推荐系统总结MF->PMF->CTR->CDL->CNN
推荐系统总结
- 推荐系统总结
- 数据集分析
- 矩阵分解MF
- 基于概率的矩阵分解PMF
- 小结
- 扩展篇
- 标签推荐
首先进行数据集的分析,然后 介绍矩阵分解方法(MF)、基于概率的矩阵分解(PMF);
在此基础上介绍扩展方法:社交网络、隐语义模型、深度学习(CDL、CNN等);
最后介绍标签推荐方法。
1.数据集分析
以movieLens为例,介绍一下现有数据集所包含信息:
- 评分信息
userID,itemID,rating*(这里的评分分为:1~5;或者{0,1}喜欢与否)* - item信息
itemID,text(文本描述,标题,题材) - 标签信息
userID,itemID,tags
(标签信息可以进一步按照用户采集或者按照项目单独采集)
其他数据集:lastfm,豆瓣生态等
包含user-user之前的联系;
2.矩阵分解(MF)
用户评分矩阵RR分解成两个矩阵,R′=UTVR′=UTV,R′R′的维度为N∗MN∗M
U={u1,u2,...,uk−1,uk}U={u1,u2,...,uk−1,uk},UU维度是k∗Nk∗N,用户特征矩阵
V={v1,v2,...,vk−1,vk}V={v1,v2,...,vk−1,vk},VV维度是k∗Mk∗M,项目特征矩阵
如图所示,矩阵分解是共享了一个向量空间,其中uiui潜在向量如图, 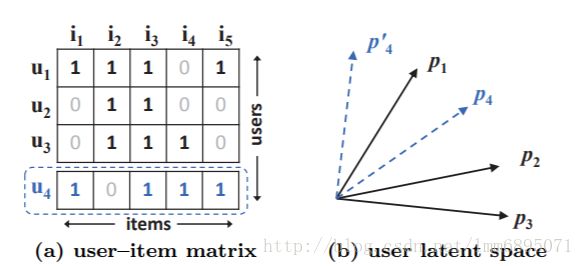
计算平方损失:(只计算有评分的元素,II指示是否有评分,Ii,j∈{0,1}Ii,j∈{0,1})
然后利用凸优化方法,偏导为零,然后迭代即可;
注:因为上式的优化是针对于有评分数据进行的,容易过拟合,加上正则项(二范数):
扩展:不同用户对评分有不同的偏执;则
再扩展:加入置信度,时间序列等等;
参考论文:matrix factorizatiom technigues for recommender systems
3.基于概率的矩阵分解(PMF)
假设参数服从正态分布:
U∼N(0,σ2u)U∼N(0,σu2) , V∼N(0,σ2v)V∼N(0,σv2) , R−UTV∼N(0,σ2)R−UTV∼N(0,σ2)
并假设用户之间、项目之间独立:
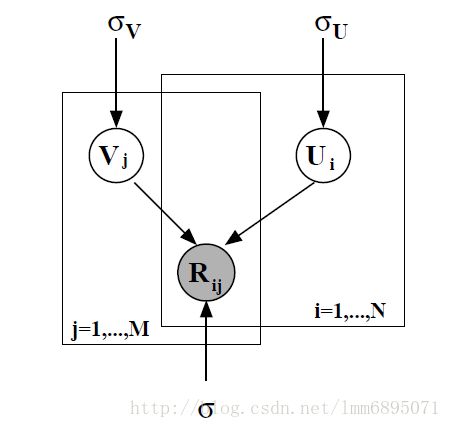
最大后验概率: 后验概率∝似然∗先验后验概率∝似然∗先验
对数变换之后:
令 λU=σ2/σ2uλU=σ2/σu2 , λV=σ2/σ2vλV=σ2/σv2 ,
