大数据--毕业生
前序
本篇文章适合初级大数据开发,初级java开发,如果文章有错误,请及时指出
常见基础问题
//之前已经背过许多题了,这里都是默写,根据我的理解,所以有时候可能不对,望指正。
hadoop
hdfs的写流程:
首先由三部分组成 namenode ,datenode,client。client通过RPC连接namenode通信,namenode检查,是否有上传权限和指定目录,namenode返回给client一个可以上传的信息,client将文件切分为128M的块,向namenode申请第一个块存放的位置,namenode根据拓扑排序(一般是存放三份,一份存本地A,一份存同一个机架B,第三份存C)返回给client存放数据的datanode位置,client与第一个datanode的位置连接,建立pipeline,client开始发送第一个block块,以packet(64KB)为单位,A收到第一个Packet 给B传,B给C传。A传完之后进入等待第一个datanode的节点返回的ack,第一个block传完之后,第二第三继续重复。
hdfs的读流程:
client向namenode申请,namenode看权限和是否有文件,如果有返回给client第一个block块的datanode位置(排序后的) ,这个底层是用了socket Stream(fsDatainputStream),每一个block传送完成后都会checksum验证。最终block会合并成一个完整的文件。
hdfs读取文件时,损坏了咋办
每一个块读取后都会进行checksum验证,坏的话就传一个新的block呗
HDFS在上传文件的时候,如果其中一个DataNode突然挂掉了怎么办
pipeline是一个双向的,如果dataNode挂了,ack会没有,client会通知namenode,namenode会通知其他的datanode去复制副本,然后对这个datanode做下线处理
namenode启动时会进行哪些处理
读取fsimage和edits文件,并合并成新的fsimage 创建新的edits,启动datanode
Secondary NameNode工作机制
协助完成edits和fsiimage的合并。但是不能作为namenode的高可用,因为fsimage中的信息是不全的,edits正在编译的并没有合并到一块。高可用还得HadoopHA
NameNodeHA
元数据信息同步在HA方案中采用的是“共享存储”。每次写文件时,需要将日志同步写入共享存储,这个步奏才算成功,然后备份节点定期从共享存储同步日志,以便进行主备切换。
小文件过多危害
namenode是存储元数据信息的,顶不住啊,解决方法,在客户端上传时,合并小文件。
MapReduce
map阶段:程序提交后,inputFile通过split切分,为多个block块,然后record根据一行一行读取,执行map函数,Mapper逻辑结束之后,将mapper的每条结果通过context.write进行collect数据收集,在collect中,对其进行hash分区进去环形缓冲区(100M,80M时开始进行按key快排,溢写),每次溢写会在磁盘上生成一个临时文件,会把这些溢写文件合并一下。
Reduce 阶段: 1 copy拉取数据创建copy线程通过http拉取,拉取时partition的分区会指定mapTask属于哪个reduce,2reduce拉取过后进行归并排序并且合并 3把key相同的进行reduce.
shuffle阶段: 就是把map产生输出到reduce排序好。
再写MR时,什么情况下可以使用规约
combiner,就是在reduce前可以进行合并一下,适用于求和类而不是平均值,如果reduce的输入参数和输出参数类型是一样的,则规约的类可以使用reduce类。
yarn架构和工作原理
ResourceManager 主要分配资源和管理AM,
ApplicationMaster 一个任务对应一个AM,主要是与RM交互得到资源(container)
NodeManager NM是每个节点的资源和任务管理器。
hive
内部表和外部表的区别
external 修饰
外部表数据存储在hdfs上,删除时只删除了元数据
order by和sort by
order by 会对输入做全局排序,因为只有一个reduce
sort by这个局部排序因为多个reducer
数据倾斜
hive小文件过多
解决方法:
1 concatenate
#对于非分区表
alter table A concatenate;
#对于分区表
alter table B partition(day=20220217) concatenate;
减少map的数量
减少reduce的数量
spark
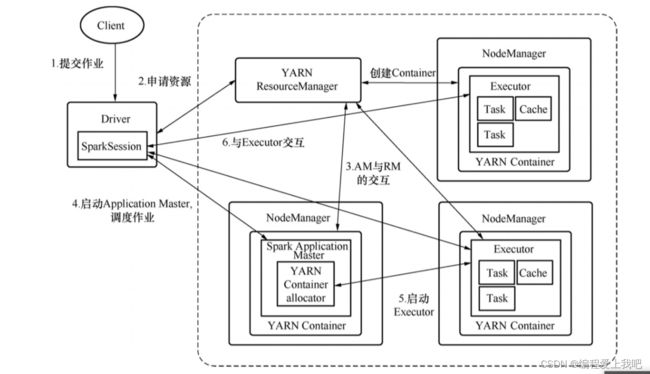
运行流程
yarn模式
首先 1 driver向RM申请资源,RM给一个AM,AM在调动NM,一个AM对应一个程序,全程driver不参与,
 ** Spark中RDD机制**
** Spark中RDD机制**
弹性分布式数据集 在逻辑上是hdfs文件,抽象上是数据集合。
reduceByKey和groupByKey
reduceByKey,会在map结束后进行一个combiner 类似于mapreduce那个
groupByKey ,他会把value的值聚合形成一个序列,此操作发生在reduce端。所以势必会将所有的数据通过网络进行传输
进行大量数据的 reduce 操作时候建议使用 reduceByKey。不仅可以提高速度,还可以防止使用 groupByKey 造成的内存溢出问题。
Spark中的数据倾斜
1 分拆发生数据倾斜的记录,分成几个部分进行,然后合并 join 后的结果
2 两阶段聚合
3 自定义partioner
Kafka
为什么要用
我总结为4字:容易缓解
容—冗余:可以一对多,一个生产者,可以被多个topic
易–异步通信
缓–缓冲和削峰
解–解耦
kafka速度快的原因
1 顺序写入
2 零拷贝 ,就是说之前produce是先写入操作系统的页缓存,然后写入磁盘的,要想读还得写出来,现在直接从页缓存开始读了。
3 他把topic切分为多个partition,这样不仅可以快速定位message和response的,而且删除也可方便
4 页缓存技术:基于操作系统的页缓存来实现文件写入的,就是先写到内存后写到磁盘。
kafka数据怎么保障不丢失
producer consumer broker
生产方,设置ack应答机制0 1 -1
consumer, offset
broker 如果宕机了,会有副本顶替
kafka的数据offset读取流程
zk中记录了topic的partition和partion的leader的相关信息
consumer从zk获取leader将offset发给leader,leader信息定位到segment
kafka顺序能保证吗
分区内可以
kafka消费能力不足
增加topic分区,增加消费者组中消费者的数量,使分区数等于消费者数
下游数据没处理好也会造成挤压
如何根据offset找到对应的Message?
第一步,根据 Offset 找到所属的 Segment 文件
第二步,从 Segment 中获取对应 Offset 的消息数据
index文件中存储的是Offset和Position
Hbase
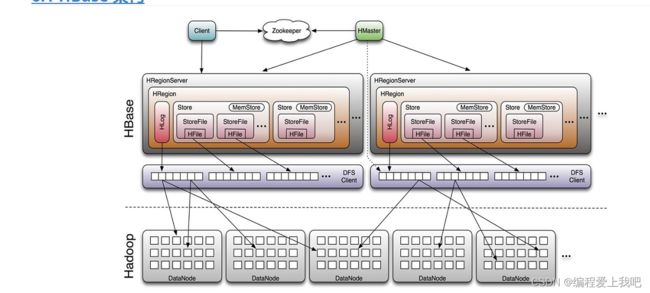
rowkey设计原则
唯一。长度100字节以内,8的倍数最好(操作系统大多为64位),可能的情况下越短越好。 散列
(加盐哈希反转)
Flink
因为flink是我想对来说最熟的东西,所以这里面试题就不背诵了,有需要的小伙计可以看我主页 第三次学flink https://blog.csdn.net/MRzhenglea/article/details/121919620
ES
kylin
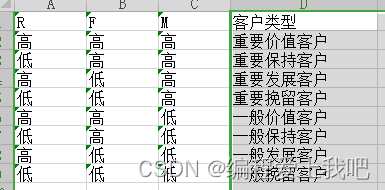
RFM用户画像
字段 说明
R 今天-支付时间=最近一次消费距离今天的天数 , if(最近一次消费距离今天的天数 > 所有用户的平均天数:低,高)
F 一年以内支付成功订单数 , if(一年以内支付成功订单数>所有用户的平均订单数:高,低)
M 一个人的支付金额/F ,if(一个人的支付总金额/F> (所有用户的金额/总订单次数 ):高 ,低 )


网络原理
TCP和UDP的区别
1 TCP是面向连接的,UDP是无连接的
2 TCP是全双工的可靠信道,信息不会丢失,UDP则是不可靠信道。
3 TCP面向字节流,UDP面向报文
4 TCP是点到点的,UDP可以一对一,一对多
5TCP首部是20字节,UDP的8字节
TCP是怎么建立连接的
第一次握手,clint发送syn=j同步序列编号,然后进入syn-sent状态
第二次握手,server发送syn=k ,ack=j+1,服务器进入syn-recv状态
第三次握手,client给server发送ack=k+1。
4次挥手
第一次 clinet 发送关闭关闭
第二次 server ack回应我收到了
第三次 server发送我发送完了
第四次 client 发送ack 我收到了
java
线程安全如何实现?
