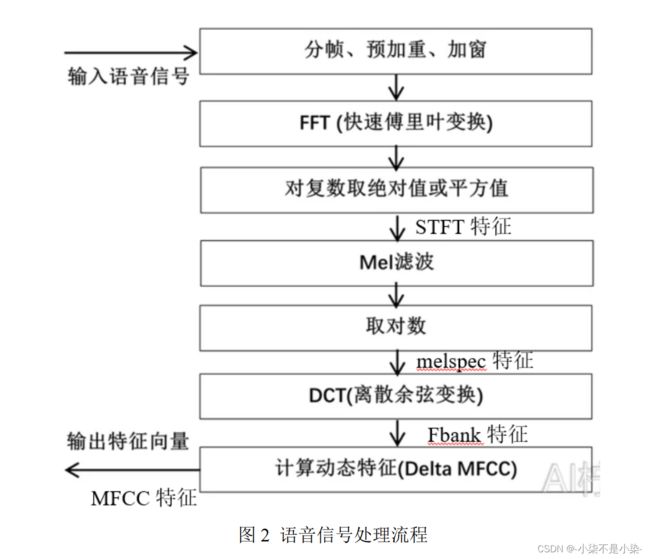
语音信号处理 —— 笔记(一)音频信号处理
声音的产生 :能量通过声带使其振动产生一股基声音,这个基声音通过声道 ,与声道发生相互作用产生共振声音,基声音与共振声音一起传播出去。
一、音频信号简介
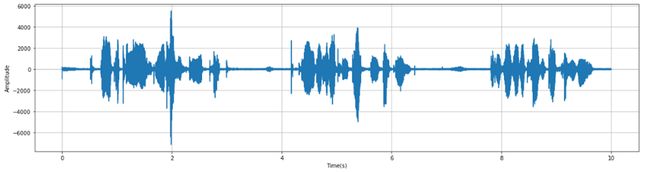
1.声音波形图
传感器以某种频率探测声音的振幅强度以及振动方向,所得到的一系列随时间变化的点。
2.采样频率
传感器的探测频率,即为采样频率。根据采样定理得到采样频率。
采样定理(Nyquist-Shannon定理)
定义:用来描述给定带宽的最高传输速率。
整数周期(eg.物体旋转后回到原状所需的时间),采样周期为整数倍的整数周期时不能检测到相位的变化。
*若为轮子转动问题:若需要同时看到旋转方向和相位变化,采样周期要小于整数周期的1/2,采样频率应大于原始频率的2倍。
➡️➡️对于模拟信号:要同时看到信号的全部特性,采样频率应大于原始模拟信号的最大频率的2倍,否则会出现混叠现象。
混叠现象
指利用 离散傅里叶变换 (DFT)对信号Z域进行频域抽样时,取样点数小于时域列长所引起的时域周期延拓序列互相交叠的现象。
3.语谱图
分为窄带语谱图和宽带语谱图
窄带:接入速度慢,传输速率低
宽带:传输模拟信号,将信道分成多个子信道,分别传送音频、视频和数字信号,称为宽带传输。
带宽:电磁波频带的宽度,也就是信号的最高频率与最低频率的差值
时宽:脉冲宽度,是信号的结束时间减去信号的开始时间
时窗:时间间隔(time interval)
窄带语谱图
- 带宽小,时宽大,短时窗长度长。窄带语谱图即为长窗条件下画出的语谱图。
- 表现为“横线”,“横”体现了频率分辨率高。
宽带语谱图
- 带宽大,时宽窄,短时窗长度短。
- 表现为“竖线”,可以区分语音在时间上重复的部分,“竖”体现了时间分辨率高。
4.基频(基音频率)
- 声带每次张开闭合的频率,声带振动周期就是基音周期。
- 在窄带语谱图上,是所有横条纹中频率范围最低的那条,与其在同一水平线上的条纹都表示该时刻的基音频率成分。此条纹对应的纵轴刻度值就是基音频率数值。
- 其他横条纹是各次谐波
- 在宽带语谱图上,两竖线之间的时间表示基音周期
5.共振峰
- 谐波中有些地方比同时刻其附近其他横条纹颜色要深,这些颜色深的表示共振峰
二、语音信号处理
目标:找出各个频率成分的分布
