文献阅读:On Learning Contrastive Representations for Learning with Noisy Labels
文献阅读:On Learning Contrastive Representations for Learning with Noisy Labels
Abstract
现存的问题:
深度神经网络能够以软最大交叉熵(CE)损失轻松记忆噪声标签。
先前研究选择将噪声鲁棒损失函数结合到CE中,然而问题仍然存在。
文章的提出:
提出了一种新的对比正则化函数来学习噪声数据上的这种表示,其中标签噪声不主导表示学习。
实现的效果:
学习的表示保留了与真实标签相关的信息,并丢弃了与损坏标签有关的信息。
学习的表示对标签噪声是鲁棒的。
Introduction
对比学习:
- 对比学习的关键组成部分是正对比对(x1,x2)。训练对比目标会鼓励x1、x2的表示更接近。
- 监督分类任务中,正确的正对比对由同一类的例子形成。当标签噪声存在时,根据噪声标签定义对比对会产生不利影响。鼓励不同类别的表示更接近,使得分离不同类别的图像变得更加困难。
- 先前的工作侧重于通过根据对比对的伪标签重新定义对比对来减少不利影响。然而,伪标签可能是不可靠的,然后错误的对比对是不可避免的,并且可能主导表征学习。
新对比正则化函数:
从两个方面从理论上研究了由所提出的对比正则化函数引起的表示的益处。
1.图像的表示保留了与真实标签相关的信息,并丢弃了与损坏标签有关的信息。
2.从理论上证明,在给定学习的表示的情况下,分类器很难记住损坏的标签,这证明了我们的表示对标签噪声是鲁棒的。
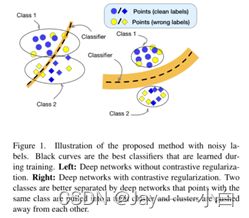
左:没有对比正则化的深度网络。
右:具有对比正则化的深度网络。
Contributions:
-
分析了对比正则化函数诱导的表示,表明表示保留了与真实标签相关的信息,并丢弃了与损坏标签相关的数据。此外,证明了具有不充分的损坏标签相关信息的表示对标签噪声是鲁棒的。
-
提出了一种新的算法来学习带有噪声的数据的对比表示,并提供了梯度分析,以表明正确的对比对可以主导表示学习。
-
方法可以应用于现有的标签校正技术和噪声损失函数,以进一步提高性能。
Theoretical Analysis
Preliminaries:
随机变量: ![]()
样本空间: ![]()
,具体实现:![]()
X为输入随机变量, Y为其真值标签
错误标记的随机变量:![]()
随机变量Y的熵由 ![]() 表示,X和Y的互信息为
表示,X和Y的互信息为![]()
通过在 ![]() 的所有示例
的所有示例 ![]() 上引入以下对比正则化函数来学习表示:
上引入以下对比正则化函数来学习表示:
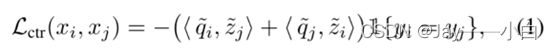
![]()
![]()
![]()
![]()
f是由主干网络和投影MLP组成的编码器网络,h是预测MLP
(如果yi=yj,最小化{(xi,yi),(xj,yj)}上的等式(1)可以拉近xi和xj的表示。应用于表示的停止梯度运算和h的设计主要是为了避免平凡的常数解。
)
The Benefits of Representations Induced by Contrastive Regularization:
首先将最小化等式(1)的解与互信息联系起来 : ![]() 与
与 ![]() 同一类
同一类
![]()
![]()
![]()
- Theorem 1. 通过最小化等式(1)学习的表示Z最大化互信息
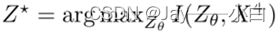 表示最大化互信息,其中
表示最大化互信息,其中
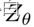 是由具有参数θ的神经网络f参数化的X的表示。
是由具有参数θ的神经网络f参数化的X的表示。
Definition 1 ![]()
![]()
![]()
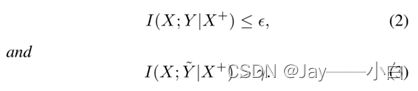
(等式(1)鼓励将来自同一类的表示拉到一起,并将来自不同类的表示推开。以x+为条件的z的估计比随机猜测更准确,因为x的表示z与x+的表示类似。
等式(2)描述了图像与其真实标签之间的关系。如果我们已经知道图像X+,那么通过额外知道X,与真实标签相关的额外信息有限。
等式(3)描述了这些图像与其损坏标签之间的联系。通过知道附加图像X+,X包含的关于其损坏标签的信息~Y仍然大于γ。
增加同类对真实标签的增益少
增加同类对噪声标签的增益大)

- 模型捕获的亮显区域与标签最为相关。
- 对于具有相同干净标签的图像,其与真实标签相关的信息相似。例如,当图2中的猫1和猫2被标记为“猫”时,猫的脸被捕获为与标签相关的真实信息,并且它们看起来都很相似。
- 对于标签损坏的图像,其与损坏标签相关的信息截然不同。

- 该定理指出,学习的表示Z*保留尽可能多的真实标签相关信息,并丢弃大量损坏的标签相关信息。
- 由于从表示Z中丢弃了损坏的标签相关信息, 基于Z的损坏标签记忆减少。

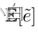 是损坏标签上的预期误差,
是损坏标签上的预期误差,
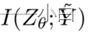 最小化意味着对标签噪声的鲁棒性
最小化意味着对标签噪声的鲁棒性- 当最小化等式(1)时,小
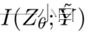 可以如等式(5)中的上界所示实现。同时,等式(4)
可以如等式(5)中的上界所示实现。同时,等式(4)
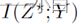 的下界表明可以保留数据的信息
的下界表明可以保留数据的信息