主要考的就是乐观锁与悲观锁
Java中线程安全主要是通过同步互斥、非阻塞同步和无同步方案这三种手段实现的:
简单而言就是,乐观锁,悲观锁,和压根就不同步
同步互斥,就是指,当这个资源被某个线程调用时,其他线程不能过来,主要应用就是synchronized关键字
非阻塞同步,就是指,他每次都改变那个资源,但是改变前,要先进行对比,自己要改的资源有没有已经发生变化。 比如说CAS指令(比较与交换),主要包括三个操作数,分别为内存地址,期望值,旧值。当指令执行时,将内存地址的值和旧值进行比较,如果相同,则将值修改为期望值;否则就不执行。这个过程是一个原子操作。
无同步方案:要保证线程安全,不一定就要进行同步。如果一个方法本来就不涉及共享数据,那么自然也不需要同步来保证正确性。
java中通过如下方法实现线程安全
1 使用线程同步synchorized 悲观锁
2 使用Volatile关键字 乐观锁
3 Atomic AtomicInteger
4 final
1使用synchronized
class A{
synchronized void sum(){
Thread a=Thread.currentThread();
for(int i=0;i<10;i++){
System.out.println(a.getName()+i);
}
}
}
class B extends Thread{
A x=new A();
public void run(){
x.sum();
}
}
class main{
public static void main(String[] args) {
B a=new B();
Thread aa=new Thread(a);
Thread bb=new Thread(a);
aa.setName("A");
bb.setName("B");
aa.start();
bb.start();
}
}
写一个死锁
public class DeadLock {
public static final String source1 = "a";
public static final String source2 = "b";
public static void main(String[] args) {
Thread a=new Thread(()->{
synchronized (DeadLock.source1){
System.out.println("aa");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (DeadLock.source2){
System.out.println("bb");
}
}
});
Thread b=new Thread(()->{
synchronized (source2){
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
synchronized (source1){
}
}
});
a.start();
b.start();
}
}
Synchronized和lock的区别
Synchronized是基于JVM层,Reentrantlock是java的一个类,Reentrantlock它可以定时锁等候,和中断锁等特性
所以如果线程竞争不激烈,当然用人家写好的Synchronized.
hashcode和equals方法的关系
我个人认为哈:hash的本质就是将一个大范围的数据,变成一个小范围的数据。可以参考hashmap。
首先hashcode是object的方法,返回值是int,根据一定的规则,生成一个数组,生成hash值。
equals是先比较了hashcode,然后再比较了这两个数据。为什么?因为hashcode不一样的话,说明地址不一样,一定不相等,你想想,比hashcode一定比两个数据快的多吧。
ArrayList和LinkedList的扩容机制
Arraylist 底层是数组,以add()方法为例,创建集合对象时候,会首先创建长度为10的数组,一旦添加的数据个数超过了底层数组的长度10 ,就会考虑扩容。默认的扩容长度为原来的1.5倍,同时将原来的数组在中的数据复制到新的数组中
LinkedList:底层是Node双向链表的结构,添加数据时候,元素会封装在Node 对象中,并且指向前面和后面的元素。因为底层不是数组,所以LinkedList没有添加数据需要扩容的问题
线程的创建方式
Thread 继承这个类就不能继承其他类了。
runable
几种最短路径算法的实现
深度或广度优先搜索算法,费罗伊德算法,迪杰斯特拉算法,Bellman-Ford 算法。
常量池到底放在哪?
Java6和6之前,常量池是存放在方法区(永久代)中的。
Java7,将常量池是存放到了堆中。
Java8之后,取消了整个永久代区域,取而代之的是元空间。运行时常量池和静态常量池存放在元空间中,而字符串常量池依然存放在堆中。
gc问题
一个对象的创建先到栈里,然后到新生代(新老比1:3) 新生代(eden servior servior 8:1:1) eden经过垃圾扫描到servior1 然后再扫描到servior2,然后清空servior1,然后到servior1.然后再到持久代。
标记清楚法:一般适合老年代,因为老年代是相对来说长期存活的。要清除的少。缺点就是内存碎片太多了。
标记整理算法:就是先进行标记清除法,然后进行整理。优点是没有内存碎片了。
CMS垃圾回收器:并发的标记清除法。专门回收老年代。
主要分为四个阶段
初始标记: 1主要是标记的是GCRoots,GCRoots主要包括的是静态变量,常量 。初始标记会暂停线程运行但是时间特别短。
并发标记: 把相关联的都标记起来。这一段时间比较长。
重新标记: 害怕有的没有标记。重新标记也会暂停所有的线程
并发清除: 。
java线程的几大状态转换
就绪 阻塞 运行 等待 超时等待 终止
线程可重入
具体就是两个线程用一个函数,函数懵逼了,执行顺序蒙了。(第一个线程运行此函数时,中止了,第二个又给他激活了)
使用线程池有什么好处
1 方便管理线程 2 节省系统资源 3 提高处理时间(线程创建比较消耗时间)
有几种创建线程池的方法
new CachedThreadPool 可缓存线程池 就是线程数量不限制,会回收那些长时间不需要的线程
new FixedThreadPool 定长线程池,超出的线程会在队列中等待
new ScheduledThreadPool 定长,支持定时及周期性任务执行
new SingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务
java线程之间如何相互通信
1 同步 就是说一个类(school)中有两个方法用Synchronized修饰(student和teacher),当调用了两个线程,但是这两个线程共用一个对象,这个就是有先后顺序的,第一个线程运行完,才会让第二个用这个对象。
2 while轮询方式
3 notify wait
">>"和“>>>”的区别
>>:带符号右移。正数右移高位补0,负数右移高位补1。比如:
4>>1,结果为2;
-4>>1,结果为-2.
>>>:无符号右移。无论正数还是负数,高位通通补0.