傅里叶变换(FFT)操作 && 小波变换 && 全卷积时域音频分离网络——Conv-TasNet
语音信号处理操作
1.傅里叶级数
猜测任意周期函数可以写成三角函数之和。
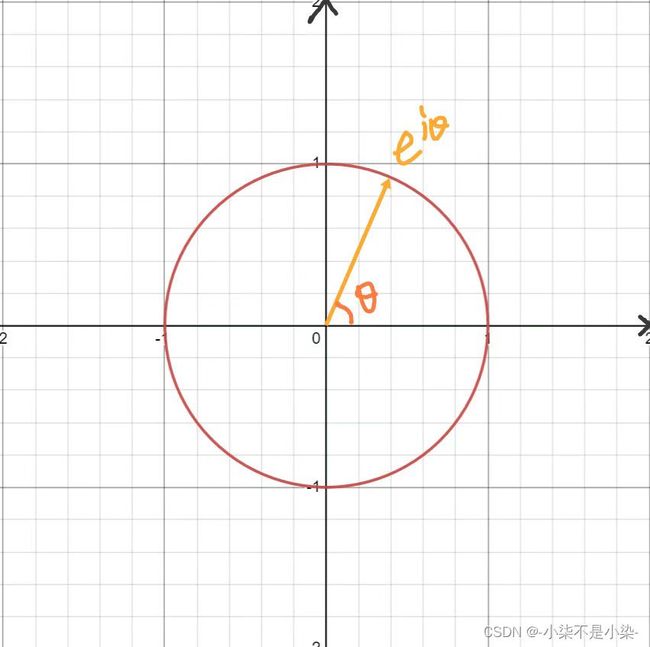
欧拉公式
定义:对于θ∈R,有![]()
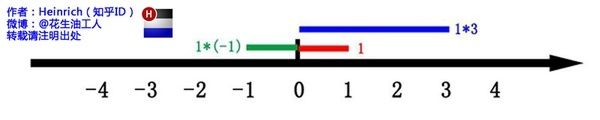
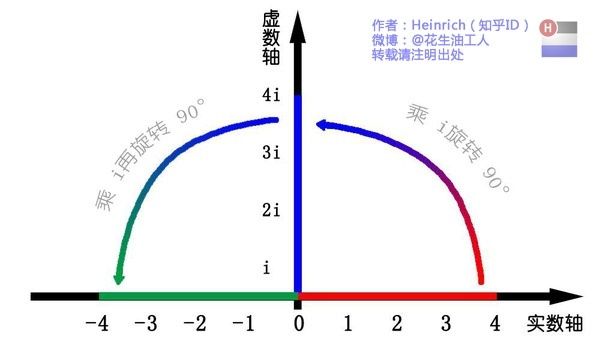
虚数 i:i*i=-1
数轴上 1*(-1) [即1*i*i],线段在数轴上绕原点旋转了180°
当1*i时,线段在平面上旋转90°,即得到虚数轴(复平面)。
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
 是复平面上的一个夹角为
是复平面上的一个夹角为 的向量
的向量
在时间轴t上,记录![]() 向量虚部(纵坐标)的值,即为
向量虚部(纵坐标)的值,即为![]()
在时间轴t上,记录![]() 向量实部(横坐标)的值,即为
向量实部(横坐标)的值,即为![]()
![]()
两种角度,一个可以观察到旋转的频率,所以称为频域;一个可以看到流逝的时间,所以称为时域。
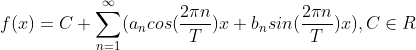
 的基(最基本单元)为:
的基(最基本单元)为: ![]()
经过点积得到:
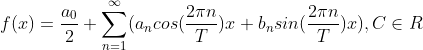
![]()
![]()
频谱时谱
- 任何波形都可以通过无数个正弦波叠加形成,这些不同频率的正弦波称为频率分量
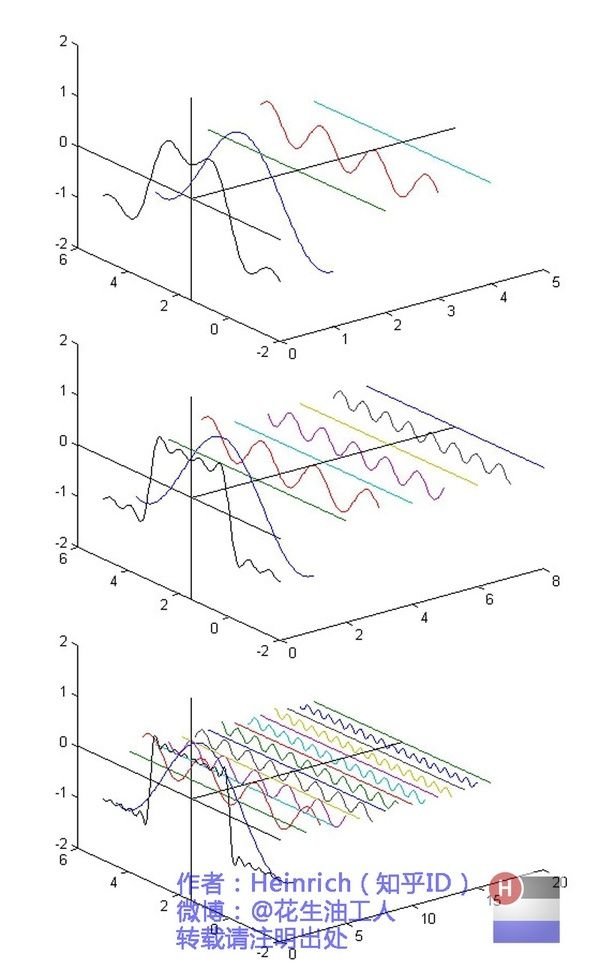
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
- 其中第一个频率最低的频率分量为构建频域的基(最基本单元)[类比于有理数轴的基本单元“1”],周期无限长的正弦波
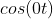 ,即一条直线 [即为有理数轴的“0”]
,即一条直线 [即为有理数轴的“0”] - 正弦波是一个圆周运动在一条直线上的投影。
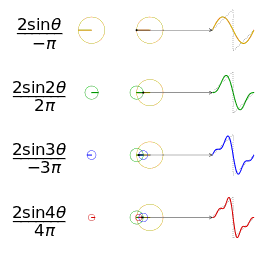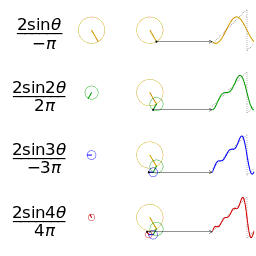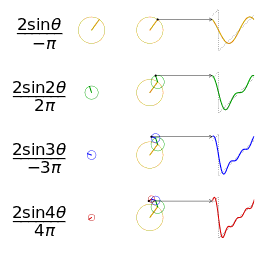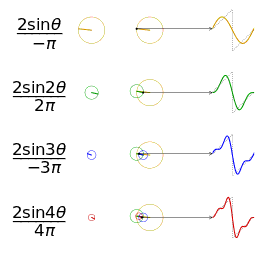
