机器学习-Sklearn-13(回归类大家族-下——非线性问题:多项式回归(多项式变换后形成新特征矩阵))
机器学习-Sklearn-13(回归类大家族-下——非线性问题:多项式回归(多项式变换后形成新特征矩阵))
5 非线性问题:多项式回归
5.1 重塑我们心中的“线性”概念
在机器学习和统计学中,甚至在我们之前的课程中,我们无数次提到”线性“这个名词。首先我们本周的算法就叫做”线性回归“,而在支持向量机中,我们也曾经提到最初的支持向量机只能够分割线性可分的数据,然后引入了”核函数“来帮助我们分类那些非线性可分的数据。我们也曾经说起过,比如说决策树,支持向量机是”非线性“模型。所有的这些概念,让我们对”线性“这个词非常熟悉,却又非常陌生——因为我们并不知道它的真实含义。在这一小节,我将来为大家重塑线性的概念,并且为大家解决线性回归模型改进的核心之一:帮助线性回归解决非线性问题。
5.1.1 变量之间的线性关系
首先,”线性“这个词用于描述不同事物时有着不同的含义。我们最常使用的线性是指“变量之间的线性关系(linear relationship)”,它表示两个变量之间的关系可以展示为一条直线,即可以使用方程y=ax+b来进行拟合。


5.1.2 数据的线性与非线性
从线性关系这个概念出发,我们有了一种说法叫做**“线性数据”**。通常来说,一组数据由多个特征和标签组成。当这些特征分别与标签存在线性关系的时候,我们就说这一组数据是线性数据。当特征矩阵中任意一个特征与标签之间的关系需要使用三角函数,指数函数等函数来定义,则我们就说这种数据叫做“非线性数据”。
对于线性和非线性数据,最简单的判别方法就是利用模型来帮助我们——如果是做分类则使用逻辑回归,如果做回归则使用线性回归,如果效果好那数据是线性的,效果不好则数据不是线性的。当然,也可以降维后进行绘图,绘制出的图像分布接近一条直线,则数据就是线性的。



同时我们还注意到,当我们在进行分类的时候,我们的数据分布往往是这样的:

可以看得出,这些数据都不能由一条直线来进行拟合,他们也没有均匀分布在某一条线的周围,那我们怎么判断,这些数据是线性数据还是非线性数据呢?在这里就要注意了,当我们在回归中绘制图像时,绘制的是特征与标签的关系图,横坐标是特征,纵坐标是标签,我们的标签是连续型的,所以我们可以通过是否能够使用一条直线来拟合图像判断数据究竟属于线性还是非线性。然而在分类中,我们绘制的是数据分布图,横坐标是其中一个特征,纵坐标是另一个特征,标签则是数据点的颜色。因此在分类数据中,我们使用“是否线性可分”(linearly separable)这个概念来划分分类数据集。当分类数据的分布上可以使用一条直线来将两类数据分开时,我们就说数据是线性可分的。反之,数据不是线性可分的。
总结一下,对于回归问题,数据若能分布为一条直线,则是线性的,否则是非线性。对于分类问题,数据分布若能使用一条直线来划分类别,则是线性可分的,否则数据则是线性不可分的。
5.1.3 线性模型与非线性模型
在回归中,线性数据可以使用如下的方程来进行拟合:
![]()
也就是我们的线性回归的方程。根据线性回归的方程,我们可以拟合出一组参数 ,在这一组固定的参数下我们可以建立一个模型,而这个模型就被我们称之为是线性回归模型。所以建模的过程就是寻找参数的过程。此时此刻我们建立的线性回归模型,是一个用于拟合线性数据的线性模型。作为线性模型的典型代表,我们可以从线性回归的方程中总结出线性模型的特点:其自变量都是一次项。
那线性回归在非线性数据上的表现如何呢?我们来建立一个明显是非线性的数据集,并观察线性回归和决策树的而回归在拟合非线性数据集时的表现:
#1. 导入所需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
#2. 创建需要拟合的数据集
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100) #random.uniform,从输入的任意两个整数中取出size个随机数
X #作为横坐标

#生成y的思路:先使用NumPy中的函数生成一个sin函数图像,然后再人为添加噪音
#random.normal,生成size个服从正态分布的随机数
#此外正弦函数添加噪声,该噪声除以3是为了让添加的噪声后的正选曲线依然能够看出是正弦函数的样子,让噪声不要过于大了而使其失去了原本正弦曲线的样子。
y = np.sin(X) + rnd.normal(size=len(X)) / 3
y

#使用散点图观察建立的数据集是什么样子
plt.scatter(X, y,marker='o',c='k',s=20)
plt.show()

#为后续建模做准备:sklearn只接受二维以上数组作为特征矩阵的输入
X.shape
![]()
#升维
X = X.reshape(-1, 1)
X.shape
![]()
#3. 使用原始数据进行建模
#使用原始数据进行建模
LinearR = LinearRegression().fit(X, y)
TreeR = DecisionTreeRegressor(random_state=0).fit(X, y)
#放置画布 (画布命令要和绘图命令在同一个cell)
fig, ax1 = plt.subplots(1)
#创建测试数据:一系列分布在横坐标上的点
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
plt.tight_layout()
plt.show()
#从这个图像来看,可以得出什么结果?

