论文阅读《Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector》
Attention-RPN 和 Multi-Relation Detector
提出了一种包含带注意力机制的 RPN、Multi-Relation Detector 和对比训练策略通过度量 support 和 query 相似性来解决小样本问题的方法,同时很好地抑制了背景。训练完成的网络可以直接泛化到新类别上,而不需要在新类别上进行微调。具体来说,该方法利用权重共享网络,探索对象对(object pair)在 Multi-Relation Detector 的匹配关系,实验证明带注意力机制的 RPN 可以提高 proposal 的质量,而 multi-relation detector module 可以很好的过滤掉负样本和背景。该模型在 MS COCO 和 ImageNet 的小样本任务上达到了 SOTA。
真实世界的物体照片中的光照、形状和纹理等的巨大变化,是小样本学习的一个挑战。传统方法中(如 Faster Rcnn)常常检测不出新颖类别,文章认为是 RPN 中对新类别正样本 bounding box 的不合适得分引起的对该新类别检测困难。
整理了一个小样本学习的数据集,包含1000个类别,每个类别的图片不多,训练集与验证集没有交集。后面实验证明了类别多的数据集(也即文章中提出的数据集)比类别少的大数据集(如 COCO)对模型泛化能力的提升更大,使用该数据集训练后的模型在其他数据集上的取得了更好的泛化效果,在不进行微调的情况下。
目前的小样本学习
目前的大多数工作都是在图像分类任务上,而目标检测、图像分割和行为预测任务上的解决方案很少。可大致分为:度量学习(Prototypical network,这篇文章的方法也是启发于度量学习和匹配网络),元学习(Siamese network),匹配网络(Matching network、Relation network),图神经网络(Graph Neural Network)和参数优化(MAML)。
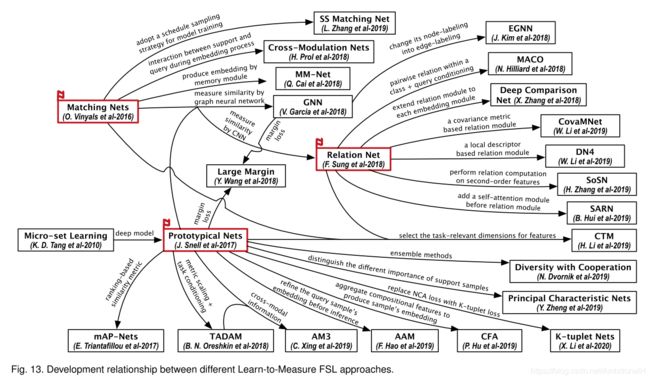
目前的一些小样本目标检测方法:
- 《Few-example object detection with model communication》,对无标签数据交替优化多个模型。
- 《Lstd: A low-shot transfer detector for object detection》、《Few-shot object detection via feature reweighting》、《Repmet: Representative-based metric learning for classification and few-shot object detection》和《Meta r-cnn : Towards general solver for instance-level low-shot learning》,这四种方法学习了特定类别的度量并且对新类别需要进行微调。
A Highly-Diverse Few-Shot Object Detection Dataset
高多样性的数据集对小样本学习的效果的好坏与否至关重要,现有的数据集类别太少,不利于小样本问题。本文提出的数据集 FSOD 以现有的大型数据集为基础制作而成,如 ImageNet。也有些问题,一些具有相同语义的对象在不同的数据集中采用不同的标注,标注不准确,存在错误的框。最重要的是训练和测试集中的类别有交集,这使得不能很好的检验模型泛化性能。