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
- 在频域中,0频率被称为直流分量。在傅里叶级数的叠加中,只影响全部波形相对于数轴整体向上还是向下,不改变波的形状
- 延时间方向的图叫时域图像[时谱](正弦波叠加最终形成的图案)
- 延频率方向的图叫频域图像[频谱/振幅谱](所有叠加正弦波的振幅的竖线组成的)
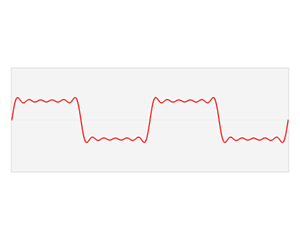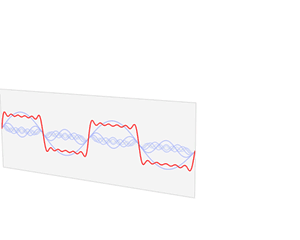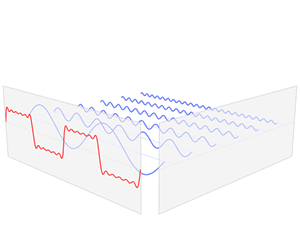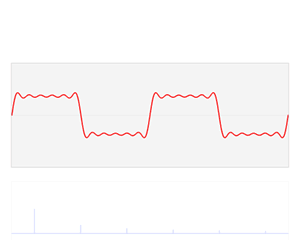
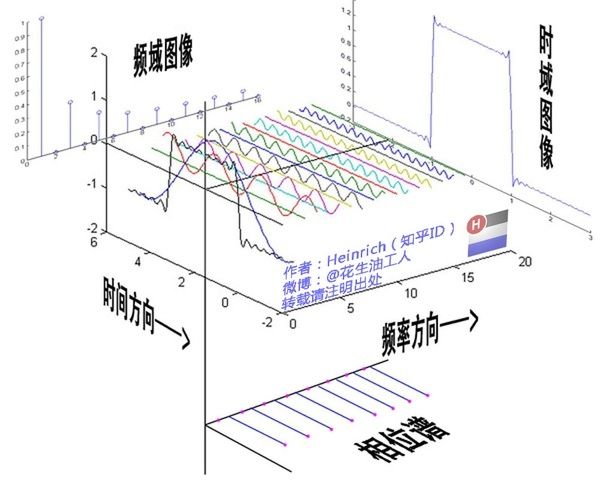
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
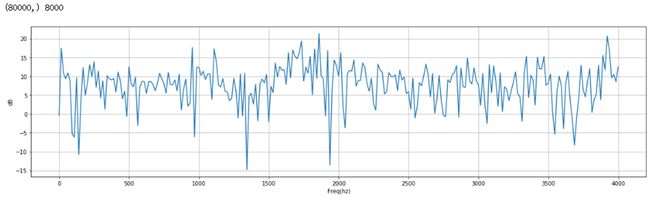
#导包 import numpy as np from scipy.io import wavfile from scipy.fftpack import dct import matplotlib.pyplot as plt #绘制时域图 def plot_time(sig, fs): time = np.arange(0,len(sig))*(1.0/fs) plt.figure(figsize = (20, 5)) plt.plot(time, sig) plt.xlabel('Time(s)') plt.ylabel('Amplitude')#振幅 plt.grid() #绘制频域图 def plot_freq(sig, sample_rate, n_fft=512): freqs = np.linspace(0, sample_rate/2, n_fft//2 + 1) xf = np.fft.rfft(sig, n_fft) / n_fft xfp = 20*np.log10(np.clip(np.abs(xf), le-20, le100))#强度 plt.figure(figsize = (20, 5)) plt.plot(freqs, xfp) plt.xlabel('Freq(hz)') plt.ylabel('dB')#强度 