#从图像上可以看出,线性回归无法拟合出这条带噪音的正弦曲线的真实面貌,只能够模拟出大概的趋势,而决策树却通过建立复杂的模型将几乎每个点都拟合出来了。可见,使用线性回归模型来拟合非线性数据的效果并不好,而决策树这样的模型却拟合得太细致,过拟合了,但是相比之下,还是决策树的拟合效果更好一些。
#决策树无法写作一个方程(我们在XGBoost章节中会详细讲解如何将决策树定义成一个方程,但它绝对不是一个形似y=ax+b的方程),它是一个典型的非线性模型,当它被用于拟合非线性数据,可以发挥奇效。
#其他典型的非线性模型还包括使用高斯核的支持向量机,树的集成算法,以及一切通过三角函数,指数函数等非线性方程来建立的模型。
根据这个思路,我们也许可以这样推断:线性模型用于拟合线性数据,非线性模型用于拟合非线性数据。
但事实上机器学习远远比我们想象的灵活得多,线性模型可以用来拟合非线性数据,而非线性模型也可以用来拟合线性数据,更神奇的是,有的算法没有模型也可以处理各类数据,而有的模型可以既可以是线性,也可以是非线性模型!
接下来,我们就来一一讨论这些问题。
非线性模型拟合线性数据
非线性模型能够拟合或处理线性数据的例子非常多,我们在之前的课程中多次为大家展示了非线性模型诸如决策树,随机森林等算法在分类中处理线性可分的数据的效果。无一例外的,非线性模型们几乎都可以在线性可分数据上有不逊于线性模型的表现。同样的,如果我们使用随机森林来拟合一条直线,那随机森林毫无疑问会过拟合,因为线性数据对于非线性模型来说太过简单,很容易就把训练集上的R^2训练得很高,MSE训练的很低。

线性模型拟合非线性数据
但是相反的,线性模型若用来拟合非线性数据或者对非线性可分的数据进行分类,那通常都会表现糟糕。通常如果我们已经发现数据属于非线性数据,或者数据非线性可分的数据,则我们不会选择使用线性模型来进行建模。改善线性模型在非线性数据上的效果的方法之一时进行分箱,并且从下图来看分箱的效果不是一般的好,甚至高过一些非线性模型。在下一节中我们会详细来讲解分箱的效果,但很容易注意到,在没有其他算法或者预处理帮忙的情况下,线性模型在非线性数据上的表现时很糟糕的。

从上面的图中,我们可以观察出一个特性:线性模型们的决策边界都是一条条平行的直线,而非线性模型们的决策边界是交互的直线(格子),曲线,环形等等。对于分类模型来说,这是我们判断模型是线性还是非线性的重要评判因素:线性模型的决策边界是平行的直线,非线性模型的决策边界是曲线或者交叉的直线。之前我们提到,模型上如果自变量上的最高次方为1,则模型是线性的,但这种方式只适用于回归问题。分类模型中,我们很少讨论模型是否线性,因为我们很少使用线性模型来执行分类任务(逻辑回归是一个特例)。但从上面我们总结出的结果来看,我们可以认为对分类问题而言,如果一个分类模型的决策边界上自变量的最高次方为1,则我们称这个模型是线性模型。
既是线性,也是非线性的模型
对于有一些模型来说,他们既可以处理线性模型又可以处理非线性模型,比如说强大的支持向量机。支持向量机的前身是感知机模型,朴实的感知机模型是实打实的线性模型(其决策边界是直线),在线性可分数据上表现优秀,但在非线性可分的数据上基本属于无法使用状态。


还有更加特殊的,没有模型的算法,比如最近邻算法KNN,这些都是不建模,但是能够直接预测出标签或做出判断的算法。而这些算法,并没有线性非线性之分,单纯的是不建模的算法们。
讨论到这里,相信大家对于线性和非线性模型的概念就比较清楚了。来看看下面这张表的总结:
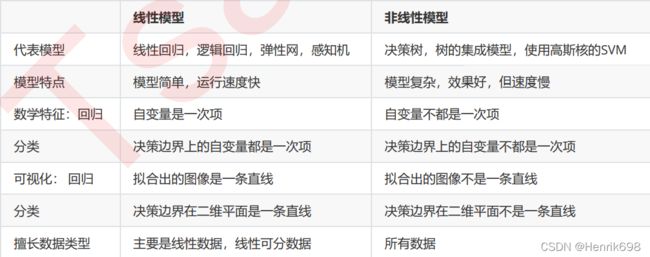
模型在线性和非线性数据集上的表现为我们选择模型提供了一个思路:
当我们获取数据时,我们往往希望使用线性模型来对数据进行最初的拟合(线性回归用于回归,逻辑回归用于分类),如果线性模型表现良好,则说明数据本身很可能是线性的或者线性可分的,如果线性模型表现糟糕,那毫无疑问我们会投入决策树,随机森林这些模型的怀抱,就不必浪费时间在线性模型上了。
不过这并不代表着我们就完全不能使用线性模型来处理非线性数据了。在现实中,线性模型有着不可替代的优势:计算速度异常快速,所以也还是存在着我们无论如何也希望使用线性回归的情况。因此,我们有多种手段来处理线性回归无法拟合非线性问题的问题,接下来我们就来看一看。
5.2 使用分箱处理非线性问题
让线性回归在非线性数据上表现提升的核心方法之一是对数据进行分箱,也就是离散化。与线性回归相比,我们常用的一种回归是决策树的回归。我们之前拟合过一条带有噪音的正弦曲线以展示多元线性回归与决策树的效用差异,我们来分析一下这张图,然后再使用采取措施帮助我们的线性回归。
#1. 导入所需要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
#2. 创建需要拟合的数据集
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100) #random.uniform,从输入的任意两个整数中取出size个随机数
#生成y的思路:先使用NumPy中的函数生成一个sin函数图像,然后再人为添加噪音
y = np.sin(X) + rnd.normal(size=len(X)) / 3 #random.normal,生成size个服从正态分布的随机数
#使用散点图观察建立的数据集是什么样子
plt.scatter(X, y,marker='o',c='k',s=20)
plt.show()

#为后续建模做准备:sklearn只接受二维以上数组作为特征矩阵的输入
X = X.reshape(-1, 1)
X.shape
![]()
在这里插入代码片#3. 使用原始数据进行建模
#使用原始数据进行建模
LinearR = LinearRegression().fit(X, y)
TreeR = DecisionTreeRegressor(random_state=0).fit(X, y)
#放置画布
fig, ax1 = plt.subplots(1)
#创建测试数据:一系列分布在横坐标上的点
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
plt.tight_layout()
plt.show()
#从这个图像来看,可以得出什么结果?

