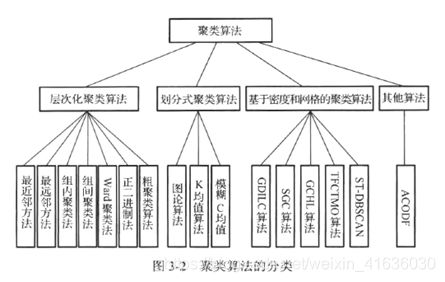
用户画像相关方法
用户画像方法:关联规则,聚类
用户定性画像:用户维度+产品维度
用户维度:用户特征,用户行为,用户兴趣偏好
产品维度:用户下单的产品类别,下单次数,下单的平台
用户画像相似度
定量相似度计算

W(k)表示第k个标签的权重
用户画像中不同标签需要进行归一化处理;具体某个标签相似度计算方法有:欧式距离,余弦相似度,jaccard系数等;对于标量标签,通常采用欧式距离,曼哈顿距离和余弦相似度等。
定性相似度计算
- 一个方向是将定性标签映射为定量标签
- 另一个方向是直接采用基于概念的相似度计算方法
在k-means中,聚类中心节点反映了其所在聚类的总体特征,因此,我们将最后一次迭代中聚类的中心节点数据作为该聚类的群体用户画像。
用户画像的管理
用户画像的表现形式
- 关键词法
- 评分矩阵法
- 向量空间法
- 本体表示法
用户画像数据主要采用列式存储和key-value数据库
- Key-value数据库:基于哈希计算,其数据按键值对形式进行组织,索引和存储;典型的key-value数据库有redis,apache accumulo,berkley DB
- 列式数据库:这类数据库主要用来应对分布式存储的海量数据;其典型的列存储数据库有sybase IQ, apache的HBase和google开发的bigtable
用户画像库是随着时间变化的
一个简单的用户画像库有数百个特征标签,其中一些特征标签是固定不变的,如用户信息等;有些是随着时间变化的,如按周期统计的用户行为指标。
用户画像更新机制:
- 如何获取实时变化的用户画像数据
- 如何设置合适的用户画像更新触发条件
- 高效的更新算法
用户画像更新触发条件
- 设置一个阈值,当获取的实时画像数据量超过这一阈值时,根据存储的画像数据构建用户画像
- 设置一个时间周期,每隔该周期时间根据存储的画像数据构建用户画像
- 从增加的数据中挖掘用户画像,然后将其与原先的用户画像进行比较,根据比较的结果决定是否更新。
注:第一种方式适合数据敏感型的用户画像;第二种方式适合时效性要求较高的用户画像;第三种方式适合相对稳定的用户画像
用户->由住址和消费品类关联其消费水平和消费偏好->由其最近的消费类别鉴别其基于物品的协同过滤
基于用户的协同过滤算法
基于内容的两大类推荐算法(item based):
基于信息检索的启发式算法:该算法可将信息检索的TF-IDF算法应用到推荐中
基于机器学习的自适应算法:该算法将机器学习中的模型和算法来建立用户画像
基于知识的推荐方法
基于知识的推荐方法首先是“问”的过程,通过交互,会话等方式直接了解到用户的需求,然后视频匹配即”找”的过程。
基于约束的推荐算法:侧重于使用用户形式化的条件进行搜索
基于实例的推荐算法:侧重于在已有实例上进行匹配和调试
混合推荐方法
将以上的推荐方法进行融合,充分利用用户画像,物品画像,群体数据和知识模型四类信息源,使融合后的算法既能吸取各自算法的长处,也能弥补各自算法的缺陷,从而获得更好的推荐效果。
整体式混合设计:特征组合和特征补充
并行式混合设计:加权式,交叉式,切换式
流水线式混合设计:瀑布式,级联式