plt.grid() #绘制二维数组 def plot_spectrogram(spec,ylabel = 'ylabel'): fig = plt.figure(figsize = (20, 5)) heatmap = plt.pcolor(spec) fig.colorbar(mappable = heatmap) plt.xlabel('Time(s)') plt.ylabel(ylabel) plt.tight_layout() plt.show() wav_file = '文件名.wav' fs, sig = wavfile.read(wav_file) #fs是wav文件的采样率,signal是wav文件的内容,filename是要读取的音频文件的路径 sig = sig[0: int(10 *fs)] #保留前10s的数据 plot_time(sig, fs) #时域图 plot_freq(sig, fs) #频域图
时域图 源 博客园 yifanhunter
频域图 源 博客园 yifanhunter
预加重
定义:对语音的高频部分进行加重
目的:
- 平衡频谱,高频通常与低频相比具有较小的幅度,提高高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的噪声比(SNR)求频谱
- 突出高频的共振峰
将语音信号通过一个高通滤波器:
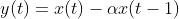
(其中滤波器系数
值通常为0.95或0.97
# 代码形式 pre_emphasis = 0.97 emphasized_signal = numpy.append(signal[0], signal[1:] - pre_emphasis * signal[:-1]) # emphasized_signal为新signal效果
时域图 源 博客园 yifanhunter
频域图 源 博客园 yifanhunter
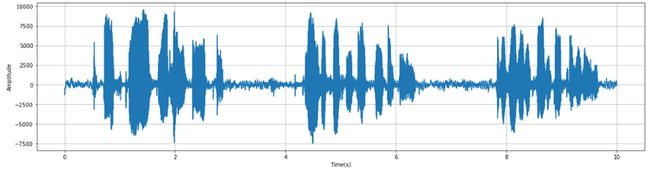
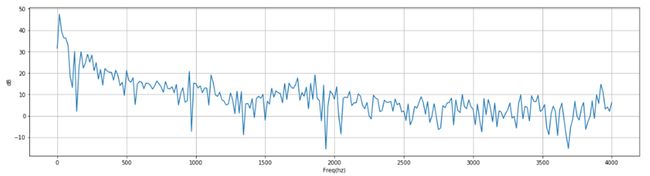
滤波
从某条曲线中去除一些特定的频率成分
2.傅里叶变换(Fourier Tranformation)
基本思想:非周期性的信号可以由多个周期性的信号叠加而逼近得到。将无限长的三角函数作为基函数