#4. 分箱及分箱的相关问题
from sklearn.preprocessing import KBinsDiscretizer
#KBinsDiscretizer离散化使用的类,连续型转成分类型,分段函数来拟合大概的趋势。
#将数据分箱
enc = KBinsDiscretizer(n_bins=10 #分几类(分成几个箱子呢)?
,encode="onehot") #ordinal
#encode参数表示分类模式,有两种编码方式,一种是ordinal,另一种是onehot。
#第一种encode模式"ordinal":当我们输入一列特征之后,它会给我们返回一列特征。返回的这列特征上,原有的特征值已经被我们的类别0123456789所代替了,我们分10箱,就返回0到9。
#第二种encode模式"onehot":使用做哑变量方式做离散化。
#之后返回一个稀疏矩阵(m,n_bins),m表示样本数量,n_bins每一列是一个分好的类别。
#n_bins为10,fit_tansform(X),转换后出来的X就会有X原本的行数,并且有10列。
#对每一个样本而言,它包含的分类(箱子)中它表示为1,其余分类中它表示为0
X_binned = enc.fit_transform(X) #获得分箱后的特征矩阵。
X #原来的X,是一列连续型的变量。

X.shape
![]()
X_binned #100行10列的稀疏矩阵,矩阵中带的是numpy.float64位的浮点数。
#这里的100行10列,其实就是上面训练转换返回的稀疏矩阵(m,n_bins)

#使用pandas打开稀疏矩阵
import pandas as pd
pd.DataFrame(X_binned.toarray()).head()
#可以看到第0号样本被分到了第四箱中,因为在4号箱中是1,其他箱中为0。

#我们将使用分箱后的数据来训练模型,在sklearn中,测试集和训练集的结构必须保持一致,否则报错
#新建一个线性回归模型,将分箱后的X_binned放入其中进行训练。
LinearR_ = LinearRegression().fit(X_binned, y)
LinearR_.predict(line) #line作为测试集
#这个报错数目,测试数据和训练数据的数据结构必须一致,不然会报错。

line.shape #测试
![]()
X_binned.shape #训练
![]()
#因此我们需要创建分箱后的测试集:按照已经建好的分箱模型将line分箱
line_binned = enc.transform(line)
line_binned.shape #分箱后的数据是无法进行绘图的
![]()
line_binned #也是一个稀疏矩阵,需要用pandas来查看

LinearR_.predict(line_binned).shape
![]()
LinearR_.predict(line_binned)

#5. 使用分箱数据进行建模和绘图
#===============================================
#等号线间的内容为下面 “建模和绘图” 过程中一些相关提示:
enc.bin_edges_ #分出的箱子的上限和下限,每个箱的边缘

enc.bin_edges_[0] #就可以完全将上限和下限完全取出来

plt.gca().get_ylim()
#.get_ylim()包含了两个对象
[*plt.gca().get_ylim()] #将0和1单独取出,用于限制之后绘制的竖线。
#===============================================
#建模和绘图:
#准备数据
#实例化,分10箱,分类方式的独热编码。
enc = KBinsDiscretizer(n_bins=10,encode="onehot")
X_binned = enc.fit_transform(X) #将原本的X转换成分箱后的训练集数据
line_binned = enc.transform(line) #再将测试数据line通过之前训练数据训练的分箱模型转换成分箱后的测试集数据。
#将两张图像绘制在一起,布置画布
fig, (ax1, ax2) = plt.subplots(ncols=2 #两个图上都有标尺
, sharey=True #让两张图共享y轴上的刻度,所以右侧的图只有标尺没有刻度
, figsize=(10, 4))
#在图1中布置在原始数据上建模的结果
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green',
label="linear regression")
ax1.plot(line, TreeR.predict(line), linewidth=2, color='red',
label="decision tree")
ax1.plot(X[:, 0], y, 'o', c='k')
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Result before discretization")
#使用分箱数据进行建模
LinearR_ = LinearRegression().fit(X_binned, y)
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
#进行预测,在图2中布置在分箱数据上进行预测的结果
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
#绘制和箱宽一致的竖线
ax2.vlines(enc.bin_edges_[0] #x轴
, *plt.gca().get_ylim() #y轴的上限和下限,这样可以现在所要绘制的竖线的范围,因为如果不限制,则会画出图像外面,不美观。
#*plt.gca()表示取出目前这个图像,.get_ylim()表示取出目前这个图像的y轴的上限和下限
, linewidth=1
, alpha=.2)
#将原始数据分布放置在图像上
ax2.plot(X[:, 0], y, 'o', c='k')
#其他绘图设定
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()

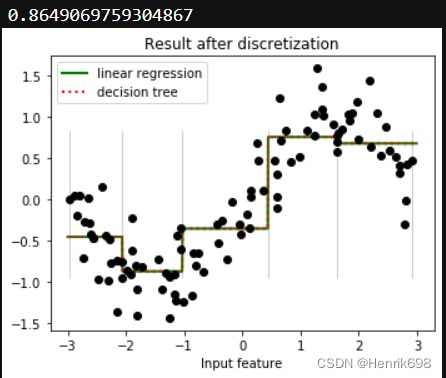
#从图像上可以看出,离散化后线性回归和决策树上的预测结果完全相同了——线性回归比较成功地拟合了数据的分布,而决策树的过拟合效应也减轻了。
#由于特征矩阵被分箱,因此特征矩阵在每个区域内获得的值是恒定的,因此所有模型对同一个箱中所有的样本都会获得相同的预测值。
#与分箱前的结果相比,线性回归明显变得更加灵活,而决策树的过拟合问题也得到了改善。
#但注意,一般来说我们是不使用分箱来改善决策树的过拟合问题的,因为树模型带有丰富而有效的剪枝功能来防止过拟合。
#在这个例子中,我们设置的分箱箱数为10,不难想到这个箱数的设定肯定会影响模型最后的预测结果,我们来看看不同的箱数会如何影响回归的结果:
#6. 箱子数如何影响模型的结果
#对比不同分箱数所对应的score结果。
#这次分5箱n_bins = 5
enc = KBinsDiscretizer(n_bins=5,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
fig, ax2 = plt.subplots(1,figsize=(5,4))
LinearR_ = LinearRegression().fit(X_binned, y)
#线性拟合的分数,测试集转换后的line_binned(Xtest),将line放入三角函数中所得到的结果(Ytest)
print(LinearR_.score(line_binned,np.sin(line)))
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()
#这次分10箱n_bins = 10
enc = KBinsDiscretizer(n_bins=10,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
fig, ax2 = plt.subplots(1,figsize=(5,4))
LinearR_ = LinearRegression().fit(X_binned, y)
#线性拟合的分数,测试集转换后的line_binned(Xtest),将line放入三角函数中所得到的结果(Ytest)
print(LinearR_.score(line_binned,np.sin(line)))
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()