推荐系统评测方法
评测过程:推荐系统在投入运营前所经历的不同形式的评测经历
按成本由低到高分为:离线评测,用户调查和在线评测
评测指标从不同的角度衡量系统推荐质量的参考标准
常见评测指标:
- 单击率和转化率:在线评测的重要指标
- 用户满意度:评测推荐系统最重要的指标
- 预测准确度:最直观评价系统预测评分和用户真实评分差距的指标
- 覆盖率:推荐的广度,即所有物品是否都有被推荐的机会
- 多样性和新颖性:推荐系统离线评测的常用指标
- 适应性和扩展性
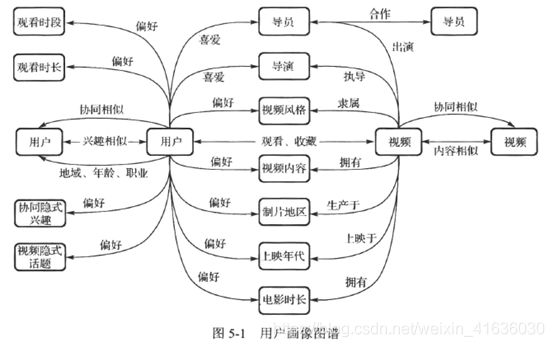
用户画像:真实用户在视频网站中的形象勾勒,为用户打上一系列标签,实现用户标签化;其基于用户基础信息,视频基础信息和用户浏览行为等数据,采用统计和机器学习等方法,从用户观看行为,视频和隐式话题等维度深入挖掘用户行为特性和偏好等。
用户画像分为整体画像和个性画像
整体画像从不同角度观察,发现和挖掘用户整体的观看行为特性和兴趣偏好等。
个性画像从用户个人角度来观察,发现和挖掘不同用户的观看行为特性。
协同过滤推荐方法

- User-based CF vs item-based CF
- 基于项目的协同过滤推荐 vs 基于内容的推荐
- Memory-based CF vs Model-based CF
基于记忆的协同过滤中,原始评分数据保存在内存中,直接生成推荐结果,缺点是资料稀疏,难以处理大数据量下的即时结果,故逐渐发展出以模型为基础的协同过滤技术。
基于模型的方法首先会离线处理原始数据,先用历史资料得到一个模型,再用此模型进行预测,运行时只需预计算或学习就能进行预测。
Ex:基于记忆的方法好比以用户ID或项目ID为输入,实时查询数据库并计算推荐结果返回,该方法可解释性强,但数据库一大,查询和计算都非常慢。
基于模型的方法好比事先对离线的数据训练出一个非常复杂的模型,通过接收符合模型输入参数才能得到预测的推荐结果,该方法可解释性不强,但在离线模型计算和训练方面,可支持大规模的数据。
关系矩阵及矩阵计算
推荐系统中,“关系”是用关系矩阵形式来创建和存储下来的;上述三种生态关系被表示为用户关系矩阵(U-U矩阵),视频关系矩阵(V-V矩阵)和用户-视频关系矩阵(U-V矩阵)。
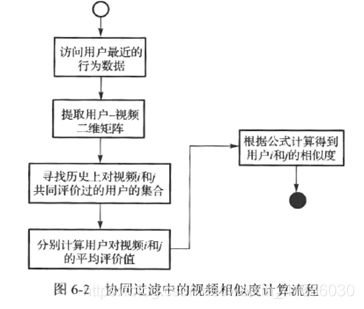
基于记忆的协同过滤算法主要依赖于对U-U矩阵和V-V矩阵的分析处理,通过相似度计算得到用户相似度或视频相似度,并以此形成推荐结果。
除相似度计算外,矩阵分解也可用来处理高维U-V矩阵,并进行关联分析;如基于模型的协同过滤算法依赖于对U-V矩阵的隐因子分析,核心计算就是矩阵分解。
U-V矩阵的两种主要分解方法:
- 奇异值分解
- 主成分分析
U-U矩阵