傅里叶变换:将一个时域非周期的连续信号转换成一个在频域非周期的连续信号(将频域的点连接起来的图像)得到频谱和时谱

图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
离散谱频域:
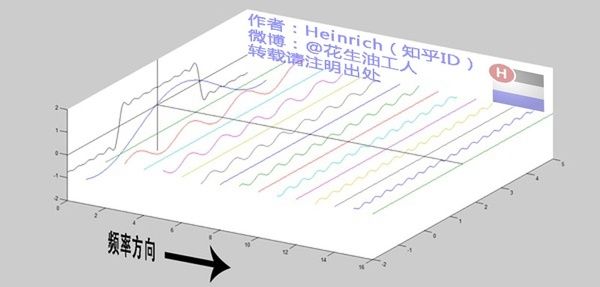
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
连续谱频域:
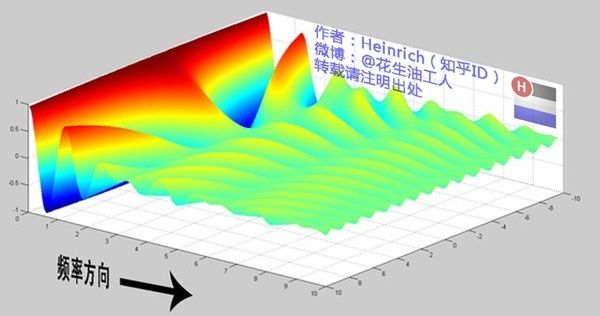
图源:博客园 - 韩昊 - 深入浅出的讲解傅里叶变换
分帧
解释:将语音信号截取成小段,即为分帧,每一段信号就叫做一「帧」
- 即将整个时域过程分解为无数个等长的小过程,每个小过程近似平稳(短时间内的信号可以看作是平稳的,可以截取出来做FFT

图源:知乎 王赟 Maigo

图源:知乎 王赟 Maigo
帧移:STRIDE,0~1/2帧长,帧与帧之间的平滑长度
def framing(frame_len_s, frame_shift_s, fs, sig):
"""
分帧,主要是计算对应下标
param frame_len_s: 帧长,s
param frame_shift_s: 帧移,s
param fs: 采样率,hz
param sig: 信号
return: 二维list,一个元素为一帧信号
"""
sig_n = len(sig)
frame_len_n, frame_shift_n = int(round(fs * frame_len_s)), int(round(fs * frame_shift_s))
num_frame = int(np.ceil(float(sig_n - frame_len_n) / frame_shift_n) + 1)
pad_num = frame_shift_n * (num_frame - 1) + frame_len_n - sig_n # 待补0的个数
pad_zero = np.zeros(int(pad_num)) # 补0
pad_sig = np.append(sig, pad_zero)
# 计算下标
# 每个帧的内部下标
frame_inner_index = np.arange(0, frame_len_n)
# 分帧后的信号每个帧的起始下标
frame_index = np.arange(0, num_frame) * frame_shift_n
