机器学习,详解SVM软间隔与对偶问题
今天是机器学习专题的第34篇文章,我们继续来聊聊SVM模型。
我们在上一篇文章当中推导了SVM模型在硬间隔的原理以及公式,最后我们消去了所有的变量,只剩下了 α \alpha α。在硬间隔模型当中,样本是线性可分的,也就是说-1和1的类别可以找到一个平面将它完美分开。但是在实际当中,这样的情况几乎是不存在的。道理也很简单,完美是不存在的,总有些样本会出错。
那针对这样的问题我们应该怎么解决呢?
软间隔
在上文当中我们说了,在实际的场景当中,数据不可能是百分百线性可分的,即使真的能硬生生地找到这样的一个分隔平面区分开样本,那么也很有可能陷入过拟合当中,也是不值得追求的。
因此,我们需要对分类器的标准稍稍放松,允许部分样本出错。但是这就带来了一个问题,在硬间隔的场景当中,间隔就等于距离分隔平面最近的支持向量到分隔平面的距离。那么,在允许出错的情况下,这个间隔又该怎么算呢?
为了解决这个问题,我们需要对原本的公式进行变形,引入一个新的变量叫做松弛变量。松弛变量我们用希腊字母 ξ \xi ξ来表示,这个松弛变量允许我们适当放松 y i ( ω T x i + b ) ≥ 1 y_i(\omega^T x_i + b) \ge 1 yi(ωTxi+b)≥1这个限制条件,我们将它变成 y i ( ω T x i + b ) ≥ 1 − ξ i y_i(\omega^T x_i + b) \ge 1-\xi_i yi(ωTxi+b)≥1−ξi。
也就是说对于每一条样本我们都会有一个对应的松弛变量 ξ i \xi_i ξi,它一共有几种情况。
- ξ = 0 \xi=0 ξ=0,表示样本能够正确分类
- 0 < ξ < 1 0 < \xi < 1 0<ξ<1,表示样本在分割平面和支持向量之间
- ξ = 1 \xi = 1 ξ=1,表示样本在分割平面上
- ξ ≥ 1 \xi \ge 1 ξ≥1,表示样本异常
我们可以结合下面这张图来理解一下,会容易一些:

松弛变量虽然可以让我们表示那些被错误分类的样本,但是我们当然不希望它随意松弛,这样模型的效果就不能保证了。所以我们把它加入损失函数当中,希望在松弛得尽量少的前提下保证模型尽可能划分正确。这样我们可以重写模型的学习条件:
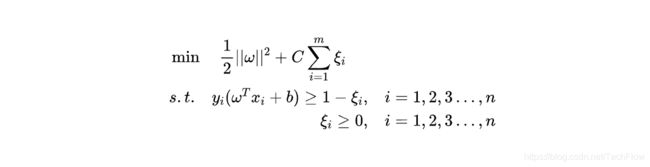
这里的C是一个常数,可以理解成惩罚参数。我们希望 ∣ ∣ ω ∣ ∣ 2 ||\omega||^2 ∣∣ω∣∣2尽量小,也希望 ∑ ξ i \sum \xi_i ∑ξi尽量小,这个参数C就是用来协调两者的。C越大代表我们对模型的分类要求越严格,越不希望出现错误分类的情况,C越小代表我们对松弛变量的要求越低。
从形式上来看模型的学习目标函数和之前的硬间隔差别并不大,只是多了一个变量而已。这也是我们希望的,在改动尽量小的前提下让模型支持分隔错误的情况。
模型推导
对于上面的式子我们同样使用拉格朗日公式进行化简,将它转化成没有约束的问题。
首先,我们确定几个值。第一个是我们要优化的目标: f ( x ) = min ω , b , ξ 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m ξ i f(x)=\min_{\omega, b, \xi}\frac{1}{2}||\omega||^2 + C\sum_{i=1}^m \xi_i f(x)=minω,b,ξ21∣∣ω∣∣2+C∑i=1mξi
第二个是不等式约束,拉格朗日乘子法当中限定不等式必须都是小于等于0的形式,所以我们要将原式中的式子做一个简单的转化:
g ( x ) = 1 − ξ i − y i ( ω T x i + b ) ≤ 0 h ( x ) = − ξ i ≤ 0 \begin{aligned} g(x) = 1 - \xi_i - y_i(\omega^Tx_i + b) \leq 0 \\ h(x) = -\xi_i \le 0 \end{aligned} g(x)=1−ξi−yi(ωTxi+b)≤0h(x)=−ξi≤0
最后是引入拉格朗日乘子: α = ( α 1 , α 2 , ⋯ , α m ) , β = ( β 1 , β 2 , ⋯ , β m ) \alpha = (\alpha_1, \alpha_2, \cdots, \alpha_m), \beta = (\beta_1, \beta_2, \cdots, \beta_m) α=(α1,α2,⋯,αm),β=(β1,β2,⋯,βm)