即 U∼N(0,λ−1UIK)U∼N(0,λU−1IK) , V∼N(0,λ−1VIK)V∼N(0,λV−1IK) , R∼N(UTV,C−1I)R∼N(UTV,C−1I)
化简上式为:
观察:PMF最大后验概率的对数化结果与MF的最小化平方损失一致
最后按照随机梯度等方式进行优化获得 u,vu,v 的迭代公式。
参考文献:Probabilistic Matrix Factorization
小结
矩阵分解方法是寻找用户、项目的矩阵,发现其潜在的特征,共享特征空间。
这种方法只是利用了评分矩阵矩阵信息,而且存在物品冷启动问题,通过引入物品文本特征,社交网络等信息,修正用户或项目向量,以期缓解冷启动问题。
4.扩展篇
这一节主要介绍在经典的矩阵分解模型上,融合更多信息来解决矩阵稀疏性问题。
社交的关联矩阵、物品的描述信息等;
方法是矩阵模型的正则扩展,或者深度学习;
4.1 隐语义模型(CTR=PMF+LDA)
引入:矩阵分解方法中存在数据稀疏问题,进而导致冷启动问题
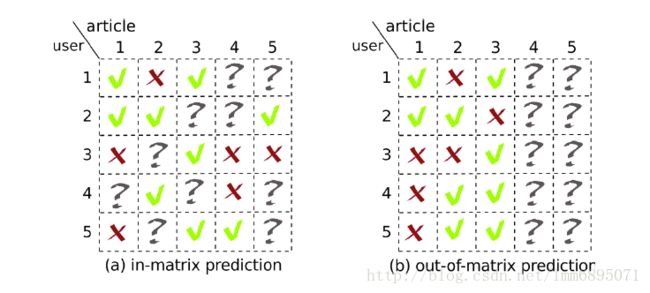
从图(b)中,可以看出I4,I5I4,I5没有用户记录偏好信息,所以矩阵分解之后会有很大的偏差;为此引入Item 信息,Item使用LDA(topic model)方法,然后进行融合。
LDA模型:
- 从狄雷克类分布中获得主题分布θj∼Dirichlet(α)θj∼Dirichlet(α)
- 对于文档djdj中的每一个词语wj,nwj,n:
(a)从主题多项式分布中获得一个主题zj,n∼Mult(θj)zj,n∼Mult(θj);
(b)从词语-主题分布中获得一个词语wj,n∼Mult(βzj,n)wj,n∼Mult(βzj,n)
P(W|d)=∏i=1N∑znP(wn|zn)P(zn|d)P(W|d)=∏i=1N∑znP(wn|zn)P(zn|d)
P(W,θ)=P(θ)∏n=1N∑znP(zn|θ)∗P(wn|zn,β)=P(θ)∏n=1N∑kθj,k∗βk,wj,nP(W,θ)=P(θ)∏n=1N∑znP(zn|θ)∗P(wn|zn,β)=P(θ)∏n=1N∑kθj,k∗βk,wj,n
现在假定:ϵj∼N(0,λ−1VIK),则ϵj∼N(0,λV−1IK),则
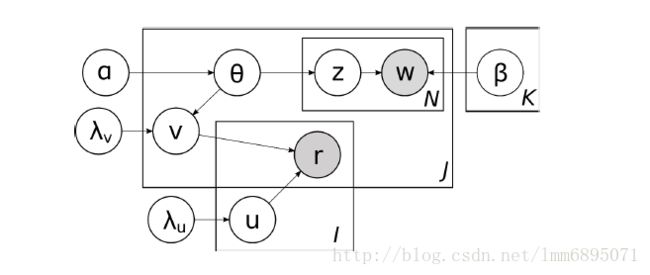
根据CTR的概率模型图可知:
最大后验概率的对数形式:
有了优化公式,按照坐标上升法进行优化;
首先假设θθ固定,计算U,VU,V;
然后固定U,VU,V,优化θθ.
预测:对于问题提出的图(b),使用θjθj代替vjvj.