# 复制每个帧的内部下标,信号有多少帧,就复制多少个,在行方向上进行复制
frame_inner_index_extend = np.tile(frame_inner_index, (num_frame, 1))
# 各帧起始下标扩展维度,便于后续相加
frame_index_extend = np.expand_dims(frame_index, 1)
# 分帧后各帧的下标,二维数组,一个元素为一帧的下标
each_frame_index = frame_inner_index_extend + frame_index_extend
each_frame_index = each_frame_index.astype(np.int, copy=False)
frame_sig = pad_sig[each_frame_index]
return frame_sig
frame_len_s = 0.025
frame_shift_s = 0.01
frame_sig = framing(frame_len_s, frame_shift_s, fs, sig)
短时傅里叶变换 (STFT)
在分帧后,要进行加窗 操作,即与一个「窗函数」相乘
- 加窗的目的:让一帧信号幅度在两端渐变到0(即为下图图3的样子, 可以让频谱上的峰更细,减轻频谱泄漏
- 加窗后一帧信号的两端部分就被削弱了
- 通过帧之间相互重叠的方式弥补,相邻两帧起始位置的时间差叫帧移(常见取法:取帧长的一半,或固定为取10毫秒

图源:知乎 王赟 Maigo
确定窗函数的宽度:
- 窗太窄,窗内的信号太短,会导致频率分析不够精准,频率分辨率差,但时间分辨率高
- 窗太宽,时域上又不够精细,时间分辨率低,但频率分辨率高
对于时变的非稳态信号,高频适合小窗口,低频适合大窗口
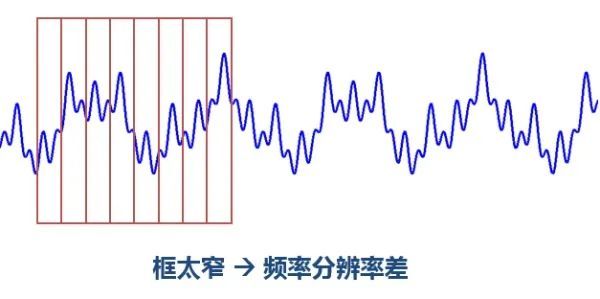
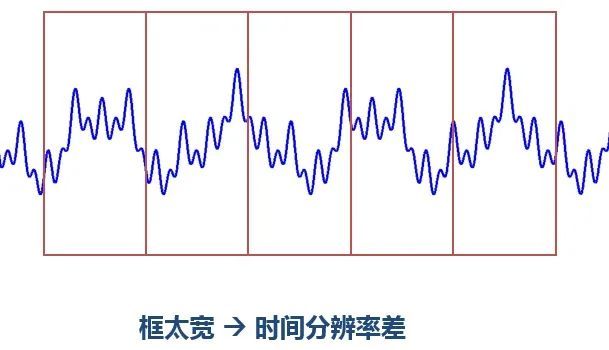
图源:极市平台
对每一帧的信号做FFT,得到频谱
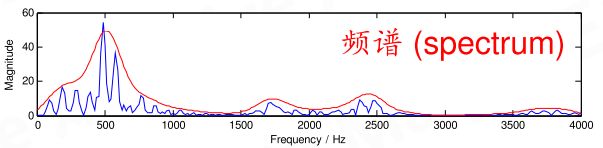
图源:知乎 王赟 Maigo
- 其中横轴是频率,纵轴是幅度
- 「精细结构」:是蓝线上的一个个小峰,在横轴上的间距就是基频,体现了语音的音高
- 峰越稀疏,基频越高,音高越高
- 「包络」:是连接这些小峰峰顶的平滑曲线(红线),代表发的是哪个音。其上的峰叫共振峰(可以根据共振峰的位置看出发的什么音
