日报 7 | 数据分析应用
一、今日计划
对考核文本进行数据分析
二、知识
1、学习matplotlib的一些内容
(1)常常以plt作为matplotlib.pyplot的省略
(2)plt.plot()
默认情况下不会直接显示图像,只有调用了plt.show()
%matplotlib notebook也可以
(3)plt.plot()
可以用来绘制线型图
默认x是索引,给的list是y
plt.plot(x,y)
(4)字符参数
(5)显示范围:plt.axis([xmin,xmax,ymin,ymax])
(6)plt.setp()修改线条性质
(7)子图:
figure()函数会产生一个指定编号为num的图
subplot可以在一副图中生成多个子图
plot.subplot(numrows,numcols,fignum)
2、cd
cd命令:改变目录(向大的文件走)
cd\是到根目录
3、绘制散点图
(1)主要是用matplotlib中的scatter
基本命令:scatter(x, y, s=20, c=None, marker='o', cmap=None, norm=None, vmin=None,
vmax=None, alpha=None, linewidths=None, edgecolors=None)
x,y是坐标位置,s是点的大小,cmap是颜色映射表,marker是打点的标记,norm是设置数据亮度,vmin/vmax是亮度设置,alpha修改透明度,linewidths设置散点边界线的宽度,edgecolors设置散点边界线的颜色
x=df['long']
y=df['lat']
plt.scatter(x,y)
plt.title('车站分布图')
plt.show()这是一个比较基本的展示了,其实还有变颜色,框框(figure)设置等等
附一张marker
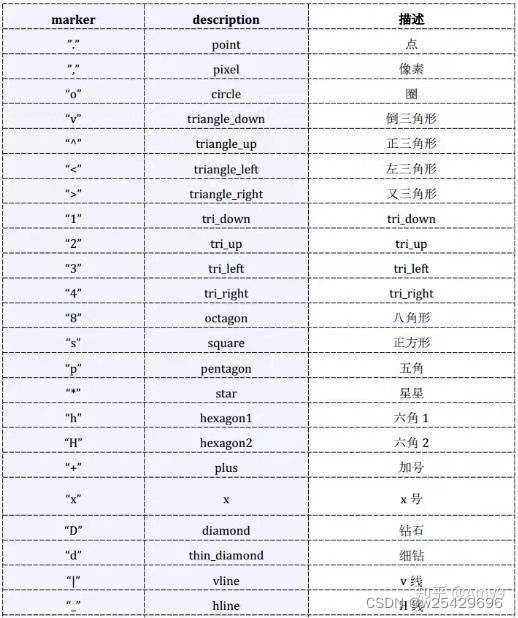
(2)用点的大小表示数量由大到小(气泡图)
思想:将数量大小归一化到点大小的尺度,如0~1000000对应到0~10的点的大小,然后将列表传入s参数
操作:其实就是给s一个值乘个常数看出变化
随机颜色:colors=np.random.rand(len(数据列表))
4、导入必备
分别是不显示warnings,导入三大库,解决中文和负号问题

三、问题
1、jupyter找不到电脑文件
根本原因是jupyter的文件在哪里打开,就获取在当下文件夹的信息。应该要先确保要导入的文件在jupyter所在文件夹
检查当前工作目录
import os
os.getcwd()然后就知道jupyter所在的文件夹了
如果在文件在文件夹里,则可以执行:
df=pd.read_csv('xxx.csv',index_col=0)否则获取文件的目录,然后执行:
df=pd.read_csv('C:\\x\\x\\x.csv',index_col=0)我尝试的时候文件就在我的用户文件夹里,用第一个不行,用第二个成功了

可以进行检验:df[:5],显示前五个内容正确即可
四、心得体会
一开始我都不知道数据分析要分析什么,在这里花费了很长时间,但与其跟excel中的数据大眼瞪小眼,不如做几个数据分析图出来,一边分析一边学,所以也慢慢开始了。几乎就是跟着别人的代码模仿的写,但是看到图形出来还是被惊喜到了
五、反思
最近进度慢了,卷起来
六、明日计划
学习更多的数据分析,运用三大库解决实际问题
2022.11.11