FSOD 里非叶节点的类别采用 MS COCO 的类别,将 ImageNet(红色叶节点)和 Open Image(绿色叶节点)数据集的类别归到这20个类别下作为叶节点。其中训练集和测试集类别数分别为800和200,其中531个类别来自 ImageNet 数据集,469个类别来自 Open Image 数据集。总共包含66000张图片和182000个 bounding box。其详细的统计如下:
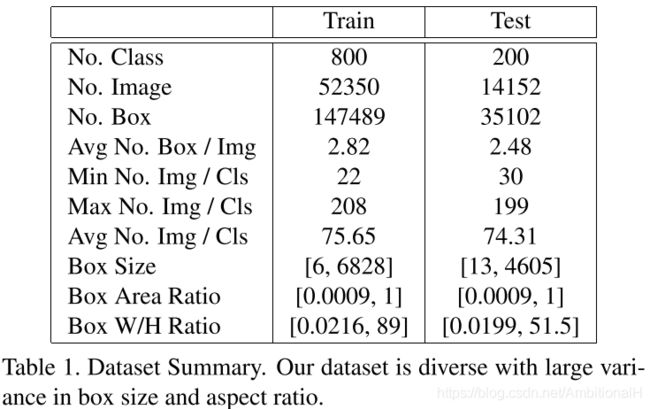
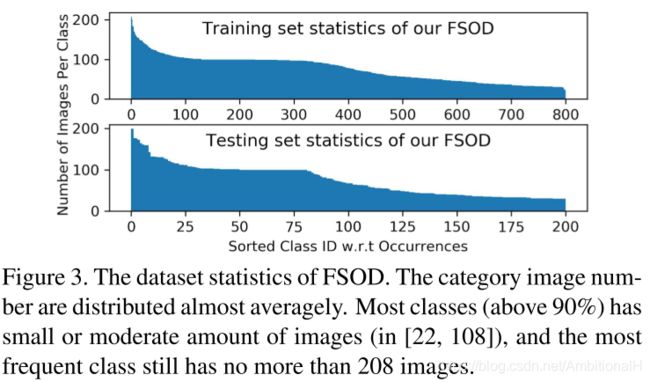
如此制作的数据集类别间差异很大,bounding box 的大小和长宽比差异也很大,同时测试集类别与训练集类别没有交叉,这些都对模型的泛化能力提出了挑战。
Deep Attentioned Few-Shot Detection
问题定义为一张带有类别 c 标注的 Support image(Sc)和一张可能包含该类别的 Query image(Qc),任务是找出 Qc 中所有为类别 c 的物体。Support set 中包含 N 个类别,每个类别包含 K 张图片的话,此问题定义为 N-way K-shot learning。
Attention-Based Region Proposal Network

提出了一种新的注意网络,在 RPN 模块和检测器上学习 Support 和 Query 之间的匹配关系。网络结构如上图,构建了一个由多个分支组成的权重共享框架,其中一个分支用于查询集,其他分支用于支持集(图中只列出了含一张 Sc 的情况),图中黄色框内(Weight Shared Network)的 Query 分支是 Faster Rcnn 的特征提取网络。利用这个框架来训练 Support 特征和 Query 特征之间的匹配关系,以使网络学习相同类别之间的通用知识。
RPN 网络应该不仅能够判断 proposal 内是否包含物体,而且应该能够过滤掉不属于 Support 类别的 proposal,然而没有 Sc 的话 RPN 网络是做不到的,它会输出所有包含 proposal 的边框,从而加重的后面网络分类的负担。本文提出 Attention RPN(上图蓝色框内,具体结构如下图)来解决这个问题,

具体的做法是在通道域计算 Sc 特征图和 Qc 特征图的相似度,原因是全局特征能更好的提供一个物体的先验信息用来分类。
这里借鉴的了 Siamese-fc 的思想,这是将 Siamese 结构用于目标追踪的算法,并且目前在目标追踪领域也算是占据非常重要的地位。在了解之后再来看这个结构就能一目了然,网上有许多关于 Siamese-fc 的博客,简单说一下核心思想,就是把 support image 想象成一个巨大的卷积核,在 query image 上进行卷积。在 query image 上与 support image 长得像的区域,激活值就会很高,这样就很容易找到 query image 上的高度疑似区域。同样,这里也是采取了这样一个思想,并且采用了 SiamRPN++ 中的 depth-wise 思想,即将 X 这个大卷积核的大小变为1(这个1是作者做实验得出的)。这里只需要把这一步当成用一个大卷积核 X 在 Y 上做 depth-wise 卷积。
Sc 特征图中每个通道域取均值作为该通道域的卷积核在 Qc 特征图上滑动的到图中的 G,公式如下:
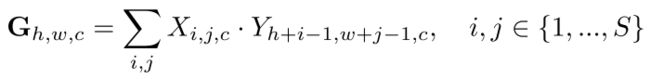
X 为从 Sc 得到的卷积核,Y 为 Qc 的特征,文中 S 取1,通过计算得到 G。G 再通过3*3卷积、分类层和 box 回归层得到 Attention RPN。取出其中的 proposal 对 Qc 特征图进行 RoI Pooling,即图中的这一步操作:

为了证明 Attention RPN 的效果,比较了在 IoU=0.5 设定下 RPN 和 attention RPN 两种方法的产生 proposal 与 gt 的 IoU 最大的100个 proposal 的 recall。0.9130 vs. 0.8804,要优于传统 RPN。
另一种评价 proposal 的方法:
We then evaluate the average best overlap ratio (ABO [62]) across ground truth boxes for these two RPNs. The ABO of atten- tion RPN is 0.7282 while the same metric of regular RPN is 0.7127. These results indicate that the attention RPN can generate more high-quality proposals.
Multi-Relation Detector
在 Faster Rcnn 中,RPN 之后要进行 RoI Pooling,在这之后就是 Fast R-CNN 的分类器和 RoI 边框修正训练。分类器主要是分这个提取的 RoI 具体是什么类别(人,车,马等),一共 C+1 类(包含一类背景)。RoI 边框修正和 RPN 中的 anchor 边框修正原理一样,同样也是 SmoothL1 Loss。值得注意的是,RoI 边框修正也是对于非背景的 RoI 进行修正,对于类别标签为背景的 RoI,则不进行 RoI 边框修正的参数训练。
而本文提出的方法希望一个分类器有很强的判别能力来区分不同的类别,也就是 multi-relation detector(对应 Figure 4 中的橙黄色方框)。如下图:

一共包含三个关系模块,Global Relation 学习全局匹配的深度嵌入,Local Relation 学习 Sc proposal 和 Qc proposal 之间的像素级和深度级的关联,Patch Relation 学习 patch(即遍历)匹配的深度非线性度量。三个模块并行计算相似度,也就是三个结构分别会对每一个 Qc proposal 计算出一个相似度,将三个置信度结合起来。作者没说怎么结合,这里理解为简单的相加取平均,就得到了这个 Qc proposal 最终的置信度。这时候我们就可以通过阈值法,留下置信度阈值之上的框从而得到最终的预测结果。这三个模块的具体实现:
- Global Relation
先假设 Qc proposal 的大小固定为7x7xC,C是通道数。这时候我们有一个 Qc proposal,一个 Sc proposal(这里只以一个为例)。我们首先将这两个 proposal 做 concatenate,这时候就变成了7x7x2C。再经过一次全局平均池化,变成1x1x2C,相当于获取了全局信息。这时候就可以通过一系列全连接操作输出得到一个数值(从2C降维到1),该数值就是两ROI特征图相似性。
- Local Relation
先对两个 proposal 分别用 weight-share 的1x1卷积进行 channel-wise 操作,然后再进行类似于Attention RPN 的操作。如 Fig.5 所示,区别在于 Sc proposal 不需要全局池化到1x1,而是直接以7x7的大小作为一个卷积核在 Qc proposal 上进行 channel-wise 卷积,变成1x1xC,最后同样使用fc层得到预测相似度。
- Patch Relation
先将两个 proposal 进行 concatenate,变成7x7x2C,然后经过 Fig.8 所示的网络结构。图中的卷积层后面都会跟一个RELU用来获得非线性,并且 pooling 和卷积层都是 stride=1 以及 padding=0。在经过这些操作之后, proposal 的大小会变为1x1x2C,这时候后面接一个全连接层用来获得相似度。除了相似度之外,还并行接了一个全连接层,作者说是产生 bounding box predictions,这里理解为候选框回归。
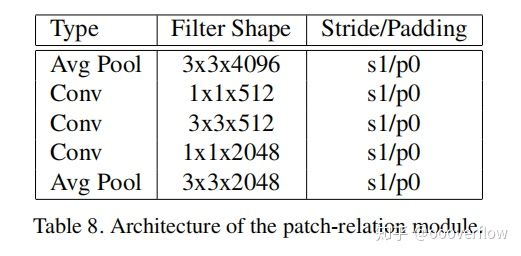
实验表明,这三个关系模块可以相互补充,产生更好的性能。同时对这三种模块进行了 ablation studies,结果如下:
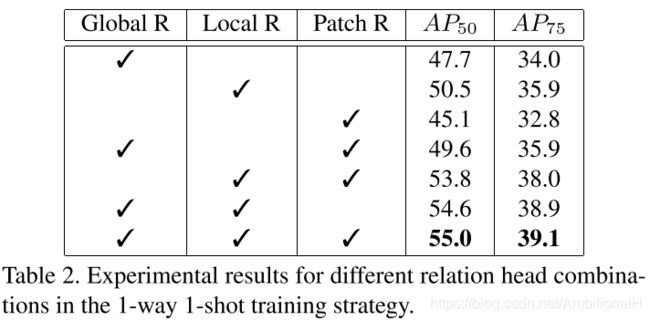
Patch Relation 效果最差,尽管它试图学习最复杂的关系,这也是作者认为它效果最差的原因。从图中可以看到组合三种关系模块得到的精度最高,这表明所提出的三个关系模块是互补的,可以更好地区分目标与非匹配的对象。
Two-way Contrastive Training Strategy
一个好的模型不仅要匹配相同的类别对象,还要区分不同的类别。基于这个动机提出了该策略,也就是在输入 Sc 的同时也要输入不包含类别 c 的 Support image(Sn,包含类别 n 的 Support image)。在(Sc,Qc,Sn)中,只有类别 c 被认为是前景,其余类别都是背景。因此在训练阶段,模型不仅学会了匹配相同的类别(Sc,Qc),也学会区分不同的类别(Sn,Qc)。