算法
- 对于一个表示为1行,T列的的信号(1,T),通常会设定一组线性增加的频率,然后假定信号由这些频率的三家函数信号叠加而成。
- FFT计算,是将傅里叶级数变换到复数域,经过计算再变成时域。得到的结果就是每个假定的三角函数信号的一个复数表示,即为a+bj。用librosa库和torchaudio库中代码计算,得到由ai+bi j组成的矩阵。ai bi即为每个信号的矢量表示。
- 在复数域的几何表示为:
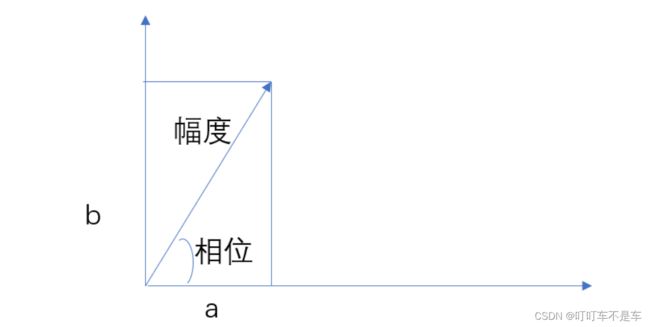
- 得到两个矩阵,幅度谱(语谱图) 和 相位谱 ,
- 傅里叶变换得到的谱,被称为“线性谱”。
n_fft即为多少个信号点做傅里叶变换
公式:
- 某帧做STFT,得到频率组的数量 = n_fft // 2 + 1 (//表示整除
- 计算一段信号STFT能得到的帧数:已知分帧的窗长winlength,帧移长度hoplength,信号采样点个数L
- 时间帧数N = L // hoplength + 1(与窗长无关
eg:假设某信号采样率为16000,取一秒钟,也即采样点数量为16000的信号,做窗长512(512/16000*1000=32毫秒)点,帧移256(16毫秒)的STFT变换,即可得到
16000 // 256 + 1= 63帧。
import torchaudio signal = torch.rand(16000) stft = torch.stft(signal.return_complex=True,n_fft=512,hop_length=256,win_length=512) print(stft,shape)
3.小波变换
时频分析:各个成分出现的时间、信号频率随时间变化的情况、各个时刻的瞬时频率及其幅值
傅里叶变换缺陷:只能获取一段信号总体上包括哪些频率部分,但无法获知各成分出现的时刻。➡️➡️“对于非平稳的过程,傅里叶变换有局限性” “两个时域有巨大差异的信号的频域可能高度一致”
小波变换思路:将FFT中的无限长三角函数换成了有限长的会衰减的小波基
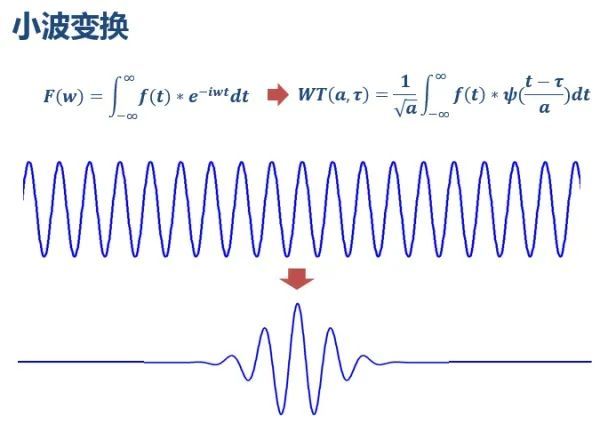
图源:极市平台
两个变量:
- 尺度
 :控制小波函数的伸缩,对应于频率(纵轴
:控制小波函数的伸缩,对应于频率(纵轴 - 平移量
 :控制小波函数的平移,对应于时间(横轴
:控制小波函数的平移,对应于时间(横轴
得到时频谱
对于突变信号:FFT存在吉布斯效应
