DETR & 3DETR
DETR & 3DETR
- 0. Attention is all you need (NIPS 2017)
-
- Transformer Encoder
- Transformer Decoder
- 1. DE⫶TR: End-to-End Object Detection with Transformers - ECCV 2020
-
- ==== bipartite matching 二分匹配 ====
- ==== DETR architecture ====
- DETR transformer
- 2. An End-to-End Transformer Model for 3D Object Detection – ICCV 2021
-
- 3DETR Transformer
- 与2D的DETR对比
- 总结
0. Attention is all you need (NIPS 2017)
论文:https://arxiv.org/abs/1706.03762
代码:attention-is-all-you-need-pytorch
这篇论文的核心就是transformer结构,如下图。主要分成两个部分:encoder和decoder。
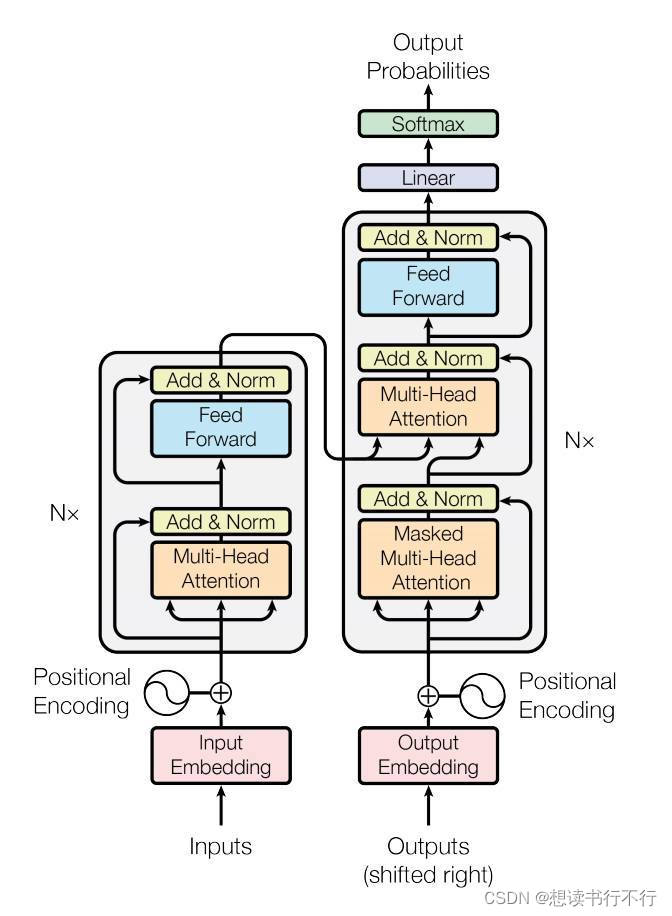
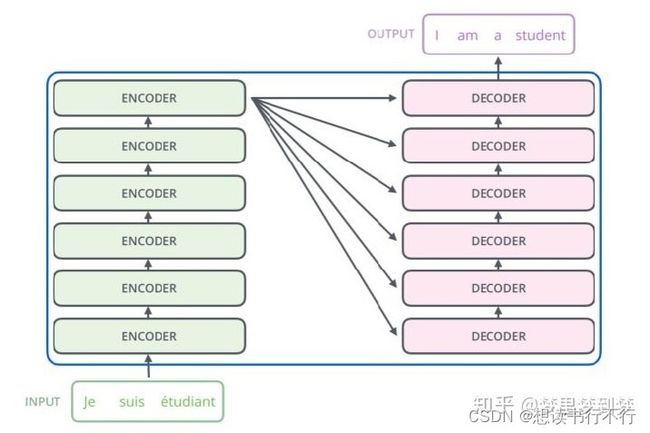
该结构的提出起初是用于机器翻译的,即某种语言,经过encoder后得到一种语义特征,然后再经过decoder从这种语义特征解码得到另一种语言。如下图(图自知乎:梦里梦到梦)。
Transformer Encoder
单层encoder的结构如下图所示。
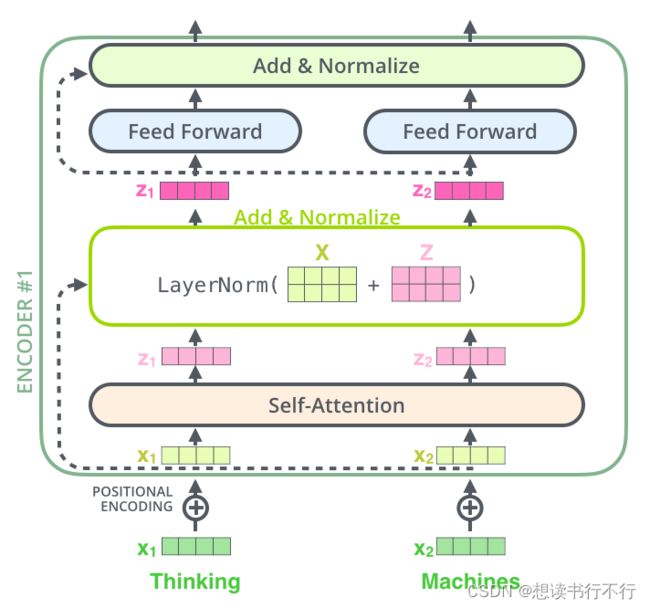
Encoder的输入是词向量和Positional encoding(二者相加之后送入第一个encoder),然后经过self-attention和LN层,最后经过一个FFN。同时可以看到单层encoder里还有两个skip connection。
最后,经过若干层encoder之后就能得到句子的编码。
(1) Positional Encoding:
因为词向量不包含其在句子中的顺序,因此位置编码的作用是为每个词向量提供位置信息。
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d i m ) P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d i m ) PE_{(pos,2i)}=\sin(pos/10000^{2i/dim})\\ PE_{(pos,2i+1)}=\cos(pos/10000^{2i/dim}) PE(pos,2i)=sin(pos/100002i/dim)PE(pos,2i+1)=cos(pos/100002i/dim)
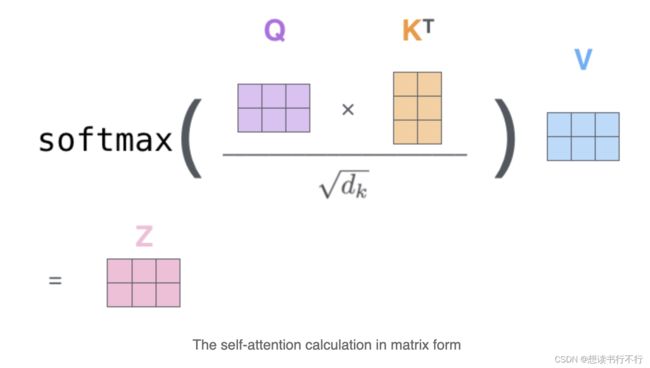
(2) Self-attention:
自注意力的矩阵形式如下图。
(3) FFN:
本质就是FC+ReLU+FC的组合。
Transformer Decoder
单层decoder的结构如下图右边所示。
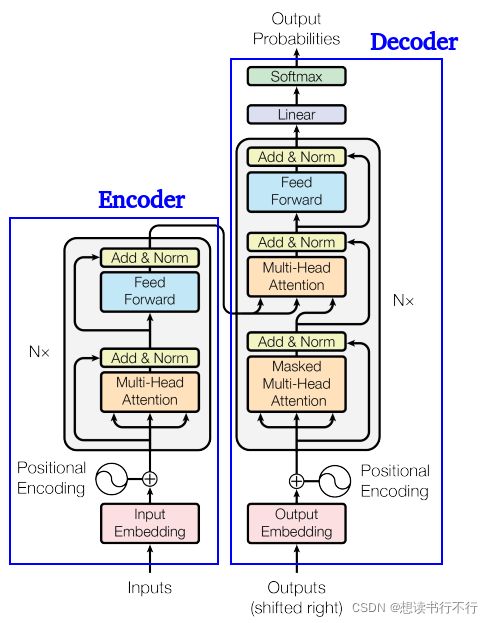
Decoder的第一个Attention与Encoder类似,只不过是带了一个与位置有关的Mask(预测第i个位置的时候,输入是前i-1个位置的embedding,后面位置的编码被Mask掉了)。-- self-attention