对于正数而言,>>和>>>没有区别。
对于负数而言,-2>>>1,结果是2147483647(Integer.MAX_VALUE)
-1>>>1,结果是2147483647(Integer.MAX_VALUE)
如果要判断两个数符号是否相同时,可以这么干:
return ((a >> 31) ^ (b >> 31)) ==0;
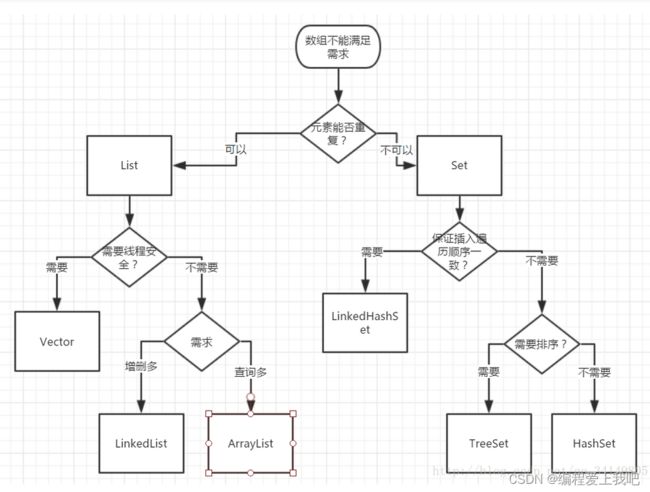
集合
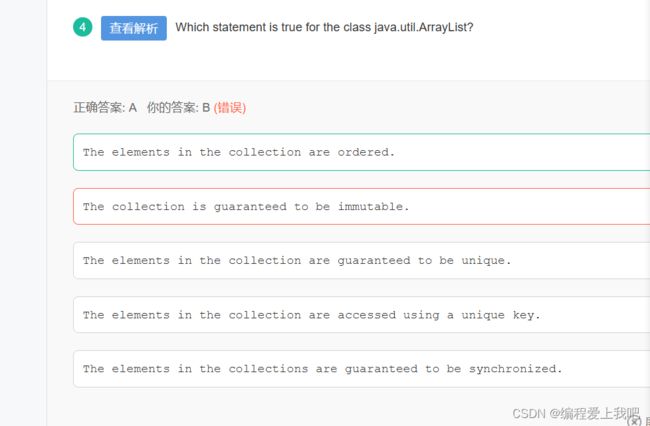
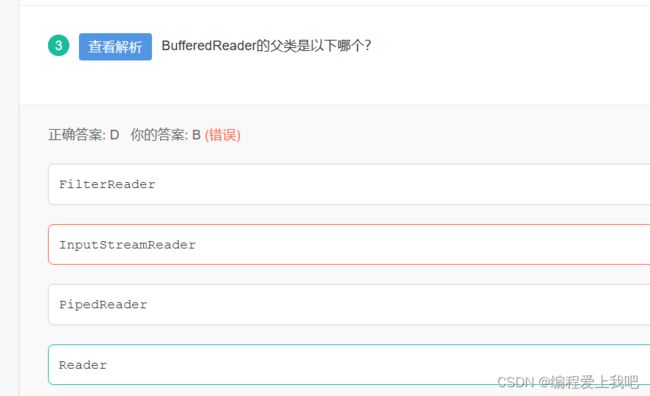
选择填空题
2022年2月18日





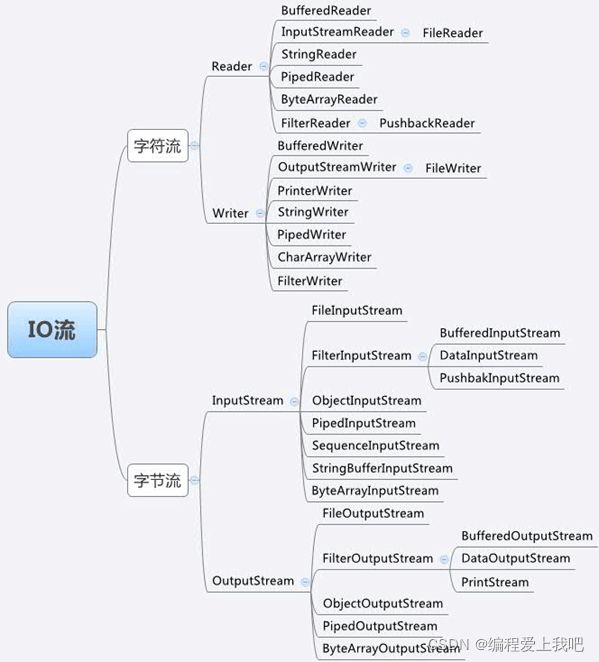

- n个节点的二叉树一共有((2n)!)/(n! * (n+1)!)种
- n层二叉树的第n层最多为2^(n-1)个
- 二叉树节点计算公式 N = n0+n1+n2,度为0的叶子节点比度为2的节点数多一个。N=1n1+2n2+1
- 对任何一棵二叉树T,如果其终端节点数为n0,度为2的节点数为n2,则n0=n2+1
- 具有n个节点的完全二叉树的深度为log2(n) + 1
- B-树,除叶子与根节点以外的任意结点的分支数介于m/2,m
- 具有n 个结点的完全二叉树的深度为[log2n]+1
- 树的高度:从根节点到所有叶节点中最大的边的数目。树的深度:从根节点到所有叶节点中最多的节点数目
二叉树有以下几个性质:TODO(上标和下标)
性质1:二叉树第i层上的结点数目最多为 2{i-1} (i≥1)。
性质2:深度为k的二叉树至多有2{k}-1个结点(k≥1)。
性质3:包含n个结点的二叉树的高度至少为[log2n]+1。
性质4:在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1。

先画出二叉树,然后求平均长度。

空闲分区分配算法有以下三个:
-
首适应算法:当接到内存申请时,查找分区说明表,找到第一个满足申请长度的空闲区,将其分割并分配。此算法简单,可以快速做出分配决定,空闲区首地址递增顺序形成空闲分区链。
-
最佳适应算法:当接到内存申请时,查找分区说明表,找到第一个能满足申请长度的最小空闲区,将其进行分割并分配。此算法最节约空间,因为它尽量不分割到大的空闲区,其缺点是可能会形成很多很小的空闲分区,称为“碎片”,空闲区大小递增顺序形成空闲分区链。
-
最坏适应算法:当接到内存申请时,查找分区说明表,找到能满足申请要求的最大的空闲区。该算法的优点是避免形成碎片,而缺点是分割了大的空闲区后,在遇到较大的程序申请内存时,无法满足的可能性较大,空闲区大小递减顺序形成空闲分区链。
 I级是最低级的。
I级是最低级的。
 堆插入一条的复杂度位logn.(这点也懵逼呀,背会吧)
堆插入一条的复杂度位logn.(这点也懵逼呀,背会吧)
红黑树平均复杂度时logn,平衡树二叉也是logn
算法空间复杂度(辅助空间)
O(1) 冒泡排序
O(1) 简单选择
O(1) 直接插入
O(1) 希尔排序
O(1) 堆排序
O(n) 归并排序
O(log n)~O(n) 快速排序
分块查找,就是分成多个块,除最后一块,其他几块大小相等,块内无序,块之间整体数据有序(比如说{1,2,4,0,5} ,{60,58,30,27,6}),然后对每块的最大值和最小值进行索引。
汉诺塔移动次数2^n -1


红黑树 就是对链表数组进行了一个折中,复杂度为O(log n),就是和平衡二叉树差不错,只不过删除插入操作时少旋转了几下
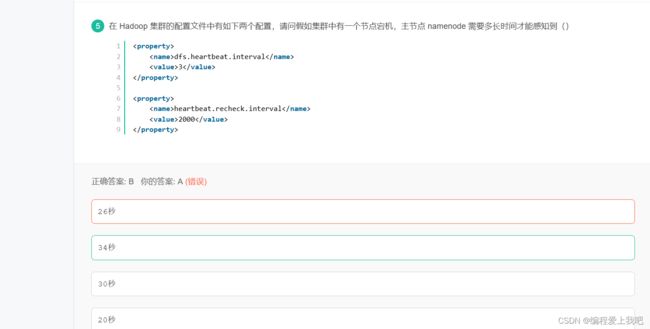

2022年2月21日

 监视器就是锁
监视器就是锁
 子类构造方法在调用时必须先调用父类的,由于父类没有无参构造,必须在子类中显式调用,修改子类构造方法如下即可:
子类构造方法在调用时必须先调用父类的,由于父类没有无参构造,必须在子类中显式调用,修改子类构造方法如下即可:
public Derived(String s){
super(“s”);
System.out.print(“D”);
}
单一连续分配:内存在此方式下分为系统区和用户区,系统区仅提供给操作系统使用,通常在低地址部分;用户区是为用户提供的、除系统区之外的内存空间。这种方式无需进行内存保护。这种方式的优点是简单、无外部碎片,可以釆用覆盖技术,不需要额外的技术支持。缺点是只能用于单用户、单任务的操作系统中,有内部碎片,存储器的利用率极低。
 小端存储(intel采用)和大端存储
小端存储(intel采用)和大端存储
大端模式:低数据位存到低位地址
小端模式:高数据位存到低位地址
 页逻辑地址不连续
页逻辑地址不连续
段之间不连续,每段内连续。
段二维是因为,存放了每段的首位置和段长
分页和分段时操作系统确定和进行的
页式和段式都是采用动态重定位方式
 *p =a[0]
*p =a[0]
a[10]越界
*a=a[0]
p和a指向同一个数组,可以做加减法(如果p和a不是指向同一数组则会出错),得到的值为整数。此题为0。所以D也相当于a[0]。
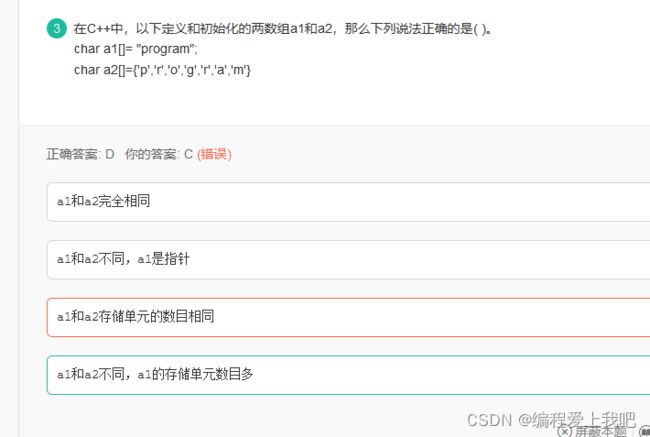
a1中存储的是字符串,因此在末尾存在字符’\0’;而a2中没有’\0’字符,所以sizeof(a1)=8,sizeof(a2)=7,a1存储单元数目多
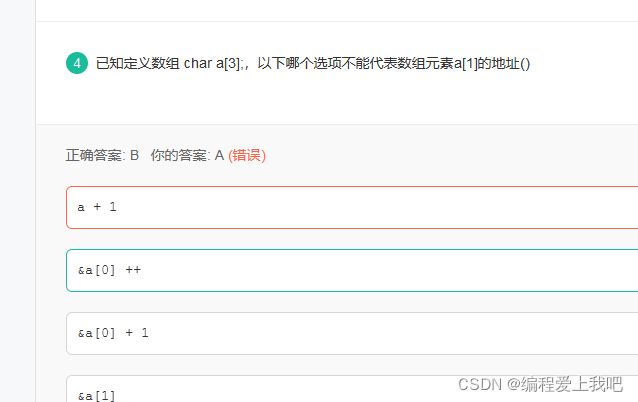 &a[0]是地址,不能自加;可以用一个指针指向它,对指针自加。 非变量不能自加
&a[0]是地址,不能自加;可以用一个指针指向它,对指针自加。 非变量不能自加

太长时间都快把指针忘掉了 &a[i]=a+i 所以 *(a+i)=a[i]
2022年2月22日
instance of
int i = 0;
System.out.println(i instanceof Integer);//编译不通过
System.out.println(i instanceof Object);//编译不通过
instanceof 运算符只能用作对象的判断。
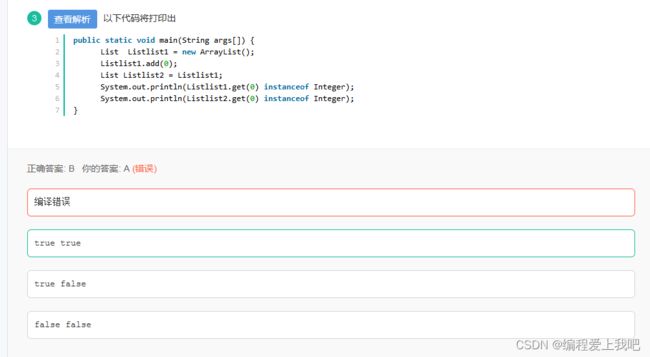
B.
collection类型的集合(ArrayList,LinkedList)只能装入对象类型的数据,该题中装入了0,是一个基本类型,但是JDK5以后提供了自动装箱与自动拆箱,所以int类型自动装箱变为了Integer类型。编译能够正常通过。
将list1的引用赋值给了list2,那么list1和list2都将指向同一个堆内存空间。instanceof是Java中关键字,用于判断一个对象是否属于某个特定类的实例,并且返回boolean类型的返回值。显然,list1.get(0)和list2.get(0)都属于Integer的实例
2022年2月24日
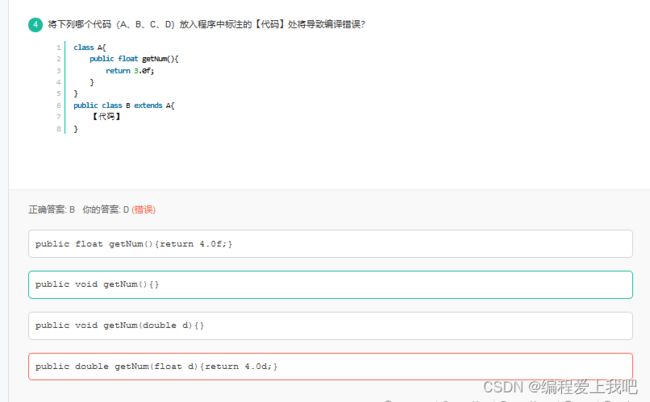 重写的条件,方法名相同,参数类型相同。并且重写的抛出的异常要小于父类。 子类返回类型小于等于父类方法返回类型。