傅里叶变换:
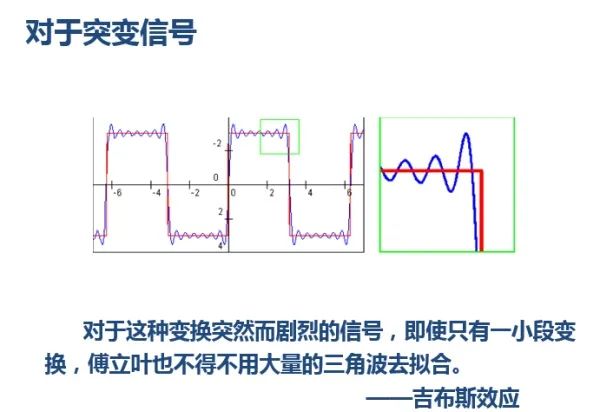
图源:极市平台
对小波变换:
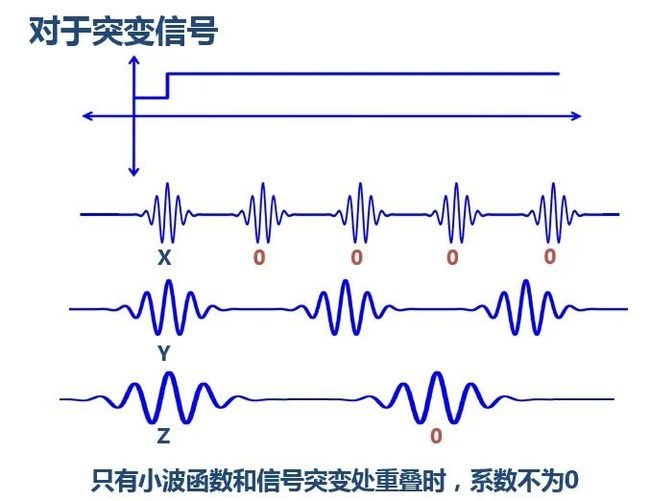
图源:极市平台
4.声谱图、梅尔频谱
声谱图
对一段长语音信号,分帧、加窗、在对每一帧做傅里叶变换,之后把每一帧的结果沿着另一维度堆叠,得到的图就是声谱图

图源:CSDN lvziye00lvziye文章
梅尔频谱
将声谱图通过梅尔尺度滤波器(Mel 滤波),变为梅尔频谱,得到合适大小的声音特征
- 频率的单位是HZ,将HZ转化成梅尔频率,则人耳对频率的感知度变为线性。
- 公式:
![]()

图源:CSDN lvziye00lvziye文章
5.Fbank和MFCC
Fbank(FilterBank)
一种前端处理算法,以类似于人耳的方式对音频进行处理,以提高语音识别的性能。
MFCC
对Fbank做离散余弦变换(DCT)即可获得MFCC特征。
MFCC:梅尔频率倒谱系数。实际就是在梅尔频谱上做倒谱分析(取对数,做DCT变换)
参考文章:
本文不做任何商用,仅为自我学习摘录。如有某部分侵犯了大家的利益,还望海涵,并联系删除,谢谢大家!!!
https://www.zhihu.com/question/24490634 --采样定理
https://blog.csdn.net/lzrtutu/article/details/78882715 --语谱图、基频、共振峰
https://www.zhihu.com/question/19714540/answer/334686351 --马同学(如何理解FT公式
https://mp.weixin.qq.com/s/CRqhHIlYYRjYJ64PZZnUkQ --极市平台 傅里叶变换 小波变换
https://www.cnblogs.com/h2zZhou/p/8405717.html --韩昊 博客园 深入浅出的讲解傅里叶变换
https://www.zhihu.com/question/52093104 --by 知乎 王赟 Maigo 怎样理解分帧
https://blog.csdn.net/lvziye00lvziye/article/details/100132715 --声谱图,梅尔谱图
https://www.cnblogs.com/yifanrensheng/p/13510742.html --Fbank和MFCC介绍-忆凡人生-博客园