#这次分30箱n_bins = 30
enc = KBinsDiscretizer(n_bins=30,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
fig, ax2 = plt.subplots(1,figsize=(5,4))
LinearR_ = LinearRegression().fit(X_binned, y)
#线性拟合的分数,测试集转换后的line_binned(Xtest),将line放入三角函数中所得到的结果(Ytest)
print(LinearR_.score(line_binned,np.sin(line)))
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()

#重要:如果分箱过多会造成过拟合,因为分10箱时分数已经很好了。
#7. 如何选取最优的箱数
#怎样选取最优的箱子?
#最优问题,永远是交叉验证
from sklearn.model_selection import cross_val_score as CVS
import numpy as np
pred,score,var = [], [], []
binsrange = [2,5,10,15,20,30]
#绘制学习曲线
for i in binsrange:
#实例化分箱类
enc = KBinsDiscretizer(n_bins=i,encode="onehot")
#转换数据
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
#建立模型
LinearR_ = LinearRegression()
#全数据集上的交叉验证
cvresult = CVS(LinearR_,X_binned,y,cv=5)
score.append(cvresult.mean())
var.append(cvresult.var())
#测试数据集上的打分结果R^2
pred.append(LinearR_.fit(X_binned,y).score(line_binned,np.sin(line)))
#绘制图像
plt.figure(figsize=(6,5))
#第一天线:测试数据,橙色
plt.plot(binsrange,pred,c="orange",label="test")
#第二条线,全数据在交叉验证后的均值
plt.plot(binsrange,score,c="k",label="full data")
#第三和四条线,围绕在全数据交叉验证后均值两边的方差。
plt.plot(binsrange,score+np.array(var)*0.5,c="red",linestyle="--",label = "var")
plt.plot(binsrange,score-np.array(var)*0.5,c="red",linestyle="--")
plt.legend()
plt.show()

#由于X_binned数据太少了,交叉验证结果会比测试结果低不少。
#可以看到趋势比较相似。
#箱数为20时,交叉验证结果最好,而且方差离全数据均值很接近。
#发现20箱时,结果最好。方差很小,模型稳定,R^2是最高的。
#这次分20箱n_bins = 20
enc = KBinsDiscretizer(n_bins=20,encode="onehot")
X_binned = enc.fit_transform(X)
line_binned = enc.transform(line)
fig, ax2 = plt.subplots(1,figsize=(5,4))
LinearR_ = LinearRegression().fit(X_binned, y)
#线性拟合的分数,测试集转换后的line_binned(Xtest),将line放入三角函数中所得到的结果(Ytest)
print(LinearR_.score(line_binned,np.sin(line)))
TreeR_ = DecisionTreeRegressor(random_state=0).fit(X_binned, y)
ax2.plot(line #横坐标
, LinearR_.predict(line_binned) #分箱后的特征矩阵的结果
, linewidth=2
, color='green'
, linestyle='-'
, label='linear regression')
ax2.plot(line, TreeR_.predict(line_binned), linewidth=2, color='red',
linestyle=':', label='decision tree')
ax2.vlines(enc.bin_edges_[0], *plt.gca().get_ylim(), linewidth=1, alpha=.2)
ax2.plot(X[:, 0], y, 'o', c='k')
ax2.legend(loc="best")
ax2.set_xlabel("Input feature")
ax2.set_title("Result after discretization")
plt.tight_layout()
plt.show()
#如果觉得过拟合了,可以适当减小箱子数量

在工业中,大量离散化变量与线性模型连用的实例很多,在深度学习出现之前,这种模式甚至一度统治一些工业中的机器学习应用场景,可见效果优秀,应用广泛。对于现在的很多工业场景而言,大量离散化特征的情况可能已经不是那么多了,不过大家依然需要对“分箱能够解决线性模型无法处理非线性数据的问题”有所了解。
5.3 多项式回归PolynomialFeatures
5.3.1 多项式对数据做了什么
除了分箱之外,另一种更普遍的用于解决”线性回归只能处理线性数据“问题的手段,就是使用多项式回归对线性回归进行改进。这样的手法是机器学习研究者们从支持向量机中获得的:**支持向量机通过升维可以将非线性可分数据转化为线性可分,然后使用核函数在低维空间中进行计算,这是一种“高维呈现,低维解释”的思维。那我们为什么不能让线性回归使用类似于升维的转换,将数据由非线性转换为线性,从而为线性回归赋予处理非线性数据的能力呢?**当然可以。

接下来,我们就来看看线性模型中的升维工具:多项式变化。这是一种通过增加自变量上的次数,而将数据映射到高维空间的方法,只要我们设定一个自变量上的次数(大于1),就可以相应地获得数据投影在高次方的空间中的结果。这种方法可以非常容易地通过sklearn中的类PolynomialFeatures来实现。我们先来简单看看这个类是如何使用的。
![]()

import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import PolynomialFeatures
#如果原始数据是一维的
X = np.arange(1,4).reshape(-1,1)
X
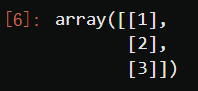
#二次多项式,参数degree控制多项式的次方
poly = PolynomialFeatures(degree=2) #degree等于几,最后一列就是X的几次方。
#接口transform直接调用
X_ = poly.fit_transform(X)
X_

X_.shape
![]()
#三次多项式
PolynomialFeatures(degree=3).fit_transform(X)
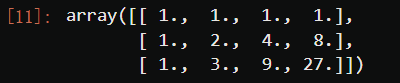
不难注意到,多项式变化后数据看起来不太一样了:首先,数据的特征(维度)增加了,这正符合我们希望的将数据转换到高维空间的愿望。其次,维度的增加是有一定的规律的。不难发现,如果我们本来的特征矩阵中只有一个特征x,而转换后我们得到:

