基于hadoop的电影推荐系统的实现
1.设计任务
通过编写代码,设计一个基于Hadoop的电影推荐系统,通过此推荐系统的编写,掌握在Hadoop平台上的文件操作,数据处理的技能。
工程文件放在百度网盘了,运行run.py即可启动程序,由于代码年份久远,我已尽量打了注释,大家可以下载后进行摸索。
链接:https://pan.baidu.com/s/17OpSNstnFA1nVxDisuNBBg
提取码:9fv3
2.开发环境
windows 10
hadoop 2.8.3
python 3.+
vscode
MySQL 8.0
关于hadoop配置可以看我之前的文章
win10下配置hadoop环境
3.系统层次设计
为了使电影推荐系统的设计更加完善,提高推荐系统的可维护性和可拓展性。我们采用三种系统相结合的方式进行总的系统层次设计。分为Hadoop为主的分布式系统,python为主的算法分析系统和MySQL为主的数据库存储系统。三种系统之间相互独立,仅采用特定的程序接口进行调用,可以最大程度的增强推荐系统的稳健性。
该系统的设计框架图如下所示:
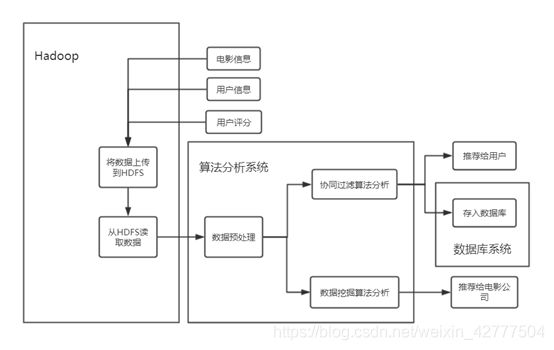
4.数据上传与下载
1.启动hadoop
2.将ml-100k数据集上传到hadoop下的ml-100k文件夹

上传结果如下:

3.与python相连接
利用python中的hdfs包,用如下代码实现hadoop与python相连接。
from hdfs import *
client = Client("http://localhost:50070")
4.数据下载
client.download(file_user_movie,"D://VSC//vscode python//hadoop//ml-100k")
client.download(file_movie_info,"D://VSC//vscode python//hadoop//ml-100k")
client.download(user_information,"D://VSC//vscode python//hadoop//ml-100k")
5.面向电影制作方的推荐数据
运行结果如下图所示:


总览如下:


6.基于协同过滤算法的用户推荐算法
运行结果如下图:
7.将推荐结果存入数据库以便查阅
db = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123456', db='test', charset='utf8')
cursor = db.cursor() #新建数据库访问游标
main函数调用
cursor.execute("drop table if exists Recommended") #检查数据库中是否存在名为recommended的数据库,若存在则删除
sql = """
create table Recommended (
film varchar(80) not null,
rating DECIMAL (7, 4) not null )
"""
cursor.execute(sql) #创建数据库
for i in result.keys():
print("film:%s,rating:%f"%(movies[i],result[i]))
sql = 'insert into Recommended (`film`,`rating`) values("%s","%f")'%(movies[i],result[i])
cursor.execute(sql) #执行数据插入语句
db.commit() #提交结果到数据库中