结果分析: 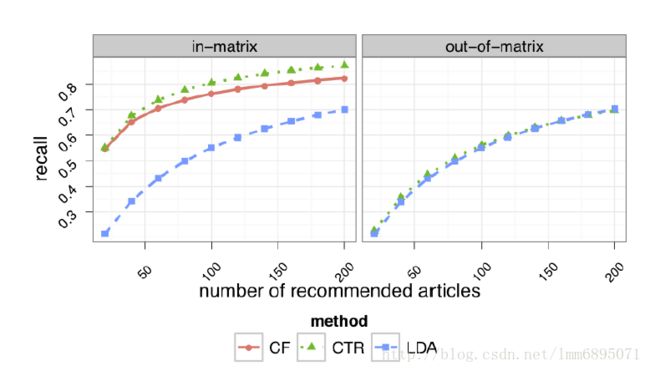
基于用户的召回率: 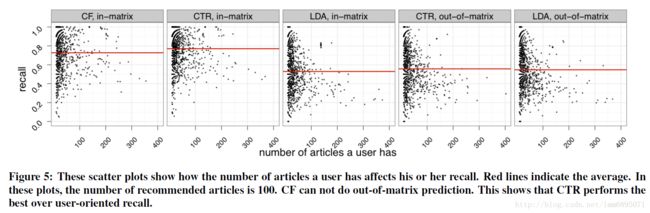
基于Item的召回率: 
参考论文:Collaborative Topic Modeling for Recommending Scientific Articles KDD 2011
4.2 社交网络
CTR-SR 引入社交网络信息,介绍两种融合方式。
两个矩阵分解(2012 ICML)
Item信息直接使用CTR模型;
引入Q矩阵,代表user-user之间是否有联系;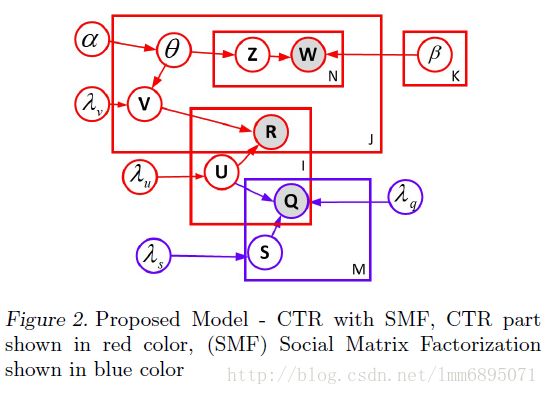 P(U,V,S|R,Q,λU,λV,λS,λQ,C)∝P(R|U,V,C)P(Q|U,S,λQ)P(U|λU)P(V|θ,λV)P(S|λS)P(θ|α,β)P(U,V,S|R,Q,λU,λV,λS,λQ,C)∝P(R|U,V,C)P(Q|U,S,λQ)P(U|λU)P(V|θ,λV)P(S|λS)P(θ|α,β)
P(U,V,S|R,Q,λU,λV,λS,λQ,C)∝P(R|U,V,C)P(Q|U,S,λQ)P(U|λU)P(V|θ,λV)P(S|λS)P(θ|α,β)P(U,V,S|R,Q,λU,λV,λS,λQ,C)∝P(R|U,V,C)P(Q|U,S,λQ)P(U|λU)P(V|θ,λV)P(S|λS)P(θ|α,β)
其中 vj∼N(θj,λ−1VIK)vj∼N(θj,λV−1IK);
最大后验概率的对数形式:
ψ(U,V,S,θ)=−λU2∑i=1N||ui||22−λV2∑j=1M||vj−θj||22−∑i=1N∑j=1Mci,j2(ri,j−uTivj)2−λS2∑h=1H||sh||22−∑i=1N∑h=1Hdi,h2(qi,h−uTish)2+∑j=1M∑x=1Xln(∑kθj,kβk,wj,x)ψ(U,V,S,θ)=−λU2∑i=1N||ui||22−λV2∑j=1M||vj−θj||22−∑i=1N∑j=1Mci,j2(ri,j−uiTvj)2−λS2∑h=1H||sh||22−∑i=1N∑h=1Hdi,h2(qi,h−uiTsh)2+∑j=1M∑x=1Xln(∑kθj,kβk,wj,x)
优化过程:首先固定θθ,然后计算U,V,SU,V,S的偏导为0的值;
然后固定U,V,SU,V,S,按照CTR模型方式优化θθ.