重写的条件,方法名相同,参数类型相同。并且重写的抛出的异常要小于父类。 子类返回类型小于等于父类方法返回类型。
尴尬的是这道题拿void和float比,记住,void大于一切。
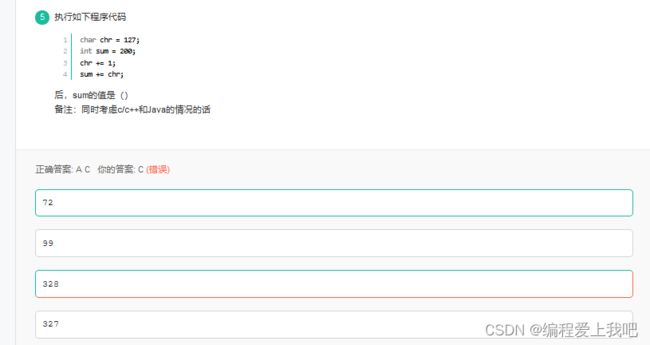
ava中只有byte, boolean是一个字节, char是两个字节, 所以对于java来说127不会发生溢出, 输出328
但是对于c/c++语言来说, char是一个字节, 会发生溢出, 对127加一发生溢出, 0111 1111 --> 1000 0000, 1000 0000为补码-128, 所以结果为200-128=72
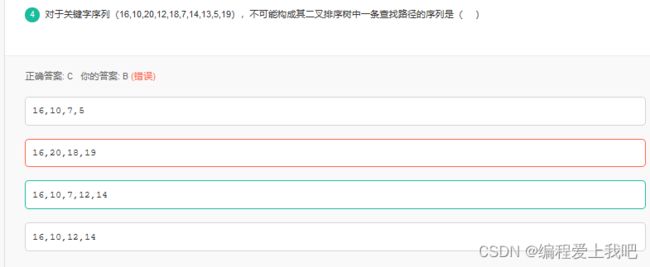
对于后续节点,要么都比他大,要么都比他小。
2022年2月25日
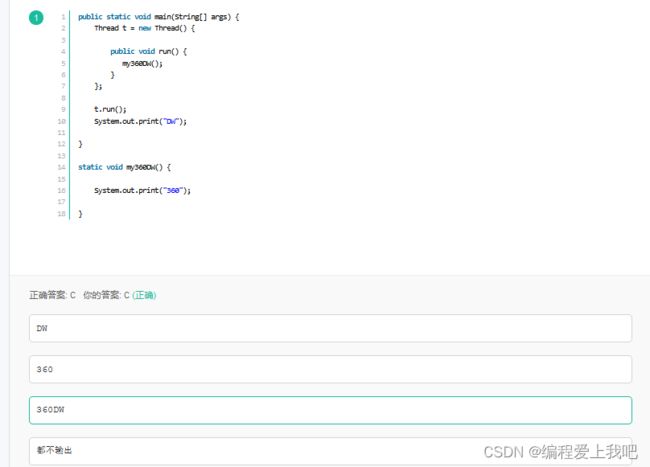 t.run就是调用这个方法,而t.start才是调用这个线程
t.run就是调用这个方法,而t.start才是调用这个线程

堆排序的时间复杂度是logn
在Unix系统中,磁盘空闲空间管理所采用的方法是成组链表法。
空闲块成组链接,建立空闲块专用栈,空闲块分配时按组进行,一组的空闲块分配完了,再使用下一组;回收时次序相反,入栈一组空闲块后,够成一组。这种方法兼备了空闲空间表法和空闲块链接法的优点,UNIX系统使用这种空闲块管理策略。
SQL练习
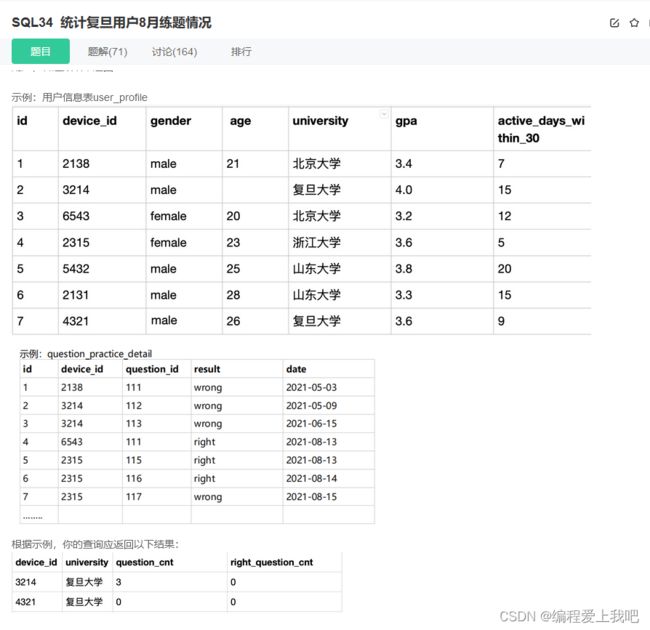 求复旦大学总的答题树和正确答题树。
求复旦大学总的答题树和正确答题树。
select t1.device_id,t1.university,count(t2.question_id) as question_cnt,sum( case when result="right" then 1 else 0 end) as right_question_cnt
from user_profile t1
left join question_practice_detail t2 on t1.device_id=t2.device_id
where t1.university = '复旦大学' and (MONTH(date)=8 or date is null)
group by device_id
计算用户的平均次日留存率
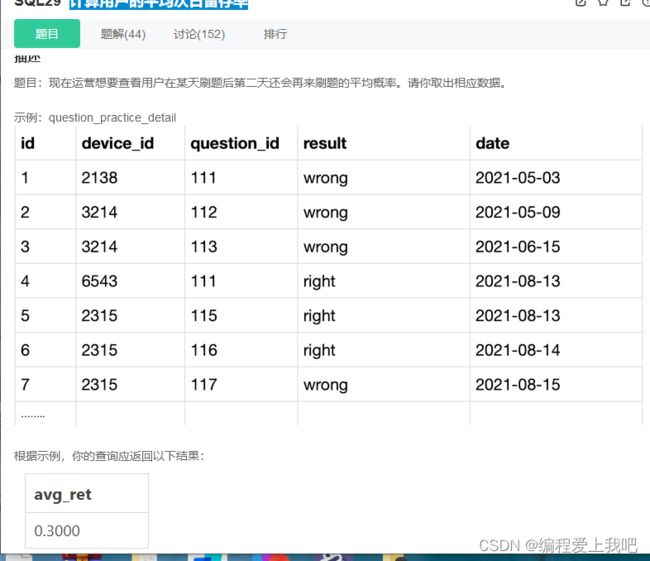 思路:1因为这道题牵涉到过去或者未来,首先想到的是要join自己,然后把关键是以后针对于时间就用 date_add这个函数,这个题中上等难度吧。
思路:1因为这道题牵涉到过去或者未来,首先想到的是要join自己,然后把关键是以后针对于时间就用 date_add这个函数,这个题中上等难度吧。
select count(date2)/count(date1) as avg_ret from(select DISTINCT q1.device_id,q1.date as date1 ,q2.date as date2 from question_practice_detail q1
LEFT JOIN (SELECT DISTINCT device_id,date from question_practice_detail) as q2
on q1.device_id=q2.device_id and date_add(q1.date,interval 1 DAY) = q2.date) as id_last_next_date
浙大不同难度题目的正确率
(我之前就是sql渣渣,这道题是我第一次没看答案写出来的困难题,开心,看来每天练几道sql是有用的)
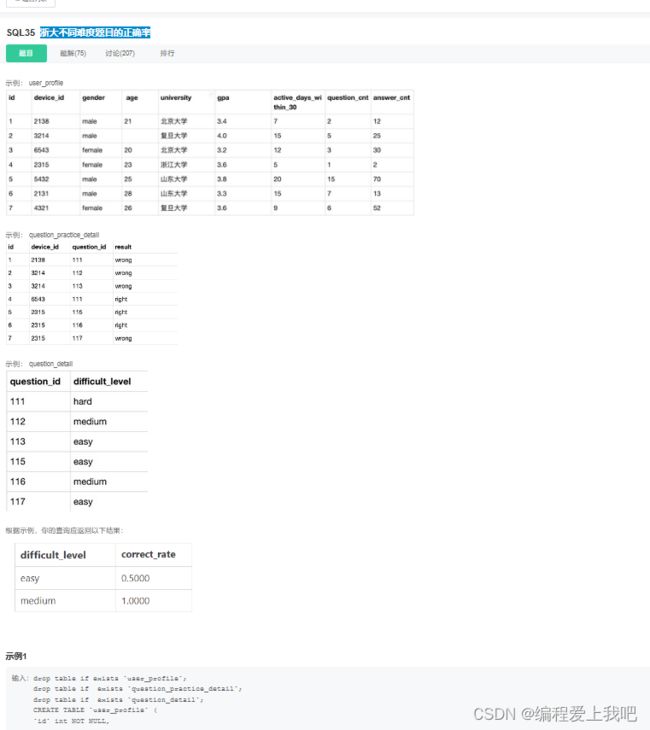
select difficult_level, sum(case when t12.result='right' then 1 end)/count(*) as correct_rate from
(select t1.device_id,t2.question_id,t2.result from user_profile t1 left JOIN question_practice_detail t2 on t1.device_id=t2.device_id and t1.university='浙江大学') t12
join question_detail t3 using(question_id) group by t3.difficult_level
SQl类别高难度试卷得分截断平均值
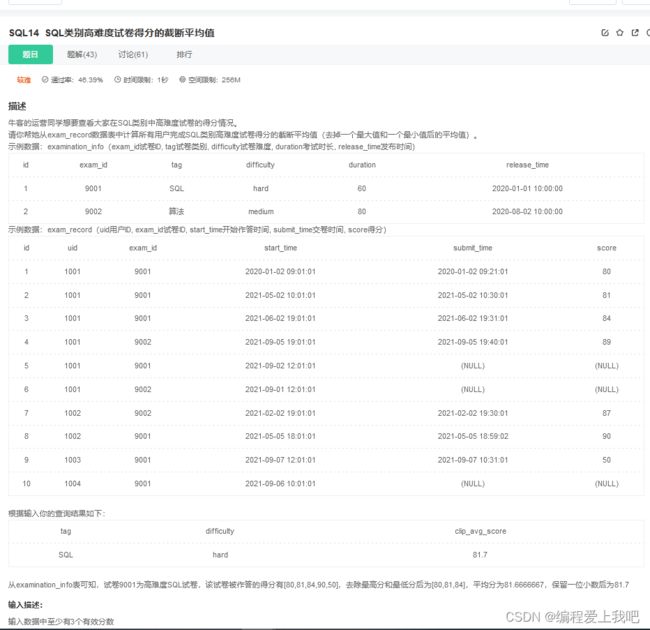 猛的一看,去掉一个最高分和最低分,还有那个保留一位我不会求。这道题直接蒙蔽了,看了答案才会写,但要是去掉两个最高分或者最低分怎么写呢?原来用round函数
猛的一看,去掉一个最高分和最低分,还有那个保留一位我不会求。这道题直接蒙蔽了,看了答案才会写,但要是去掉两个最高分或者最低分怎么写呢?原来用round函数
这个是我写的,比较垃圾
select t2.tag , t2.difficulty,round((sum(t1.score)-max(t1.score)-min(t1.score))/(count(*)-2),1) as clip_avg_score from exam_record t1 LEFT join examination_info t2
on t1.exam_id=t2.exam_id and submit_time is not null where t2.difficulty='hard' and t2.tag='SQL' group by t2.difficulty
这个官方写的
select tag, difficulty,
round((sum(score) - max(score) - min(score)) / (count(score) - 2), 1) as clip_avg_score
from exam_record
join examination_info using(exam_id)
where tag="SQL" and difficulty="hard"
一张表中有name,科目,分数 统计所有科目大于85分的学生
select * from table group by name having count(*) = sum(case when score>85 then 1 else 0 end)
SQL优化
1 避免全表扫描,首先应考虑在where及order by设计的列上建立索引
2 建立索引后,不要使用 where name is null 这样全表扫描 最好用 name=0