计算用户相似度方法有:pearson相关系数,余弦相似度,以及修正的余弦相似度,spearman秩相关系数和均方差等
Pearson相关系数在视频推荐系统中的计算公式:
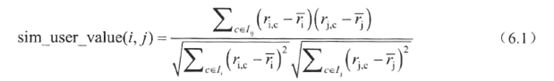
算法流程:
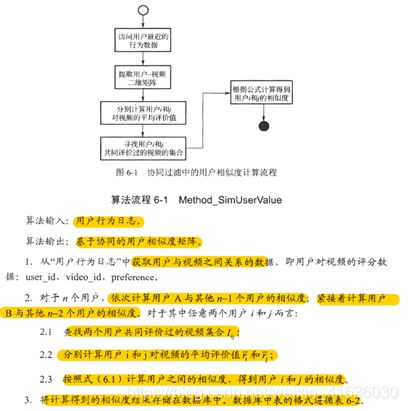
注:用户相似度好计算,但是难以得到用户对不同产品的评价值。
V-V矩阵

注:用户相似度通常用pearson相关系数去衡量;但在物品的相似度中,通常用余弦相似度去衡量,因为余弦相似度的精确度较好。
余弦相似度计算公式:
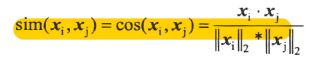
修正的余弦相似度可以避免不同用户评价标准不同从而导致的差异:
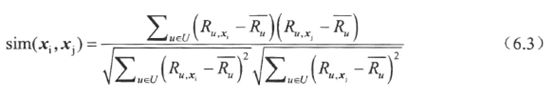
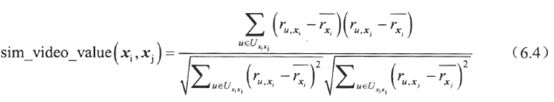

算法流程:

U-V矩阵
U-V矩阵表示用户与视频之间的关系,该关系是基于用户对视频的评分,也可基于用户观看视频的频度,还可以基于用户是否看过视频的行为(用0/1来表示未观看过/观看过)。
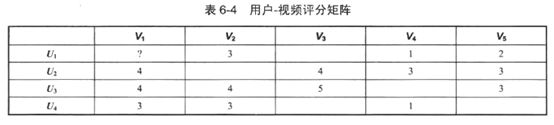
注:可通过用户频繁购买某种或者某类商品间接定义其对产品的喜好程度来决定用户对于产品的评分。
另外,还可以观察用户定期下单某种或某类商品,推测用户对于该商品的使用频率,在接近该时间段时推荐该类商品。
真实推荐系统中,一方面U-V矩阵行列数随着用户和视频数量变得庞大,另一方面,由于用户实际只能对有限数量的视频做出评价,故U-V矩阵内部会非常稀疏,从而导致系统处理这些高维U-V矩阵时,所消耗的时间,存储和计算资源都非常巨大,故需要一种能降低这种计算复杂度的方法。
解决思路:
矩阵分解:一种有效降低矩阵计算复杂度的方法,它实质是将高维矩阵进行有效降维。
解决方案:
- 奇异值分解(SVD)
一种正交矩阵分解法;基本原理是将给定的矩阵M分解为3个矩阵的乘积形式,即

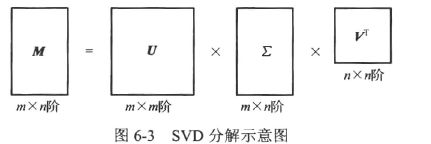

SVD的意义是将一个稀疏的评分矩阵分解为一个表示用户特性的矩阵U和一个表示物品特性的矩阵V,以及一个表示用户和物品相关性的矩阵E;在视频推荐系统中,可用矩阵U 表示用户与隐因子的关系特性,用矩阵V表示视频与隐因子的关系特性。
?这有点像隐因子模型
- 主成分分析(PCA)
PCA最重要的应用是对原有数据降维,简化数据,该方法可以有效找到数据中的主成分,去除噪音和冗余,将原有复杂数据降维简化进行分析,从而揭示隐藏在复杂数据背后的简单语义。

注:主成分分析可以用来分析用户和购买产品一级类别或者二级类别的分析上。
基于记忆的协同过滤算法
使用已知的评分矩阵去预测用户对未知项目的评分或者推荐;可分为:
基于用户的协同过滤算法
基于物品的协同过滤算法