这个规律在转换为二次多项式的时候同样适用。原本,我们的模型应该是形似y=ax+b的结构,而转换后我们的特征变化导致了模型的变化。根据我们在支持向量机中的经验,现在这个被投影到更高维空间中的数据在某个角度上看起来已经是一条直线了,于是我们可以继续使用线性回归来进行拟合。线性回归是会对每个特征拟合出权重w的,所以当我们拟合高维数据的时候,我们会得到下面的模型:

由此推断,假设多项式转化的次数是n,则数据会被转化成形如:

而拟合出的方程也可以被改写成:
![]()
这就是大家会在大多数数学和机器学习教材中会看到的**“多项式回归”**的表达式。
这个过程看起来非常简单,只不过是将原始的x上的次方增加,并且为这些次方项都加上权重w,然后增加一列所有次方为0的列作为截距乘数的x0,参数include_bias就是用来控制x0的生成的。
#三次多项式
PolynomialFeatures(degree=3).fit_transform(X)

#三次多项式,不带与截距项相乘的x0
PolynomialFeatures(degree=3,include_bias=False).fit_transform(X)

#为什么我们会希望不生成与截距相乘的x0呢?
#对于多项式回归来说,我们已经为线性回归准备好了x0,但是线性回归并不知道那一列是对应的x0。
xxx = PolynomialFeatures(degree=3).fit_transform(X)
xxx.shape
![]()
rnd = np.random.RandomState(42) #设置随机数种子
y = rnd.randn(3)
y
![]()
#生成了多少个系数?
LinearRegression().fit(xxx,y).coef_
![]()
#查看截距
LinearRegression().fit(xxx,y).intercept_
#查看截距时是有数值的1.2351711202036895
#线性回归并没有把多项式生成的x0当作是截距项。
![]()
#重要:
#发现问题了吗?
#线性回归并没有把多项式生成的x0当作是截距项
#所以我们可以选择:关闭多项式回归中的include_bias
#也可以选择:关闭线性回归中的fit_intercept
#生成了多少个系数?4个
#与x0对应相乘的系数就是我们的截距,即1.00596411就是我们的截距了,因为x0本身是等于1的。
LinearRegression(fit_intercept=False).fit(xxx,y).coef_
![]()
#查看截距
#发现为0,因为上面关闭线性回归中的fit_intercept了。
LinearRegression(fit_intercept=False).fit(xxx,y).intercept_
![]()
不过,这只是一维状况的表达,大多数时候我们的原始特征矩阵不可能会是一维的,至少也是二维以上,很多时候还可能存在上千个特征或者维度。现在我们来看看原始特征矩阵是二维的状况:
#原始特征矩阵是二维的状况
X = np.arange(6).reshape(3, 2)
X
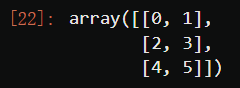
#尝试二次多项式,原始特征矩阵是二维
PolynomialFeatures(degree=2).fit_transform(X)
#第一列还是x0,是没有变化的。
#第二、三列是对应的原始的特征举证的第一列和第二列。
#第四列是第二列的平方。
#第五列是第二列与第三列相乘的结果。
#最后一列是第三列的平方。

很明显,上面一维的转换公式已经不适用了,但如果我们仔细看,是可以看出这样的规律的:

当原始特征为二维的时候,多项式的二次变化突然将特征增加到了六维,其中一维是常量(也就是截距)。当我们继续适用线性回归去拟合的时候,我们会得到的方程如下:
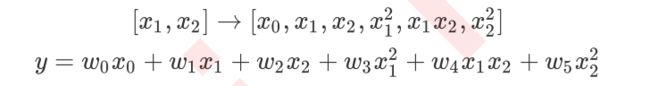
这个时候大家可能就会感觉到比较困惑了,怎么会出现这样的变化?如果想要总结这个规律,可以继续来尝试三次多项式:
#尝试三次多项式,原始特征矩阵是二维
PolynomialFeatures(degree=3).fit_transform(X)
#第一列:x0;
#第二列:x1;
#第三列:x2;
#第四列:x1^2;
#第五列:x1*x2
#第六列:x2^2
#第七列:x1^3
#第八列:(x1^2)*x2
#第九列:x1*x2^2
#第十列:x2^3

#不难发现:当我们进行多项式转换的时候,多项式会产出到最高次数为止的所有低高次项。
#在多项式回归中,我们可以规定是否产生平方或者立方项,其实如果我们只要求高次项的话,x1x2会是一个比x1^2更好的高次项,因为x1x2和x1之间的共线性会比x1^2与x1之间共线性好那么一点点(只是一点)。
#而我们多项式转化之后是需要使用线性回归模型来进行拟合的,就算机器学习中不是那么在意数据上的基本假设,但是太过分的共线性还是会影响到模型的拟合。
因此sklearn中存在着控制是否要生成平方和立方项的参数interaction_only,默认为False,以减少共线性。
来看这个参数是如何工作的:
PolynomialFeatures(degree=2).fit_transform(X)

PolynomialFeatures(degree=2,interaction_only=True).fit_transform(X)
#对比之下,当interaction_only为True的时候,只生成交互项:
#x1^2和x2^2就不在生成了,只有交互项了x1x2。其共线性就会少一点。

从之前的许多次尝试中我们可以看出,随着多项式的次数逐渐变高,特征矩阵会被转化得越来越复杂。
不仅是次数,当特征矩阵中的维度数(特征数)增加的时候,多项式同样会变得更加复杂:
#更高维度的原始特征矩阵
X = np.arange(9).reshape(3, 3)
X

PolynomialFeatures(degree=2).fit_transform(X)

PolynomialFeatures(degree=3).fit_transform(X)