3 减少使用or where name=1 or name=2 可以写成 select id from t where num=10 union all select id from t where num=20
4 能用between and 不用in 很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
5 不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引
例如 select id from t where num/2=100 select id from t where num=100*2
6 在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
7 索引不要太多,不利于插入和update
8 尽量使用数字型字段,如果数值信息的字段尽量不要设置成varchar,因为底层是一个一个字符比较
9 尽量使用varchar 而不是char 节省空间,比较变少了
10 不要返回用不到的任何字段,比如说 select * from t要用具体的字段代替。
11 避免向客户端返回大数据量,检查需求是否合理。
算法学习
利用数组,
1有效的字母异位词

public boolearn test(String s,String t){
if(s.length()!=t.length()){return false;}
char[] str1=s.toCharArray();
char[] str2=t.toCharArray();
Arrays.sort(str1);
Arrays.sort(str2);
return Arrays.equals(str1,str2)
}
如果要是与当前有关的话,一般利用栈。
class Solution {
public int[] dailyTemperatures(int[] temperatures) {
int length = temperatures.length;
int[] ans = new int[length];
Deque<Integer> stack = new LinkedList<Integer>();
for (int i = 0; i < length; i++) {
int temperature = temperatures[i];
while (!stack.isEmpty() && temperature > temperatures[stack.peek()]) {
int prevIndex = stack.pop();
ans[prevIndex] = i - prevIndex;
}
stack.push(i);
}
return ans;
}
}
优先队列
优先队列和队列的区别是:队列先进先出,优先队列,可以通过比较让谁先出去,在java中主要是priorityQueue,其中要重写comparator接口,返回的是一个int ,int越小,则越靠近树的根部。
二叉堆的结构,利用一个数组来实现完全二叉树
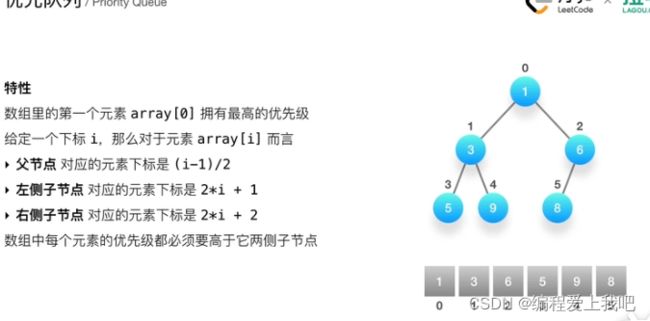 向上筛选和向下筛选。就是插入一个树与父节点或者子节点进行交换。
向上筛选和向下筛选。就是插入一个树与父节点或者子节点进行交换。
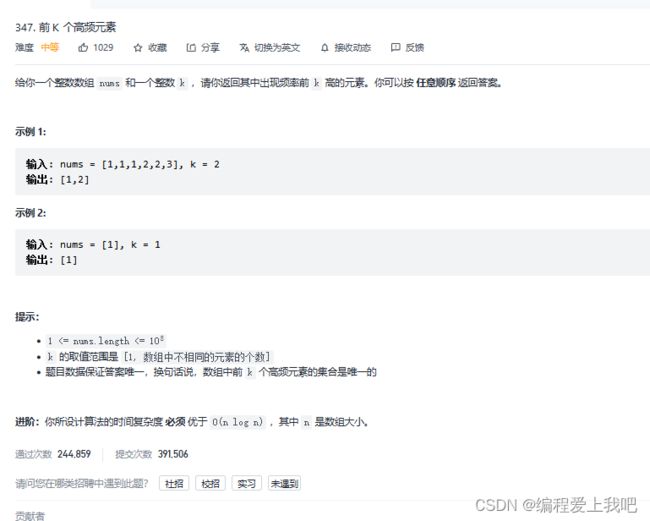 以后对于取前几个的值就采用这种方法,优先队列 prorityQueue重写个Compator方法,a-b就是小堆。a就是上边的父亲节点,b就是下面的子节点。
以后对于取前几个的值就采用这种方法,优先队列 prorityQueue重写个Compator方法,a-b就是小堆。a就是上边的父亲节点,b就是下面的子节点。
public static List<Integer> topKFrequent(int[] nums, int k) {
HashMap<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
if (map.containsKey(num)) {
map.put(num, map.get(num) + 1);
} else {
map.put(num, 1);
}
}
PriorityQueue pq = new PriorityQueue<Integer>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o1.intValue() - o2.intValue();
}
});
for(Integer i : map.keySet()){
if(pq.size()<k){
pq.add(i);
}else {
if(map.get((int)pq.peek())<map.get(i)){
pq.poll();
pq.add(i);
}
}
}
ArrayList<Integer> res = new ArrayList<>();
while(pq.size()!=0){
res.add((Integer) pq.poll());
}
return res;
}
注意o1-o2是小堆,o2-01是大堆。
解这种题我发现了更快的一个方法:就是利用数组 set list直接来回转换,Arrays.sort比较
package com.dayup.algorithm.task.zijie;
import java.util.Scanner;
/**
* @author zhz
* @date 2022/2/18
* 聪明的编辑
* 题目:三个同样的字母连在一起,一定是拼写错误,去掉一个的就好啦:比如 helllo -> hello
* 两对一样的字母(AABB型)连在一起,一定是拼写错误,去掉第二对的一个字母就好啦:比如 helloo -> hello
* 上面的规则优先“从左到右”匹配,即如果是AABBCC,虽然AABB和BBCC都是错误拼写,应该优先考虑修复AABB,结果为AABCC
* 输入描述:
* 第一行包括一个数字N,表示本次用例包括多少个待校验的字符串。
* 后面跟随N行,每行为一个待校验的字符串。
* 输出描述:
* N行,每行包括一个被修复后的字符串。
* 输入
* 2
* helloo
* wooooooow
* 输出
* hello
* woow
*/
public class Edit {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int num = sc.nextInt();
for (int i = 0; i < num; i++) {
String s = sc.next();
System.out.println(change(s));
}
}
static String change(String s) {
StringBuilder res=new StringBuilder();
if(s.length()<2){
return s;
}
for(int i=0;i<s.length();i++){