同样碰到了负样本数目过多的问题,这里将 Sc 和 Sn 划分为 Sp(positive Support)和 Sn(negative Support),将 Qc 划分为 Pf(foreground Proposal)和 Pb(background Proposal)。控制(Pf,Sp)、(Pb,Sp)和(P,Sn)的比例为1:2:1,根据匹配得分来选取这些图片对,选取对应得分最高的 N:2N:N 张图片。
输入一张 Sn 称为 2-way 训练策略,文中比较了不同的训练策略,证明只有一个 negative support 就足够:

图中的实验结果也证明了 Attention RPN 的效果要优于传统 RPN。
实验结果
与不同数据集上的 SOTA 方案进行了比较。本文的模型采用预训练好的 ResNet50 模型,第二列是用来训练的数据集,第三列是微调的数据集。
ImageNet Detection dataset

可以看到在 FSOD 上训练的模型不用微调就已经达到了 SOTA。
MS COCO dataset
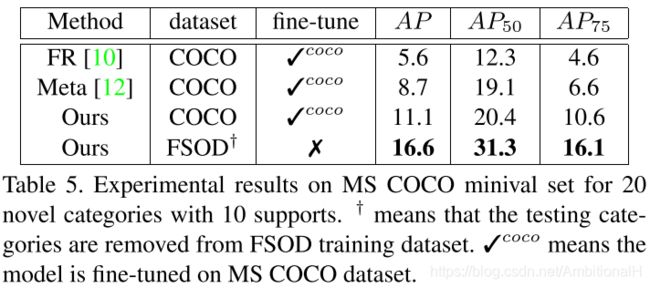
与 Feature Reweighting 和 Meta R-CNN 作比较,可以看出学习通用的匹配关系比尝试学习特定类别的嵌入效果更好。
结论
文章还列举了该模型未来可能的两个应用案例:给定相册或者一段视频,标注出其中出现的目标物体。第二个案例是可以用在自动驾驶任务里的车辆检测上。讨论了数据集包含多类别和多实例哪个对小样本任务更有利,与 COCO 数据集做了对比实验:
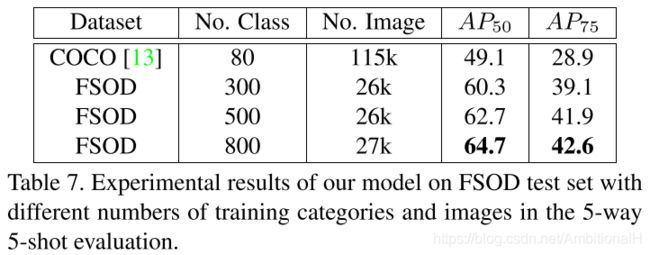
证明数据集包含数量有限的类别和每类别内过多的图像实际上会阻碍 few-shot 任务,而包含类别数多的数据集则有利于这项任务。
附加
-
目标检测 faster rcnn、SSD 和 yolo 系列的正负样本标定:参考https://blog.csdn.net/xiaotian127/article/details/104661466
-
与 FSOD 类似的数据集 tieredImageNet:参考https://blog.csdn.net/Dream_xd/article/details/105579392
-
Depthwise Convolution:不同于常规卷积操作,Depthwise Convolution 的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。上面所提到的常规卷积每个卷积核是同时操作输入图片的每个通道。Depthwise Convolution 完成后的 Feature map 数量与输入层的通道数相同,无法扩展 Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的 feature 信息。因此需要 Pointwise Convolution 来将这些 Feature map 进行组合生成新的 Feature map。
 Depthwise Convolution
Depthwise Convolution