第二个Attention依然是同样的结构,区别在其输入不同:Q来自于Decoder,K和V来自于Encoder。这种做法大抵是为了结合Encoder和Decoder的信息。 – cross-attention
最后经过若干层decoder后,由线性层和softmax得到每一个单词的翻译结果。
本文重点不是注意力,所以介绍比较简略,关于注意力的介绍在各处都能检索得到
1. DE⫶TR: End-to-End Object Detection with Transformers - ECCV 2020
论文:DETR
代码:https://github.com/facebookresearch/detr(好像收敛起来会比较慢)
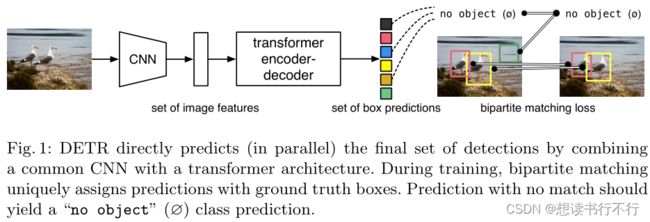
(1) 它基于transformer实现了端到端的目标检测。回顾以往的2d目标检测方法,大多都是模型预测输出一堆anchors,然后需要利用NMS将多余的anchors过滤掉,最终得到最精确的anchors。而这篇论文提出的方法与以往很多的方法不一样,它提出的方法将目标检测看作了一项direct set prediction问题。Direct set prediction问题,简单地说就是模型的预测输出就是最终结果,不需要NMS等操作,也不需要提前设置anchor的各种参数等。
(2) 这篇论文的创新点主要有两个:①bipartite matching,②transformer encoder-decoder architecture。
==== bipartite matching 二分匹配 ====
(1) 从图的描述可以看到,训练过程中是要求 predictions 和 ground truth boxes 是唯一的两两配对上的。即 gt 有 N 个boxes,预测就有 N 个boxes,这两个set里面的N个boxes是要求一对一、无重复地匹配上的。 N是一个超参数,要求远大于gt boxes的数量。
(2) 说到这里,首先遇到的问题就是gt boxes根本就没有 N 个boxes,如何匹配呢?关于这个问题,本文的解决方法是用一个新类别 “no object” 来填充gt,使其满足 N 个boxes的要求。这个 “no object”类其实就相当于的是以往的 “background”类。
(3) 第二个问题就是怎么确保两个集合里的boxes一对一、无重复地匹配呢?这是一个最优化问题,论文据此提出的待解决问题如下:

需要寻找一种配对方式,使得 L m a t c h ( y i , y σ ( i ) ^ ) {L}_{match}(y_i,\hat{y_{\sigma(i)}}) Lmatch(yi,yσ(i)^) 的值最小。这个最优化问题可以利用匈牙利算法解决。

==== DETR architecture ====
论文的第二个创新点就是DETR architecture:
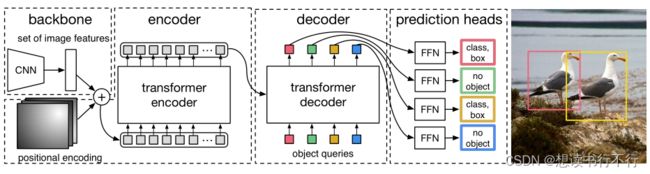
(1) 第一部分backbone:传入图片 ∈ ( 3 × 0 × 0 ) _{}\in^{(3×_0×_0)} ximage∈R(3×H0×W0),利用CNN提取得到 lower-resolution activation map ∈ ( × × ) \in ^{(\times \times )} f∈R(C×H×W)。 = 2048 , = 0 / 32 , = 0 / 32 =2048,=_0/32 ,=_0/32 C=2048,H=H0/32,W=W0/32 。需要注意的是,输入的image要求具有相同的尺寸,论文是通过填充0来实现。
(2) 第二部分transformer encoder:首先利用 1 × 1 1\times1 1×1卷积降低 f得通道数,得到一个新的feature map ∈ ( × × ) \in ^{(\times \times )} z∈R(d×H×W) 。因为encoder的输入是sequence,所以需要将 z 展成 × \times d×HW,并且添加上位置编码。