8.参考资料
[1]《大数据原理及应用》电子邮电出版社 林子雨著
[2] Python如何连接mysql数据库 https://www.py.cn/jishu/jichu/12706.html
[3] Movielens数据集详细介绍 https://blog.csdn.net/zwqhehe/article/details/75912003
[4] Python3调用Hadoop的API https://www.cnblogs.com/sss4/p/10443497.html
[5] Collaborative Filtering(协同过滤算法详解) https://www.cnblogs.com/ECJTUACM-873284962/p/8729010.html
9.部分源码
完整代码请移步基于Hadoop的电影推荐系统 下载
或者我的github,里面有详细的数据集和代码
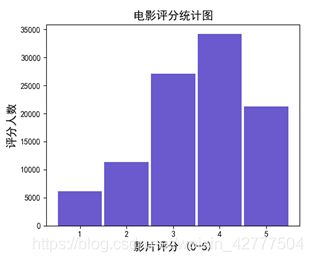
def score_analysis(): #电影评分分析
scores = {"1":0,"2":0,"3":0,"4":0,"5":0}
for line in open(user_movie):
user, item, score = line.split('\t')[0:3]
scores[score] += 1
x1 = scores.keys() #用字典的键也就是分数作为x轴
y1 = scores.values() #用字典键对应的值也就是打分人数作为y轴
# print(scores)
plt.figure(figsize=(19, 10))
plt.subplot(2,3,2)
plt.bar(x1,y1,color = 'slateblue',width = 0.95)
plt.title("电影评分统计图",fontsize=14)
plt.xlabel("影片评分 (0-5)",fontsize=14)
plt.ylabel("评分人数",fontsize = 14)
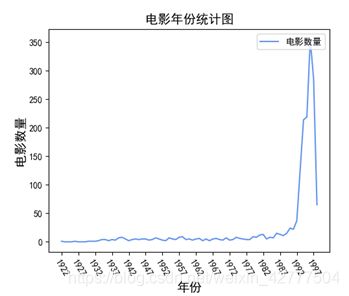
def movie_year_analysis(): #电影年份分析
yearCounts = {} #用来统计电影年份与数量的对应关系
for year in range(1922,1999): #按照数据集中电影的年份信息 生成年份字典
yearCounts[str(year)] = 0
for line in open(movie_information,encoding='ISO-8859-1'):
release_date = line.split('|')[2]
release_year = release_date[-4:]
if release_year == "": continue
yearCounts[release_year] += 1
x2 = list(yearCounts.keys()) #获取x轴坐标并转为列表
y2 = list(yearCounts.values())#获取y轴坐标并转为列表
plt.subplot(2,3,5)
plt.plot(x2,y2,label = '电影数量',color = 'cornflowerblue')
plt.legend(loc="upper right") #设置标签图在右上角
x_major_locator=MultipleLocator(5) #设置x轴间隔为5
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.xticks(rotation = -60) #将x轴坐标旋转60度
x_new = range(1922,1998)
plt.title("电影年份统计图",fontsize=14)
plt.xlabel("年份",fontsize=14)
plt.ylabel("电影数量",fontsize = 14)
# plt.show()
def occuptin_analysis(): #职业分析
occuption_count = {}
for line in open(user_information):
occuption = line.split('|')[3]
occuption_count[occuption] = occuption_count.get(occuption,0) + 1 #统计职业及其对应人数
sort_occuption_counts = sorted(occuption_count.items(),key=lambda k: k[1]) #将结果从小到大排序
# print(sort_occuption_counts)
#由于排序之后,字典类型会变成列表类型
#然而这两种类型无法相互转换
#所以得遍历来将列表的值转换为字典
sort_occuption = {}
for i in sort_occuption_counts: #将排序结果存回字典
sort_occuption[i[0]] = i[1]
# print(sort_occuption)
x4 = sort_occuption.keys()
y4 = sort_occuption.values()
plt.subplot(2,3,6)
plt.bar(x4,y4,color = 'blue',width = 0.8)
plt.xticks(rotation = -60) #将x轴坐标旋转60度
# plt.title("用户职业统计情况",fontsize=14)
plt.xlabel("职业",fontsize=14)
plt.ylabel("人数",fontsize=14)
def gender_analysis(): #性别分析
unames = ['userid','age','gender','occupation','zip code']
users = pd.read_table('u.user',sep = '\|',names = unames)
rnames = ['userid','itemid','rating','timestamp']
ratings = pd.read_table('u.data',names = rnames,engine = 'python')
inames = ['itemid','movie title','release date','video release date','IMDB URL','unknown','Action','Adventure'
,'Animation','Children\'s','Comedy','Crime','DOcumentrary','Drama','Fatasy','Film-Noir','Horror','Musical'
,'Mystery','Romance','Sci-Fi','Thriller','War','Western']
items = pd.read_table('u.item',sep = '\|',names = inames,engine = 'python')
#计算男女生对电影评分的平均值和标准差
users_df = pd.DataFrame()
users_df['userid'] = users['userid']
users_df['gender'] = users['gender']
ratings_df = pd.DataFrame()
ratings_df['userid'] = ratings['userid']
ratings_df['rating'] = ratings['rating']
rating_df = pd.merge(users_df,ratings_df)
gender_table = pd.pivot_table(rating_df,index = ['gender','userid'],values = 'rating')
gender_df = pd.DataFrame(gender_table)
Female_df = gender_df.query("gender == ['F']")
Male_df = gender_df.query("gender == ['M']")
print("男性电影评分平均值:"+str(Male_df.rating.sum()/len(Male_df.rating)) +" 标准差:"+str(np.std(Male_df.rating)))
print("女生电影评分平均值:"+str(Female_df.rating.sum()/len(Female_df.rating))+"标准差:"+str(np.std(Female_df.rating)))
