机器学习(一)读取csv数据进行分析1
0_引言
笔者的环境为:windows10,python3.8,pycharm 2021.3
测试用例csv数据下载链接:链接
需要安装的第三方库有:pandas,numpy
可使用清华源的在pycharm终端(或win+R)进行安装,命令如下(一次输入一条即可):
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple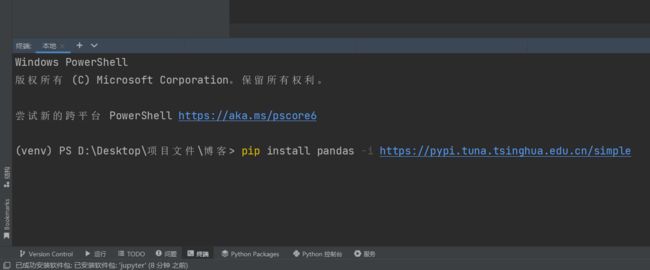
回车即可安装。
若pycharm下方没有终端,可在左上方视图中找到工具窗口,或者是Alt+F12,输入如上命令安装
1_基础操作
在python实践中,为了方便书写与理解,第三方库常常有约定俗成的缩写,例如pandas就会缩写为pd,numpy就会缩写为np,
import pandas as pd
import numpy as np在调用库的方法时,仅需使用 模块.方法()的格式即可调用,例如使用numpy格式化一个列表
List1 = [1,2,3,4]
NewList = np.array(List1)
print(List1)
print(NewList)输出如下,明显可以看到程序生效,数据格式发生改变(间隔符由逗号变为空格)

接下来对csv数据进行基本处理,首先我们要认识csv是什么
csv可以理解为间隔符变为逗号的txt,也可以理解为另一种形式的excel
如下图,在wps中它和excel基本上一摸一样(数据下载链接)
而在pycharm中,它是这样的(在pycharm中打开csv数据需要下载csv插件,教程链接)
我下载的是Rainbow CSV
我们使用pandas的方法读取csv数据
# 创建一个data变量存储数据
data = pd.read_csv('StudentPerformance.csv')
# 展示一下数据
print(data)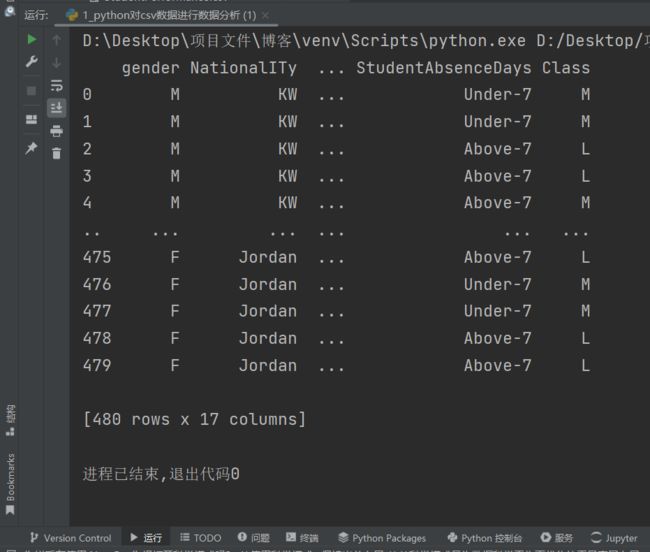
出现...是因为数据太长了,pycharm选择缩略中间部分
查看数据的一些基本属性
# 获取首行(标签)名称
labels = list(data.columns.values)
print(labels)
# 查看数据特征
print(data.dtypes)
# 列名
print(data.columns)
# 索引
print(data.index)
#查看特征空值信息,以及数据类型
print(data.info(verbose=True))
#输出数据集前n个样本,默认n=5
print(data.head(n=5))以下为部分运行结果图:
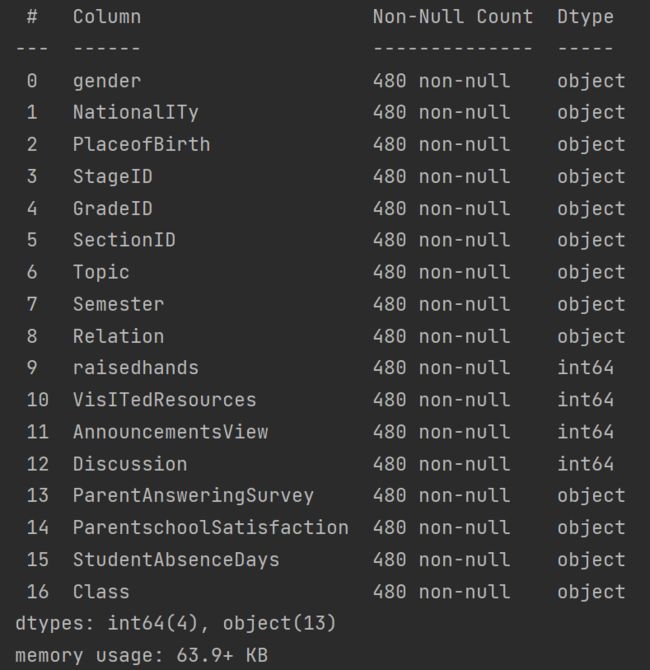
可以观察到数据既有object类型的字符也有int64类型的数字,对于object类型我们可以认为它是一个离散型的变量,对应于int64类型我们认为它是一个连续变量
# 数值型变量统计描述
# 下面的结果描述了有关数值型变量的简单统计值,包括非缺失观测的个数(count)、平均值(mean)、标准差(std)、最小值(min)、下四分位数(25%)、中位数(50%)、上四分位数(75%)和最大值(max)。
print(data.describe())
data.describe().to_csv('Feature_Of_Values.csv')
# 离散型变量统计描述
print(data.describe(include=['object']))
data.describe(include=['object']).to_csv('Feature_Of_Object.csv')