X_ = PolynomialFeatures(degree=20).fit_transform(X)
X_.shape
![]()
如此,多项式变化对于数据会有怎样的影响就一目了然了:
随着原特征矩阵的维度上升,随着我们规定的最高次数的上升,数据会变得越来越复杂,维度越来越多,并且这种维度的增加并不能用太简单的数学公式表达出来。
因此,多项式回归没有固定的模型表达式,多项式回归的模型最终长什么样子是由数据和最高次数决定的,因此我们无法断言说某个数学表达式"就是多项式回归的数学表达"。
因此要求解多项式回归不是一件容易的事儿,感兴趣的大家可以自己去尝试看看用最小二乘法求解多项式回归。实际工作中是不会要我们自己去计算的。
接下来,我们就来看看多项式回归的根本作用:处理非线性问题。
5.3.2 多项式回归处理非线性问题
之前我们说过,是希望通过这种将数据投影到高维的方式来帮助我们解决非线性问题。那我们现在就来看一看多项式转化对模型造成了什么样的影响:
from sklearn.preprocessing import PolynomialFeatures as PF
from sklearn.linear_model import LinearRegression
import numpy as np
rnd = np.random.RandomState(42) #设置随机数种子
X = rnd.uniform(-3, 3, size=100)
y = np.sin(X) + rnd.normal(size=len(X)) / 3
#将X升维,准备好放入sklearn中,如果是一维,是会报错的。
#这里的X为训练数据。
X = X.reshape(-1,1)
#创建测试数据,均匀分布在训练集X的取值范围内的一千个点
#这里的line为测试数据
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
line.shape
![]()
#原始特征矩阵的拟合结果
LinearR = LinearRegression().fit(X, y)
#对训练数据的拟合
LinearR.score(X,y)
![]()
#对测试数据的拟合
LinearR.score(line,np.sin(line))
![]()
#多项式拟合,设定高次项
d=5
#进行高此项转换
poly = PF(degree=d)
#训练数据高次转换
X_ = poly.fit_transform(X)
#测试数据高次转换
line_ = poly.fit_transform(line)
#训练数据的拟合(高次转换后的特征矩阵X_)
LinearR_ = LinearRegression().fit(X_, y)
LinearR_.score(X_,y)
![]()
#测试数据的拟合
LinearR_.score(line_,np.sin(line))
#没有出现过拟合,测试数据集上的表现要比训练集上的表现好,证明模型没有过拟合。

如果我们将这个过程可视化:
import matplotlib.pyplot as plt
d=5
#和上面展示一致的建模流程
LinearR = LinearRegression().fit(X, y)
X_ = PF(degree=d).fit_transform(X)
LinearR_ = LinearRegression().fit(X_, y)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
line_ = PF(degree=d).fit_transform(line)
#放置画布
fig, ax1 = plt.subplots(1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green'
,label="linear regression")
ax1.plot(line, LinearR_.predict(line_), linewidth=2, color='red'
,label="Polynomial regression")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Linear Regression ordinary vs poly")
plt.tight_layout()
plt.show()
#来一起鼓掌,感叹多项式回归的神奇
#随后可以试试看较低和较高的次方会发生什么变化
#d=2
#d=20

#d=2时
import matplotlib.pyplot as plt
d=2
#和上面展示一致的建模流程
LinearR = LinearRegression().fit(X, y)
X_ = PF(degree=d).fit_transform(X)
LinearR_ = LinearRegression().fit(X_, y)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
line_ = PF(degree=d).fit_transform(line)
#放置画布
fig, ax1 = plt.subplots(1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green'
,label="linear regression")
ax1.plot(line, LinearR_.predict(line_), linewidth=2, color='red'
,label="Polynomial regression")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Linear Regression ordinary vs poly")
plt.tight_layout()
plt.show()
#来一起鼓掌,感叹多项式回归的神奇

#d=10时
import matplotlib.pyplot as plt
d=10
#和上面展示一致的建模流程
LinearR = LinearRegression().fit(X, y)
X_ = PF(degree=d).fit_transform(X)
LinearR_ = LinearRegression().fit(X_, y)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
line_ = PF(degree=d).fit_transform(line)
#放置画布
fig, ax1 = plt.subplots(1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green'
,label="linear regression")
ax1.plot(line, LinearR_.predict(line_), linewidth=2, color='red'
,label="Polynomial regression")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Linear Regression ordinary vs poly")
plt.tight_layout()
plt.show()
#来一起鼓掌,感叹多项式回归的神奇

#d=20时 过拟合
import matplotlib.pyplot as plt
d=20
#和上面展示一致的建模流程
LinearR = LinearRegression().fit(X, y)
X_ = PF(degree=d).fit_transform(X)
LinearR_ = LinearRegression().fit(X_, y)
line = np.linspace(-3, 3, 1000, endpoint=False).reshape(-1, 1)
line_ = PF(degree=d).fit_transform(line)
#放置画布
fig, ax1 = plt.subplots(1)
#将测试数据带入predict接口,获得模型的拟合效果并进行绘制
ax1.plot(line, LinearR.predict(line), linewidth=2, color='green'
,label="linear regression")
ax1.plot(line, LinearR_.predict(line_), linewidth=2, color='red'
,label="Polynomial regression")
#将原数据上的拟合绘制在图像上
ax1.plot(X[:, 0], y, 'o', c='k')
#其他图形选项
ax1.legend(loc="best")
ax1.set_ylabel("Regression output")
ax1.set_xlabel("Input feature")
ax1.set_title("Linear Regression ordinary vs poly")
plt.tight_layout()
plt.show()
#来一起鼓掌,感叹多项式回归的神奇

如何判断d什么时候最好,可以使用交叉验证。
从这里大家可以看出,多项式回归能够较好地拟合非线性数据,还不容易发生过拟合,可以说是保留了线性回归作为线性模型所带的“不容易过拟合”和“计算快速”的性质,同时又实现了优秀地拟合非线性数据。
到了这里,相信大家对于多项式回归的效果已经不再怀疑了。多项式回归非常迷人也非常神奇,因此一直以来都有各种各样围绕着多项式回归进行的讨论。
5.3.3 多项式回归的可解释性
线性回归是一个具有高解释性的模型,它能够对每个特征拟合出参数 以帮助我们理解每个特征对于标签的作用。当我们进行了多项式转换后,尽管我们还是形成形如线性回归的方程,但随着数据维度和多项式次数的上升,方程也变得异常复杂,我们可能无法一眼看出增维后的特征是由之前的什么特征组成的(之前我们都是肉眼看肉眼判断)。不过,多项式回归的可解释性依然是存在的,我们可以使用接口get_feature_names来调用生成的新特征矩阵的各个特征上的名称,以便帮助我们解释模型。来看下面的例子:
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
X = np.arange(9).reshape(3, 3)
X

