ggplot2 多个柱状图比较_2. 主成分分析(PCA)与ggplot2绘图
看了大部分的《Numerical Ecology with R》,并参考了赖江山老师的翻译版,可以说依然是一头雾水。
着实难啃,因为其中涉及的术语极多,而且杂乱的各种分析方法看过之后也没有清楚的认识。
现在陆续附上个人总结的PCA、NMDS、CCA和RDA分析与ggplot2表达的部分代码。当然在使用时还需要对ggplot2表达进行优化。
总的来说,由多个处理(或样本、样方)和多个解释变量组成的多维矩阵需要在某个方向来展示趋势。
其在ggplot2中的表达也是将其排序的结果提取出来,主要是前两个轴,实际上这就是前两个轴的坐标数据(在PCA中叫PC1和PC2值,在作图时其实就是x值和y值啦),然后在ggplot2中表达。
实在时间有限,仅做代码展示。
对于PCA
一、PCA分析
#分析使用vegan包
library(vegan)
#针对标签问题使用ggrepel包
library(ggrepel)
library(ggplot2)
#设置工作路径,根据个人需要修改载入数据的位置!!!
setwd("C:/Users/93179/Desktop/")
#采用csv格式是因为读取数据时,首行和首列的名字比较容易读取为行列名
#读取数据,命名为env
(env <- read.csv("C:/Users/93179/Desktop/1.csv",header = T,row.names = 1))
#本文数据是随手编的,所以不一定有好的结果,仅做过程展示!
#使用vegan包的rda()函数,进行基于相关性矩阵的PCA分析;scale = TRUE表示变量的标准化
env.pca <- rda(env, scale = TRUE)
#查看PCA结果,并将结果赋值给pca_result
pca_result <- summary(env.pca)
#查看特征根
(ev <- env.pca$CA$eig)
#查看断棍模型
screeplot(env.pca, bstick = TRUE, npcs = length(env.pca$CA$eig))
二、ggplot2作图准备(也就是提取坐标值)
#提取响应变量(或者叫解释变量、环境变量)的坐标数据,乘以5是使图美观,不影响分析
xy <- as.data.frame(pca_result$species[,1:2])*5
#提取样方(或者叫处理或编号之类的)的坐标
yf<- as.data.frame(pca_result$sites[,1:2])
#注意:在PCA结果中,响应变量结果的变量名是species!!!样方是sites!!!必须严格对应!!!
三、ggplot2作图
#本文数据是随手编的,所以不一定有好的结果,仅做过程展示!
样式1. 不显示样方点信息,只显示解释变量信息
ggplot() +
geom_segment(data = xy,aes(x = 0, y = 0, xend = PC1, yend = PC2),
arrow = arrow(angle=22.5,length = unit(0.35,"cm"),
type = "closed"),linetype=1, size=0.6,colour = "red")+
geom_text_repel(data = xy, aes(PC1,PC2,label=row.names(xy)))+
#可以手动添加前两轴的解释度
labs(x="PCA1",y="PCA2")+
geom_hline(yintercept=0,linetype = 3,size = 1) +
geom_vline(xintercept=0,linetype = 3,size = 1)+
theme_bw()+theme(panel.grid=element_blank())

样式2. 显示样方点、解释变量,但样方点仅显示字符
ggplot() +
geom_text_repel(data = yf, aes(PC1,PC2,label=row.names(yf)),size=4) +
geom_segment(data = xy,aes(x = 0, y = 0, xend = PC1, yend = PC2),
arrow = arrow(angle=22.5,length = unit(0.35,"cm"),
type = "closed"),linetype=1, size=0.6,colour = "red")+
geom_text_repel(data = xy, aes(PC1,PC2,label=row.names(xy)))+
#可以手动添加前两轴的解释度
labs(x="PCA1",y="PCA2")+
geom_hline(yintercept=0,linetype = 3,size = 1) +
geom_vline(xintercept=0,linetype = 3,size = 1)+
theme_bw() +
theme(panel.grid=element_blank())

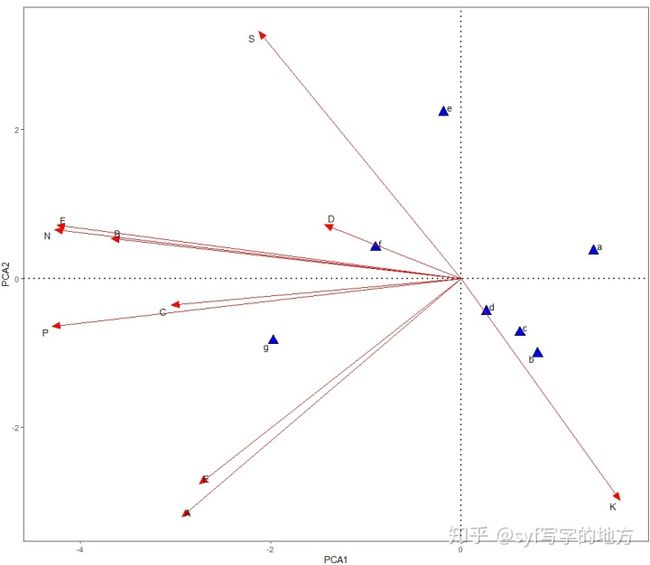
样式3. 显示样方点、解释变量,同时样方点显示为字符和图形标识
ggplot() +
geom_text_repel(data = yf, aes(PC1, PC2, label=row.names(yf)), size=4) +
geom_point(data = yf,aes(x = PC1,y = PC2), size=4, shape = 24, fill = "blue", colour = "black") +
geom_segment(data = xy,aes(x = 0, y = 0, xend = PC1, yend = PC2),
arrow = arrow(angle=22.5,length = unit(0.35,"cm"),
type = "closed"),linetype=1, size=0.6,colour = "red")+
geom_text_repel(data = xy, aes(PC1, PC2, label=row.names(xy)))+
#可以手动添加前两轴的解释度
labs(x="PCA1",y="PCA2")+
geom_hline(yintercept=0,linetype = 3,size = 1) +
geom_vline(xintercept=0,linetype = 3,size = 1) +
theme_bw() +
theme(panel.grid=element_blank())
四、总结
做这种PCA的过程很简单,但数量生态学的书是看不懂的。
主要流程是:做分析,然后提取每个对象的前两轴的坐标,然后再将坐标信息在ggplot2中表达。