# 此处由于pycharm自动缩略,故将运行结果保存到同文件夹的csv中方便查看(使用to_csv方法)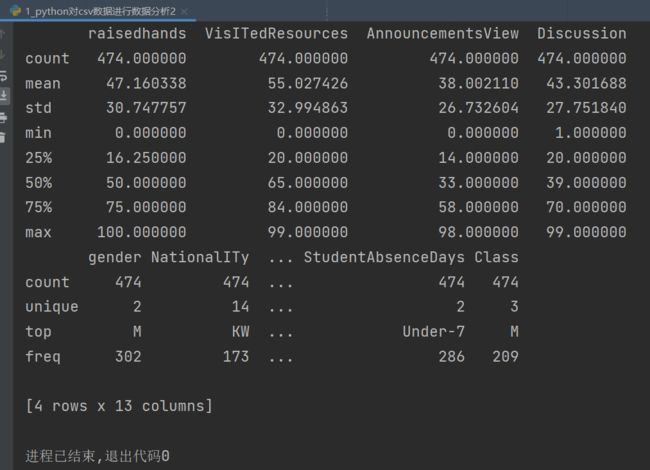
此外还有一些基础操作,详见:博客链接
2_可视化方法分析数据
注意!!!上文的缺值信息只能识别空格内没有值的空值,对于NAN,#VALUE!,Nan,None等一系列空值都无法识别,但是可以将其转换为空,再进行识别,
这里为了方便展示,我们首先导入可视化库
# 按照引言步骤安装这两个第三方库即可
import missingno as msno
import matplotlib.pyplot as plt
# 使用可视化方法查看缺失值在数据中的分布
msno.matrix(data, figsize=(14, 7), width_ratios=(13, 2), color=(0.25, 0.25, 0.5))
plt.show()运行后可以看到我的数据是完整的,但是其中却充斥着Nan,#VALUE!等字符

于是我将原数据的奇怪字符替换为空,并在原数据上保存改动
# 将原数据中的Nan,#VALUE!替换为空值,并将改动保存
data.replace('Nan', '', inplace=True)
data.replace('#VALUE!', '', inplace=True)
data.to_csv("StudentPerformance.csv")重新读取数据后,再次使用可视化方法进行观察
# 重新读取数据
data = pd.read_csv('StudentPerformance.csv')
# 使用可视化方法查看缺失值在数据中的分布
msno.matrix(data, figsize=(14, 7), width_ratios=(13, 2), color=(0.25, 0.25, 0.5))
plt.show()
可以看到,在数据柱中出现了空白部分,此处手动找到数据,整行删除,解决问题
也可以进行均值填补,机器学习方法填补等一系列方法,详见后续博客
接下来进行相关性分析(只能对数值型变量进行分析)
# 首先导入第三方库,方便可视化
import seaborn as sns
# 接下来设置字体,解决无法显示中文的问题
sns.set(font="Kaiti", style="ticks", font_scale=1.4)
matplotlib.rcParams['axes.unicode_minus'] = False
# 设置画布尺寸,18为长,8为宽
plt.figure(figsize=(18, 8))
sns.heatmap(data.corr(), cmap="YlGnBu", annot=True) # 绘制热力图
plt.title('相关性分析热力图')
plt.show()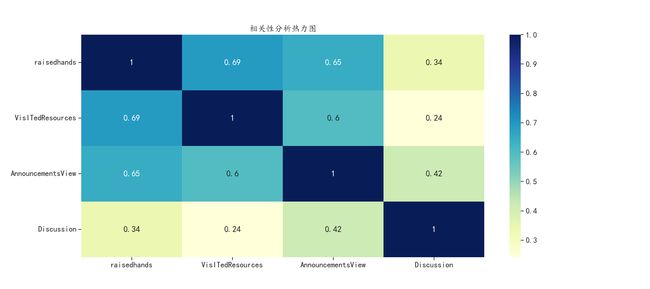
可以发现,在不同特征中确实存在着相关性,其中VisITedResources和raisedhands的相关性高达0.69,这是一个比较高的值了
接下来我们在不同数据坐标间进行比对,发现Class数据分布上的潜在特征
# 一张大图,其中包含n个子图,每个子图都是每个维度和其他某个维度的相关关系图
# 这其中主对角线上的图,则是每个维度的数据分布直方图,
# 以Class这个维度的数据为标准,来对各个数据点进行着色,
sns.pairplot(data, hue='Class')
plt.show()
可以明显观察到,Class为L的同学,在每个散点图中大部分处于左下角的位置,也就意味着当四个连续性变量数值均偏低的时,该同学的Class为L的概率较高
下一篇博客我们将对数据集的结构进行分析,同时进行进一步的数据可视化,为后续的机器学习模型构建打下良好基础