召回率作为评价指标:分别与PMF、CTR模型进行比对。显示模型的优越性;参考论文:
Collaborative Topic Regression with Social Matrix Factorization for Recommendation SystemsV 由S、θθ两个高斯分布共同决定(2013 IJCAI)
标签推荐的挑战:如何高效得融入item-tag,Item内容信息,社交网络信息;
本文使用Item-tags矩阵,A是社交网络的邻接矩阵(连个Item之间的联系);S是潜在的社交矩阵,V是由双高斯分布POG模型(2006);
vj∼POG(θj,sj,λ−1vIK,λ−1rIK)vj∼POG(θj,sj,λv−1IK,λr−1IK)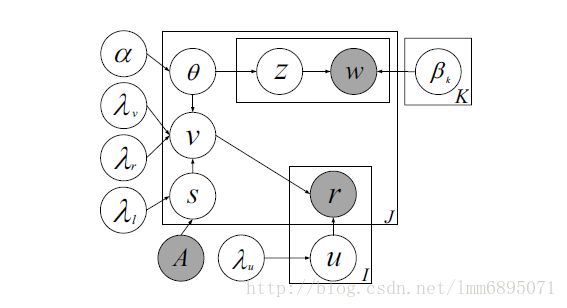
因此最大后验概率是:maxV,U,S,θP(U,V,S|R,A,λv,λu,λl,λr,C)∝P(R|U,V,C)P(U|λu)P(V|θ,S,λv,λr)P(S|λl,A)P(θ|α,β)maxV,U,S,θP(U,V,S|R,A,λv,λu,λl,λr,C)∝P(R|U,V,C)P(U|λu)P(V|θ,S,λv,λr)P(S|λl,A)P(θ|α,β)
在此基础上,利用item-tags(类似与评分矩阵ri,j∈0,1ri,j∈0,1),item信息,item-item邻接矩阵; 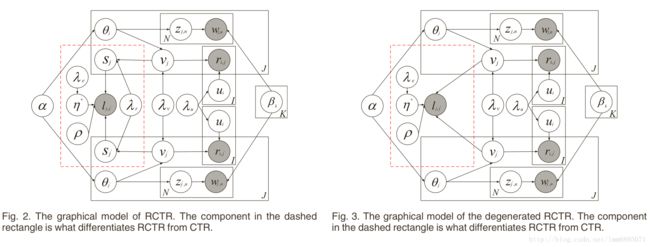
其中,
这样子的话,凸函数部分,先利用朗格朗日方法,偏导数为0,即可更新 ui,vjui,vj ;然后利用CTR方法更新 θjθj ,最后 sj,η+sj,η+ 利用梯度下降法计算;
参考论文:
Collaborative Topic Regression with Social Matrix Factorization for Recommendation Systems 2013
Relational Collaborative Topic Regression for Recommender Systems 2015
4.3 深度学习之CDL
回顾一下:CTR模型将Item信息很好融合到vjvj中,缓解矩阵稀疏带来的冷启动问题;CTR模型依赖与LDA,在此基础上人们开展了各种拓展和应用。随着深度网络的兴起,我们可以很轻松的将文本信息、图片信息、用户离散信息等多模态特征萃取出来;因此推荐系统也迎来一个又一个春天。
优秀的模型有CDL,ConvMF,deepConNN,UWCVM等;
CDL模型(2015 KDD)
(SDAE+PMF)
利用SDAE网络学习出vjvj的词向量;vj=ϵj+XL2,j∗,ϵj∼N(0,λ−1vIK)ui∼N(0,λ−1uIK)ri,j∼N(uTivj,c−1i,j)vj=ϵj+XL2,j∗,ϵj∼N(0,λv−1IK)ui∼N(0,λu−1IK)ri,j∼N(uiTvj,ci,j−1)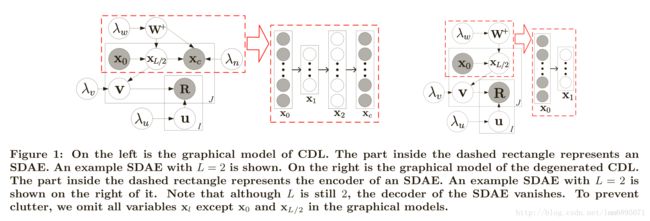