(3) 第三部分是transformer decoder:DETR中的decoder与之前vanilla transformer decoder的区别在于其能够同时输出 N 个object。由于decoder也是permutation-invariant(置换不变)的,因此decoder的这 N 个输入embedding必须要不同以输出不同的结果。原文“These input embeddings are learnt positional encoding that we refer to as object queries”,即 “object queries” 蕴含着位置的信息。与encoder一样,这些object queries会被加到每一个attention层的输入。
DETR transformer
DETR中的transformer结构如下图所示。

比较关键的就是decoder部分的object queries的理解。从上图的右边可以看到object queries是用于计算Q矩阵的,回顾attention机制,Q矩阵就相当于是提出问题。
从右边的multi-head attention module可以看到,K和V矩阵都是来自于encoder的输出,而K矩阵是相当于解答问题的一些关键信息,V矩阵则是encoder输入的另一种表达形式。
更具体地,结合原文“These input embeddings are learnt positional encodings that we refer to as object queries”,则object queries就是位置编码,而根据object queries得到的Q矩阵则可以认为是提出了这样的问题“某个位置上有什么东西?”。同时,这 N 个位置编码是需要进行训练学习的,训练的过程可以看作是提出更加准确、具体的问题。
俗话说,“提出问题比解决问题更困难”,通过提出更加细致的问题,更容易根据问题得到更加准确的预测结果。而且这提出的 N 个问题是互不相同的。根据Encoder输出得到的K矩阵则可以认为蕴含着某个位置上object的一些关键feature。
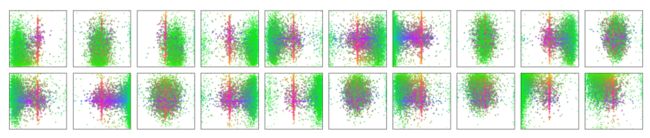
Decoder的预测输出的可视化如上图所示。
对“object queries”的理解:相当于 N 个人从不同的角度进行询问,训练过程就是训练这 N 个人从不同的角度去提出问题。从上图的第一幅图可以看到,points主要集中在左下角,且是绿色的,代表的是这个“人”不论输入的图像是什么,它只会在意图像的左下角的小物体。又如第二排的第二幅图,点在中心分布挺集中,颜色是红色和蓝色混杂,则代表这个“人”会更多在意图像的中心的大物体。其他例子同理。
可以设想, N 越大,则提出问题的“人”就更多,或者说提出了更多的问题,每个问题有一个答案,即信息,更多的信息,就意味着对全局信息的捕获更多了,从而就可以根据这些全局的信息提出更多细致的问题,从而得到更加准确的答案,即得到更加准确的预测。
原文中写到“Using self- and encoder-decoder attention over these embeddings, the model globally reasons about all objects together using pair-wise relations between them, while being able to use the whole image as context.” 论文结合了self-attention和encoder-decoder attention,用于全局地推理object之前的关系,从而充分地利用了整个图像的信息,以便于预测。
