalDateTime.now(),file.getName(),file.getType());
}
}
}
FileCustom
@Data
public class FileCustom {
private String id;//标识
private String name;//文件名
private String type;//文件类型,如text、image、radio、vedio
private String content;//文件内容
private Boolean backedUp=false;//是否已备份
public FileCustom(String id, String name, String type, String content) {
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
设置三个启动配置,修改端口,模拟多线程


运行结果,分片处理作业


4.2.作业分片
4.2.1.分片概念
作业分片是指任务的分布式执行,需要将一个任务拆分为多个独立的任务项,
然后由分布式的应用实例分别执行某 一个或几个分片项。
例如:Elastic-Job快速入门中文件备份的例子,现有2台服务器,每台服务器分别跑一个应用实例。为了快速的执 行作业,那么可以将作业分成4片,每个应用实例个执行2片。作业遍历数据的逻辑应为:实例1查找text和image 类型文件执行备份;实例2查找radio和video类型文件执行备份。 如果由于服务器扩容应用实例数量增加为4,则 作业遍历数据的逻辑应为:4个实例分别处理text、image、radio、video类型的文件。
- 可以看到,通过对任务合理的分片化,从而达到任务并行处理的效果,大限度的提高执行作业的吞吐量。
分片项与业务处理解耦
Elastic-Job并不直接提供数据处理的功能,框架只会将分片项分配至各个运行中的作业服务器,开发者需要自行处 理分片项与真实数据的对应关系。
最大限度利用资源
将分片项设置为大于服务器的数量,好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配 分片项。
例如:3台服务器,分成10片,则分片项分配结果为服务器A=0,1,2;服务器B=3,4,5;服务器C=6,7,8,9。 如果服务器C 崩溃,则分片项分配结果为服务器A=0,1,2,3,4;服务器B=5,6,7,8,9。在不丢失分片项的情况下,大限度的利用现 有资源提高吞吐量。
4.2.2 作业分片实现
- 基于Spring boot集成方式的而产出的工程代码,完成对作业分片的实现,文件数据备份采取更接近真实项目的数 据库存取方式。
4.2.2.1 创建数据库
数据库:mysql-8.0
创建elastic_job_demo数据库:
CREATE DATABASE `elastic_job_demo` CHARACTER SET 'utf8' COLLATE 'utf8_general_ci';
CREATE TABLE `t_file` (
`id` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` VARCHAR (255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`type` VARCHAR (255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`content` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`backedUp` tinyint(1) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = INNODB CHARACTER
SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
项目结构

4.2.2.2 maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.0version>
dependency>
<dependency>
<groupId>com.dangdanggroupId>
<artifactId>elastic-job-lite-springartifactId>
<version>2.1.5version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.27version>
dependency>
dependencies>
4.2.2.3 编写文件服务类
FileService
@Service
public class FileService {
@Autowired
JdbcTemplate jdbcTemplate;
/**
* @description
* @author ThinkPad
* @param[1] fileType
* @param[2] count
* @throws
* @return List
* @time 2023/2/2 16:03
*/
public List<FileCustom> fetchUnBackupFiles(String fileType,Integer count){
