机器学习(11)--降维法PCA与SVD
目录
一、PCA
1、概述
2、降维原理
3、PCA重要参数n_components
4、PCA重要接口
5、鸢尾花数据集降维实战
5.1导入模块和库
5.2利用PCA降维
5.3降维后数据制图
二、SVD
1、概述
2、重要参数svd_solver
3、人像识别中的svd
3.1导入库
3.2实例化
3.3处理前人像图片显示
3.4处理后人像图片显示
3.5对降维图片进行升维后与原图片对比
4、基于手写体识别数据集进行降维算法在两种模型下的提升
一、PCA
1、概述
由于高维数据中,必不可少带有一些无效数据,即噪音,降维意味着减少特征的数量,但我们更希望减少无效特征的数量,保留大部分有效信息数量,减少运行时间。
PCA(主成分分析)使用的信息量衡量指标为样本方差,又称可解释性方差,方差越大,特征所带信息量越多。注意这里用的无偏估计的n-1。

2、降维原理
n维特征矩阵的降维原理,输入原数据(结构为(m,n)),给定降维后的特征数量k,通过某种变化,找出n个新特征向量,以及新n维空间V,并找出原数据在新特征空间V的n个新特征向量上对应的值,选取前k个信息量最大的特征,删掉没有被选中的特征,成功将n维空间V降为k维。
在寻找n个新特征向量时,将数据压缩到少数特征上并且总信息量不损失太多的技术就是矩阵分解,而PCA和SVD作为两种降维算法,均遵从上面的原理降维,只是矩阵分解的方式不同,PCA使用方差作为信息量的衡量指标,并且用特征值分解来找出空间V。SVD使用奇异值分解来找出空间V。
3、PCA重要参数n_components
n_components是我们降维后需要保留的维度,即保留的特征数量。
n_components一般输入范围内的整数k,即保留特征数量k;也可输入百分数p,即保留特征占总信息量的占比为p,并加入另一个参数svd_solver='full';也可输入'mle',返回最大似然估计后最优的特征数量。
4、PCA重要接口
| explained_variance_ |
返回可解释方差大小 |
explained_variance_ratio_ |
返回降维后每个新特征向量所占信息量的占原始数据总信息量的百分比 |
一定要在transform之后使用上述接口,不然会报错;接口是在PCA().fit(x)下的。
pca_mle=PCA(n_components='mle').fit(x) #最大似然估计mle,获得最优特征数量
x_mle_score=pca_mle.transform(x)
print(pca_mle.explained_variance_ratio_)5、鸢尾花数据集降维实战
5.1导入模块和库
from sklearn.datasets import load_iris #鸢尾花数据集
from sklearn.decomposition import PCA #PCA
import matplotlib.pyplot as plt
import pandas as pd5.2利用PCA降维
data=load_iris()
x=data.data
y=data.target
x=pd.DataFrame(x)
pca=PCA(n_components=2) #降到二维矩阵
x_new=pca.fit_transform(x)
print(x_new)5.3降维后数据制图
plt.figure()
for i in [0,1,2]:
plt.scatter(x_new[y==i,0],x_new[y==i,1],alpha=.7,label=data.target_names[i])
plt.legend()
plt.title("iris")
plt.show()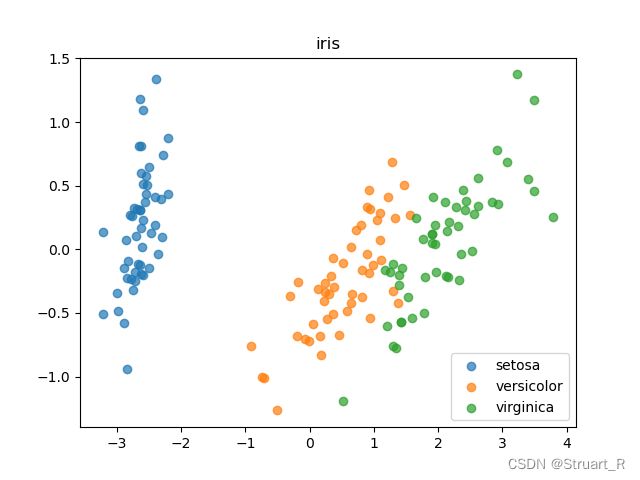
从图表能看出来三种花中每种有明显的集聚现象,这种数据非常适合用聚类模型。
二、SVD
1、概述
SVD利用奇异值分解,可以不计算协方差矩阵等结构复杂计算冗长的矩阵,可直接求出新特征空间和降维后特征矩阵。
2、重要参数svd_solver
svd_solver:分解器类型,默认为"auto"
| "auto" | 基于x.shape和n_components的默认策略来选择分解器,如果输入数据的尺寸大于500*500或者选择特征数小于最小维度的80%,就启用randomized分解器,否则启用full分解器。 |
| "full" | 返回完整的SVD,适合数据量适中,时间充裕情况 |
| "arpack" | 利用ARPACK分解器截断奇异值分解,加快运算速度,适用于特征矩阵很大的情况,一般用于稀疏矩阵 |
| "randomized" | 分解器先生成多个随机向量,检测随机向量中是否有任意一个符合分解需求,并保留该分解向量,构造向量空间。适合特征矩阵巨大,计算量庞大的情况。 |
3、人像识别中的svd
3.1导入库
from sklearn.datasets import fetch_lfw_people #人脸数据集