P(U,V|R,λu,λv,C)∝P(R|U,V,C)P(U|λu)P(V|XL2,j∗,λv)P(XL,j∗|wl,bl,λs,λn)P(w|λw)P(b|λw)P(U,V|R,λu,λv,C)∝P(R|U,V,C)P(U|λu)P(V|XL2,j∗,λv)P(XL,j∗|wl,bl,λs,λn)P(w|λw)P(b|λw)ui,vjui,vj,按照偏导为零计算得出;
wl,blwl,bl计算梯度方向,按照梯度下降方法更新;参考文献:
Collaborative Deep Learning for Recommender Systems (KDD 2015)CDL模型优化(2017 ICLR)
ConvMF模型(2016 RecSys)
(CNN+PMF)
利用CNN网络学习出vjvj向量;vj=cnn(W,Xj)+ϵj,ϵ∼N(0,λ−1V)))vj=cnn(W,Xj)+ϵj,ϵ∼N(0,λV−1)))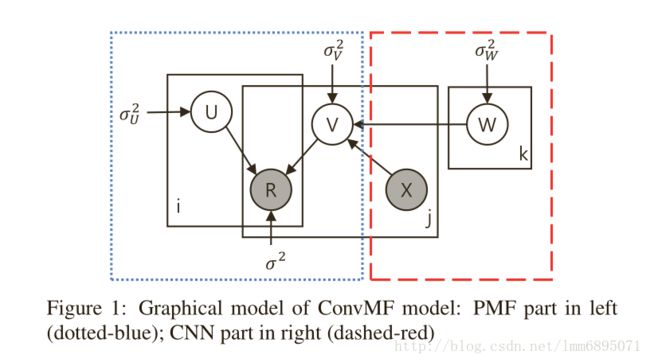
参考文献:
Convolutional Matrix Factorization for Document Context-Aware Recommendation(2016 RecSys)
Convolutional Neural Networks for Sentence Classification(CNN 2014)DeepCoNN模型(2017 WSDM)
(CNN+FM)
将用户评论信息分成两部分:user-review,item-review,构造两个平行的CNN网络,但是两个向量不是同一向量空间,因此利用FM技术,计算交叉特征,并构造目标函数;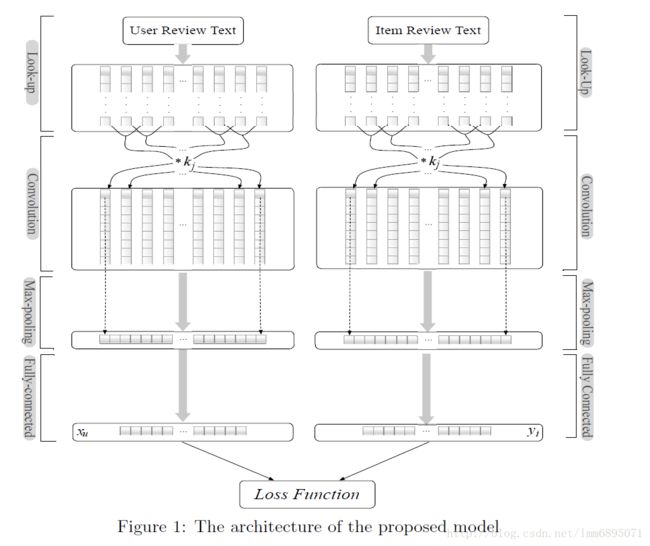 J=w0+∑i=1zwizi+∑i=1z∑j=i+1zwi,jzizjJ=w0+∑i=1zwizi+∑i=1z∑j=i+1zwi,jzizj交叉项系数分解成矩阵相乘的形式,因为在数据稀疏情况下,参数无法学习到;另外交叉项ab+bc+ac=12[(a+b+c)2−a2−b2−c2]ab+bc+ac=12[(a+b+c)2−a2−b2−c2];
J=w0+∑i=1zwizi+∑i=1z∑j=i+1zwi,jzizjJ=w0+∑i=1zwizi+∑i=1z∑j=i+1zwi,jzizj交叉项系数分解成矩阵相乘的形式,因为在数据稀疏情况下,参数无法学习到;另外交叉项ab+bc+ac=12[(a+b+c)2−a2−b2−c2]ab+bc+ac=12[(a+b+c)2−a2−b2−c2];
所以wi,j=<vi,vj>=∑f=1zvi,fvj,fwi,j=
J=w0+∑i=1zwizi+∑i=1z∑j=i+1zw