if(i<2){
res.append(s.charAt(i));
continue;
}
else {
if(res.length()-3>=0) {
if (s.charAt(i) == res.charAt(res.length() - 1) && s.charAt(i) == res.charAt(res.length() - 2)) {
continue;
}
if (s.charAt(i) == res.charAt(res.length() - 1) && res.charAt(res.length() - 2) == res.charAt(res.length() - 3)) {
continue;
}
}else {
if (s.charAt(i) == res.charAt(res.length() - 1) && s.charAt(i) == res.charAt(res.length() - 2)) {
continue;
}
}
res.append(s.charAt(i));
}
}
return res.toString();
}
}
图

前缀树
线段树
树状数组
力扣练习
数组
1移除元素(简单)
https://leetcode-cn.com/problems/remove-element/
//暴力击败了百分五
class Solution {
public static int removeElement(int[] nums, int val) {
int len = nums.length;
if (len == 0) {
return 0;
}
for (int i = 0; i < len; i++) {
if (nums[i] == val) {
for (int j = i; j < len - 1; j++) {
nums[j] = nums[j + 1];
}
i--;
len--;
}
}
return len;
}
}
//双指针法
public static int removeElement(int[] nums, int val) {
int right = 0,left=0;
for(;right<nums.length;right++){
if(nums[right]!=val){
nums[left]=nums[right];
left++;
}
}
return left;
}
链表
哈希表
字符串
双指针法
栈与队列
java中的stack是容器吗
是容器
stack继承vector类,vector继承list,list继承collection,stack底层用数组存储,但是不连续。栈是容器适配器,底层容器使用不同的容器,导致栈内数据在内存中是不是连续分布。
一个是用java本身的集合类型Stack类型;另一个是借用LinkedList来间接实现Stack。
Deque stack=new ArrayDeque();
Deque stack = new LinkedList();
1.用栈实现队列(简单)
https://leetcode-cn.com/problems/implement-queue-using-stacks/submissions/
//第一个是我写的,但是运行报错,第二个是官方,我不会测试,不知道为啥输入空的能进栈,忘大佬告知
package com.zb;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.Stack;
class MyQueue {
Deque<Integer> frist;
Deque<Integer> two;
public MyQueue() {
frist=new ArrayDeque<Integer>();
two=new ArrayDeque<Integer>();
}
public void push(int x) {
frist.push(x);
}
public int pop() {
if(two.isEmpty()){
two.push(frist.pop());}
return two.pop();
}
public int peek() {
if(two.isEmpty()){
two.push(frist.pop());}
return two.peek();
}
public boolean empty() {
return two.isEmpty()&&frist.isEmpty();
}
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue obj = new MyQueue();
* obj.push(x);
* int param_2 = obj.pop();
* int param_3 = obj.peek();
* boolean param_4 = obj.empty();
*/
class MyQueue {
Deque<Integer> inStack;
Deque<Integer> outStack;
public MyQueue() {
inStack = new ArrayDeque<Integer>();
outStack = new ArrayDeque<Integer>();
}
public void push(int x) {
inStack.push(x);
}
public int pop() {
if (outStack.isEmpty()) {
in2out();
}
return outStack.pop();
}
public int peek() {
if (outStack.isEmpty()) {
in2out();
}
return outStack.peek();
}
public boolean empty() {
return inStack.isEmpty() && outStack.isEmpty();
}
private void in2out() {
while (!inStack.isEmpty()) {
outStack.push(inStack.pop());
}
}
}
二叉树
//先序中序后序遍历
public class TreeNode{
int val;
TreeNode left;
TreeNode right;
public TreeNode(int val){
this.val=val;
}
public TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
void postorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val); // 注意这一句
}
回溯算法
递归和回溯的区别
个人认为: 递归,就是当前解需要上或者下一个解,层层迭代
回溯,先遍历到最后一个解,再依次往回退,就像链表反转,用回溯的方法。
问题1 :给两个数 n和k,求1到n中所有的组合,每个组合中的个数为k