DETR是第一篇将transformer结构应用到图像目标检测的论文,对于object queries的理解尤为关键
2. An End-to-End Transformer Model for 3D Object Detection – ICCV 2021
论文:http://arxiv.org/abs/2109.08141
代码:https://github.com/facebookresearch/3detr
这一篇是facebook基于DETR,将transformer结构拓展到3d目标检测任务中。

(1) 论文提出了一个用于3d目标检测的transformer结构,只需要对vanilla transformer做少量的修改。而且通过实验证明,这个简单的transformer结构能够比那些专门针对3d任务,且调整好超参数的框架更好。
(2) Transformer中的自注意力操作是置换不变的,能够捕获long range的上下文语义信息,故很适合处理无序的点云数据。
(3) 具体方法:
① 接收point cloud,利用PointNet++中的方法对点云降采样, N个点降为′个。然后进行特征变换,得到 ′ × ′\times N′×d 特征,直接送入encoder,不需要提供位置编码,因为点云信息已经蕴含了xyz坐标信息。
② Encoder同样会输出一个 ′ × ′\times N′×d 张量,直接送入decoder。
③ 不同与DETR,此处的decoder接收的query非nn.Embedding生成,而是根据′个输入点产生的(non-parametric query embeddings),共个queries。 具体:利用farthest point sampling采样得到个点,然后进行Fourier位置编码,特征变换,得到query embedding。这样个点就会与个query embedding相对应。Query embedding表征着3d空间中接近objects的空间。
3DETR Transformer
 encoder和decoder的框架如上图所示。
encoder和decoder的框架如上图所示。
encoder方面接收降采样后的 N ′ × N^′\times N′×d 的点特征,输出为 N ′ × d N^′\times d N′×d的特征。
decoder方面首先会利用降采样后的 KaTeX parse error: Expected group after '^' at position 2: N^̲' 个点再随机采样得到 B B B个点,得到 B × d B\times d B×d的特征。经过MLP得到位置编码,再经过MLP得到query embeddings。
在decoder里,会有self-attention和cross-attention操作,最终输出 B × d B\times d B×d 的特征。
与2D的DETR对比
与2D的DETR相比,最大的区别是non-parametric queries。论文通过实验证明了,在3d点云中使用non-parametric queries的重要性。相比于2d图像网格,点云更为稀疏和不规则,因此很难学习到parametric queries(nn.Embeddings)。Non-parametric queries从点云中直接采样学习到,因此能更少受点云的不规则性影响。
3DETR相比与2D的DETR结构简单了不少,在了解了DETR中的object queries的含义之后理解起来也很得心应手。
总结
以上就是个人看过的transformer在目标检测中应用,DETR给我的印象比较深刻。