#多项式变换成五次项
poly = PolynomialFeatures(degree=5).fit(X)
#重要接口get_feature_names
#属性是下画线结尾,而接口是()括号结尾
poly.get_feature_names()
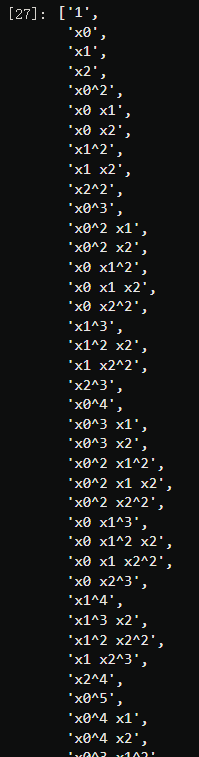

使用加利佛尼亚房价数据集给大家作为例子,当我们有标签名称的时候,可以直接在接口get_feature_names()中输入标签名称来查看新特征究竟是由原特征矩阵中的什么特征组成的:
#使用加利佛尼亚房价数据集给大家作为例子,当我们有标签名称的时候,可以直接在接口get_feature_names()中输入标签名称来查看新特征究竟是由原特征矩阵中的什么特征组成的:
from sklearn.datasets import fetch_california_housing as fch
import pandas as pd
housevalue = fch()
X = pd.DataFrame(housevalue.data)
y = housevalue.target
housevalue.feature_names #获取特征列名

X.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目"
,"平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"]
X.head()

poly = PolynomialFeatures(degree=2).fit(X,y)
poly.get_feature_names()

#将列名传入,可以查看到是哪些列(哪些特征)进行的组合,是以列名进行显示的。
poly.get_feature_names(X.columns)
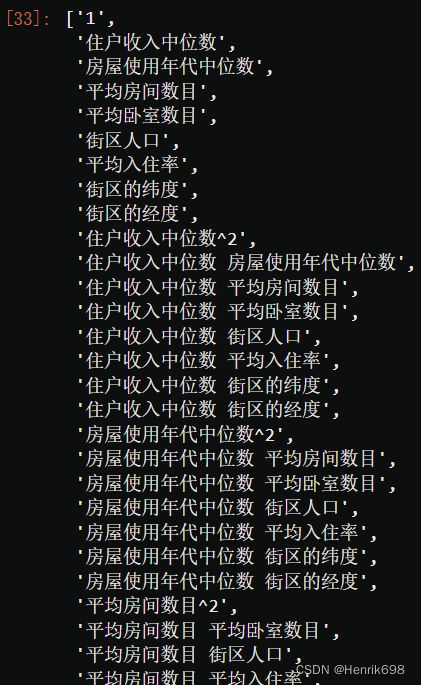
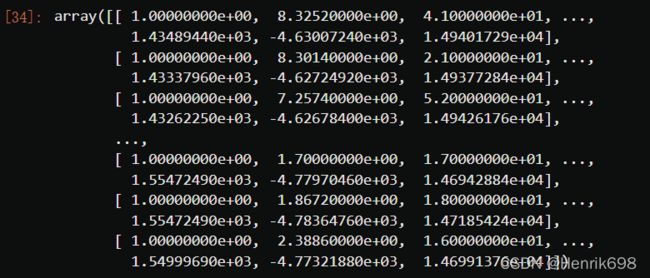
X_ = poly.transform(X)
X_
#在这之后,我们依然可以直接建立模型,使用多项式变换后最高次为2次的新特征矩阵带入到多元线性模型中,然后使用线性回归的coef_属性来查看什么特征对标签的影响最大
reg = LinearRegression().fit(X_,y)
reg
![]()
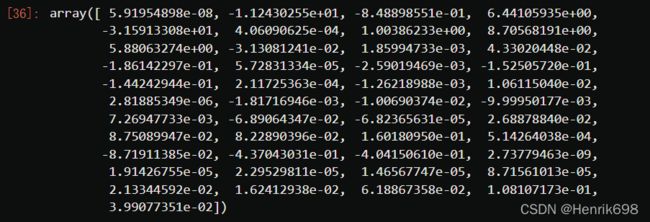
coef = reg.coef_
coef #查看每一列调整所对应的系数
[*zip(poly.get_feature_names(X.columns),reg.coef_)]
#获得了新特征矩阵中高次、一次特征所对应的系数
#这个系数表示这个特征所占的重要性,系数绝对值越大越重要。

#放到dataframe中进行排序
coeff = pd.DataFrame([poly.get_feature_names(X.columns),reg.coef_.tolist()]).T
coeff.columns = ["feature","coef"]
coeff.sort_values(by="coef") #按照系数排序,由最小系数到最大系数。
#系数的正负表示正相关还是负相关。


#顺便可以查看一下多项式变化之后,模型的拟合效果如何了
poly = PolynomialFeatures(degree=4).fit(X,y)
X_ = poly.transform(X)
#对原始数据进行建模
reg = LinearRegression().fit(X,y)
reg.score(X,y)
![]()
#使用标准化过后的数据来在线性回归中建模
from time import time
time0 = time()
reg_ = LinearRegression().fit(X_,y)
print("R2:{}".format(reg_.score(X_,y)))
print("time:{}".format(time()-time0))