from sklearn.decomposition import PCA #导入PCA
import matplotlib.pyplot as plt3.2实例化
face=fetch_lfw_people(min_faces_per_person=60)
print(face.data.shape) #(1348,2914)
print(face.images.shape) #(1348, 62, 47)返回数据图片个数,每个数据特征矩阵行和列3.3处理前人像图片显示
fig,axes=plt.subplots(3,4 #3*8子图,画布尺寸12*4,坐标轴不标注单位
,figsize=(8,4)
,subplot_kw={'xticks':[],'yticks':[]})
for i ,ax in enumerate(axes.flat): #将24个数据铺平,循环24次
ax.imshow(face.images[i,:,:])
plt.show()3.4处理后人像图片显示
x=face.data
y=face.target
pca=PCA(150).fit(x)
V=pca.components_ #降维后的矩阵空间
fig,axes=plt.subplots(3,4 #3*8子图,画布尺寸12*4,坐标轴不标注单位
,figsize=(8,4)
,subplot_kw={'xticks':[],'yticks':[]})
for i ,ax in enumerate(axes.flat):
ax.imshow(V[i,:].reshape(62,47)) #降维后为二维数据,需要转换到原行列
plt.show() #一定记得加plt.show()显示图片
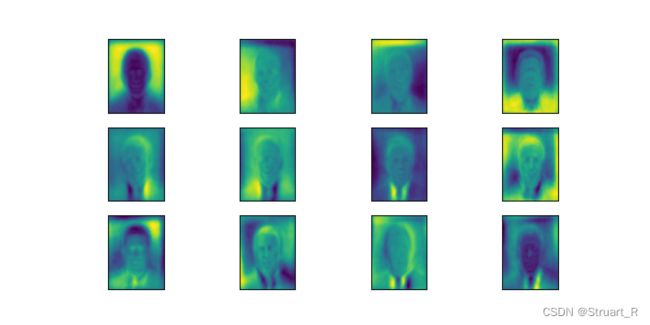
3.5对降维图片进行升维后与原图片对比
x_dr=pca.transform(x)
x_inverse=pca.inverse_transform(x_dr) #升维,逆转模型
fig,ax=plt.subplots(2,10
,figsize=(10,4)
,subplot_kw={'xticks':[],'yticks':[]}
)
for i in range(0,10):
ax[0,i].imshow(face.images[i,:,:],cmap='binary_r')
ax[1,i].imshow(x_inverse[i].reshape(62,47),cmap='binary_r')
plt.show()可以看到逆转后图片,并不是原图片,而是利用降维时的150个特征进行随机升维到62*47的空缺点上。
由于人像图片降维后对模型的处理不够完全,所以我们先利用手写体识别数据集来观察降维后acc的变化。
4、基于手写体识别数据集进行降维算法在两种模型下的提升
from sklearn.neighbors import KNeighborsClassifier as KNN
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_digits
data=load_digits()
x=data.data
y=data.target
score=cross_val_score(KNN(),x,y,cv=10).mean()
score_=cross_val_score(RFC(random_state=0),x,y,cv=10).mean()
print(score,score_)在降维算法前,KNN模型acc为0.9716,随机森林算法acc为0.9477。
利用学习曲线寻找最优的n_components值。
score_all=[]
score__all=[]
for i in range(1,64,1):
x_new=PCA(i).fit_transform(x)
score=cross_val_score(KNN(),x_new,y,cv=10).mean()
score_=cross_val_score(RFC(random_state=0),x_new,y,cv=10).mean()
score_all.append(score)
score__all.append(score_)
plt.figure()
plt.plot(range(1,64,1),score_all,c='r',alpha=.7,label='KNN')
plt.plot(range(1,64,1),score__all,c='b',alpha=.7,label='RFC')
print('knn',max(score_all),score_all.index(max(score_all)))
print('rfc',max(score__all),score__all.index(max(score__all)))
plt.show()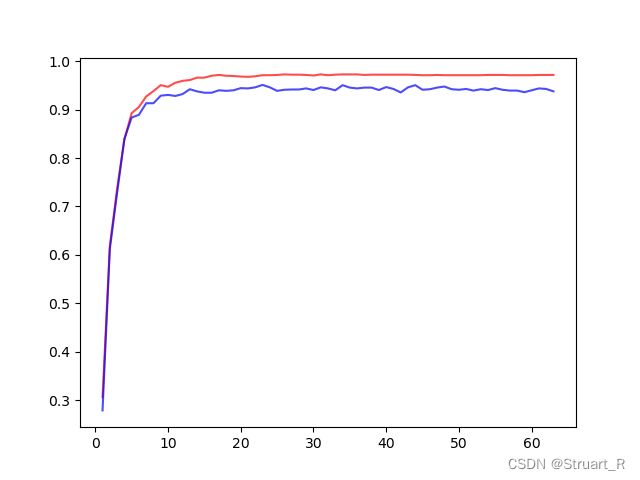
在降维算法后,最优值下的KNN模型acc为0.9727,随机森林算法acc为0.9510,算法有所提升。