String sql="select *from t_file where type=? and backedUp=0 limit 0,?";
List<FileCustom> files = jdbcTemplate.query(sql, new Object[]{fileType, count}, new BeanPropertyRowMapper(FileCustom.class));
return files;
}
/**
* @description 备份文件
* @author ThinkPad
* @param[1] files
* @throws
* @time 2023/2/3 9:32
*/
public void backupFiles(List<FileCustom> files){
for (FileCustom file : files) {
String sql="update t_file set backedUp=1 where id=?";
jdbcTemplate.update(sql,file.getId());
System.out.println(String.format("线程 %d | 已备份文件:%s 文件类型:%s"
,Thread.currentThread().getId()
,file.getName()
,file.getType()));
}
}
}
4.2.2.4 Elastic-Job任务类
FileBackupJobDb
/*
文件备份任务
*/
@Component
public class FileBackupJobDb implements SimpleJob {
//文件列表(模拟)
public static List<FileCustom> files=new ArrayList<>();
//每次任务执行要备份文件的数量
private final int FETCH_SIZE=1;
@Autowired
private FileService fileService;
//任务执行代码逻辑
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("作业分片信息:"+shardingContext.getShardingItem());
//分片参数 0=text,1=image,2=radio,3=video
//获取分片参数
String jobParameter = shardingContext.getShardingParameter();
//1.获取未备份文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(jobParameter,FETCH_SIZE);
//进行文件备份
backupFiles(fileCustoms);
}
//获取未备份文件
public List<FileCustom> fetchUnBackupFiles(String fileType,int count){
List<FileCustom> fileCustoms = fileService.fetchUnBackupFiles(fileType, count);
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),count);
return fileCustoms;
}
/*
文件备份
*/
public void backupFiles(List<FileCustom> files){
fileService.backupFiles(files);
}
}
4.2.2.5 编写Elastic-Job配置类及任务类
Zookeeper配置类
@Configuration
public class RegistryCenterConfig {
//zookeeper连接字符串 localhost:2181
private final String ZOOKEEPER_CONNECTION_STRING="localhost:2181";
//定时任务命名空间
private final String JOB_NAMESPACE="elastic-job-example-java";
//zk的配置
//注册中心配置
@Bean(initMethod = "init")
public CoordinatorRegistryCenter setUpRegistryCenter(){
//注册中心配置
ZookeeperConfiguration zookeeperConfiguration = new ZookeeperConfiguration(ZOOKEEPER_CONNECTION_STRING,JOB_NAMESPACE);
//减少zk的超时时间
zookeeperConfiguration.setSessionTimeoutMilliseconds(100);
//创建注册中心
CoordinatorRegistryCenter registryCenter = new ZookeeperRegistryCenter(zookeeperConfiguration);
//registryCenter.init();
return registryCenter;