ratings_df_2 = pd.DataFrame()
ratings_df_2['userid'] = ratings['userid']
ratings_df_2['rating'] = ratings['rating']
ratings_df_2['itemid'] = ratings['itemid']
items_df = pd.DataFrame()
items_df['itemid'] = items['itemid']
items_df['movietitle'] = items['movie title']
tmp = pd.merge(users_df,ratings_df_2)
gender_item_df = pd.merge(tmp,items_df)
Female_item_df = gender_item_df.query("gender == ['F']")
Male_item_df = gender_item_df.query("gender == ['M']")
print("女生最爱看的五部电影")
print(Female_item_df.groupby(['movietitle']).rating.mean().sort_values(ascending = False)[0:5,])
print("男生最爱看的五部电影")
print(Male_item_df.groupby(['movietitle']).rating.mean().sort_values(ascending = False)[0:5,])
def gender_compare():
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv(user_information, sep='|', names=u_cols,encoding='latin-1')
r_cols = ['user_id', 'movie_id', 'rating', 'unix_timestamp']
ratings = pd.read_csv(user_movie, sep='\t', names=r_cols,encoding='latin-1')
m_cols = ['movie_id', 'title', 'release_date', 'video_release_date', 'imdb_url']
movies = pd.read_csv(movie_information, sep='|', names=m_cols, usecols=range(5),encoding='latin-1')
# 数据集整合
movie_ratings = pd.merge(movies, ratings)
lens = pd.merge(movie_ratings, users)
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79']
lens['age_group'] = pd.cut(lens.age, range(0, 81, 10), right=False, labels=labels)
lens[['age', 'age_group']].drop_duplicates()[:10]
lens.groupby('age_group').agg({'rating': [np.size, np.mean]})
most_50 = lens.groupby('movie_id').size().sort_values(ascending=False)[:50]
lens.set_index('movie_id', inplace=True)
by_age = lens.loc[most_50.index].groupby(['title', 'age_group'])
lens.reset_index('movie_id', inplace=True)
pivoted = lens.pivot_table(index=['movie_id', 'title'],
columns=['sex'],
values='rating',
fill_value=0)
pivoted['diff'] = pivoted.M - pivoted.F
plt.subplot(2,3,3)
users.age.plot.hist(bins=30,edgecolor='black')
plt.title("用户年龄分布图",fontsize=14)
plt.ylabel('用户数量',fontsize=14)
plt.xlabel('用户年龄',fontsize=14)
pivoted.reset_index('movie_id', inplace=True)
disagreements = pivoted[pivoted.movie_id.isin(most_50.index)]['diff']
plt.subplot(1,3,1)
disagreements.sort_values().plot(kind='barh',color = 'dodgerblue')
plt.title('男/女性平均评分\n(差异>0=受男性青睐)',fontsize=14)
plt.ylabel('电影',fontsize=14)
plt.xlabel('平均评级差',fontsize=14)
def ItemSimilarity(user_movie):
C = {} #存放最终的物品相似度矩阵
N = {} #存放每个电影评分人数
for user, items in user_movie.items():
for i in items.keys():
print(i)
N.setdefault(i,0)
N[i] += 1
C.setdefault(i,{})
for j in items.keys():
if i == j : continue
C[i].setdefault(j,0)
C[i][j] += 1
W = {} #计算最终物品余弦相似度矩阵
for i, related_items in C.items():
W.setdefault(i,{})
for j,cij in related_items.items():
W[i][j] = cij /(math.sqrt(N[i] * N[j]))
return W
def Recommend(user, user_movie, W, K, N): #根据矩阵为具体用户推荐
rank = {}
action_item = user_movie[user]
for item, score in action_item.items():
for j, wj in sorted(W[item].items(),key = lambda x: x[1], reverse = True)[0:K]:
if j in action_item.keys():
continue
rank.setdefault(j,0)
rank[j] += score * wj
return dict(sorted(rank.items(),key = lambda x:x[1],reverse= True)[0:N]) #排序 取前N个结果
class information_counts(MRJob):
"""
聚合单个用户的下的所有评分数据
格式为:user_id, (item_count, rating_sum, [(item_id,rating)...])
"""
def group_by_user_rating(self, key, line):
user_id, item_id, rating = line.split('|')
yield user_id, (item_id, float(rating))
def count_ratings_users_freq(self, user_id, values):
item_count = 0
item_sum = 0
final = []
for item_id, rating in values:
item_count += 1
item_sum += rating
final.append((item_id, rating))
yield user_id, (item_count, item_sum, final)
def steps(self):
return [MRStep(mapper=self.group_by_user_rating,
reducer=self.count_ratings_users_freq),]