- 这意味着在干净分布下实现的良好分类器也可以基于表示Z*来实现。
- 用预测等于其标签的损坏示例的分数来表示记忆。图3说明了CTR表示在测试准确性和减少记忆方面的改进性能和鲁棒性。

通常,标签噪声的记忆随着训练的进行而增加。我们注意到,在过参数化模型中观察到并证明了先前的记忆,其中数量参数与样本大小的比率约为220。在它们的设置中,模型记忆的示例比例将增加。然而,我们的设置中的记忆是在冻结数据表示之上的线性分类器上测量的,其中数量参数与样本大小的比率大约为0.1,这是参数化不足的。这解释了为什么图3显示记忆随着训练的进行而减少。
Algorithm
等式(1)会导致性能恶化,因此用更可靠的标准![]()
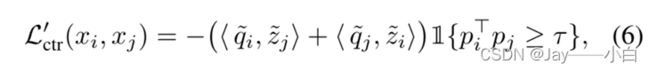
最小化等式(6)仅有助于早期阶段的表征学习。在这段时间之后,带有损坏标签的示例将主导学习过程。在早期阶段之后,深度网络开始适应错误标记的数据,错误的对比对会被错误的分到一起。
![]()
![]()
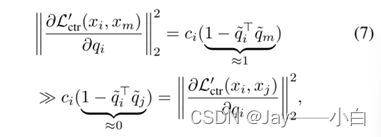
简单地最小化等式(1)会导致性能恶化。要看到这一点,请注意,只有当1{yi=yj}=1时,等式(1)才被激活。因此,当存在噪声标签时,来自不同类的两个表示将被拉到一起。
pi是线性分类器在图像xi表示上产生的概率输出
为了解决这个问题,提出了以下正则化函数
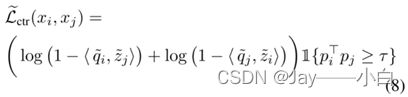
来自正确对 ![]() 的梯度大于来自错误对
的梯度大于来自错误对![]()
![]()
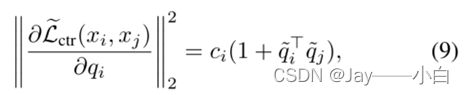
不受错误对的梯度支配,也不会过度拟合干净的示例。在表示的顶部使用一个单独的线性层作为分类器,因此,只要线性层中的参数的分类损失梯度在干净的示例上不太大,模型就不会过度拟合它们。
(等式(8)仍然旨在学习具有相同真实标签的数据的类似表示。由于等式(8)的最大值与等式(1)相同,因此我们关于Z的理论结果⋆ 保持不变。
我们提出的正则化函数不受错误对的梯度支配。同时,即使来自正确对的等式(8)的梯度大于错误对,该模型也不会过度拟合干净的示例。由于等式(7)描述了关于表示的梯度,其大小可以看作是将同一类的干净示例拉得更近的强度,这与过度拟合干净示例没有直接关系。此外,我们在表示的顶部使用一个单独的线性层作为分类器,因此,只要线性层中的参数的分类损失梯度在干净的示例上不太大,模型就不会过度拟合它们。)
总体目标函数由下式给出 :
![]()
Experiments
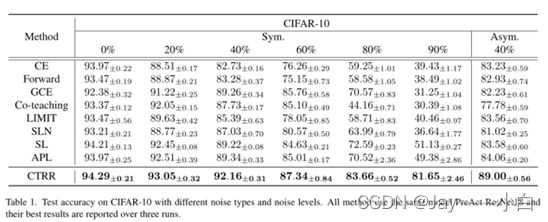

表1和表2显示了具有各种标签噪声设置的CIFAR-10和CIFAR-100的结果。当噪声水平较高时,改善更为显著。

表3显示了真实世界数据集ANIMAL-10N和Clothing1M的结果。所有方法都使用相同的模型,并在三次运行中报告最佳结果。

超参数λ控制数据表示的正则化强度。图4 (左)显示了不同λ的测试精度。结果符合预期,即太强或太弱的正则化会导致性能不佳。
τ是从同一类中选择两个示例的置信阈值。当两个示例的得分超过阈值时,这两个示例被认为是正确的对。如果τ设置得太低,则会选择许多错误的对。图4(右)显示了不同τ的测试精度。

比较了等式(8)和等式(6)的性能。经验结果与先前的梯度分析一致,如表4所示。因此,使用等式(8)学习数据表示可以避免错误对支配表示学习。
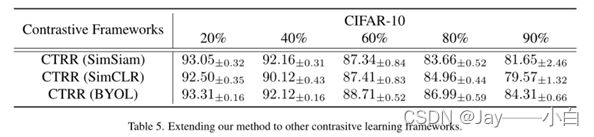
将CTRR应用于其他比较学习框架。表5表明,我们的原则不仅限于SimSiam框架,还可以应用于其他对比学习框架。
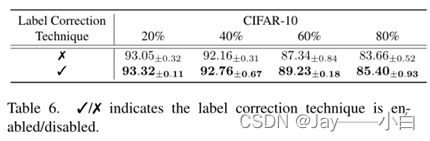
在表6中,表明在启用简单的标签校正技术后,性能得到了改善。

GCE是与CE和MAE隐式组合的部分噪声鲁棒损失函数。表7中展示了我们的方法和GCE组合的性能。
通过我们提出的方法诱导的表征,GCE有了显著的改进,这证明了学习表征的有效性。同时,这种组合的成功意味着我们提出的方法对其他部分噪声鲁棒损失函数是有益的。