}
}
Elastic-Job配置类
@Configuration
public class ElasticJobConfig {
@Autowired
FileBackupJobDb fileBackupJob;
@Autowired
CoordinatorRegistryCenter registryCenter;
@Bean(initMethod="init")
public SpringJobScheduler initSimpleElasticJob(){
LiteJobConfiguration jobConfiguration = createJobConfiguration(fileBackupJob.getClass(), "0/3 * * * * ?", 4, "0=text,1=image,2=radio,3=video");
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileBackupJob, registryCenter,jobConfiguration);
return springJobScheduler;
}
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob>
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration configuration=builder.build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(configuration,jobClass.getCanonicalName());
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}
}
4.2.2.6 编写文件实体类
FileCustom
@Data
@NoArgsConstructor
public class FileCustom {
private String id;//标识
private String name;//文件名
private String type;//文件类型,如text、image、radio、vedio
private String content;//文件内容
private Boolean backedUp=false;//是否已备份
public FileCustom(String id, String name, String type, String content) {
this.id = id;
this.name = name;
this.type = type;
this.content = content;
}
}
4.2.2.7 编写spring boot配置文件及启动类
spring boot 配置文件:
server.port=${PORT:56081}
spring.application.name=task?scheduling?springboot
logging.level.root=info
#数据源定义
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/elastic_job_demo?useUnicode=true
spring.datasource.username=root
spring.datasource.password=root
spring boot 启动类:
@SpringBootApplication
public class ElasticJobApp {
public static void main(String[] args) {
SpringApplication.run(ElasticJobApp.class, args);
}
}
4.2.2.8 测试
增加测试数据:
通过junit单元测试程序来增加:
@RunWith(SpringRunner.class)
@SpringBootTest
class GenerateTestData {
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void testGenerateTestData(){
//清除数据
clearTestFiles();
//制造数据
generateTestFiles();
}
//清除数据
private void clearTestFiles() {
jdbcTemplate.update("delete from t_file");
}
/**
* 创建模拟数据
*/
public void generateTestFiles(){
List<FileCustom> files =new ArrayList<>();
for(int i=1;i<11;i++){
files.add(new FileCustom(String.valueOf(i),"文件"+ i,"text","content"+ i));
files.add(new FileCustom(String.valueOf((i+10)),"文件"+(i+10),"image","content"+ (i+10)));