#查看一下degree=4的情况下,poly.get_feature_names(X.columns)生成的特征中,那些特征才是最重要的:
poly = PolynomialFeatures(degree=4).fit(X,y)
poly.get_feature_names(X.columns) #通过这种方式我们可以进行特征创造,可以查看多项式变换后新特征矩阵的情况,每一列对应一个新特征
X_ = poly.transform(X)
#在这之后,我们依然可以直接使用线性模型对多项式变换后的新特征矩阵进行建模,然后使用线性回归的coef_属性来查看什么特征对标签的影响最大。
reg = LinearRegression().fit(X_,y)
coef = reg.coef_
coef #生成了对应新特征举证的系数
coeff = pd.DataFrame([poly.get_feature_names(X.columns),reg.coef_.tolist()]).T
coeff.columns = ['feature', 'coef']
coeff.sort_values(by = 'coef')

#假设使用其他模型?
#随机森林回归
from sklearn.ensemble import RandomForestRegressor as RFR
time0 = time()
print("R2:{}".format(RFR(n_estimators=100).fit(X,y).score(X,y)))
#非线性模型随机森林fit拟合的X是原始数据集,而不是多项式的,因为只有线性模型拟合才需要多项式的。
print("time:{}".format(time()-time0))

非线性模型比较慢,线性模型非常快,主要取决于对精度的要求,如果追求速度就选择线性模型。
5.3.4 多项式回归是线性还是非线性模型?
另一个围绕多项式回归的核心问题是,多项式回归是一个线性模型还是非线性模型呢?从我们之前对线性模型的定义来看,自变量上需要没有高次项才是线性模型,按照这个定义,在x上填上高次方的多项式回归肯定不是线性模型了。然而事情却没有这么简单。来看原始特征为二维,多项式次数为二次的多项式回归表达式:
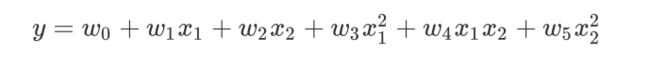
经过变化后的数据有六个特征,分别是:
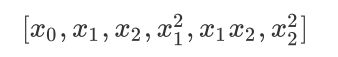
我们能够一眼看出从第四个特征开始,都是高次特征,而这些高次特征与y之间的关系必然不是线性的。但是我们也可以换一种方式来思考这个问题:假设我们不知道这些特征是由多项式变化改变来的,我们只是拿到了含有六个特征的任意数据,于是现在对于我们来说这六个特征就是:

我们通过检验发现,z1和z4,z5之间存在一定的共线性,z2也是如此,但是现实中的数据不太可能完全不相关,因此一部分的共线性是合理的,我们没有任何理由去联想到说,这个数据其实是由多项式变化来生成的。所以我们了线性回归来对数据进行拟合,然后得到了方程:
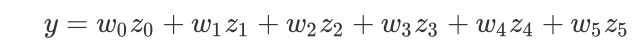
这妥妥的是一个线性方程没错:并不存在任何高次项,只要拟合结果不错,大概也没有人会在意这个六个特征的原始数据究竟是怎么来的,那多项式回归不就变成一个含有部分共线性的线性方程了么?在许多教材中,多项式回归被称为“线性回归的一种特殊情况”,这就是为什么许多人会产生混淆,多项式回归究竟是线性模型还是非线性模型呢?这就需要聊到我们对”线性模型“的狭义和广义定义了。
狭义线性模型 vs 广义线性模型
狭义线性模型:自变量上不能有高此项,自变量与标签之间不能存在非线性关系。
广义线性模型:只要标签与模型拟合出的参数之间的关系是线性的,模型就是线性的。这是说,只要生成的一系列w之间没有相乘或者相除的关系,我们就认为模型是线性的。
就多项式回归本身的性质来说,如果我们考虑狭义线性模型的定义,那它肯定是一种非线性模型没有错——否则如何能够处理非线性数据呢,并且在统计学中我们认为,特征之间若存在精确相关关系或高度相关关系,线性模型的估计就会被“扭曲“,从而失真或难以估计准确。多项式正是利用线性回归的这种”扭曲“,为线性模型赋予了处理非线性数据的能力。但如果我们考虑广义线性模型的定义,多项式回归就是一种线性模型,毕竟它的系数 之间也没有相乘或者相除。
另外,当Python在处理数据时,它并不知道这些特征是由多项式变化来的,它只注意到这些特征之间高度相关,然而既然你让我使用线性回归,那我就忠实执行命令,因此Python看待数据的方式是我们提到的第二种:并不了解数据之间的真实关系的建模。于是Python会为我们建立形如式子(2)的模型。这也证明了多项式回归是广义线性模型。所以,我们认为多项式回归是一种特殊的线性模型,不过要记得,它中间的特征包含了相当的共线性,如果处理线性数据,是会严重失误的。
总结一下,多项式回归通常被认为是非线性模型,但广义上它是一种特殊的线性模型,它能够帮助我们处理非线性数据,是线性回归的一种进化。大家要能够理解多项式回归的争议从哪里来,并且能够解释清楚观察多项式回归的不同角度,以避免混淆。
另外一个需要注意的点是,线性回归进行多项式变化后被称为多项式回归,但这并不代表多项式变化只能够与线性回归连用。在现实中,多项式变化疯狂增加数据维度的同时,也增加了过拟合的可能性,因此多项式变化多与能够处理过拟合的线性模型如岭回归,Lasso等来连用,与在线性回归上使用的效果是一致的,感兴趣的话大家可以自己尝试一下。
到这里,多项式回归就全部讲解完毕了。多项式回归主要是通过对自变量上的次方进行调整,来为线性回归赋予更多的学习能力,它的核心表现在提升模型在现有数据集上的表现。
6 结语
学习了多元线性回归,岭回归,Lasso和多项式回归总计四个算法,他们都是围绕着原始的线性回归进行的拓展和改进。其中岭回归和Lasso是为了解决多元线性回归中使用最小二乘法的各种限制,主要用途是消除多重共线性带来的影响并且做特征选择,而多项式回归解决了线性回归无法拟合非线性数据的明显缺点,核心作用是提升模型的表现。除此之外,本章还定义了多重共线性和各种线性相关的概念,并为大家补充了一些线性代数知识。回归算法属于原理简单,但操作困难的机器学习算法,在实践和理论上都还有很长的路可以走,希望大家继续探索,让线性回归大家族中的算法真正称为大家的武器。