https://leetcode-cn.com/problems/combinations/
/**
这道题对我来说挺难的,理解了好半天
小题总结,回溯算法就是用树的思路,一直遍历到最后一个节点,然后往上回,链表反转可以用到回溯算法。
这道题的思路是for循环横向遍历,递归纵向遍历,但是我的理解也不深刻,仅仅的就只是会写这道题了。
*/
class Solution {
List<List<Integer>> res = new ArrayList<>();
ArrayList<Integer> zujian = new ArrayList<>();
public List<List<Integer>> combine(int n, int k) {
xiangxia(n, k, 1);
return res;
}
//采用回溯法,思路,for用来横向扩展,递归用来向下扩展
void xiangxia(int n, int k, int index) {
if (zujian.size() == k) {
res.add(new ArrayList<>(zujian));
return;
}
for (int i = index; i < zujian.size() + n - k + 1; i++) {
zujian.add(i);
xiangxia(n, k, i + 1);
zujian.remove(zujian.size() - 1);
}
}
}
贪心算法
找到局部最优解从而找到全局最优解
分饼干(简单)
https://leetcode-cn.com/problems/assign-cookies/submissions/
public int findContentChildren(int[] g, int[] s) {
Arrays.sort(s);
Arrays.sort(g);
int j=0;
int res=0;
for(int i=0 ;i<s.length && j<g.length;i++){
if(s[i]>=g[j]){
j++;
res++;
continue;
}
}
return res;
}
动态规划
0-1背包问题
打家劫舍–中等
https://leetcode-cn.com/problems/house-robber/submissions/
import java.lang.Math;
class Solution {
public static int rob(int[] nums) {
if (nums == null || nums.length == 0) {
return 0;
}
int length = nums.length;
if(length ==1){
return nums[0];
}
if (length == 2) {
return Math.max(nums[0], nums[1]);
}
else{
int[][] data = new int[length][2];
data[0][0] = nums[0];
data[0][1] = 0;
data[1][0] = Math.max(nums[0], nums[1]);
data[1][1] = nums[0];
for (int i = 2; i < length; i++) {
data[i][0] = data[i - 1][1] + nums[i];
data[i][1] = Math.max(data[i - 1][1], data[i - 1][0]);
}
return Math.max(data[length - 1][0], data[length - 1][1]);
}
}
}
单调栈
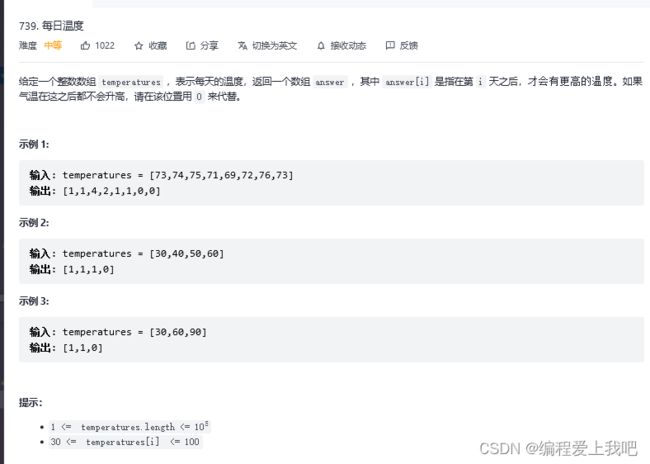
每日温度
https://leetcode.cn/problems/daily-temperatures/submissions/
这道题暴力的话,不太合适,用这种栈来解决真的很好,同时这道题我明白了下面的关系图
public static int[] dailyTemperatures(int[] temperatures) {
int res[] = new int[temperatures.length];
int length = temperatures.length;
Deque<Integer> q=new LinkedList<Integer>();//存储温度没有上升的天数
for(int i=0;i<length;i++){
while (!q.isEmpty() && (temperatures[(int)q.peek()]<temperatures[i])){
int poll = q.poll();
res[poll]=i-poll;
}
q.push(i);
}
return res;
}
碰壁经历
多益网络:笔试
SQL
查询sutdent表中的学生信息(name、age),其中age在20到30之间的优先输出,其他正常输出。
当时我不会case when
select name,age (case when age between 20 and 30 then 0 else 1 end) remark from student order by remark
算法:
给一个数组 a[0,1,-2,3,1],让其中的任意三个元素相加,等于某一个数,并且这三个数不能重复
在这里插入代码片
字节
笔试准备
1 计算机网络
ISO七层OSI五层 物理层数据链路层网络层运输层应用层
模拟信号可以转换为数字信号,转换的设施为CODEC中的编码器
TCP/IP互联层含有四个重要的协议,分别为IP,ICMP,ARP,RARP
IPV6地址的编制长度是16字节
网络体系结构中数据链路层的数据处理单元是 帧
二层交换机中的端口/mac地址映射表是 交换机在数据转发过程中通过学习动态建立的
标准的URL由协议类型,主机名,路径及文件名组成
物理层的主要功能是实现比特流的透明传输
通用顶级域名的是net
用于接收电子邮件的网络协议是 IMAP
OSPF适合于规模较大的互联网使用,而RIP适合于规模较小的互联网使用。
HTTP协议服务端进程的TCP端口为80
交换式局域网的核心设备时交换机
简述带宽 ,波特率,码元,位传输率的区别
带宽就是通过某种介质的最低频率
波特率是每秒的采用次数。
码元是每采样发送一个信息,这个信息就是码元
位传输速率就是=每个采样的大小乘以波特率
理想汽车
一面结束:问了两个问题,结束,答出来一个,没答出来的是,一个城市,红蓝车分别为15%,85%,一个人说看到是红车,专家分析是80%他看到的是真的,请问是是红车的几率是多少,15%*85%
设看到蓝车为事件A,看到绿车事件B,看正确为事件C,看错误为事件D
P(C|A)=P(CA)/P(A)=P(A)P(C|A)/[P(A)P(C|A)+P(B)P(D|B)]
1为啥要先写入mysql后写入TIDB.