files.add(new FileCustom(String.valueOf((i+20)),"文件"+(i+20),"radio","content"+ (i+20)));
files.add(new FileCustom(String.valueOf((i+30)),"文件"+(i+30),"video","content"+ (i+30)));
}
for(FileCustom file : files){
jdbcTemplate.update("insert into t_file (id,name,type,content,backedUp) values (?,?,?,?,?)",
new Object[]{file.getId(),file.getName(),file.getType(),file.getContent(),file.getBackedUp()});
}
}
}
启动Spring boot的main方法ElasticJobApp,并查看控制台:

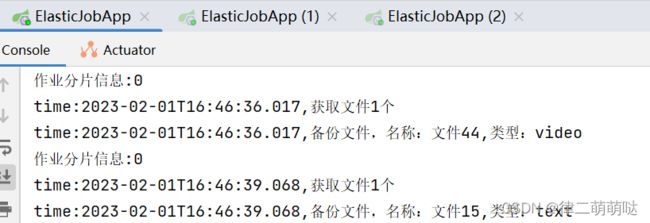
可以看出,text、image、radio、vedio四个分片被分布到这一个实例中执行。
分片弹性扩容缩容机制测试:
elastic-job的分片是通过zookeeper来实现的。分片由主节点分配,如下三种情况都会触发主节点上的分片算法执行:
新的Job实例加入集群 现有的Job实例下线(如果下线的是leader节点,那么先选举然后触发分片算法的执行) 主节点选举
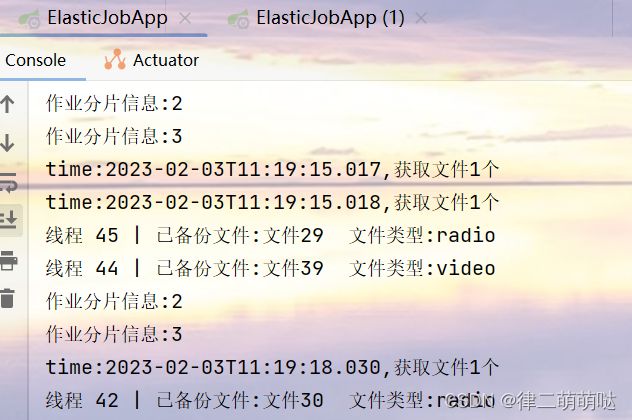
测试1:同时启动两个控制台ElasticJobApp 和ElasticJobApp(1)
ElasticJobApp
ElasticJobApp(1)
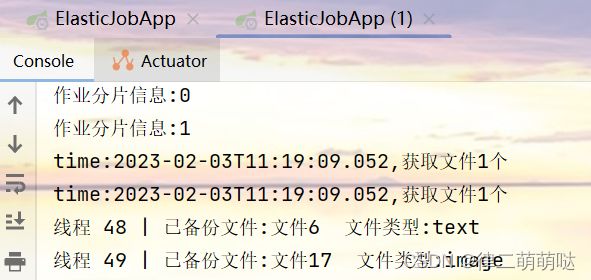
查看控制台输出可以得出如下结论: 1、任务运行期间,如果有新机器加入,则会立刻触发分片机制,将任务相对 平均的分配到每台机器上并行执行调度。 2、如果有机器退出集群,则经过短暂的一段时间(大约40秒)后又会重 新触发分片机制
如果在设置zookeeper注册中心时,设置了session超时时间100 毫秒,则下次任务前就会触发分片

如果在sessionTimeoutMs的时间段之内触发任务,则异常分片的任务会丢失。
举个例子:假如 sessionTimeoutMs被设置成1分钟,而本身的任务是30秒执行一次,
有三个任务实例在三台机器各自执行分片 1,2,3。当分片3所在的机器出现问题,
和zookeeper断开了,那么zookeeper节点失效至少要到1分钟以后。
期间30 秒执行一次的任务分片3,至少会少执行一次。1分钟过后,zookeeper节点失效,
触发 ListenServersChangedJobListener类的dataChanged方法,
在这里方法中判断instance节点变化,然后通过方法 shardingService.setReshardingFlag
设置重新分片标志位,下次执行任务的时候,leader节点重新分配分片,
分片 3就会转移到其他好的机器上。
4.2.3 作业配置说明
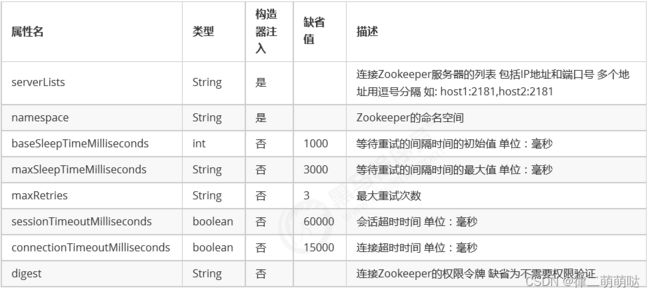
注册中心配置
ZookeeperConfiguration属性详细说明
作业配置
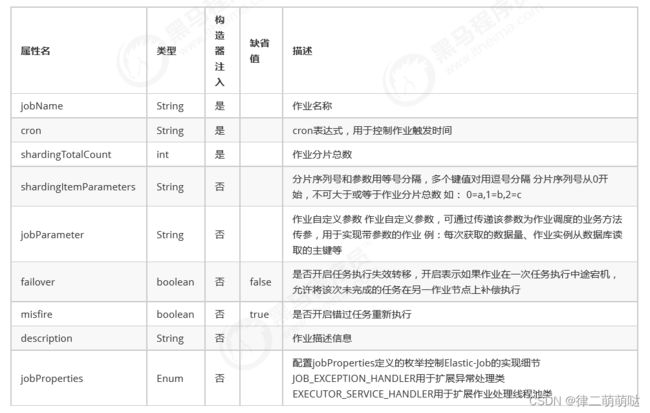
作业配置分为3级,分别是JobCoreConfiguration,JobTypeConfiguration和LiteJobConfiguration。 LiteJobConfiguration使用JobTypeConfiguration,JobTypeConfiguration使用JobCoreConfiguration,层层嵌 套。 JobTypeConfiguration根据不同实现类型分为SimpleJobConfiguration,DataflowJobConfiguration和 ScriptJobConfiguration。
4.2.4 作业分片策略
AverageAllocationJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.AverageAllocationJobShardingStrategy
策略说明:
基于平均分配算法的分片策略,也是默认的分片策略。
如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器。
如:如果有3台服务器,分成9片,则每台服务器分到的分片是:
1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:
1=[0,1,6], 2=[2,3,7], 3=[4,5] 如果有3台服务器,分成10片,
则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
OdevitySortByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.OdevitySortByNameJobShardingStrategy
策略说明:
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略。