我们写出广义拉格朗日函数: L ( ω , b , ξ , α , β ) = 1 2 ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 m ξ i , + ∑ i = 1 m α i ( 1 − ξ i − y i ( ω T x i + b ) ) − ∑ i = 1 m β i ξ i L(\omega, b, \xi, \alpha, \beta) = \frac{1}{2}||\omega||^2 + C\sum_{i=1}^m \xi_i, + \sum_{i=1}^m \alpha_i(1 - \xi_i - y_i(\omega^Tx_i + b)) -\sum_{i=1}^m \beta_i\xi_i L(ω,b,ξ,α,β)=21∣∣ω∣∣2+C∑i=1mξi,+∑i=1mαi(1−ξi−yi(ωTxi+b))−∑i=1mβiξi
我们要求的是这个函数的最值,也就是 min ω , b , ξ max α ≥ 0 , β ≥ 0 L ( ω , b , ξ , α , β ) \min_{\omega, b, \xi}\max_{\alpha \ge 0, \beta\ge 0}L(\omega, b, \xi, \alpha, \beta) minω,b,ξmaxα≥0,β≥0L(ω,b,ξ,α,β)。
在处理硬间隔的时候,我们讲过对偶问题,对于软间隔也是一样。我们求L函数的对偶函数的极值。
对偶问题
原函数的对偶问题是 max α ≥ 0 , β ≥ 0 min ω , b , ξ L ( ω , b , ξ , α , β ) \max_{\alpha \ge0, \beta \ge 0}\min_{\omega, b, \xi}L(\omega, b, \xi, \alpha, \beta) maxα≥0,β≥0minω,b,ξL(ω,b,ξ,α,β),这个对偶问题要成立需要满足KKT条件。
我们先把这个KKT条件放一放,先来看一下对偶问题当中的内部的极小值。这个极小值没有任何约束条件,所以我们可以放心大胆地通过求导来来计算极值。这个同样是高中数学的内容,我们分别计算 ∂ L ∂ ω \frac{\partial L}{\partial \omega} ∂ω∂L, ∂ L ∂ b \frac{\partial L}{\partial b} ∂b∂L和 ∂ L ∂ ξ \frac{\partial L}{\partial \xi} ∂ξ∂L。
求导之后,我们可以得到:
∂ L ∂ ω = 0 → ω = ∑ i = 1 m α i y i x i ∂ L ∂ b = 0 → ∑ i = 1 m α i y i = 0 ∂ L ∂ ξ = 0 → β i = C − α i \begin{aligned} \frac{\partial L}{\partial \omega} = 0 &\rightarrow \omega = \sum_{i=1}^m \alpha_i y_i x_i \\ \frac{\partial L}{\partial b} = 0 &\rightarrow \sum_{i=1}^m \alpha_i y_i = 0 \\ \frac{\partial L}{\partial \xi} = 0 &\rightarrow \beta_i = C - \alpha_i \end{aligned} ∂ω∂L=0∂b∂L=0∂ξ∂L=0→ω=i=1∑mαiyixi→i=1∑mαiyi=0→βi=C−αi
我们把这三个式子带入对偶函数可以得到:
L ( ω , b , ξ , α , β ) = 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j + C ∑ i = 1 m ξ i + ∑ i = 1 m α i ( 1 − ξ i ) − ∑ i = 1 m ( C − α i ) ξ i = ∑ i = 1 m α i − 1 2 ∑ i = 1 m ∑ j = 1 m α i α j y i y j x i T x j \begin{aligned} L(\omega, b, \xi, \alpha,\beta) &= \frac{1}{2} \sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j + C\sum_{i=1}^m \xi_i + \sum_{i=1}^m \alpha_i (1 - \xi_i) - \sum_{i=1}^m (C - \alpha_i) \xi_i \\ &= \sum_{i=1}^m\alpha_i - \frac{1}{2}\sum_{i=1}^m \sum_{j=1}^m \alpha_i \alpha_j y_iy_jx_i^Tx_j \end{aligned} L(ω,b,ξ,α,β)=21i=1∑mj=1∑mαiαjyiyjxiTxj+Ci=1∑mξi+i=1∑mαi(1−ξi)−i=1∑m(C−αi)ξi=i=1∑mαi−21i=1∑mj=1∑mαiαjyiyjxiTxj
由于 β i ≥ 0 \beta_i \ge 0 βi≥0,所以我们可以得到 0 ≤ α i ≤ C 0 \le \alpha_i \le C 0≤αi≤C,所以最后我们可以把式子化简成:

将原始化简了之后,我们再回过头来看KKT条件。KKT条件单独理解看起来有点乱,其实我们可以分成三个部分,分别是原始问题可行:
1 − ξ i − y i ( ω T x i + b ) ≤ 0 − ξ i ≤ 0 \begin{aligned} 1 - \xi_i - y_i(\omega^Tx_i + b) \le 0 \\ -\xi_i \le 0 \end{aligned} 1−ξi−yi(ωTxi+b)≤0−ξi≤0
对偶问题可行:
α i ≥ 0 β i = C − α i \begin{aligned} \alpha_i \ge 0 \\ \beta_i = C - \alpha_i \end{aligned} αi≥0βi=C−αi
以及松弛可行:
α i ( 1 − ξ − y i ( ω T x i + b ) ) = 0 β i ξ i = 0 \begin{aligned} \alpha_i (1 - \xi - y_i(\omega^Tx_i + b)) = 0 \\ \beta_i \xi_i = 0 \end{aligned} αi(1−ξ−yi(ωTxi+b))=0βiξi=0
我们观察一下倒数第二个条件: α i ( 1 − ξ − y i ( ω T x i + b ) ) = 0 \alpha_i (1 - \xi - y_i(\omega^Tx_i + b)) = 0 αi(1−ξ−yi(ωTxi+b))=0。
这是两个式子相乘并且等于0,无非两种情况,要么 α i = 0 \alpha_i = 0 αi=0,要么后面那串等于0。我们分情况讨论。
- 如果 α i = 0 \alpha_i = 0 αi=0,那么 y i ( ω T x i + b ) − 1 ≥ 0 y_i(\omega^Tx_i + b) - 1 \ge 0 yi(ωTxi+b)−1≥0,样本分类正确,不会对模型产生影响。
- 如果 α i > 0 \alpha_i > 0 αi>0,那么 y i ( ω T x i + b ) = 1 − ξ i y_i(\omega^Tx_i + b) = 1 - \xi_i yi(ωTxi+b)=1−ξi,则样本是支持向量。由于 C = α i + β i C = \alpha_i + \beta_i C=αi+βi ,并且 β i ξ i = 0 \beta_i \xi_i= 0 βiξi=0。我们又可以分情况:
- α i < C \alpha_i < C αi<C,那么 β i > 0 \beta_i > 0 βi>0,所以 ξ i = 0 \xi_i = 0 ξi=0,那么样本在边界上
- 如果 α i = C \alpha_i = C αi=C,那么 β i = 0 \beta_i = 0 βi=0,如果此时 ξ ≤ 1 \xi \le 1 ξ≤1,那么样本被正确分类,否则样本被错误分类
经过了化简之后,式子当中只剩下了变量 α \alpha α,我们要做的就是找到满足约束条件并且使得式子取极值时的 α \alpha α,这个 α \alpha α要怎么求呢?我们这里先放一放,将在下一篇文章当中详解讲解。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。
原文链接,求个关注