胡晶明
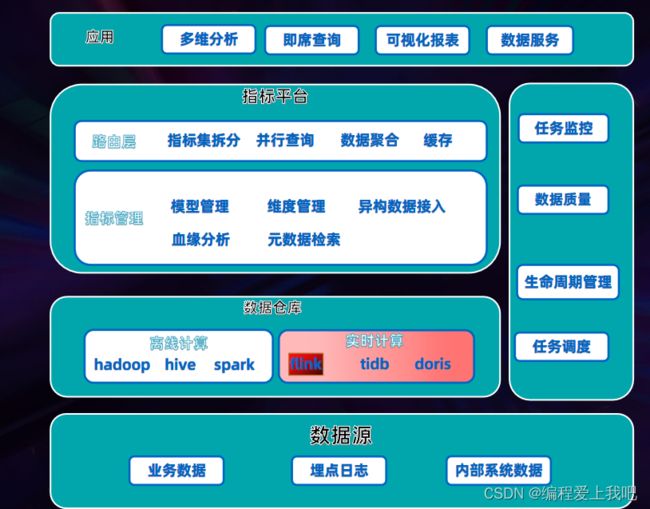
一 理想汽车基于 Flink 的实时数据仓库 0-1 初步建设
1 业务
实时数据大屏(pv uv 日活等核心指标)
实时数据异常检测(实时监控自埋点日志,发现用户使用异常,大约每日2千万条)
实时数据分析(门店销售,车辆进度管理)
2 实时数仓目标
数据准确性 实时数据和离线数据进行T+1的对比。小时级别的离线和实施的对比
实时数据链路稳定性 建立监控。
实时数据的查询服务:秒级响应。

两个例子

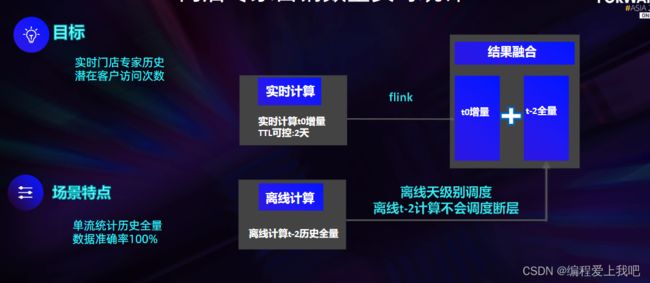 这里边实时流要超过2天,然后要通过row_number进行去重。
这里边实时流要超过2天,然后要通过row_number进行去重。
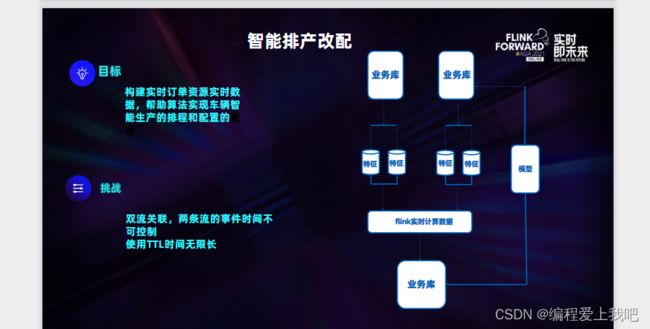
两条流的时间不可控,就把流映射成一张flink表。然后进行join ,当join不到的时候,就给维表join.
乱序问题: event_time update_time.追踪数据的
线上上线与恢复:主备链路双跑
快速修复机制: 根据侧输出流进行天级别的修复。
Lambda架构kappa架构
Lambda架构就是一个实时,一个离线
kappa架构就是实时和离线共用一个代码,简单来说,你kafka存储几天(你需要几天就几天的)数据,当你需要计算全量的时候,把这个流从新跑一下。然后把旧的去掉。
TIDB
产生的原因,mysql无法面对大数据量问题。noSQL又只能解决部分分布式事务问题
同时支持oltp 和olap
结构:
TiDBServer :负责sql请求,通过PD得到元数据,从tiki中得到。
PDServer 类似于namenode 管理元数据
TIkiServer 存储元数据 默认采用rockDB(LSM树,写的比较快)
SparkDriver 用于olap
TiDB Operator 用来方便云上部署
SQL操作:
3000 集群运行情况
8010 数据情况
mysql -h 127.0.0.1 -p 4000 -u root
读取历史数据
set @@tidb_snapshot=““2020-02-26 08:50:27;
select * from table 就直接查出来的是那个时间的数据
set @@tidb_snapshot=””;就是现在的时间。
impala
hive太慢了,所以用impala.
druid
jdbc本质 sun定义一套操作所有关系数据库的规则,即接口,各个数据库厂商去实现这套接口,提供数据库驱动jar包,我们可以使用这套接口(jdbc)编程。真正执行的代码是jar包中的实现类。
Druid由阿里巴巴提供的数据库连接池.底层是 DataSource javax.sql下面的,获取方法:getConnection. connection.close不再表示关闭,代表归还。
1 导入jar包,2 定义配置文件 3加载配置文件 4DruidDataSourceFactory.createDataSource
小米-java
一面
自我介绍
实习项目介绍
MySQL:
唯一索引比普通索引快吗, 为什么?
不,innodb引擎中,查询的话,唯一索引查到一条数据会直接返回,普通索引会匹配下面的,但是当更新时,普通索引把数据放到changebuffer中就可以了。但是唯一索引,还要验证更改后,是不是唯一的。
MySQL查询缓存有什么弊端, 应该什么情况下使用, 8.0版本对查询缓存有什么变更.
查询缓存可能会失效非常频繁, 对于一个表, 只要有更新, 该表的全部查询缓存都会被清空. 因此对于频繁更新的表来说, 查询缓存不一定能起到正面效果.
对于读远多于写的表可以考虑使用查询缓存.
8.0版本的查询缓存功能被删了 ( ̄. ̄).
sql如何对一千万的数据进行分页
select * from articles limit 100,500
select * from articles where id >(select id from articles limit 170500,1) limit 500
select * from articles where id between (select id from articles limit 170000,1) and (select id from articles limit 170500,1)
sql的运行顺序为
from where group having order limit
MVCC
什么情况下使用间隙锁
覆盖索引
如何拆分数据表
MySQL主从同步
slave主动拉binlog,还是master主动推binlog
redis数据类型
缓存雪崩 缓存穿透
Redist支持事务嘛?可以回滚吗?
单线程理解 如何保证高并发
内存淘汰算法
redis持久化方式
redis优化从哪些方面入手?(能想到的都说…
redis分布式锁
如何基于redis实现延时队列?zset
手写一个线程安全安全的单例
如何保证队列不被重复消费,保证幂等
消息队列能够解决什么问题?
二面
实习项目相关
Spring AOP
Spring Boot starter启动过程,开始启动做了什么事情
Java自定义注解
一般用来做什么
写了一个注解在方法上,SpringBoot怎么去实现这个注解,让它能用
分布式锁的具体使用场景
JVM原理
现在视频通讯,用到了哪些网络技术
DNS作用
TCP UDP区别
TCP为什么不能三次挥手
如果只有三次挥手,会出现什么情况
平衡二叉树如何维持平衡
口述:求二叉树的高度+时间复杂度
口述:链表反转+时间复杂度
研究生课程
算法题: 15. 三数之和
未来大数据的发展以及自己需要学习的方向
1主流框架只要有就去了解就去简单的学
2 网络编程基础一定要打牢固
3 数据结构和算法一定要继续练
4 学会分析和解决问题的本质
5 多线程编程技术一定是趋势
诗词
2022年2月20日
许霖:解说,形容女生像花
你看这个 #{name} 呀,沉鱼落雁之容,闭月羞花之茂
赛过西施,比过貂蝉,胜过昭君,气死玉环
在这个花样滑冰的冰面上偏偏起舞,舞起来是花蝴蝶,停起来是蝴蝶花
玉簪花乌云,乌青卷盘龙
那是仙腰婀娜多姿玉腿修长
墨跟扎条红绒花的绳,桂花油茶青丝墨菊花的色,压鬓的金花黄橙橙,柳叶花的弯眉弯又细,葡萄花的眼睛水灵灵,玄灵花的鼻梁,樱桃花的嘴,玉米花的银牙口中盛,元宝花的耳朵灯笼花的坠,丁香花的排环绕眼明,伸胳膊就像是白莲花的藕,十指尖尖像没开花的葱,坐下好似骑一匹桃红花的马,绣绒花的大刀,单手琴论模样比花花无色,