作业名的哈希值为奇数则IP升序。
作业名的哈希值为偶数则IP降序。
用于不同的作业平均分配负载至不同的服务器。
AverageAllocationJobShardingStrategy的缺点是,一旦分片数小于作业服务器数,
作业将永远分配至IP地址靠前 的服务器,导致IP地址靠后的服务器空闲。
而OdevitySortByNameJobShardingStrategy则可以根据作业名称重新分配服务器负载。
如:如果有3台服务器,分成2片,作业名称的哈希值为奇数,
则每台服务器分到的分片是:1=[0], 2=[1], 3=[] 如果有3台服务器,分成2片,
作业名称的哈希值为偶数,则每台服务器分到的分片是:3=[0], 2=[1], 1=[]
RotateServerByNameJobShardingStrategy
全路径:
com.dangdang.ddframe.job.lite.api.strategy.impl.RotateServerByNameJobShardingStrategy
策略说明:
根据作业名的哈希值对服务器列表进行轮转的分片策略。
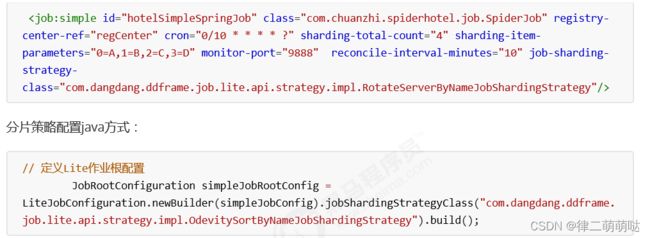
配置分片策略
与配置通常的作业属性相同,在spring命名空间或者JobConfiguration中配置
jobShardingStrategyClass属性,属 性值是作业分片策略类的全路径。
分片策略配置xml方式:
4.3 Dataflow类型定时任务
- Dataflow类型的定时任务需实现DataflowJob接口,该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据。咱们继续对例子进行改造。
- Dataflow类型用于
处理数据流,它和SimpleJob不同,它以数据流的方式执行,调用fetchData抓取数据,直到抓取不到数据才停止作业。
新增FileBackupDataFlowJob:
/*
文件备份任务
*/
@Component
public class FileBackupJobDataFlow implements DataflowJob<FileCustom> {
//文件列表(模拟)
public static List<FileCustom> files=new ArrayList<>();
//每次任务执行要备份文件的数量
private final int FETCH_SIZE=1;
@Autowired
private FileService fileService;
//抓取数据
@Override
public List<FileCustom> fetchData(ShardingContext shardingContext) {
System.out.println("作业分片信息:"+shardingContext.getShardingItem());
//分片参数 0=text,1=image,2=radio,3=video
//获取分片参数
String jobParameter = shardingContext.getShardingParameter();
//1.获取未备份文件
List<FileCustom> fileCustoms = fetchUnBackupFiles(jobParameter,FETCH_SIZE);
return fileCustoms;
}
//处理数据
@Override
public void processData(ShardingContext shardingContext, List<FileCustom> list) {
//进行文件备份
backupFiles(list);
}
//获取未备份文件
public List<FileCustom> fetchUnBackupFiles(String fileType,int count){
List<FileCustom> fileCustoms = fileService.fetchUnBackupFiles(fileType, count);
System.out.printf("time:%s,获取文件%d个\n", LocalDateTime.now(),fileCustoms.size());
return fileCustoms;
}
/*
文件备份
*/
public void backupFiles(List<FileCustom> files){
fileService.backupFiles(files);
}
}
ElasticJobConfig修改配置:
@Configuration
public class ElasticJobConfig {
/* @Autowired
FileBackupJobDb fileBackupJob;*/
@Autowired
FileBackupJobDataFlow fileBackupJob;
@Autowired
CoordinatorRegistryCenter registryCenter;
@Bean(initMethod="init")
public SpringJobScheduler initSimpleElasticJob(){
LiteJobConfiguration jobConfiguration = createFlowJobConfiguration(fileBackupJob.getClass(), "0/10 * * * * ?", 4, "0=text,1=image,2=radio,3=video");
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileBackupJob, registryCenter,jobConfiguration);
return springJobScheduler;
}
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
/* private LiteJobConfiguration createJobConfiguration(final Class
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration configuration=builder.build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(configuration,jobClass.getCanonicalName());
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}*/
//创建支持dataflow类型的作业的配置信息
private LiteJobConfiguration createFlowJobConfiguration(final Class<? extends ElasticJob>
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration configuration=builder.build();
//创建DataflowJobConfiguration
DataflowJobConfiguration dataflowJobConfiguration = new DataflowJobConfiguration(configuration,jobClass.getCanonicalName(),true);
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(dataflowJobConfiguration).overwrite(true).build();
return liteJobConfiguration;
}
}
启动应用后,日志输出如下:
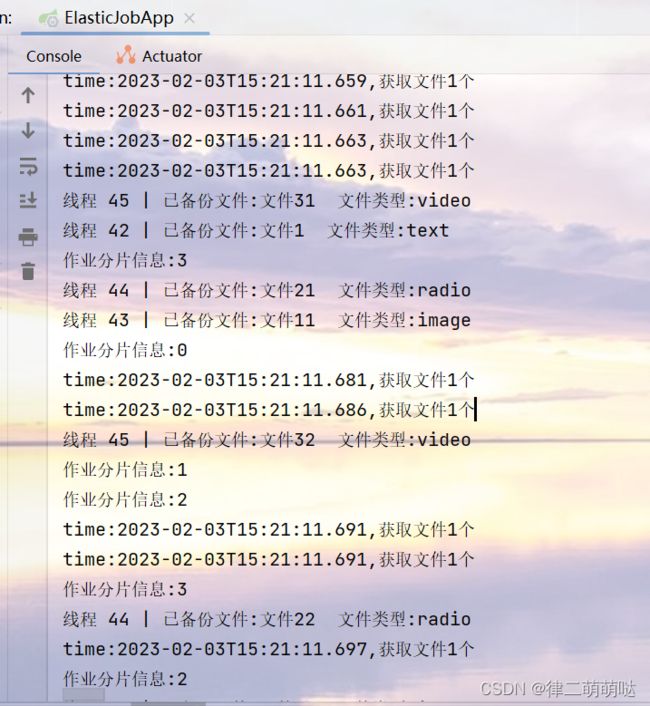
从输出日志可以看出,每次运行定时任务都会开启4个线程执行fetchData抓取数据,
抓取以后调用processData处理数据,如果是流式处理数据
(new DataflowJobConfiguration第三个参数为true)且fetchData方法的返回值为
null或集合长度为空时,作业才停止处理。
5. Elastic-Job高级
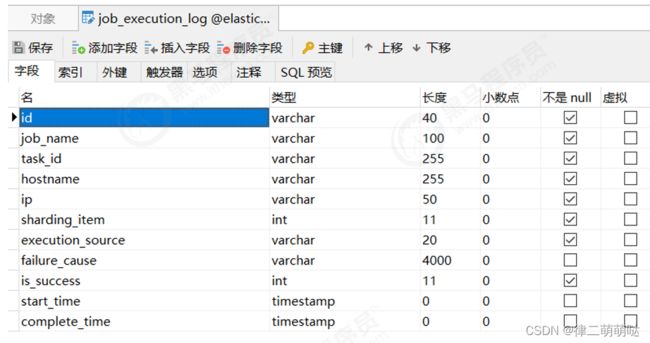
5.1 事件追踪
Elastic-Job-Lite在配置中提供了JobEventConfiguration,支持数据库方式配置,会在数据库中自动创建 JOB_EXECUTION_LOG和JOB_STATUS_TRACE_LOG两张表以及若干索引,来记录作业的相关信息。
5.1.1 修改Elastic-Job配置类
在ElasticJobConfig中修改:
@Configuration
public class ElasticJobConfig {
/* @Autowired
FileBackupJobDb fileBackupJob;*/
@Autowired
DataSource dataSource;//数据源已存在
@Autowired
FileBackupJobDb fileBackupJob;
@Autowired
CoordinatorRegistryCenter registryCenter;
@Bean(initMethod="init")
public SpringJobScheduler initSimpleElasticJob(){
LiteJobConfiguration jobConfiguration = createJobConfiguration(fileBackupJob.getClass(), "0/10 * * * * ?", 4, "0=text,1=image,2=radio,3=video");
//增加任务事件追踪配置
JobEventConfiguration jobEventConfig=new JobEventRdbConfiguration(dataSource);
SpringJobScheduler springJobScheduler = new SpringJobScheduler(fileBackupJob, registryCenter,jobConfiguration,jobEventConfig);
return springJobScheduler;
}
/**
* 配置任务详细信息
* @param jobClass 任务执行类
* @param cron 执行策略
* @param shardingTotalCount 分片数量
* @param shardingItemParameters 分片个性化参数
* @return
*/
private LiteJobConfiguration createJobConfiguration(final Class<? extends SimpleJob>
jobClass,
final String cron,
final int shardingTotalCount,
final String shardingItemParameters) {
//创建JobCoreConfiguration 每3秒钟启动一次 分片数量3
JobCoreConfiguration.Builder builder = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount);
if(StringUtils.isNotEmpty(shardingItemParameters)){
builder.shardingItemParameters(shardingItemParameters);
}
JobCoreConfiguration configuration=builder.build();
//创建SimpleJobConfiguration
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(configuration,jobClass.getCanonicalName());
//启动任务
LiteJobConfiguration liteJobConfiguration = LiteJobConfiguration.newBuilder(simpleJobConfiguration).overwrite(true)
.monitorPort(9888)//设置dump端口
.build();
return liteJobConfiguration;
}
}
5.1.2 启动项目
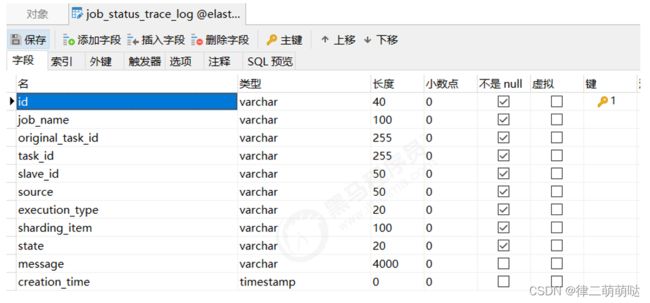
启动后会发现在elastic_job_demo数据库中新增以下两个表。
job_execution_log:
job_status_trace_log:

5.2 运维
elastic-job中提供了一个elastic-job-lite-console控制台
设计理念
- 本控制台和Elastic Job并无直接关系,是通过
读取Elastic Job的注册中心数据展现作业状态,或更新注册中心 数据修改全局配置。 2. 控制台只能控制作业本身是否运行,但不能控制作业进程的启停,因为控制台和作业本身服务器是完全分布 式的,控制台并不能控制作业服务器。
主要功能
- 查看作业以及服务器状态
- 快捷的修改以及删除作业设置
- 启用和禁用作业
- 跨注册中心查看作业
- 查看作业运行轨迹和运行状态
不支持项
- 添加作业。
因为作业都是在首次运行时自动添加,使用控制台添加作业并无必要。直接在作业服务器启动包 含Elastic Job的作业进程即可
具体搭建步骤如下:
5.2.1 搭建
下载地址:https://raw.githubusercontent.com/miguangying/elastic-job-lite-console/master/elastic-job-liteconsole-2.1.4.tar.gz
解压缩 elastic-job-lite-console-${version}.tar.gz 。

5.2.2 配置及使用
1、 配置注册中心地址
先启动zookeeper 然后在注册中心配置界面 点添加

点击提交后,然后点连接(zookeeper必须处于启动状态)
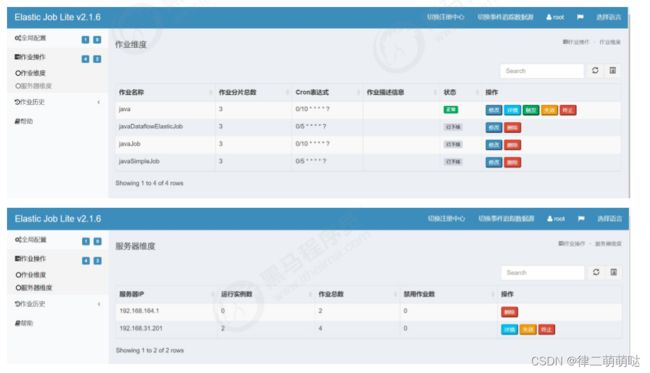
连接成功后,在作业维度下可以显示该命名空间下作业名称、分片数量及该作业的cron表达式等信息
在服务器维度可以查看服务器ip、当前运行的实例数、作业总数等信息。
2、配置事件追踪数据源
在事件追踪数据源配置页面点添加按钮,输入相关信息
提交后点击连接即可在作业历史下查看作业历史记录


5.3 dump命令
使用Elastic-Job-Lite过程中可能会碰到一些问题,导致作业运行不稳定。由于无法在生产环境调试,通过dump命 令可以把作业内部相关信息dump出来,方便开发者debug分析。
(1)开启dump监控端口,并运行程序 修改中ElasticJobConfig中的createJobConfiguration方法里JobRootConfiguration的配置,开启dump监控端口:

会在当前目录生成job_debug_dump.txt文件,打开job_debug_dump.txt后看到:

6. 课程总结
重要知识点回顾:
- 什么是任务调度?
- 任务调度的应用场景?
- 什么是分布式任务调度?
- 分布式任务调度需要解决那些问题?这些问题的大致解决思路?
- Elastic-Job是什么?
- Zookeeper在Elastic-Job整个架构中起到了什么作用? Elastic-Job分片的概念?分片是为了解决什么问题?
- Elastic-Job主要的配置类有哪些?各职责?
- Dataflow任务类型和SimpleJob类型有什么不同?